Cargo Tracker とは
エリック・エヴァンスのドメイン駆動設計 で紹介されている様々なパターンを実際に使用して、有志が作成したサンプル Web アプリのこと。
DDD Sample Application - Introduction
オリジナルは Spring Framework を使用している。
一方、この実装を Java EE 7 で置き換えたサンプルが公開されている。
この実装を読みながら、 DDD で紹介されている以下のパターンがどのように実装されているのかを確かめてみる。
- レイヤ化アーキテクチャ
- エンティティ
- 値オブジェクト
- 集約
- リポジトリ
サンプルアプリを動かす
ソースのダウンロード
このページ の一番下に zip のリンクがあるので、そこからダウンロードする。
環境準備
以下のソフトウェアをインストールする。
- JDK 7 以上
- Maven 2 以上
- GlassFish 4.1 以上
インストール方法とかは割愛。
ビルドする
zip を解凍してできたフォルダの直下に移動して、 mvn package でビルドする。
Maven のプラグインや依存関係を1つも落としていないと、結構時間がかかる(10分かそれ以上)。
ビルドが終わると、 target の直下に cargo-tracker.war という war ファイルが出力されている。
動かす
GlassFish を起動して、 cargo-tracker.war をデプロイする。
デプロイが完了したらブラウザから http://localhost:8080/cargo-tracker にアクセスする。

Cargo Tracker とは、どんな Web アプリ?
Cargo は「貨物」、 Tracker は「追跡するもの」。
このアプリを使うと、貨物の輸送ルートを登録したり、実際に貨物が通ったルートを記録・閲覧することができる。
佐川急便とかで、配送されている荷物がどういう経路で運ばれて今どこにいるのかを確認できるサービスがあるが、あれと同じようなもの。
エリック・エヴァンスのドメイン駆動設計 の「第7章 言語を使用する:応用例」で紹介されている架空の貨物輸送システムが元ネタになっている。
Cargo Tracker の機能
機能一覧
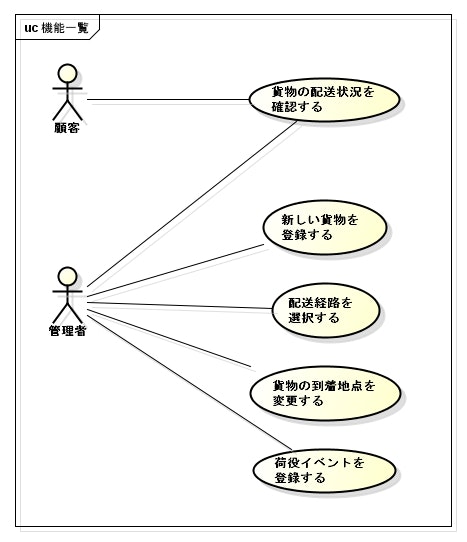
大きく、上記の機能が存在する。
- 顧客は、貨物の配送状況を確認できる。
- 管理者は、
- 貨物を新規に登録できる。
- 貨物の配送経路を選択できる。
- 「港を出発した」などの荷役イベントを登録できる。
- 貨物の到着地点を変更できる。
各画面
貨物の配送状況を確認する
URL : http://localhost:8080/cargo-tracker/public/track.xhtml
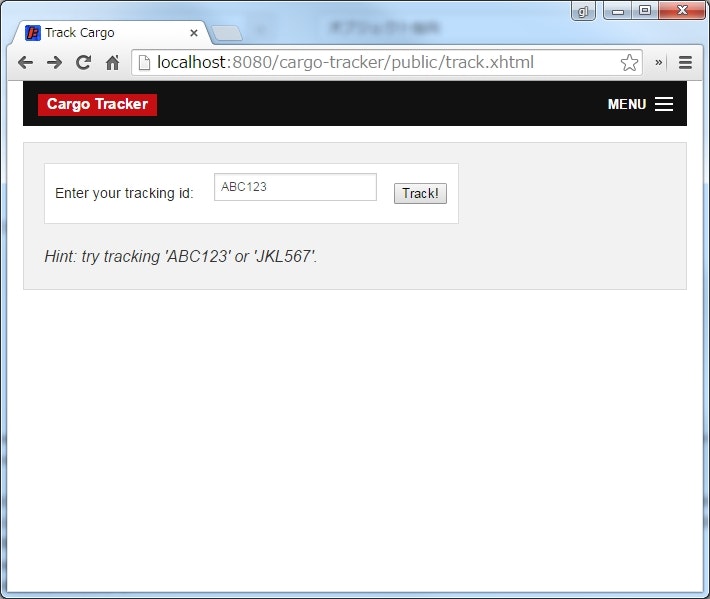
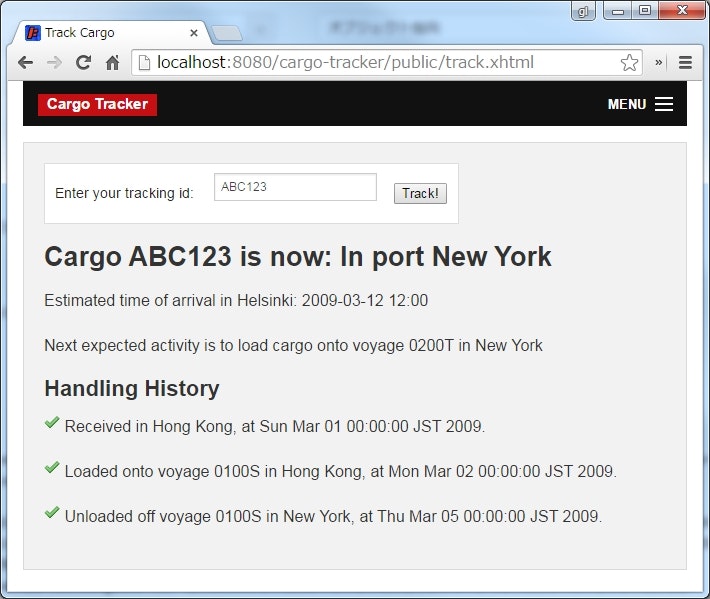
- 貨物ごとに割り当てられる追跡ID(
tracking id)を入力することで、その貨物の現在の配送状況を確認できる。 - 貨物
ABC123は、香港を出発し、現在ニューヨークに存在するらしい。
新しい貨物を登録する
URL : http://localhost:8080/cargo-tracker/admin/registration.xhtml
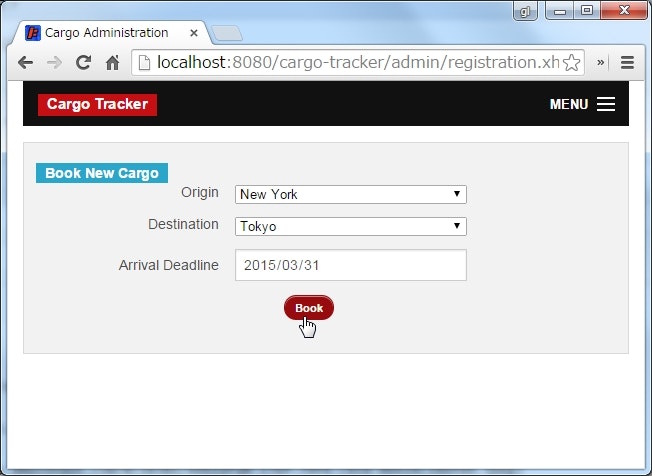
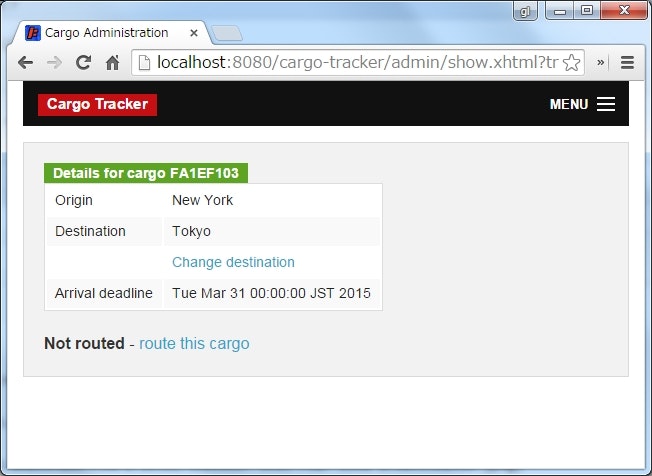
貨物の出発地点と到着地点、到着期日を入力して、新規に貨物を登録することができる。
この時点では、まだ貨物をどのような経路で配送するかについては決定していない。
配送経路を選択する
URL : http://localhost:8080/cargo-tracker/admin/selectItinerary.xhtml?trackingId=<追跡ID>

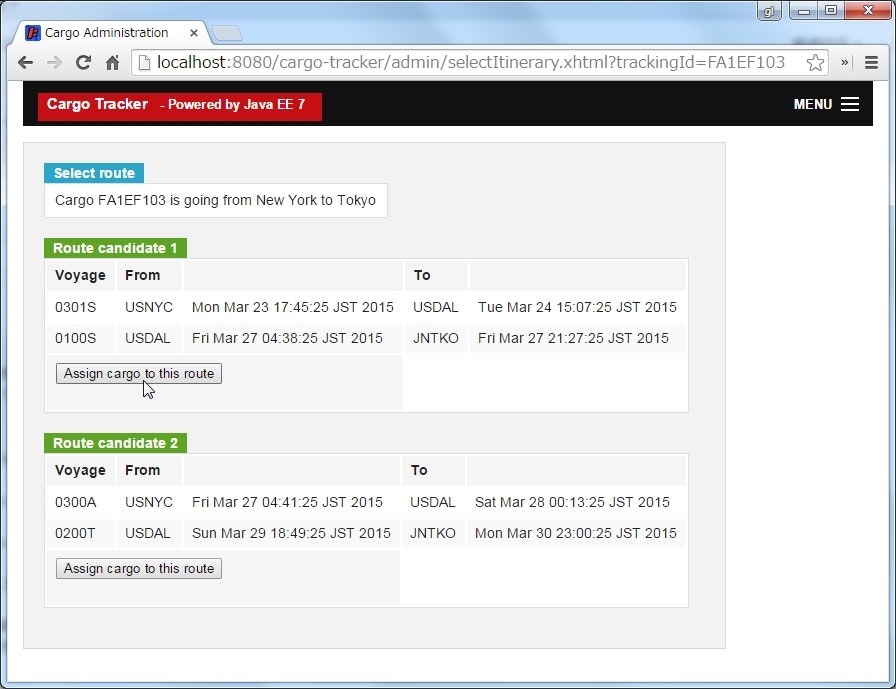
貨物ごとの管理画面から、経路を選択するページに遷移することができる。
経路の選択画面では、出発地点から到着地点までの経路の候補が表示される。
管理者は、任意の経路を選択することで、その貨物の配送経路を決定できる。
経路の候補はランダム生成
サンプルアプリでは、経路の候補はランダムに生成されている。
なので、アクセスするたびに表示される候補が変化する(候補が存在しない場合もある)。
貨物の到着地点を変更する
URL : http://localhost:8080/cargo-tracker/admin/changeDestination.xhtml?trackingId=<追跡ID>
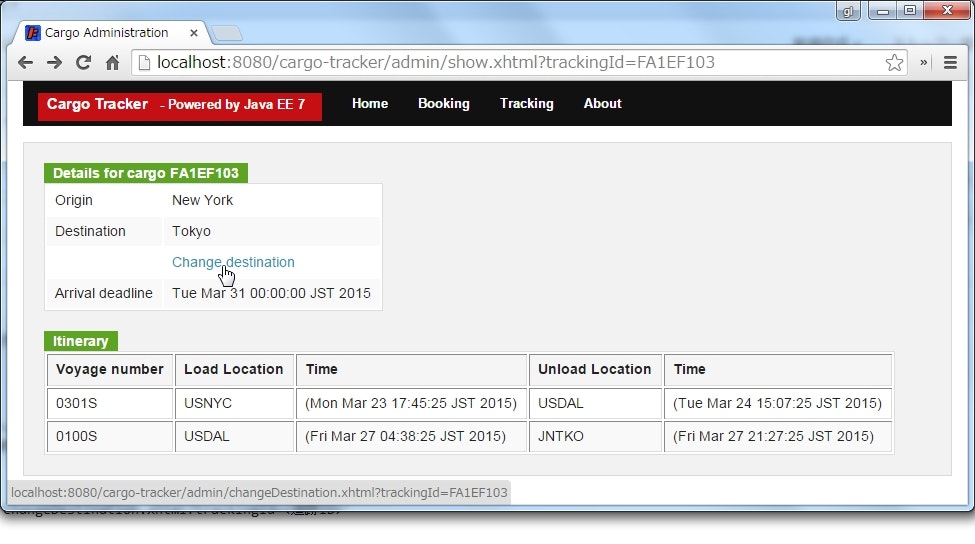

貨物の到着地点は、任意のタイミングで変更することができる。
到着地点を変更した場合は、経路を再度選択し直す必要がある。
荷役イベントを登録する
URL : http://localhost:8080/cargo-tracker/incident-logger/
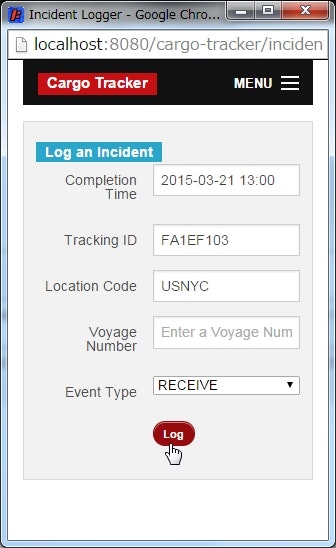
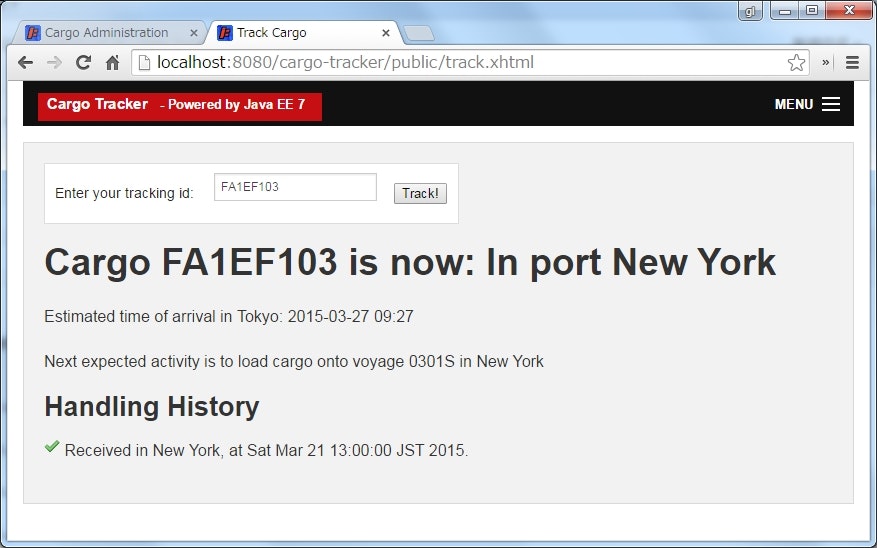
貨物に行われた荷役イベントを登録できる。
例えば、貨物(FA1EF103)をニューヨークの港(USNYC)で 2015年3月21日の 13時に受け取った(RECIEVE)場合は、以下のように入力する。
| 項目 | 値 |
|---|---|
| Completion Time | 2015-03-21 13:00 |
| Tracking ID | FA1EF103 |
| Location Code | USNYC |
| Voyage Number | - |
| Event Type | RECEIVE |
レイヤ化アーキテクチャ(LAYERED ARCHITECTURE)
DDD でのレイヤ化アーキテクチャ
アプリケーションの中では、ドメインのロジック以外にも様々な処理が行われる。
例えば、画面表示に関する処理・トランザクション制御・データベースアクセス・メール送信などがある。
もし、これら他の関心事の中にドメインロジックが紛れ込んでいると、コードは非常に読みづらくなり保守もしづらくなる。
この問題を回避するため、ドメインは他の感心事から分離しなければならない。
分離の手法は多々あるが、一般的に広く受け入れられている手法として、レイヤ化アーキテクチャがある。
レイヤ化アーキテクチャでは、アプリケーションが持つ関心事をいくつかの層に分離する。
各層に含まれる要素は、同じ層内の要素かもしくは下位の層にのみ依存し、上位の層には依存しないようにする。
上位の層と連携する場合は、コールバックやオブザーバーパターンを利用して間接的に連携する。
レイヤの分割方法にも色々あるが、以下のように4つに分割する方法が一般的に良いとされている。
- プレゼンテーション層
- アプリケーション層
- ドメイン層
- インフラストラクチャ層
各層は、次のような役割を持つ。
プレゼンテーション層(ユーザーインターフェース)
システムの利用者からの要求を解釈したり、処理結果を利用者に適した形で返却する責務を負う。
「利用者」とは、人かもしれないし、他のシステムかもしれない。
アプリケーション層
ドメイン層のオブジェクトを使って、アプリケーションの機能を実現する層。
この層はドメインロジックを持たない。代わりに、機能を実現するために必要となるドメインオブジェクトを用意し、作業の指示を出す。
また、ドメインに関係しないアプリケーション固有の関心事(例えばトランザクション制御)なども扱う。
この層は薄く保つようにし、ドメインロジックがこの層に漏れないように注意しなければならない。
ドメイン層
アプリケーションの心臓部。
ドメインロジックは、全てこの層で実装される。
インフラストラクチャ層
各層を実装するための具体的な技術要素を提供する層。
データベースアクセスやメッセージング、メール送信などがこれにあたる。
DDD の本では、ドメイン層もインフラストラクチャ層に依存する形で記述されている。
しかし、 Cargo Tracker ではインフラストラクチャ層の扱いが変わっており、ドメイン層が他の層に依存しない形になっている。個人的には、 Cargo Tracker の方のレイヤ構造の方がしっくり来ると思っている(ドメイン層がインフラ層に依存するのはおかしい気がするので)。
Cargo Tracker のレイヤ化アーキテクチャ
Cargo Tracker でのレイヤ化アーキテクチャについては、 このページ に説明が記載されている。
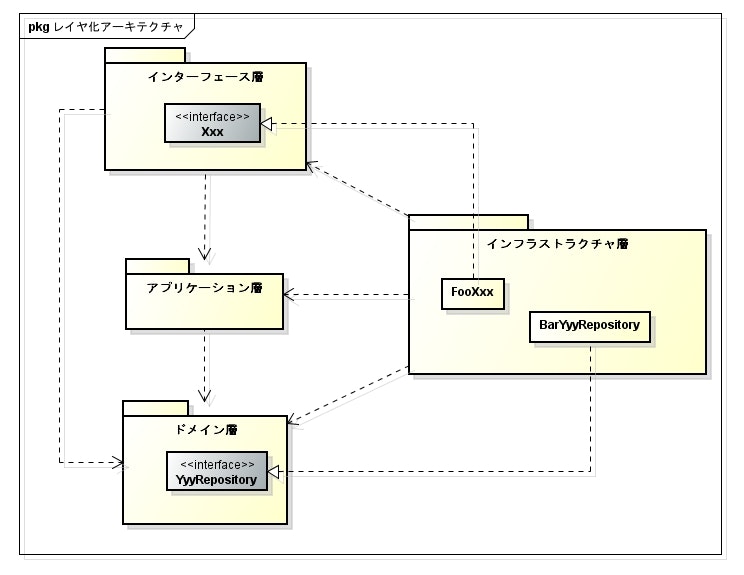
まず縦に、インターフェース層・アプリケーション層・ドメイン層の3つのレイヤが存在する。
インターフェース層は、名前が違うだけで DDD のプレゼンテーション層と役割は変わらない。
そして、3つのレイヤを支える形で、インフラストラクチャ層が存在する。
インフラストラクチャ層は、各層が持つインターフェースを実装する。そして、各層はインターフェースを介してインフラストラクチャ層に処理を委譲する。
(でも、実装を見ると依存関係が逆転してるところもあって、若干あやしい)
Cargo Tracker のパッケージ構成は、このレイヤ化アーキテクチャに従って整理されている。
net.java.cargotracker/
|-application/
|-domain/
|-infractructure/
`-interfaces/
実装を読む
貨物の登録機能の実装を例にして、 Cargo Tracker でのレイヤ化アーキテクチャの実装を見てみる。
大まかな処理の流れ
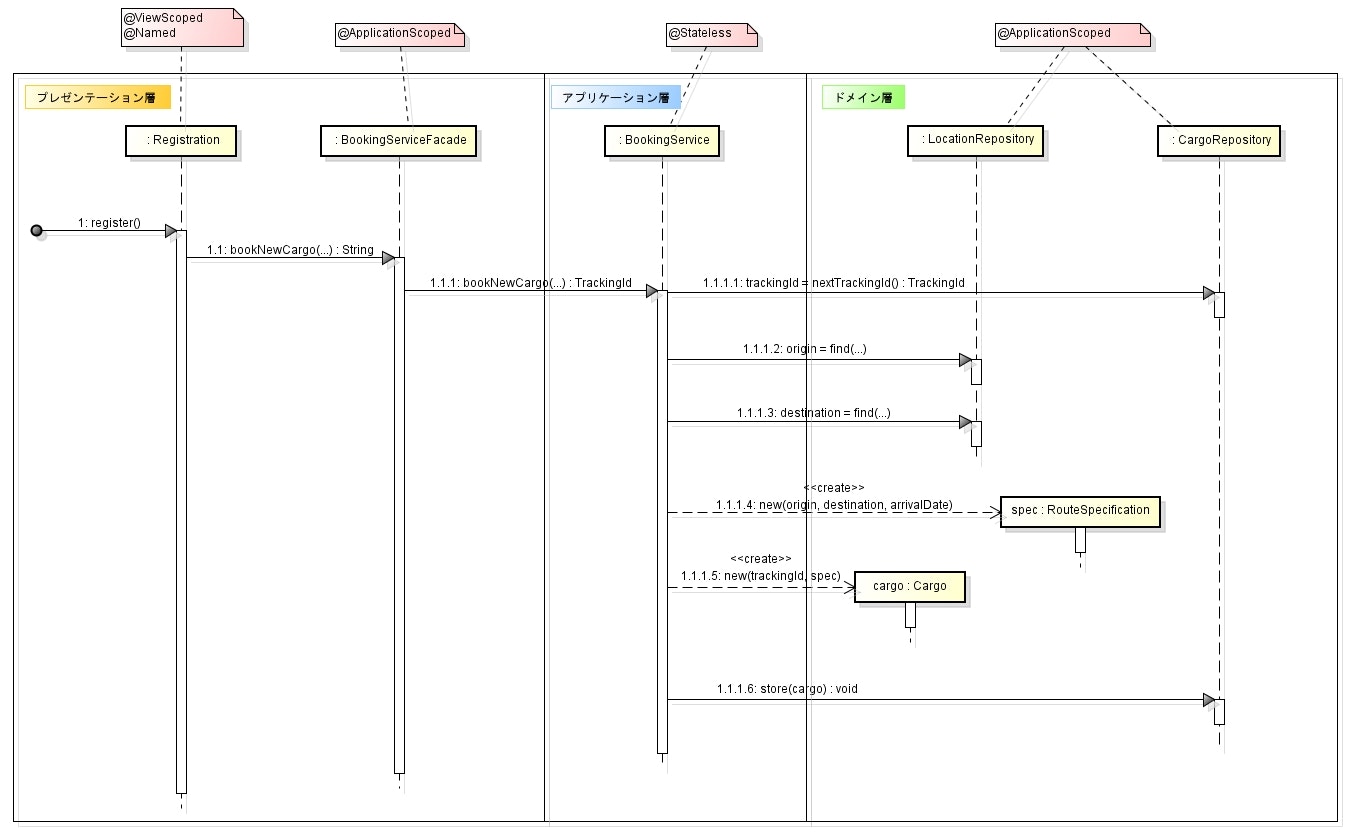
プレゼンテーション層の実装
Web のユーザーインターフェースは、 JSF で実装されている。
xhtml ファイルは src/main/webapp の下に配置されており、貨物の登録画面は admin/registration.xhtml になる。
この xhtml は、 Registration というバッキングビーンと紐付いている。
ここが、貨物登録のエントリポイントになる。
package net.java.cargotracker.interfaces.booking.web;
import java.io.Serializable;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import javax.annotation.PostConstruct;
import javax.faces.view.ViewScoped;
import javax.inject.Inject;
import javax.inject.Named;
import net.java.cargotracker.interfaces.booking.facade.BookingServiceFacade;
@Named
@ViewScoped
public class Registration implements Serializable {
private static final String FORMAT = "yyyy-MM-dd";
private String arrivalDeadline;
private String originUnlocode;
private String destinationUnlocode;
@Inject
private BookingServiceFacade bookingServiceFacade;
public String register() {
String trackingId = "";
try {
trackingId = bookingServiceFacade.bookNewCargo(originUnlocode,
destinationUnlocode,
new SimpleDateFormat(FORMAT).parse(arrivalDeadline));
} catch (ParseException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "show.xhtml?faces-redirect=true&trackingId=" + trackingId;
}
}
登録ボタンをクリックすると、 register() メソッドが実行される。
バッキングビーンは画面への入出力用のデータの保持とイベントの受付だけを行い、処理はファサード(BookingServiceFacade )に委譲している。
このファサードというクラスは、以下のような役割を担っている。
- バッキングビーン間で共通する、アプリケーション層以下への処理をとりまとめ、下位レイヤへの入り口となる。
- 画面で扱うデータ型とドメインオブジェクトを相互変換する。
このファサードを設けることで、バッキングビーンはデータの入出力に注力できるようになり、実装がシンプルになっている。
BookingServiceFacade の実体は DefaultBookingServiceFacade で、実装は以下のようになっている。
package net.java.cargotracker.interfaces.booking.facade.internal;
import javax.enterprise.context.ApplicationScoped;
import javax.inject.Inject;
import net.java.cargotracker.application.BookingService;
import net.java.cargotracker.domain.model.cargo.TrackingId;
import net.java.cargotracker.domain.model.location.UnLocode;
import net.java.cargotracker.interfaces.booking.facade.BookingServiceFacade;
import net.java.cargotracker.interfaces.booking.facade.dto.CargoRoute;
import net.java.cargotracker.interfaces.booking.facade.dto.RouteCandidate;
@ApplicationScoped
public class DefaultBookingServiceFacade implements BookingServiceFacade, Serializable {
@Inject
private BookingService bookingService;
@Override
public String bookNewCargo(String origin, String destination, Date arrivalDeadline) {
TrackingId trackingId = bookingService.bookNewCargo(
new UnLocode(origin), new UnLocode(destination),
arrivalDeadline);
return trackingId.getIdString();
}
}
@ApplicationScoped でアノテートされているので、インスタンスが CDI で管理されているのが分かる。
bookNewCargo() メソッドは、出発地点と到着地点を表すコードをドメインオブジェクトである UnLocode に変換したうえで、アプリケーション層に処理を委譲している。
また、アプリケーション層が返した処理結果(trackingId)は、インターフェース層で出力する形式(String)に変換したうえで return している。
このように、インターフェース(プレゼンテーション)層はシステムの入り口となってユーザーインターフェースとアプリケーション層との架け橋となる。
具体的には、インターフェース層で扱っているデータ形式とアプリケーション層で扱っているデータ形式(ドメインオブジェクト)の相互変換を行うのが主な役割になる。
アプリケーション層の実装
package net.java.cargotracker.application.internal;
import java.util.Date;
import java.util.List;
import java.util.logging.Level;
import java.util.logging.Logger;
import javax.ejb.Stateless;
import javax.inject.Inject;
import net.java.cargotracker.application.BookingService;
import net.java.cargotracker.domain.model.cargo.Cargo;
import net.java.cargotracker.domain.model.cargo.CargoRepository;
import net.java.cargotracker.domain.model.cargo.Itinerary;
import net.java.cargotracker.domain.model.cargo.RouteSpecification;
import net.java.cargotracker.domain.model.cargo.TrackingId;
import net.java.cargotracker.domain.model.location.Location;
import net.java.cargotracker.domain.model.location.LocationRepository;
import net.java.cargotracker.domain.model.location.UnLocode;
@Stateless
public class DefaultBookingService implements BookingService {
@Inject
private CargoRepository cargoRepository;
@Inject
private LocationRepository locationRepository;
private static final Logger logger = Logger.getLogger(DefaultBookingService.class.getName());
@Override
public TrackingId bookNewCargo(UnLocode originUnLocode, UnLocode destinationUnLocode, Date arrivalDeadline) {
TrackingId trackingId = cargoRepository.nextTrackingId();
Location origin = locationRepository.find(originUnLocode);
Location destination = locationRepository.find(destinationUnLocode);
RouteSpecification routeSpecification = new RouteSpecification(origin, destination, arrivalDeadline);
Cargo cargo = new Cargo(trackingId, routeSpecification);
cargoRepository.store(cargo);
logger.log(Level.INFO, "Booked new cargo with tracking id {0}", cargo.getTrackingId().getIdString());
return cargo.getTrackingId();
}
}
BookingService インターフェースは、 DefaultBookingService が実装している。
「アプリケーション層は薄く保つ」という割に、 bookNewCargo() メソッドの中身は結構色々やっているように見える。
しかし、実際やっているのはドメインオブジェクトをリポジトリから取得したり new したりしているだけで、ドメインの知識が漏れているわけではない。
もし、ドメインオブジェクトの生成がもっと複雑で、ドメインの知識が必要になる場合(ある条件のときはインスタンスの生成方法が変わるとか)は、**ファクトリ(FACTORY)**パターンを使って処理をファクトリに委譲したりすることになると思う。
このようにアプリケーション層は、インターフェース層から依頼された仕事を実行するためにドメインオブジェクトのクラスを連携させるのが役割になる。
あくまでアプリケーション層は調停役であり、ドメイン知識が必要になるような実装はドメイン層に任せ、アプリケーション層の実装は薄く単純に保たなければならない。
トランザクション境界
このクラスは @Stateless でアノテートされているので、 EJB コンテナによってインスタンスが管理される。
他のクラスは基本的に全て CDI によってインスタンスが管理されているなか、アプリケーション層のインスタンスだけが EJB で定義されている。
これは、トランザクションの管理を EJB コンテナに任せるためで、アプリケーション層の入り口がトランザクション境界となっている。
アプリケーション層は必須か?
自分の認識では、必須ではない。
アプリケーション層の目的は「ドメインオブジェクトを連携させて処理を実現する」ことなので、逆にいうと「連携させるほどのことでない」のであれば、その必要はないと思う。
実際、 Cargo Tracker の実装では、アプリケーション層を介さずにインターフェース層から直接ドメイン層のリポジトリを利用している実装が存在する。
@Override
public CargoRoute loadCargoForRouting(String trackingId) {
Cargo cargo = cargoRepository.find(new TrackingId(trackingId));
CargoRouteDtoAssembler assembler = new CargoRouteDtoAssembler();
return assembler.toDto(cargo);
}
インターフェース層のクラスである BookingServiceFacade が、 CargoRepository の find() メソッドを直接呼び出している。
これをわざわざアプリケーション層を介するようにしても、結局リポジトリに処理を丸投げするだけの1行メソッドができあがるだけで、コストのわりにメリットが無い(むしろ、面倒臭いという印象を実装者に与えてしまう)。
なので、こういう単純な処理はアプリケーション層を経由せずに直接ドメイン層に委譲していいと思う。
ただし、 Cargo Tracker のアプリケーション層には「トランザクション境界」という責務もあるので、トランザクション制御が必要な処理の場合はアプリケーション層を経由しなければならない。
ドメイン層の実装
package net.java.cargotracker.domain.model.cargo;
import java.io.Serializable;
import javax.persistence.Embedded;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.NamedQueries;
import javax.persistence.NamedQuery;
import net.java.cargotracker.domain.model.handling.HandlingEvent;
import net.java.cargotracker.domain.model.handling.HandlingHistory;
import net.java.cargotracker.domain.model.location.Location;
import net.java.cargotracker.domain.shared.DomainObjectUtils;
import org.apache.commons.lang3.Validate;
@Entity
@NamedQueries({
@NamedQuery(name = "Cargo.findAll",
query = "Select c from Cargo c"),
@NamedQuery(name = "Cargo.findByTrackingId",
query = "Select c from Cargo c where c.trackingId = :trackingId")})
public class Cargo implements Serializable {
private static final long serialVersionUID = 1L;
// Auto-generated surrogate key
@Id
@GeneratedValue
private Long id;
@Embedded
private TrackingId trackingId;
@ManyToOne
@JoinColumn(name = "origin_id", updatable = false)
private Location origin;
@Embedded
private RouteSpecification routeSpecification;
@Embedded // This should be nullable: https://java.net/jira/browse/JPA_SPEC-42
private Itinerary itinerary;
@Embedded
private Delivery delivery;
public Cargo() {
// Nothing to initialize.
}
public Cargo(TrackingId trackingId, RouteSpecification routeSpecification) {
Validate.notNull(trackingId, "Tracking ID is required");
Validate.notNull(routeSpecification, "Route specification is required");
this.trackingId = trackingId;
// Cargo origin never changes, even if the route specification changes.
// However, at creation, cargo orgin can be derived from the initial
// route specification.
this.origin = routeSpecification.getOrigin();
this.routeSpecification = routeSpecification;
this.delivery = Delivery.derivedFrom(this.routeSpecification,
this.itinerary, HandlingHistory.EMPTY);
this.itinerary = Itinerary.EMPTY_ITINERARY;
}
public void specifyNewRoute(RouteSpecification routeSpecification) {
// 省略
}
public void assignToRoute(Itinerary itinerary) {
// 省略
}
public void deriveDeliveryProgress(HandlingHistory handlingHistory) {
// 省略
}
}
ドメイン層のオブジェクトの代表格である Cargo (貨物)の実装。
JPA のアノテーションでアノテートすることで、エンティティの実装をそのままデータベースにマッピングできるようにしている。
それ以外は普通の Java オブジェクトと変わらない。
新しいインスタンスは、普通に new で作成する。
なので、ドメイン層のオブジェクトは Java SE 環境で単体テストを動かすことができる(SE 環境で動かせない場合は、ドメイン層が他の層に依存している可能性があり、あやしい)。
インフラストラクチャ層の実装
package net.java.cargotracker.infrastructure.persistence.jpa;
import java.io.Serializable;
import java.util.List;
import java.util.UUID;
import javax.enterprise.context.ApplicationScoped;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import net.java.cargotracker.domain.model.cargo.Cargo;
import net.java.cargotracker.domain.model.cargo.CargoRepository;
import net.java.cargotracker.domain.model.cargo.Leg;
import net.java.cargotracker.domain.model.cargo.TrackingId;
@ApplicationScoped
public class JpaCargoRepository implements CargoRepository, Serializable {
@PersistenceContext
private EntityManager entityManager;
@Override
public TrackingId nextTrackingId() {
String random = UUID.randomUUID().toString().toUpperCase();
return new TrackingId(random.substring(0, random.indexOf("-")));
}
@Override
public void store(Cargo cargo) {
// TODO See why cascade is not working correctly for legs.
for (Leg leg : cargo.getItinerary().getLegs()) {
entityManager.persist(leg);
}
entityManager.persist(cargo);
}
}
JpaCargoRepository は、ドメイン層で定義されたインターフェースである CargoRepository を、 JPA を使って実装している。
このように、インフラストラクチャ層は各層で定義されたインターフェースを実装し、具体的なインフラストラクチャに依存した機能を提供する。
依存関係は DI によって解決されるので、各層との結合も自然に実現できるようになっている。
エンティティ(ENTITY)
DDD でのエンティティ
普通、システムは様々な情報を取り扱う。
その中には、属性ではなく同一性によって個々を識別しなければならないものがある。
例えば、ある人物 A さんがいたとする。
A さんは現在 15 歳で、身長は 160 センチある。
5 年後、 A さんは 20 歳になり、身長は 180 センチになった。
15 歳の A さんと 20 歳の A さんは、年齢や身長(属性)は異なるが同一人物だ(同一性は一致している)。
DDD では、この「A さん」のように属性ではなく同一性で個々を識別しなければならないオブジェクトを エンティティ と呼び、他のオブジェクトと区別する。
エンティティは、属性が違っても同一性が一致していれば同じインスタンスと判断される。
もしインスタンスの識別を誤ると、データを間違って変更してしまうかもしれない。
そのため、エンティティの識別には細心の注意を払わなければならない。
ただし、同じオブジェクトでも、識別を同一性で行わなければならないかどうかは、対象とするシステムの性質によって変化する。
前述の A さんの場合、医療関係のシステムなら同一性による識別は必要だが、一人の人間が自由に複数のアカウントを作成できるようなシステムでは不要になる。
Cargo Tracker でのエンティティ
Cargo Tracker では、貨物がエンティティとして扱われている。
貨物が2つ登録された場合、それぞれの貨物は別物として扱われる。それは、2つの貨物に同じ配送経路が割り当てられていても変わらない。
もし2つの貨物が別物と識別できないと、貨物ごとの配送記録の登録や、履歴の確認ができなくなってしまう。
つまり、貨物には属性に関係しない同一性があり、エンティティであると判断できる。
貨物の識別には**追跡ID(TrackingId)**が使用されており、以下のように実装されている。
package net.java.cargotracker.domain.model.cargo;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
public class Cargo implements Serializable {
// Auto-generated surrogate key
@Id
@GeneratedValue
private Long id;
private TrackingId trackingId;
private Location origin;
private RouteSpecification routeSpecification;
private Itinerary itinerary;
private Delivery delivery;
@Override
public boolean equals(Object object) {
if (this == object) {
return true;
}
if (object == null || getClass() != object.getClass()) {
return false;
}
Cargo other = (Cargo) object;
return sameIdentityAs(other);
}
private boolean sameIdentityAs(Cargo other) {
return other != null && trackingId.sameValueAs(other.trackingId);
}
@Override
public int hashCode() {
return trackingId.hashCode();
}
@Override
public String toString() {
return trackingId.toString();
}
}
Cargo の equals() メソッドは、 TrackingId が等しいかどうかを検証しており、 hashCode() メソッドも TrackingId のハッシュ値をそのまま返している。
これによって、 Cargo は TrackingId だけで同一性の比較がされるようになっている。
サロゲートキーが使われている点について
サンプル実装では、識別をトラッキングID で行っているのに、データベースへの登録にはサロゲートキー(id)を使用している。
DB 上と Java 上とで、異なる値が一意識別に利用されていることに違和感を覚える。
サロゲートキーを使用するのであれば、 equals() や hashCode() もサロゲートキーを使うのが自然だと思えるのだが、どうなんだろう。。。
値オブジェクト(VALUE OBJECT)
DDD での値オブジェクト
エンティティは同一性によって各インスタンスを識別していたが、逆に属性だけで識別できるオブジェクトも存在する。
DDD では、このようなオブジェクトを 値オブジェクト と呼んでいる。
値オブジェクトは、持っている属性の値だけが重要で、同一性の識別は必要ない。
値が全く同じインスタンスが2つ存在すれば、それらは「同じもの」として扱われる。
例えば、前述の A さんの場合は、年齢(15 歳)や身長(180 センチ)という属性が値オブジェクトとなる可能性がある。
値オブジェクトは同一性を持たないので、1つのインスタンスを様々なエンティティの属性として使いまわすことができる(A さんが持つ「15 歳」インスタンスも、 B さんが持つ「15 歳」インスタンスも、同じものを使いまわして問題ない)。
ただし、インスタンスを安全に使い回すために、値オブジェクトはイミュータブル(変更不可)に設計されていなければならない。
もし値オブジェクトがミュータブル(変更可能)だと、値を変更することで他の箇所に思わぬ影響を与えてしまう可能性がある。そうなると、インスタンスは安全に使い回すことができなくなる。
Cargo Tracker での値オブジェクト
Cargo Tracker でも、様々な値オブジェクトが定義されている。
例えば、位置を識別するためのコード(UnLocode)は、以下のように実装されている。
package net.java.cargotracker.domain.model.location;
import java.io.Serializable;
import javax.persistence.Embeddable;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Pattern;
import org.apache.commons.lang3.Validate;
@Embeddable
public class UnLocode implements Serializable {
private static final long serialVersionUID = 1L;
@NotNull
// Country code is exactly two letters.
// Location code is usually three letters, but may contain the numbers 2-9
// as well.
@Pattern(regexp = "[a-zA-Z]{2}[a-zA-Z2-9]{3}")
private String unlocode;
private static final java.util.regex.Pattern VALID_PATTERN
= java.util.regex.Pattern.compile("[a-zA-Z]{2}[a-zA-Z2-9]{3}");
public UnLocode() {
// Nothing to initialize.
}
public UnLocode(String countryAndLocation) {
this.unlocode = countryAndLocation.toUpperCase();
}
public String getIdString() {
return unlocode;
}
@Override
public boolean equals(Object o) {
// ...
}
@Override
public int hashCode() {
return unlocode.hashCode();
}
boolean sameValueAs(UnLocode other) {
return other != null && this.unlocode.equals(other.unlocode);
}
@Override
public String toString() {
return getIdString();
}
}
JPA の @Embeddable でアノテートされている。
エンティティが @Entity でアノテートされるのに対して、値オブジェクトは @Embeddable でアノテートされ、組み込み可能オブジェクトとして扱われている。
実装を見ると、インスタンス変数の unlocation は、コンストラクタでしか値を渡すことができない。
つまり、 UnLocode はイミュータブルになっている。
集約(AGGREGATES)
DDD での集約
オブジェクト同士の間には、様々なルールが存在する。
例えば、あるオブジェクトの属性を変更したときは、別のオブジェクトの属性も合わせて更新しなければならない、といったルールがあったりする。
DDD では、このようにオブジェクトの変更に一貫性を持たせなければならないようなルールのことを 不変条件 と表現している。
そして、この不変条件が満たされるようにするため、 DDD では 集約(AGGREGATES) という名のカプセル化を行う。
集約は、いくつかのオブジェクトの集合体で、あるエンティティをルートとした木構造のような形をしている。
このルートエンティティは、集約の外にあるオブジェクトが集約内部のオブジェクトにアクセスするときの入り口となる。
集約外部のオブジェクトはルートエンティティを介してのみ集約内部にアクセスする。そして、ルートエンティティは不変条件が満たされるように集約内部のオブジェクトを更新する。これによって、集約内の変更に対して一貫性を保つことができるようになる。
また、集約をモデルとして表現することで、一貫性を保たなければならない領域が明確になる。
Cargo Tracker での集約
Cargo をルートとした集約
Cargo Tracker にもいくつかの集約が存在する。その1つに、 Cargo をルートとした集約がある。
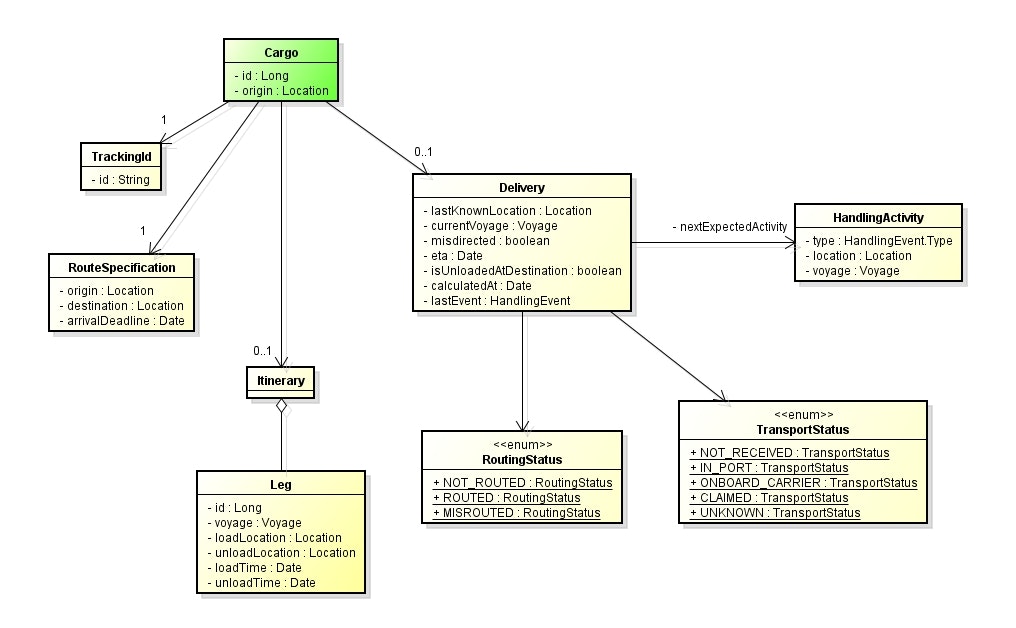
Cargo クラスを起点として、他のクラスが紐付いている。
この一連のクラスの集まりが「集約」で、 Cargo クラスが集約のルートとなっている。
また、集約にまとめられたクラスは、ちょうど cargo パッケージにまとめられたクラスと一致している。
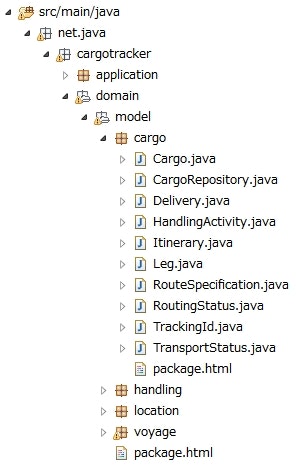
個人的な意見として、 Java のパッケージは、この集約をまとめるのに適していると思う。
特に、デフォルトの可視性である パッケージプライベート は、集約内部で閉じた処理を実現するときに有効だと思う。
DDD を知るまではパッケージプライベートの存在意義がよく分からなかったが、集約を知ってからはパッケージプライベートに重要性を感じるようになった。
具体的な実装例
具体的に、 Cargo が不変条件を満たすように振舞っている箇所を見てみる。
ユースケースで言うと、配送経路を決定する処理の部分になる。
@Override
public void assignCargoToRoute(Itinerary itinerary, TrackingId trackingId) {
Cargo cargo = cargoRepository.find(trackingId);
cargo.assignToRoute(itinerary);
cargoRepository.store(cargo);
logger.log(Level.INFO, "Assigned cargo {0} to new route", trackingId);
}
DefaultBookingService はアプリケーション層のクラスで、 assignCargoToRoute() メソッドでは、次の処理が行われている。
- トラッキングID を元に、リポジトリから貨物を取得する。
- 画面で選択された輸送日程(
Itinerary)を、貨物に設定する。 - 変更結果をリポジトリに保存する。
この2つ目の処理で呼ばれている Cargo クラスの assignToRoute() メソッドを見ると、以下のようになっている。
public void assignToRoute(Itinerary itinerary) {
Validate.notNull(itinerary, "Itinerary is required for assignment");
this.itinerary = itinerary;
// Handling consistency within the Cargo aggregate synchronously
this.delivery = delivery.updateOnRouting(this.routeSpecification, this.itinerary);
}
輸送日程が更新された直後に、配送状況(delivery)も更新されている。
この配送状況というクラスは、貨物の現在の状態を記録しているクラスで、次に行われる荷役イベントなど輸送日程に関係する様々な情報を持っている。
つまり、輸送日程を変更すると配送状況も設定し直す必要があるという不変条件が、この集約には存在している。
この不変条件は、 Cargo クラスが集約のルートとなり、 assignToRoute() メソッドを外部に提供することにより守られている。
リポジトリ(REPOSITORY)
DDD でのリポジトリ
集約内部のオブジェクトには、ルートエンティティを介してのみアクセスするようにしなければならない。
もし、集約内部のオブジェクトに自由にアクセスできるようにしてしまうと、集約によるカプセル化が破壊され、不変条件の維持ができなくなる。
つまり、集約内部のオブジェクトを取得するには、まずルートエンティティを取得しなければならない、ということになる。
では、そのルートエンティティはどこから取得するのか?
ルートエンティティの情報は、通常データベースなどに永続化されている。
ルートエンティティのインスタンスは、永続化されている情報から再構築しなければならない。
永続化されたデータにアクセスするためには、インフラストラクチャに関する処理を書かなければならない(SQL やテーブルの関連などを意識した実装)。
しかし、これらの処理をクライアント(ドメイン層を利用する側)が直接実装してしまうと、集約のカプセル化を誤って破ってしまったり、処理が複雑になったりとデメリットが大きい。
そこで、 DDD ではルートエンティティへのアクセスを抽象化し、特定のメソッドでのみインスタンスを取得できるようにしたインターフェースを定義する。
これを リポジトリ と呼ぶ。
似たようなパターンとして、 DAO (Data Access Object) がある。こちらもデータベースアクセスなどの複雑な処理を抽象化することが目的となっている。
自分の理解では、リポジトリも DAO の一種だが、「集約のカプセル化を破壊しないために、ルートエンティティへの参照を提供する」という役割を持つ点が、一般的な DAO とは異なる点だと思っている。
Cargo Tracker でのリポジトリ
Cargo Tracker にいくつかあるリポジトリのうち、 CargoRepository を見てみる。
CargoRepository は、インターフェースがドメインレイヤのパッケージに定義されている。
package net.java.cargotracker.domain.model.cargo;
import java.util.List;
public interface CargoRepository {
Cargo find(TrackingId trackingId);
List<Cargo> findAll();
void store(Cargo cargo);
TrackingId nextTrackingId();
}
Cargo のインスタンスを取得するためのメソッドと、更新用のメソッド、そして新しいトラッキングID を取得するためのメソッドが定義されている。
このインターフェースはインフラストラクチャレイヤで実装されている。
クラスは JpaCargoRepository になる。
package net.java.cargotracker.infrastructure.persistence.jpa;
import java.io.Serializable;
import java.util.List;
import java.util.UUID;
import javax.enterprise.context.ApplicationScoped;
import javax.persistence.EntityManager;
import javax.persistence.PersistenceContext;
import net.java.cargotracker.domain.model.cargo.Cargo;
import net.java.cargotracker.domain.model.cargo.CargoRepository;
import net.java.cargotracker.domain.model.cargo.Leg;
import net.java.cargotracker.domain.model.cargo.TrackingId;
@ApplicationScoped
public class JpaCargoRepository implements CargoRepository, Serializable {
private static final long serialVersionUID = 1L;
@PersistenceContext
private EntityManager entityManager;
@Override
public Cargo find(TrackingId trackingId) {
return entityManager
.createNamedQuery("Cargo.findByTrackingId", Cargo.class)
.setParameter("trackingId", trackingId)
.getSingleResult();
}
@Override
public void store(Cargo cargo) {
// TODO See why cascade is not working correctly for legs.
for (Leg leg : cargo.getItinerary().getLegs()) {
entityManager.persist(leg);
}
entityManager.persist(cargo);
}
@Override
public TrackingId nextTrackingId() {
String random = UUID.randomUUID().toString().toUpperCase();
return new TrackingId(random.substring(0, random.indexOf("-")));
}
@Override
public List<Cargo> findAll() {
return entityManager
.createNamedQuery("Cargo.findAll", Cargo.class)
.getResultList();
}
}
JpaCargoRepository クラスは @ApplicationScoped でアノテートされており、インスタンスが CDI によって管理されている。
JpaCargoRepository には EntityManager がインジェクションされており、データベースアクセスに JPA が使用されているのが分かる。
処理は基本的に EntityManager に委譲しており、 JpaCargoRepository 自体はあまり処理をしていない。
JPA を使う場合、オブジェクト間の関連は基本的にアノテーションで定義する。すると、集約の再構築は、アノテーションの情報をもとに JPA が自動で行ってくれるようになる。
このため、リポジトリの実装は EntityManager に処理を委譲するだけの単純なものになることが多くなる(と思う)。
JPA を使わない場合、この集約の再構築を自力で実装しなければならない。これは非常に面倒で骨が折れる作業になるので、 DDD の集約を実践するなら JPA の利用は重要になるのかなと個人的に思っている。
トラッキングID の発行について
サンプル実装では 、新しいトラッキングID の発行に UUID が利用されている。
これだと、リポジトリが役割を持つことに若干の違和感を覚える(TrackingId クラスにあったほうが自然な感じがする)。
これは推測だが、 UUID を使った実装は仮の実装で、実際はデータベースなど外部の情報を利用する必要があるのではないかと思う。
例えば、連番の採番にデータベースのシーケンスオブジェクトを利用したり、生成したトラッキングID が既存のものと重複していないことを確かめるには、データベースアクセスが必要になる。
その場合、インフラストラクチャの詳細を隠蔽するため、トラッキングID の生成がリポジトリの役割となっていることが理解できる。
参考
- Amazon.co.jp: エリック・エヴァンスのドメイン駆動設計 (IT Architects’Archive ソフトウェア開発の実践): エリック・エヴァンス, 今関 剛, 和智 右桂, 牧野 祐子: 本
- Amazon.co.jp: 実践ドメイン駆動設計 (Object Oriented Selection): ヴァーン・ヴァーノン, 高木 正弘: 本
- A Life in Shinjuku.: DDD Sample Application version1.1.0 を確認する
- DDDSample screencast - YouTube
- C#実装から見るDDD(ドメイン駆動設計)
- 第3回 テーブル設計のグレーゾーン~毒と薬は紙一重 (4)サロゲートキーVSナチュラルキー:SQLアタマアカデミー|gihyo.jp … 技術評論社
- サロゲートキーと複合主キー | DBFlute
- Data Access Object - Wikipedia