初めに
Elasticsearchのanalyzerを使用することで簡単に形態素解析を行うことが可能です。
今回は簡単な例を挙げながら、Elasticsearchっていいよね!!って布教して行こうと思います。
また、今回出てくるAPIリクエストは、Kibana の Dev Toolsで基本的に実行しています。
何も考えず形態素解析をしてみよう。
まず、indexを作成。( 日本語の形態素解析ができないのでダメダメという肩書を与えます。)
PUT /damedame_analyzer/
今回は全て以下の文章を形態素解析していきます。
私は、今年25歳になりました。昼は仕事をして夜はお酒を飲んでいます。趣味はバイクです。
以下を実行します。
GET /damedame_analyzer/_analyzer
{
"analyzer": "standard",
"explain" : true,
"text": "私は、今年25歳になりました。昼は仕事をして夜はお酒を飲んでいます。趣味はバイクです。"
}
結果は、こちら
", "position" : 0, "bytes" : "[e7 a7 81]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "は", "start_offset" : 1, "end_offset" : 2, "type" : "", "position" : 1, "bytes" : "[e3 81 af]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "今", "start_offset" : 3, "end_offset" : 4, "type" : "", "position" : 2, "bytes" : "[e4 bb 8a]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "年", "start_offset" : 4, "end_offset" : 5, "type" : "", "position" : 3, "bytes" : "[e5 b9 b4]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "25", "start_offset" : 5, "end_offset" : 7, "type" : "", "position" : 4, "bytes" : "[32 35]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "歳", "start_offset" : 7, "end_offset" : 8, "type" : "", "position" : 5, "bytes" : "[e6 ad b3]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "に", "start_offset" : 8, "end_offset" : 9, "type" : "", "position" : 6, "bytes" : "[e3 81 ab]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "な", "start_offset" : 9, "end_offset" : 10, "type" : "", "position" : 7, "bytes" : "[e3 81 aa]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "り", "start_offset" : 10, "end_offset" : 11, "type" : "", "position" : 8, "bytes" : "[e3 82 8a]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "ま", "start_offset" : 11, "end_offset" : 12, "type" : "", "position" : 9, "bytes" : "[e3 81 be]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "し", "start_offset" : 12, "end_offset" : 13, "type" : "", "position" : 10, "bytes" : "[e3 81 97]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "た", "start_offset" : 13, "end_offset" : 14, "type" : "", "position" : 11, "bytes" : "[e3 81 9f]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "昼", "start_offset" : 15, "end_offset" : 16, "type" : "", "position" : 12, "bytes" : "[e6 98 bc]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "は", "start_offset" : 16, "end_offset" : 17, "type" : "", "position" : 13, "bytes" : "[e3 81 af]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "仕", "start_offset" : 17, "end_offset" : 18, "type" : "", "position" : 14, "bytes" : "[e4 bb 95]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "事", "start_offset" : 18, "end_offset" : 19, "type" : "", "position" : 15, "bytes" : "[e4 ba 8b]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "を", "start_offset" : 19, "end_offset" : 20, "type" : "", "position" : 16, "bytes" : "[e3 82 92]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "し", "start_offset" : 20, "end_offset" : 21, "type" : "", "position" : 17, "bytes" : "[e3 81 97]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "て", "start_offset" : 21, "end_offset" : 22, "type" : "", "position" : 18, "bytes" : "[e3 81 a6]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "夜", "start_offset" : 22, "end_offset" : 23, "type" : "", "position" : 19, "bytes" : "[e5 a4 9c]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "は", "start_offset" : 23, "end_offset" : 24, "type" : "", "position" : 20, "bytes" : "[e3 81 af]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "お", "start_offset" : 24, "end_offset" : 25, "type" : "", "position" : 21, "bytes" : "[e3 81 8a]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "酒", "start_offset" : 25, "end_offset" : 26, "type" : "", "position" : 22, "bytes" : "[e9 85 92]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "を", "start_offset" : 26, "end_offset" : 27, "type" : "", "position" : 23, "bytes" : "[e3 82 92]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "飲", "start_offset" : 27, "end_offset" : 28, "type" : "", "position" : 24, "bytes" : "[e9 a3 b2]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "ん", "start_offset" : 28, "end_offset" : 29, "type" : "", "position" : 25, "bytes" : "[e3 82 93]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "で", "start_offset" : 29, "end_offset" : 30, "type" : "", "position" : 26, "bytes" : "[e3 81 a7]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "い", "start_offset" : 30, "end_offset" : 31, "type" : "", "position" : 27, "bytes" : "[e3 81 84]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "ま", "start_offset" : 31, "end_offset" : 32, "type" : "", "position" : 28, "bytes" : "[e3 81 be]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "す", "start_offset" : 32, "end_offset" : 33, "type" : "", "position" : 29, "bytes" : "[e3 81 99]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "趣", "start_offset" : 34, "end_offset" : 35, "type" : "", "position" : 30, "bytes" : "[e8 b6 a3]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "味", "start_offset" : 35, "end_offset" : 36, "type" : "", "position" : 31, "bytes" : "[e5 91 b3]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "は", "start_offset" : 36, "end_offset" : 37, "type" : "", "position" : 32, "bytes" : "[e3 81 af]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "バイク", "start_offset" : 37, "end_offset" : 40, "type" : "", "position" : 33, "bytes" : "[e3 83 90 e3 82 a4 e3 82 af]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "で", "start_offset" : 40, "end_offset" : 41, "type" : "", "position" : 34, "bytes" : "[e3 81 a7]", "positionLength" : 1, "termFrequency" : 1 }, { "token" : "す", "start_offset" : 41, "end_offset" : 42, "type" : "", "position" : 35, "bytes" : "[e3 81 99]", "positionLength" : 1, "termFrequency" : 1 } ] } } }Elasticsearchは、標準では形態素解析を日本語では行えません。
( 全て一文字で解析されてしまいます。)
なので、 Elasticsearchのpluginである。kuromoji を利用します。
(その他、 sudachiなどがあります。)
kuromoji
kuromoji を使って形態素解析をしよう。
indexを新しく作成します。
ここでは、damedame_analyzerの時と違いsettingsでanalyzerをkuromojiに指定します。
PUT /iketeru_analyzer/
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"iketeru_analyzer" : {
"tokenizer" : "kuromoji_tokenizer"
}
}
}
}
}
}
では、同様に形態素解析しましょう。
GET /iketeru_analyzer/_analyze
{
"analyzer": "iketeru_analyzer",
"explain" : true,
"text": "私は、今年25歳になりました。昼は仕事をして夜はお酒を飲んでいます。趣味はバイクです。"
}
結果はこちら
{ "detail" : { "custom_analyzer" : true, "charfilters" : [ ], "tokenizer" : { "name" : "kuromoji_tokenizer", "tokens" : [ { "token" : "私", "start_offset" : 0, "end_offset" : 1, "type" : "word", "position" : 0, "baseForm" : null, "bytes" : "[e7 a7 81]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-代名詞-一般", "partOfSpeech (en)" : "noun-pronoun-misc", "positionLength" : 1, "pronunciation" : "ワタシ", "pronunciation (en)" : "watashi", "reading" : "ワタシ", "reading (en)" : "watashi", "termFrequency" : 1 }, { "token" : "は", "start_offset" : 1, "end_offset" : 2, "type" : "word", "position" : 1, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "今年", "start_offset" : 3, "end_offset" : 5, "type" : "word", "position" : 2, "baseForm" : null, "bytes" : "[e4 bb 8a e5 b9 b4]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-副詞可能", "partOfSpeech (en)" : "noun-adverbial", "positionLength" : 1, "pronunciation" : "コトシ", "pronunciation (en)" : "kotoshi", "reading" : "コトシ", "reading (en)" : "kotoshi", "termFrequency" : 1 }, { "token" : "25", "start_offset" : 5, "end_offset" : 7, "type" : "word", "position" : 3, "baseForm" : null, "bytes" : "[32 35]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-数", "partOfSpeech (en)" : "noun-numeric", "positionLength" : 1, "pronunciation" : null, "pronunciation (en)" : null, "reading" : null, "reading (en)" : null, "termFrequency" : 1 }, { "token" : "歳", "start_offset" : 7, "end_offset" : 8, "type" : "word", "position" : 4, "baseForm" : null, "bytes" : "[e6 ad b3]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-接尾-助数詞", "partOfSpeech (en)" : "noun-suffix-classifier", "positionLength" : 1, "pronunciation" : "サイ", "pronunciation (en)" : "sai", "reading" : "サイ", "reading (en)" : "sai", "termFrequency" : 1 }, { "token" : "に", "start_offset" : 8, "end_offset" : 9, "type" : "word", "position" : 5, "baseForm" : null, "bytes" : "[e3 81 ab]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-格助詞-一般", "partOfSpeech (en)" : "particle-case-misc", "positionLength" : 1, "pronunciation" : "ニ", "pronunciation (en)" : "ni", "reading" : "ニ", "reading (en)" : "ni", "termFrequency" : 1 }, { "token" : "なり", "start_offset" : 9, "end_offset" : 11, "type" : "word", "position" : 6, "baseForm" : "なる", "bytes" : "[e3 81 aa e3 82 8a]", "inflectionForm" : "連用形", "inflectionForm (en)" : "conjunctive", "inflectionType" : "五段・ラ行", "inflectionType (en)" : "5-row-cons-r", "partOfSpeech" : "動詞-自立", "partOfSpeech (en)" : "verb-main", "positionLength" : 1, "pronunciation" : "ナリ", "pronunciation (en)" : "nari", "reading" : "ナリ", "reading (en)" : "nari", "termFrequency" : 1 }, { "token" : "まし", "start_offset" : 11, "end_offset" : 13, "type" : "word", "position" : 7, "baseForm" : "ます", "bytes" : "[e3 81 be e3 81 97]", "inflectionForm" : "連用形", "inflectionForm (en)" : "conjunctive", "inflectionType" : "特殊・マス", "inflectionType (en)" : "special-masu", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "マシ", "pronunciation (en)" : "mashi", "reading" : "マシ", "reading (en)" : "mashi", "termFrequency" : 1 }, { "token" : "た", "start_offset" : 13, "end_offset" : 14, "type" : "word", "position" : 8, "baseForm" : null, "bytes" : "[e3 81 9f]", "inflectionForm" : "基本形", "inflectionForm (en)" : "base", "inflectionType" : "特殊・タ", "inflectionType (en)" : "special-da", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "タ", "pronunciation (en)" : "ta", "reading" : "タ", "reading (en)" : "ta", "termFrequency" : 1 }, { "token" : "昼", "start_offset" : 15, "end_offset" : 16, "type" : "word", "position" : 9, "baseForm" : null, "bytes" : "[e6 98 bc]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-副詞可能", "partOfSpeech (en)" : "noun-adverbial", "positionLength" : 1, "pronunciation" : "ヒル", "pronunciation (en)" : "hiru", "reading" : "ヒル", "reading (en)" : "hiru", "termFrequency" : 1 }, { "token" : "は", "start_offset" : 16, "end_offset" : 17, "type" : "word", "position" : 10, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "仕事", "start_offset" : 17, "end_offset" : 19, "type" : "word", "position" : 11, "baseForm" : null, "bytes" : "[e4 bb 95 e4 ba 8b]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-サ変接続", "partOfSpeech (en)" : "noun-verbal", "positionLength" : 1, "pronunciation" : "シゴト", "pronunciation (en)" : "shigoto", "reading" : "シゴト", "reading (en)" : "shigoto", "termFrequency" : 1 }, { "token" : "を", "start_offset" : 19, "end_offset" : 20, "type" : "word", "position" : 12, "baseForm" : null, "bytes" : "[e3 82 92]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-格助詞-一般", "partOfSpeech (en)" : "particle-case-misc", "positionLength" : 1, "pronunciation" : "ヲ", "pronunciation (en)" : "o", "reading" : "ヲ", "reading (en)" : "o", "termFrequency" : 1 }, { "token" : "し", "start_offset" : 20, "end_offset" : 21, "type" : "word", "position" : 13, "baseForm" : "する", "bytes" : "[e3 81 97]", "inflectionForm" : "連用形", "inflectionForm (en)" : "conjunctive", "inflectionType" : "サ変・スル", "inflectionType (en)" : "irregular-suru", "partOfSpeech" : "動詞-自立", "partOfSpeech (en)" : "verb-main", "positionLength" : 1, "pronunciation" : "シ", "pronunciation (en)" : "shi", "reading" : "シ", "reading (en)" : "shi", "termFrequency" : 1 }, { "token" : "て", "start_offset" : 21, "end_offset" : 22, "type" : "word", "position" : 14, "baseForm" : null, "bytes" : "[e3 81 a6]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-接続助詞", "partOfSpeech (en)" : "particle-conjunctive", "positionLength" : 1, "pronunciation" : "テ", "pronunciation (en)" : "te", "reading" : "テ", "reading (en)" : "te", "termFrequency" : 1 }, { "token" : "夜", "start_offset" : 22, "end_offset" : 23, "type" : "word", "position" : 15, "baseForm" : null, "bytes" : "[e5 a4 9c]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-副詞可能", "partOfSpeech (en)" : "noun-adverbial", "positionLength" : 1, "pronunciation" : "ヨル", "pronunciation (en)" : "yoru", "reading" : "ヨル", "reading (en)" : "yoru", "termFrequency" : 1 }, { "token" : "は", "start_offset" : 23, "end_offset" : 24, "type" : "word", "position" : 16, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "お", "start_offset" : 24, "end_offset" : 25, "type" : "word", "position" : 17, "baseForm" : null, "bytes" : "[e3 81 8a]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "接頭詞-名詞接続", "partOfSpeech (en)" : "prefix-nominal", "positionLength" : 1, "pronunciation" : "オ", "pronunciation (en)" : "o", "reading" : "オ", "reading (en)" : "o", "termFrequency" : 1 }, { "token" : "酒", "start_offset" : 25, "end_offset" : 26, "type" : "word", "position" : 18, "baseForm" : null, "bytes" : "[e9 85 92]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : "サケ", "pronunciation (en)" : "sake", "reading" : "サケ", "reading (en)" : "sake", "termFrequency" : 1 }, { "token" : "を", "start_offset" : 26, "end_offset" : 27, "type" : "word", "position" : 19, "baseForm" : null, "bytes" : "[e3 82 92]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-格助詞-一般", "partOfSpeech (en)" : "particle-case-misc", "positionLength" : 1, "pronunciation" : "ヲ", "pronunciation (en)" : "o", "reading" : "ヲ", "reading (en)" : "o", "termFrequency" : 1 }, { "token" : "飲ん", "start_offset" : 27, "end_offset" : 29, "type" : "word", "position" : 20, "baseForm" : "飲む", "bytes" : "[e9 a3 b2 e3 82 93]", "inflectionForm" : "連用タ接続", "inflectionForm (en)" : "conjunctive-ta-connection", "inflectionType" : "五段・マ行", "inflectionType (en)" : "5-row-cons-m", "partOfSpeech" : "動詞-自立", "partOfSpeech (en)" : "verb-main", "positionLength" : 1, "pronunciation" : "ノン", "pronunciation (en)" : "non", "reading" : "ノン", "reading (en)" : "non", "termFrequency" : 1 }, { "token" : "で", "start_offset" : 29, "end_offset" : 30, "type" : "word", "position" : 21, "baseForm" : null, "bytes" : "[e3 81 a7]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-接続助詞", "partOfSpeech (en)" : "particle-conjunctive", "positionLength" : 1, "pronunciation" : "デ", "pronunciation (en)" : "de", "reading" : "デ", "reading (en)" : "de", "termFrequency" : 1 }, { "token" : "い", "start_offset" : 30, "end_offset" : 31, "type" : "word", "position" : 22, "baseForm" : "いる", "bytes" : "[e3 81 84]", "inflectionForm" : "連用形", "inflectionForm (en)" : "conjunctive", "inflectionType" : "一段", "inflectionType (en)" : "1-row", "partOfSpeech" : "動詞-非自立", "partOfSpeech (en)" : "verb-auxiliary", "positionLength" : 1, "pronunciation" : "イ", "pronunciation (en)" : "i", "reading" : "イ", "reading (en)" : "i", "termFrequency" : 1 }, { "token" : "ます", "start_offset" : 31, "end_offset" : 33, "type" : "word", "position" : 23, "baseForm" : null, "bytes" : "[e3 81 be e3 81 99]", "inflectionForm" : "基本形", "inflectionForm (en)" : "base", "inflectionType" : "特殊・マス", "inflectionType (en)" : "special-masu", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "マス", "pronunciation (en)" : "masu", "reading" : "マス", "reading (en)" : "masu", "termFrequency" : 1 }, { "token" : "趣味", "start_offset" : 34, "end_offset" : 36, "type" : "word", "position" : 24, "baseForm" : null, "bytes" : "[e8 b6 a3 e5 91 b3]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : "シュミ", "pronunciation (en)" : "shumi", "reading" : "シュミ", "reading (en)" : "shumi", "termFrequency" : 1 }, { "token" : "は", "start_offset" : 36, "end_offset" : 37, "type" : "word", "position" : 25, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "バイク", "start_offset" : 37, "end_offset" : 40, "type" : "word", "position" : 26, "baseForm" : null, "bytes" : "[e3 83 90 e3 82 a4 e3 82 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : "バイク", "pronunciation (en)" : "baiku", "reading" : "バイク", "reading (en)" : "baiku", "termFrequency" : 1 }, { "token" : "です", "start_offset" : 40, "end_offset" : 42, "type" : "word", "position" : 27, "baseForm" : null, "bytes" : "[e3 81 a7 e3 81 99]", "inflectionForm" : "基本形", "inflectionForm (en)" : "base", "inflectionType" : "特殊・デス", "inflectionType (en)" : "special-desu", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "デス", "pronunciation (en)" : "desu", "reading" : "デス", "reading (en)" : "desu", "termFrequency" : 1 } ] }, "tokenfilters" : [ ] } }結果を見るとわかりますが、標準で行った時と違い。
きちんと形態素分析されている事がわかります。
また、読み仮名や品詞情報、動詞の原形などもわかるので文章内のそれぞれの単語を分類分けするのも
比較的簡単となります。(例 : 名詞だけ抽出、動詞の原形を抽出など )
もっと便利にしたい。
上記までで日本語の形態素分析が行える事がわかりました。
その上、品詞もわかって+動詞の原型もわかるのでだいぶ正規化された気がします。
もっと正規化したいです。
例えば、175㌢ => 175センチ (変な文字使うな)
CoMpuTer => computer (小文字で統一したい) などです。
そういったこともElasticsearchで可能です。
例文を変えます。
例文 : 私は老眼なのでCoMpuTerから50㌢は離れないと見えない。
先ほどので形態素解析をしてみましょう。
GET /iketeru_analyzer/_analyze
{
"analyzer": "iketeru_analyzer",
"explain" : true,
"text": "私は老眼なのでCoMpuTerから50㌢は離れないと見えない。"
}
結果はこちら
{ "detail" : { "custom_analyzer" : true, "charfilters" : [ ], "tokenizer" : { "name" : "kuromoji_tokenizer", "tokens" : [ { "token" : "私", "start_offset" : 0, "end_offset" : 1, "type" : "word", "position" : 0, "baseForm" : null, "bytes" : "[e7 a7 81]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-代名詞-一般", "partOfSpeech (en)" : "noun-pronoun-misc", "positionLength" : 1, "pronunciation" : "ワタシ", "pronunciation (en)" : "watashi", "reading" : "ワタシ", "reading (en)" : "watashi", "termFrequency" : 1 }, { "token" : "は", "start_offset" : 1, "end_offset" : 2, "type" : "word", "position" : 1, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "老眼", "start_offset" : 2, "end_offset" : 4, "type" : "word", "position" : 2, "baseForm" : null, "bytes" : "[e8 80 81 e7 9c bc]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : "ローガン", "pronunciation (en)" : "rogan", "reading" : "ロウガン", "reading (en)" : "rōgan", "termFrequency" : 1 }, { "token" : "な", "start_offset" : 4, "end_offset" : 5, "type" : "word", "position" : 3, "baseForm" : "だ", "bytes" : "[e3 81 aa]", "inflectionForm" : "体言接続", "inflectionForm (en)" : "uninflected-connection", "inflectionType" : "特殊・ダ", "inflectionType (en)" : "special-ta", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "ナ", "pronunciation (en)" : "na", "reading" : "ナ", "reading (en)" : "na", "termFrequency" : 1 }, { "token" : "ので", "start_offset" : 5, "end_offset" : 7, "type" : "word", "position" : 4, "baseForm" : null, "bytes" : "[e3 81 ae e3 81 a7]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-接続助詞", "partOfSpeech (en)" : "particle-conjunctive", "positionLength" : 1, "pronunciation" : "ノデ", "pronunciation (en)" : "node", "reading" : "ノデ", "reading (en)" : "node", "termFrequency" : 1 }, { "token" : "CoMpuTer", "start_offset" : 7, "end_offset" : 15, "type" : "word", "position" : 5, "baseForm" : null, "bytes" : "[43 6f 4d 70 75 54 65 72]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : null, "pronunciation (en)" : null, "reading" : null, "reading (en)" : null, "termFrequency" : 1 }, { "token" : "から", "start_offset" : 15, "end_offset" : 17, "type" : "word", "position" : 6, "baseForm" : null, "bytes" : "[e3 81 8b e3 82 89]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-格助詞-一般", "partOfSpeech (en)" : "particle-case-misc", "positionLength" : 1, "pronunciation" : "カラ", "pronunciation (en)" : "kara", "reading" : "カラ", "reading (en)" : "kara", "termFrequency" : 1 }, { "token" : "50", "start_offset" : 17, "end_offset" : 19, "type" : "word", "position" : 7, "baseForm" : null, "bytes" : "[35 30]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-数", "partOfSpeech (en)" : "noun-numeric", "positionLength" : 1, "pronunciation" : null, "pronunciation (en)" : null, "reading" : null, "reading (en)" : null, "termFrequency" : 1 }, { "token" : "は", "start_offset" : 20, "end_offset" : 21, "type" : "word", "position" : 8, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "離れ", "start_offset" : 21, "end_offset" : 23, "type" : "word", "position" : 9, "baseForm" : "離れる", "bytes" : "[e9 9b a2 e3 82 8c]", "inflectionForm" : "未然形", "inflectionForm (en)" : "imperfective", "inflectionType" : "一段", "inflectionType (en)" : "1-row", "partOfSpeech" : "動詞-自立", "partOfSpeech (en)" : "verb-main", "positionLength" : 1, "pronunciation" : "ハナレ", "pronunciation (en)" : "hanare", "reading" : "ハナレ", "reading (en)" : "hanare", "termFrequency" : 1 }, { "token" : "ない", "start_offset" : 23, "end_offset" : 25, "type" : "word", "position" : 10, "baseForm" : null, "bytes" : "[e3 81 aa e3 81 84]", "inflectionForm" : "基本形", "inflectionForm (en)" : "base", "inflectionType" : "特殊・ナイ", "inflectionType (en)" : "special-nai", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "ナイ", "pronunciation (en)" : "nai", "reading" : "ナイ", "reading (en)" : "nai", "termFrequency" : 1 }, { "token" : "と", "start_offset" : 25, "end_offset" : 26, "type" : "word", "position" : 11, "baseForm" : null, "bytes" : "[e3 81 a8]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-格助詞-引用", "partOfSpeech (en)" : "particle-case-quote", "positionLength" : 1, "pronunciation" : "ト", "pronunciation (en)" : "to", "reading" : "ト", "reading (en)" : "to", "termFrequency" : 1 }, { "token" : "見え", "start_offset" : 26, "end_offset" : 28, "type" : "word", "position" : 12, "baseForm" : "見える", "bytes" : "[e8 a6 8b e3 81 88]", "inflectionForm" : "未然形", "inflectionForm (en)" : "imperfective", "inflectionType" : "一段", "inflectionType (en)" : "1-row", "partOfSpeech" : "動詞-自立", "partOfSpeech (en)" : "verb-main", "positionLength" : 1, "pronunciation" : "ミエ", "pronunciation (en)" : "mie", "reading" : "ミエ", "reading (en)" : "mie", "termFrequency" : 1 }, { "token" : "ない", "start_offset" : 28, "end_offset" : 30, "type" : "word", "position" : 13, "baseForm" : null, "bytes" : "[e3 81 aa e3 81 84]", "inflectionForm" : "基本形", "inflectionForm (en)" : "base", "inflectionType" : "特殊・ナイ", "inflectionType (en)" : "special-nai", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "ナイ", "pronunciation (en)" : "nai", "reading" : "ナイ", "reading (en)" : "nai", "termFrequency" : 1 } ] }, "tokenfilters" : [ ] } }結果を見ると、㌢(環境依存文字)は無視され、CoMpuTerは、そのままlowercaseなどされることなく出力されています。
このままだと、データとしては使いづらいかもです。
そこで、Elasticsearchのchar_filterを利用します。
char_filterとは、今まで行っていたtokenizerの前に文字列を正規化( 前処理 )するものです。
イメージは、以下です。
( また、tokenizerで分割後の要素を正規化する token_filterというのも存在しますが割愛します。 )
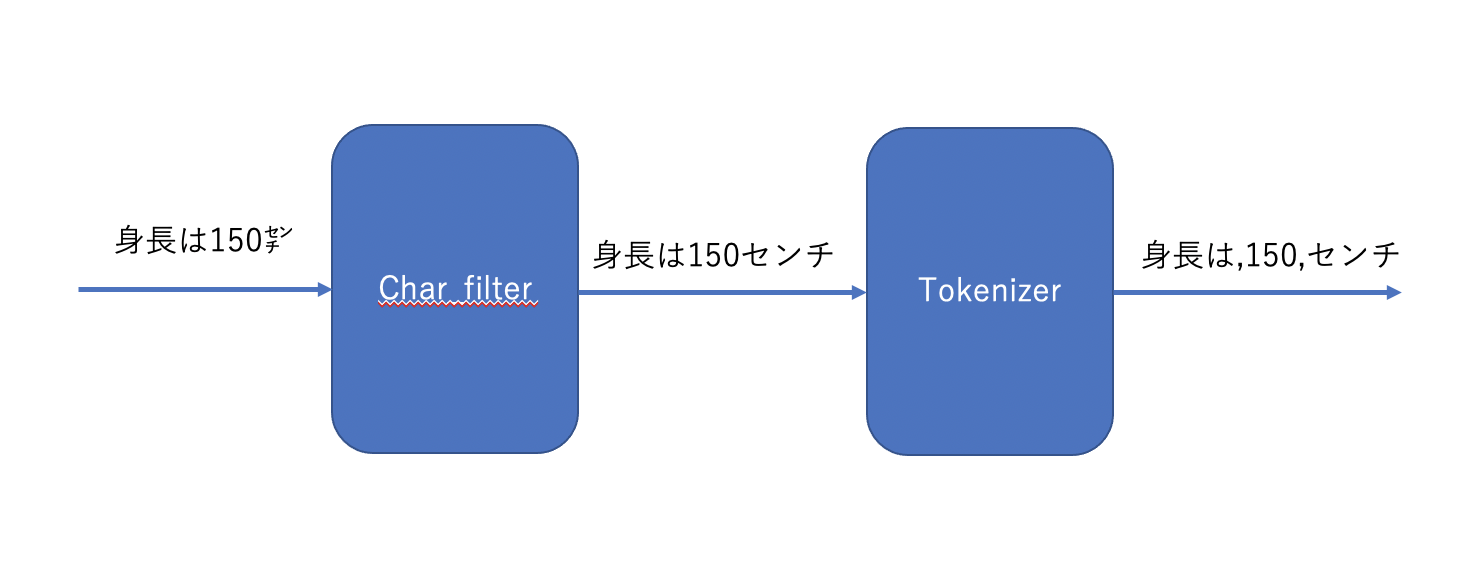
では、実際にindex作成して実行します。
PUT /motto_iketeru_analyzer/
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"motto_iketeru_analyzer" : {
"tokenizer" : "kuromoji_tokenizer",
"char_filter" : [ "icu_normalizer" ]
}
}
}
}
}
}
GET /motto_iketeru_analyzer/_analyze
{
"analyzer": "motto_iketeru_analyzer",
"explain" : true,
"text": "私は老眼なのでCoMpuTerから50㌢は離れないと見えない。"
}
結果はこちら
{ "detail" : { "custom_analyzer" : true, "charfilters" : [ { "name" : "icu_normalizer", "filtered_text" : [ "私は老眼なので" ] } ], "tokenizer" : { "name" : "kuromoji_tokenizer", "tokens" : [ { "token" : "私", "start_offset" : 0, "end_offset" : 1, "type" : "word", "position" : 0, "baseForm" : null, "bytes" : "[e7 a7 81]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-代名詞-一般", "partOfSpeech (en)" : "noun-pronoun-misc", "positionLength" : 1, "pronunciation" : "ワタシ", "pronunciation (en)" : "watashi", "reading" : "ワタシ", "reading (en)" : "watashi", "termFrequency" : 1 }, { "token" : "は", "start_offset" : 1, "end_offset" : 2, "type" : "word", "position" : 1, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "老眼", "start_offset" : 2, "end_offset" : 4, "type" : "word", "position" : 2, "baseForm" : null, "bytes" : "[e8 80 81 e7 9c bc]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : "ローガン", "pronunciation (en)" : "rogan", "reading" : "ロウガン", "reading (en)" : "rōgan", "termFrequency" : 1 }, { "token" : "な", "start_offset" : 4, "end_offset" : 5, "type" : "word", "position" : 3, "baseForm" : "だ", "bytes" : "[e3 81 aa]", "inflectionForm" : "体言接続", "inflectionForm (en)" : "uninflected-connection", "inflectionType" : "特殊・ダ", "inflectionType (en)" : "special-ta", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "ナ", "pronunciation (en)" : "na", "reading" : "ナ", "reading (en)" : "na", "termFrequency" : 1 }, { "token" : "ので", "start_offset" : 5, "end_offset" : 7, "type" : "word", "position" : 4, "baseForm" : null, "bytes" : "[e3 81 ae e3 81 a7]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-接続助詞", "partOfSpeech (en)" : "particle-conjunctive", "positionLength" : 1, "pronunciation" : "ノデ", "pronunciation (en)" : "node", "reading" : "ノデ", "reading (en)" : "node", "termFrequency" : 1 }, { "token" : "computer", "start_offset" : 7, "end_offset" : 15, "type" : "word", "position" : 5, "baseForm" : null, "bytes" : "[63 6f 6d 70 75 74 65 72]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-一般", "partOfSpeech (en)" : "noun-common", "positionLength" : 1, "pronunciation" : null, "pronunciation (en)" : null, "reading" : null, "reading (en)" : null, "termFrequency" : 1 }, { "token" : "から", "start_offset" : 15, "end_offset" : 17, "type" : "word", "position" : 6, "baseForm" : null, "bytes" : "[e3 81 8b e3 82 89]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-格助詞-一般", "partOfSpeech (en)" : "particle-case-misc", "positionLength" : 1, "pronunciation" : "カラ", "pronunciation (en)" : "kara", "reading" : "カラ", "reading (en)" : "kara", "termFrequency" : 1 }, { "token" : "50", "start_offset" : 17, "end_offset" : 19, "type" : "word", "position" : 7, "baseForm" : null, "bytes" : "[35 30]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-数", "partOfSpeech (en)" : "noun-numeric", "positionLength" : 1, "pronunciation" : null, "pronunciation (en)" : null, "reading" : null, "reading (en)" : null, "termFrequency" : 1 }, { "token" : "センチ", "start_offset" : 19, "end_offset" : 20, "type" : "word", "position" : 8, "baseForm" : null, "bytes" : "[e3 82 bb e3 83 b3 e3 83 81]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "名詞-接尾-助数詞", "partOfSpeech (en)" : "noun-suffix-classifier", "positionLength" : 1, "pronunciation" : "センチ", "pronunciation (en)" : "senchi", "reading" : "センチ", "reading (en)" : "senchi", "termFrequency" : 1 }, { "token" : "は", "start_offset" : 20, "end_offset" : 21, "type" : "word", "position" : 9, "baseForm" : null, "bytes" : "[e3 81 af]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-係助詞", "partOfSpeech (en)" : "particle-dependency", "positionLength" : 1, "pronunciation" : "ワ", "pronunciation (en)" : "wa", "reading" : "ハ", "reading (en)" : "ha", "termFrequency" : 1 }, { "token" : "離れ", "start_offset" : 21, "end_offset" : 23, "type" : "word", "position" : 10, "baseForm" : "離れる", "bytes" : "[e9 9b a2 e3 82 8c]", "inflectionForm" : "未然形", "inflectionForm (en)" : "imperfective", "inflectionType" : "一段", "inflectionType (en)" : "1-row", "partOfSpeech" : "動詞-自立", "partOfSpeech (en)" : "verb-main", "positionLength" : 1, "pronunciation" : "ハナレ", "pronunciation (en)" : "hanare", "reading" : "ハナレ", "reading (en)" : "hanare", "termFrequency" : 1 }, { "token" : "ない", "start_offset" : 23, "end_offset" : 25, "type" : "word", "position" : 11, "baseForm" : null, "bytes" : "[e3 81 aa e3 81 84]", "inflectionForm" : "基本形", "inflectionForm (en)" : "base", "inflectionType" : "特殊・ナイ", "inflectionType (en)" : "special-nai", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "ナイ", "pronunciation (en)" : "nai", "reading" : "ナイ", "reading (en)" : "nai", "termFrequency" : 1 }, { "token" : "と", "start_offset" : 25, "end_offset" : 26, "type" : "word", "position" : 12, "baseForm" : null, "bytes" : "[e3 81 a8]", "inflectionForm" : null, "inflectionForm (en)" : null, "inflectionType" : null, "inflectionType (en)" : null, "partOfSpeech" : "助詞-格助詞-引用", "partOfSpeech (en)" : "particle-case-quote", "positionLength" : 1, "pronunciation" : "ト", "pronunciation (en)" : "to", "reading" : "ト", "reading (en)" : "to", "termFrequency" : 1 }, { "token" : "見え", "start_offset" : 26, "end_offset" : 28, "type" : "word", "position" : 13, "baseForm" : "見える", "bytes" : "[e8 a6 8b e3 81 88]", "inflectionForm" : "未然形", "inflectionForm (en)" : "imperfective", "inflectionType" : "一段", "inflectionType (en)" : "1-row", "partOfSpeech" : "動詞-自立", "partOfSpeech (en)" : "verb-main", "positionLength" : 1, "pronunciation" : "ミエ", "pronunciation (en)" : "mie", "reading" : "ミエ", "reading (en)" : "mie", "termFrequency" : 1 }, { "token" : "ない", "start_offset" : 28, "end_offset" : 30, "type" : "word", "position" : 14, "baseForm" : null, "bytes" : "[e3 81 aa e3 81 84]", "inflectionForm" : "基本形", "inflectionForm (en)" : "base", "inflectionType" : "特殊・ナイ", "inflectionType (en)" : "special-nai", "partOfSpeech" : "助動詞", "partOfSpeech (en)" : "auxiliary-verb", "positionLength" : 1, "pronunciation" : "ナイ", "pronunciation (en)" : "nai", "reading" : "ナイ", "reading (en)" : "nai", "termFrequency" : 1 } ] }, "tokenfilters" : [ ] } }結果を見ると、
CoMpuTerは、computerに変換され、㌢は、センチへ変換され
より使いやすいデータが取り出せるようになりました。
最後に
Elasticsearchのanalyzerは簡易に形態素解析をする際にとても便利ですが奥が深く結構大変です。
もっと勉強しないとダメですね😢