この記事は インフォマティカ "Advent Calendar 2022 Day 9" の記事として書かれています。
はじめに
CloudのストレージサービスはData Lakeとして使用され、未加工データをひとまず保存する目的で使用されることも多いと思います。例えば、日付け名フォルダに全国のPOSレジから生データが大量ファイルとして格納されてるような状況を見たりします。店舗ID、エリアIDが違うだけで、それ以外は同じデータ構造であることが多く、数百というファイルを一度に読み込んでまとめて処理できれば楽ちんです。また、集計値を求めるために複数ファイルを一度に処理する必要があったりします。この記事ではAWS S3フォルダの複数ファイルを一括で処理する方法をご紹介します。
AWS S3での手順
とても単純な例ですが、フォルダ名"20220101"に処理対象データオブジェクト(圧縮されたファイル)が3ファイル格納されているとします。
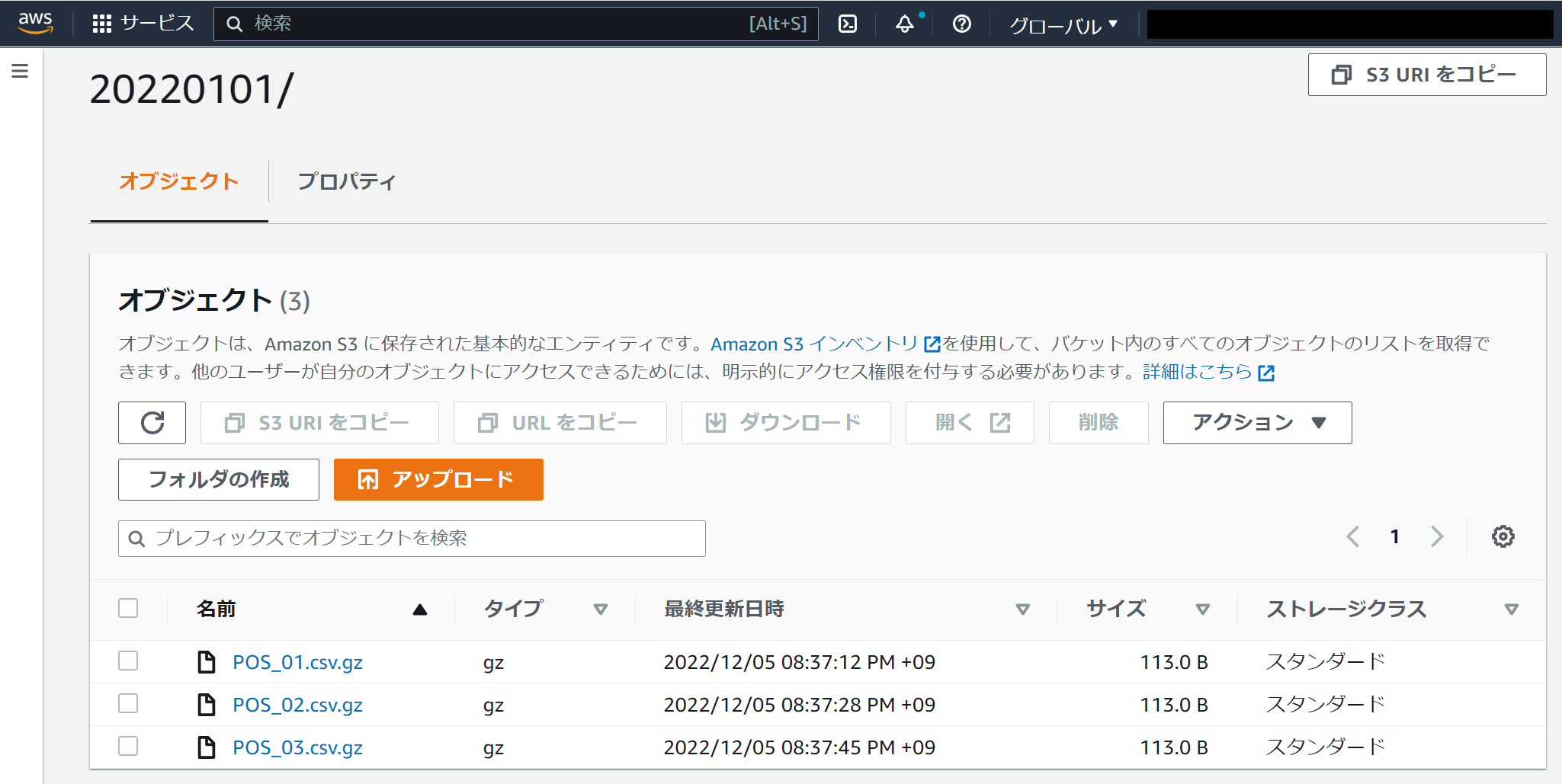
ファイル名の"POS_"が共通で、2桁の数字が店舗IDだと思って下さい。
各ファイルの内容は以下のようになっています。

CDIサービスで処理する際には、通常、各ファイルをソースに設定してETL処理を行います。
こんな風に個別にファイルのラジオボタンをチェックしソースとして設定します。

もし、店舗が1000店あって、1000のデータオブジェクトを処理するために、いちいち手動で実行するとしたら大変です(;.;)(こういう課題を解決するために違う機能もあります。6th dayの動的マッピングタスク機能の投稿も参照して下さいね!)
そこで、CDIの AWS S3 コネクタのファイル一括処理機能を使って、複数ファイルを一括処理してみます。
そのためには"manifestファイル"という特別なファイルを使用します。
以下の形式で"manifestファイル"を作成します。
{
"fileLocations": [{
"WildcardURIs": [
"20220101/POS_*.gz"
]
}, {
"URIPrefixes": [
"mseno/"
]
}],
"settings": {
"stopOnFail": "true"
}
}
上記のmanifestファイルは、「バゲットmseno配下の20220101フォルダ内にあるPOS_で始まりgzで終わるファイルを一括で読み込む。」という設定です。今回はファイル名称をPOS_Files.manifestとします。このmanifestファイルを読み込むオブジェクトを格納しているフォルダに配置します。そして、ソース設定画面でmanifestファイルを選択します。注意点として、WildcardURIsに記述するURIですが、「」は1エントリー(1行)につき一カ所しか使えないません。"20220101//.gz"というを2つ含む表記は出来ないのでお気をつけ下さい。複数エントリーを記述することが可能なので、面倒ですが環境に合わせて記述して下さい。

"形式"プルダウンから"Flat"を選びます。

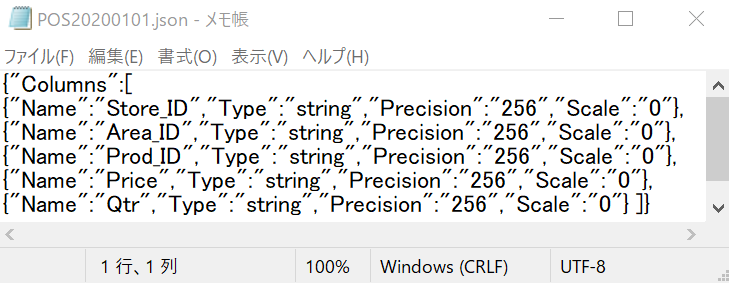
レコードのフィールド属性を設定するために、jsonファイルを使用します。
スキーマファイルファイルの内容は次のようなモノです。
フィールド名、データ型、精度などを記述します。
"形式オプション"をクリックし、スキーマソースドロップリストにて、スキーマファイルからインポートを選択します。スキーマファイルを指定するダイアログボックスが出てくるので、スキーマファイルを選択して下さい。スキーマファイルをアップロードしフィールド属性を設定します。
設定できたら、"スキーマファイル:設定済み"と表示されます。

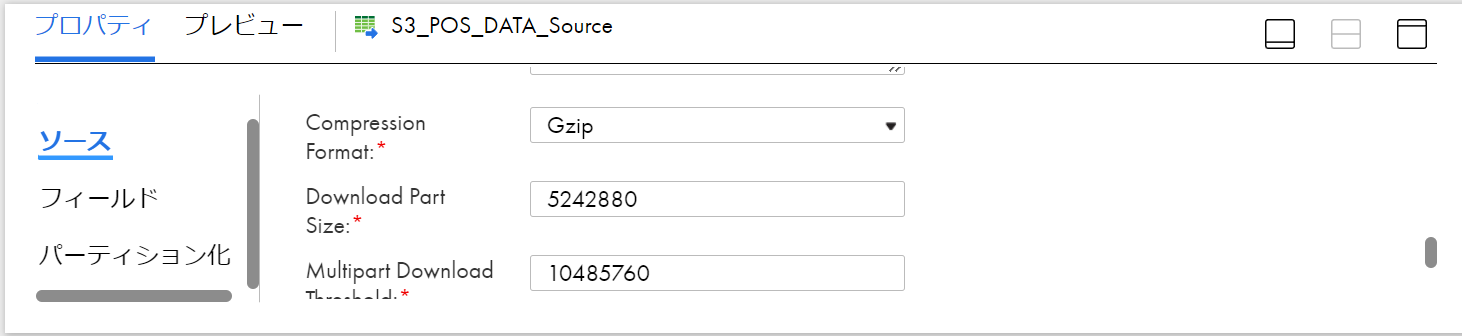
続いて、圧縮形式の設定です。今回は、gzip圧縮ファイルなので”詳細"セクションで圧縮形式を選択します。
各ファイルには5レコードが含まれ、Store_IDがそれぞれ、1,2,3の値を持っています。
以下のマッピングを実行するとStore_IDでソートされた15レコードがターゲットファイルに書き込まれます。以下実行結果です。
!
ちなみに、今回のマッピング
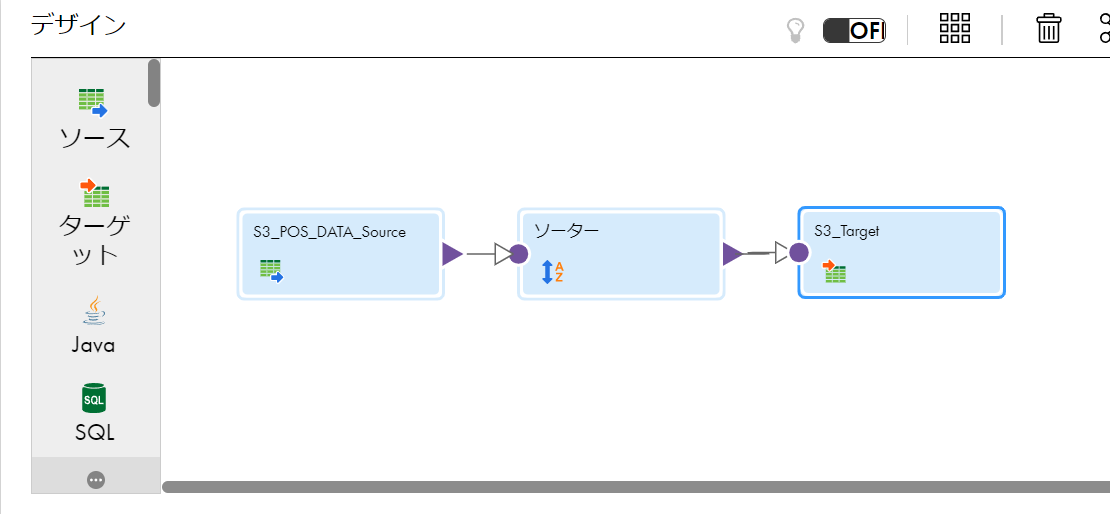
今回は、ソート処理を入れただけの簡単なETL処理でしたが、通常のETL開発と同様に様々な部品を使用して処理が出来ます。
以上で、Cloudストレージに格納された複数ファイルの一括処理手順についてご説明しました。なにかのお役に立つことを祈っております。