UnityでNPCの動きの作り方を学ばなければならないことになったので、流行りの機械学習と組み合わせてNPCの動きを学習できるML-Agentsを利用してみます。
人と協力するAgentを目指しますが、どこまでいけるのやら。
今回はまず、配布リポジトリにある環境を動かせるようになることを目指します。自作環境などは作らないのでご注意ください。
インストール準備
[GitHubのML-Agentsトップページ][gh-ml-agents]にはたくさんのバージョンがありますが、今回は最新の安定版である[release18][ml-agents-r18]をインストールします。
[gh-ml-agents]:https://github.com/Unity-Technologies/ml-agents
[ml-agents-r18]:https://github.com/Unity-Technologies/ml-agents/tree/release_18_branch
- Unityのインストール(2019.4以降)
- Python3(ver3.6もしくは3.7が推奨されている)およびpip3のインストール
- Gitコマンドをターミナルで使えるようにしておく(任意)
これらはできているものとして省略します(ごめんちゃい、ここも詳しく書いてると記述量があばば)。
多分調べればすぐ出てきます。
pip3はPython3環境でML-Agentの学習を行うためのパッケージをインストールするために使用します。
GitコマンドはML-Agent Toolkit Repositoryをcloneするために使います。
今回はAnacondaで作った仮想環境上でインストールします。
pyenvでもできるんかな。まあとりあえず、仮想環境上にインストールすることをお勧めします。
そんな安定したパッケージじゃないはずなので。
筆者の環境は
- Windows10 Pro 20H2
- Anaconda3 2021.5
- Python3.7.10
- pip3 21.1.3
- Unity Editor 2020.3.12f
です。参考までに。
インストール
まずターミナルでML-Agent Toolkit Repositoryをcloneします。
このリポジトリがなくても学習できるようですが、環境を作り学習せねばならないので(僕みたいな)初心者はcloneして、設定・学習済みのものを使用することを推奨します。
git clone --branch release_18_branch https://github.com/Unity-Technologies/ml-agents.git
次にML-AgentsのPythonパッケージをインストールします。
僕はWindows環境だったのでPyTorchを別に先行してインストールしました。
pip3 install torch~=1.7.1 -f https://download.pytorch.org/whl/torch_stable.html
pip3 install mlagents==0.27.0
これで一通り必要なもののインストールは終わりです。実際に試してみましょう!
Unity Editorで試してみる
まずは特に設定をいじらずに、学習済みのモデルを確認してみましょう。
Unity Hubを開いて、リストに追加を選択してください。
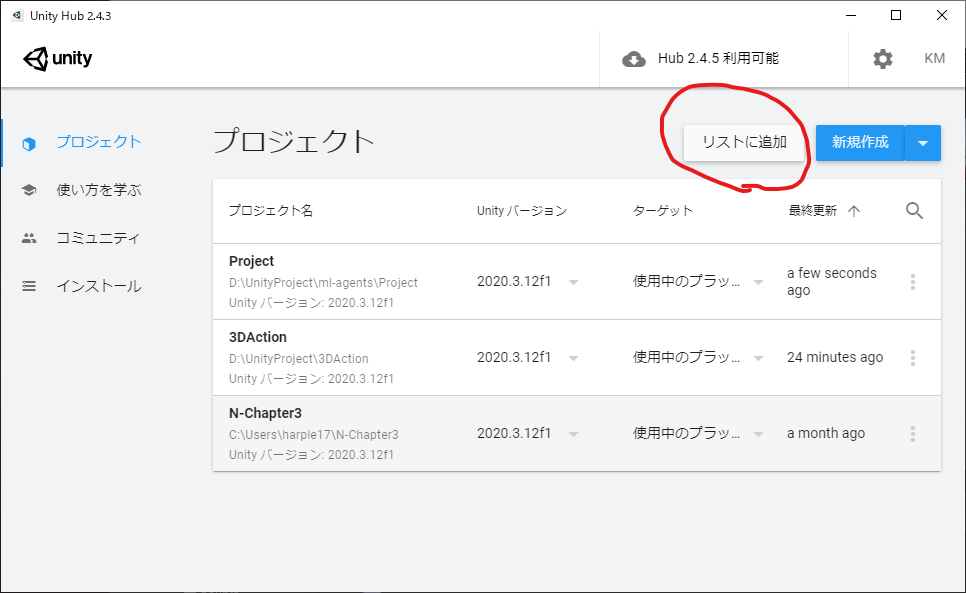
次に、先ほどcloneしたリポジトリ(ml-agents)の中にあるProjectフォルダを選択してUnity Hub上にプロジェクトを追加してください。
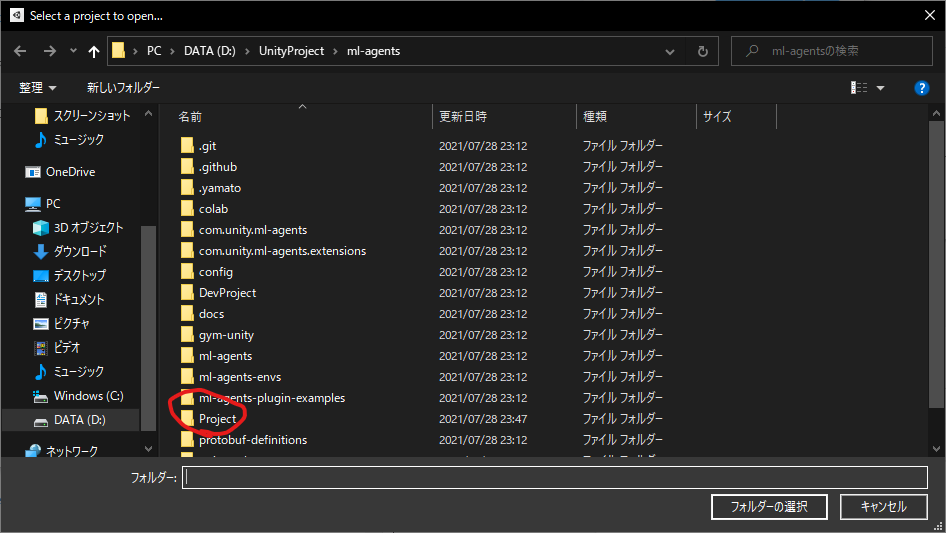
最初はUnityのバージョンが違う警告が出ると思いますが、Unity 2020.3.12fでも起動できました。
不安な方はバージョンを合わせてUnity Editorをインストールしてください。
Unity HubからProjectを開き、ProjectウィンドウからAssets > ML-Agents > Exampleに移動するといろんなゲームの例があります。
今回はWallJump > Scenes > WallJumpでWallJumpのSceneファイルを開いてみましょう。
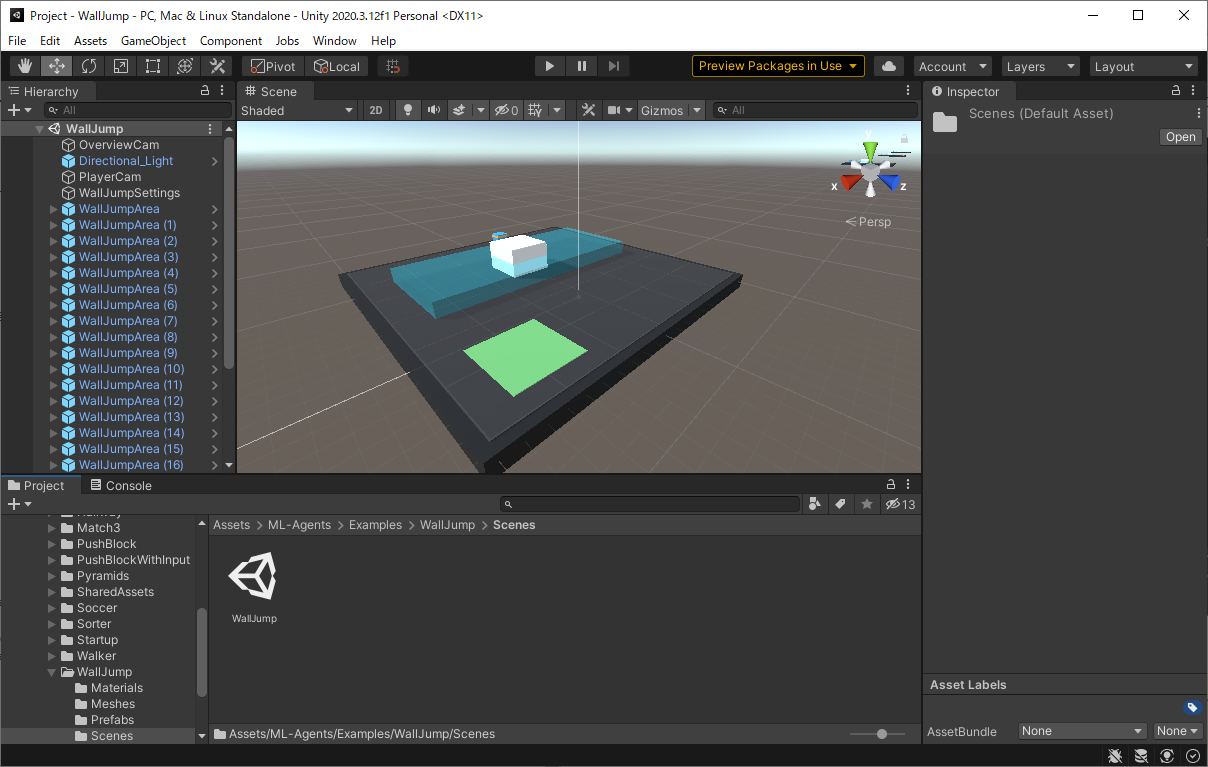
いつも通り、タブ下のPlay(▶)ボタンで動きを確認できます。
箱のAgentが壁を飛び越える動きをしているシーンを確認できればオッケーです。
かわいい
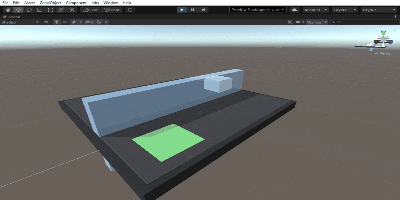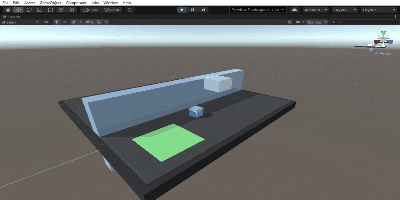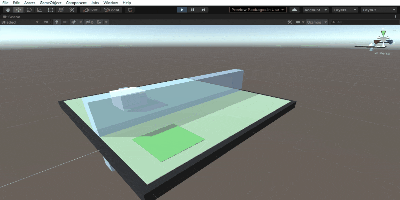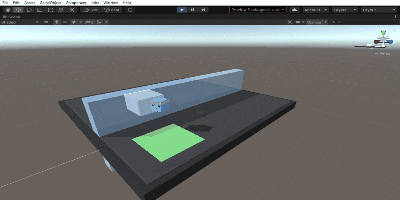
学習
さて、ML-Agentsの本筋である学習をしてみましょう。
PyTorchをインストールしたのでお察しかと思いますが、PyTorchによって学習を行います。
ただし、Pythonでコードを書くのではなくyamlファイルでハイパラを編集するだけでよさそうです。
ML-Agentsパッケージ内にスクリプトファイルがあるんでしょう。
あんまり僕のPCに負荷をかけたくないのでこのWallJumpだけ学習します。
cloneしたリポジトリ(ml-agents) > config > ppo > WallJump.yamlを以下のように編集します。
強化学習アルゴリズムはSACも使えて、GAILも可能(?)らしいですが、オーソドックスにPPOでやってみましょう。
max_stepsの回数をめちゃめちゃ減らしただけです。
behaviors:
BigWallJump:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 1000
time_horizon: 128
summary_freq: 20000
SmallWallJump:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 1000
time_horizon: 128
summary_freq: 20000
ターミナルでml-agentsフォルダに移動して、以下のコマンドを入力してください。
mlagents-learn config/ppo/WallJump.yaml --run-id=firstwj
やってることは、mlagents-learnで学習開始。次の引数でyamlファイルの相対パス指定。
--run-id=hogeで学習履歴をhogeというidで保存、です。
このコマンドを打つと、ターミナルがこんな感じになります。かっこいいな。
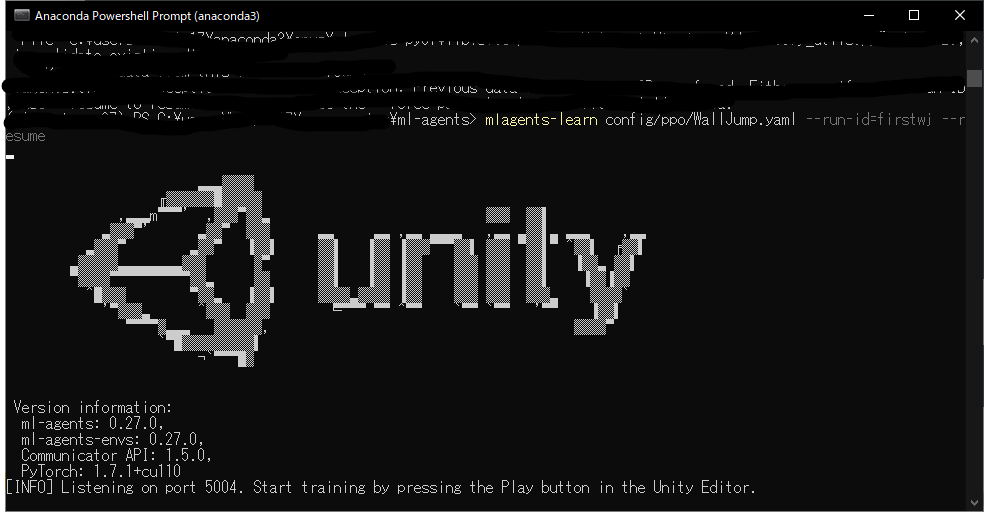
Unity EditorのPlayボタン(▶)を押せやい!って出るので素直に押します。
しばらくPlayボタンを押さないまま放置すると勝手に止まります。その時はさっきの学習開始コマンドに--resumeをつけて入力し再開してください。
僕のPCなら5秒ぐらいで終わりました。早すぎた。
学習ファイルの適用
さて、出来上がった学習ファイルは
ml-agents > results > firstwj(さっき入力したrun-id)
にある.onnxファイルです。
この.onnxファイルを
ml-agents > Project > Assets > Examples > WallJump > TFModels
に突っ込みます。元のファイルを消したくなければしっかり避けておいてね。
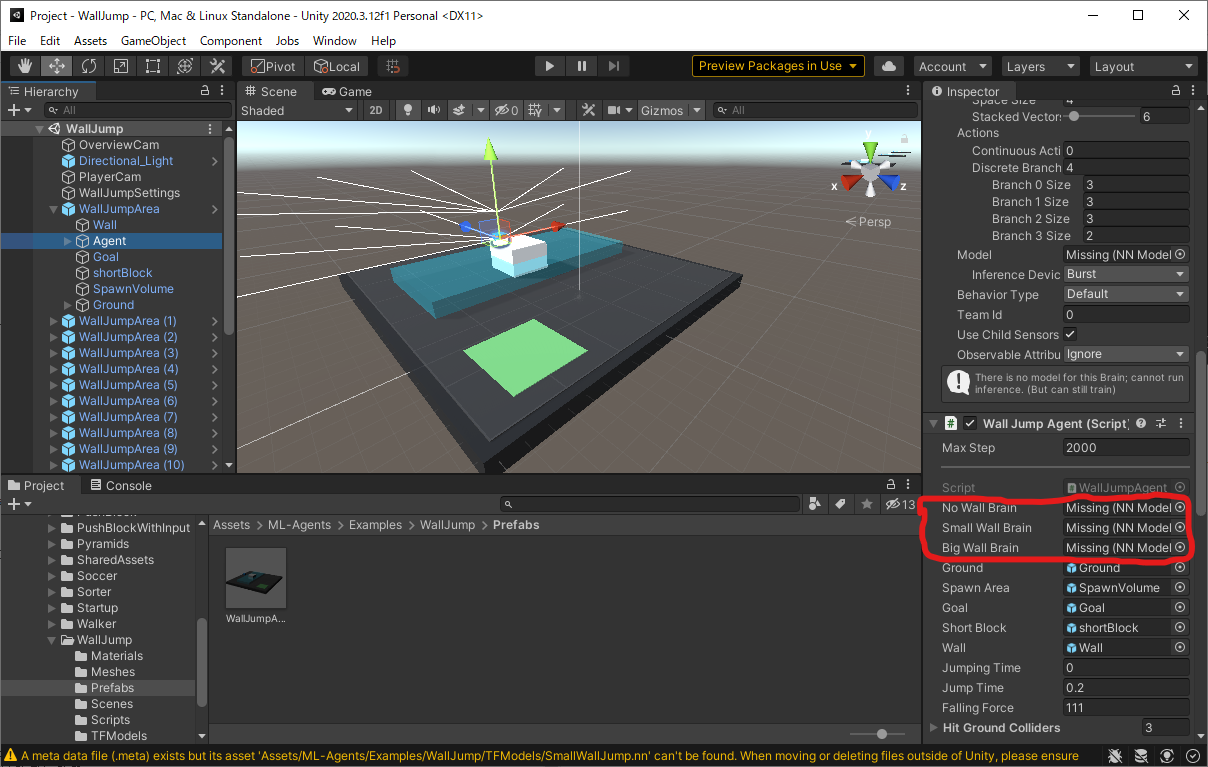
そして、Unity Editor上でシーンに対応したAgentを探します。
今回であれば、Projectウィンドウ上で
Project > Assets > ML-Agents > Examples > WallJump > Prefab
まで移動してWallJumpArea.prefabを選択すると
HierarchyウィンドウにAgentが出現します。
こいつを選択すると、Inspectorウィンドウに赤線で囲ったような、ニューラルネットワークを登録する場所が現れます。
さっき移動した.onnxファイルをProjectウィンドウで見つけ、ドラッグアンドドロップして赤線で囲った部分に登録します。
今回は2つ.onnxファイルがありますがSmall WallとBig Wallを対応させておけばとりあえず問題ないと思います。
No Wall Brainはどちらの.onnxファイルを登録してもオッケーです。
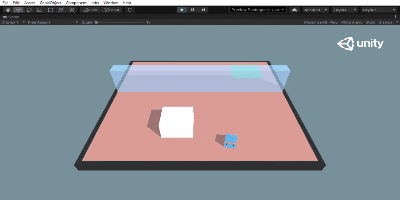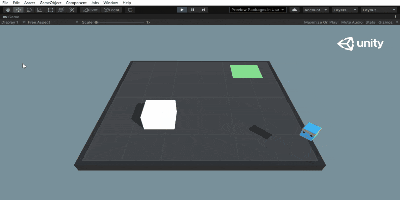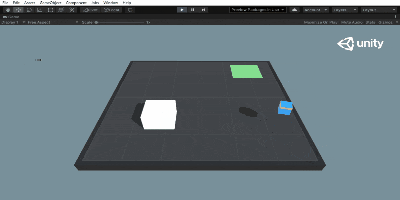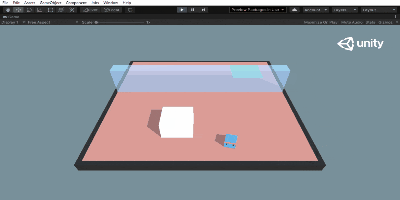
この状態でUnity Editor上でPlayボタン(▶)を押せば、学習したネットワークを用いて行動します。
こんな感じ。さっきと比べてまったくタスクをこなせていませんね。でも飛び跳ねてるのかわいい。
まとめ
- ML-Agentsのインストール
- 学習
- 学習ファイルの適用
をしました。もっといろいろできそうですね。
でもなんというか、この技術を使ってもプレイヤーと協力するAgentはなかなか作れなさそうな気がする。
自分で環境作ったりしてみますかぁ。