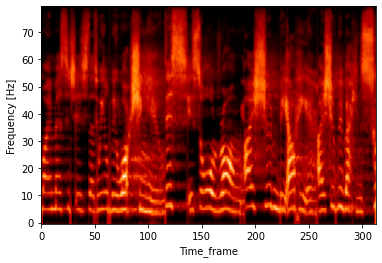
N-cross法
ILRMAによる、音声を対象としたブラインド音源分離(BASS)を適応した際、音声が完全分離(対象としていない話者の音声をゼロにする)ではなく抑制された分離となってしまったので、こういった音声でも{VAD}できるように考案した手法です。N-cross法という名前は私が適当に付けた名前なので、検索しても多分参考文献は出てこないと思います。
目的としてはVAD用のデータセットを作るときにしゃべってない区間が不要なのでこれをなんとか取り除きたいという重いです。
概要
音声の発話区間検出(voice activity detection: VAD)に用いられるゼロ交差法という手法が有りますがこれは耐騒音に弱いので、一般的には混合ガウス分布モデル (Gaussian mixture model; GMM) に基づくフレーム単位の音声・非音声識別に基づく区間検出が行われています。しかし今回のILRMAにより分離された音源では目的としない音声に対して音圧レベルの抑制は可能ではありますが完全にゼロにはできないので、GMMによる手法では必要のない部分の音声まで発話区間として扱ってしまいます。そこで背景に音声が存在していても目的とする音声を検出できる方法を実装しました。今回この手法を 「N-cross法」 と呼ぶことにします。この手法は今回のような使い方だけではなく、例えばカフェでの商談など外部の音声が混入しやすい状況であったり、音源にBGMが入ってしまった時などにも使えると思います。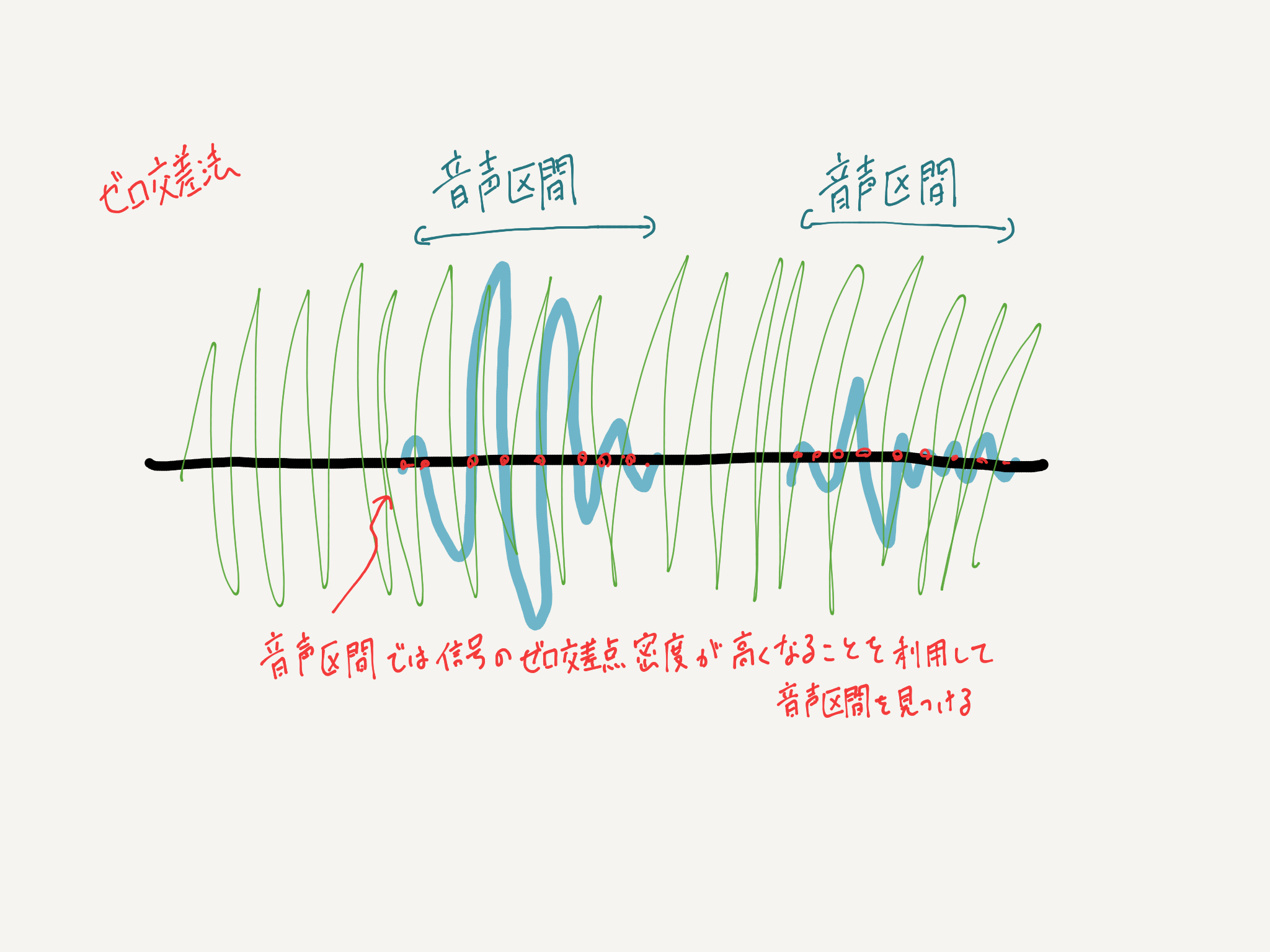
理論
理論としては単純で、ゼロ交差法では音声波形に対してY=0のラインでの交差頻度が高い区間を発話区間として検出しますが、この方法では小さな音声でも検出されてしまうので、N-cross法では任意のY=Nの値での交差点を利用します。このNの値をN-cross Lineあるいは感度と呼ぶことにします。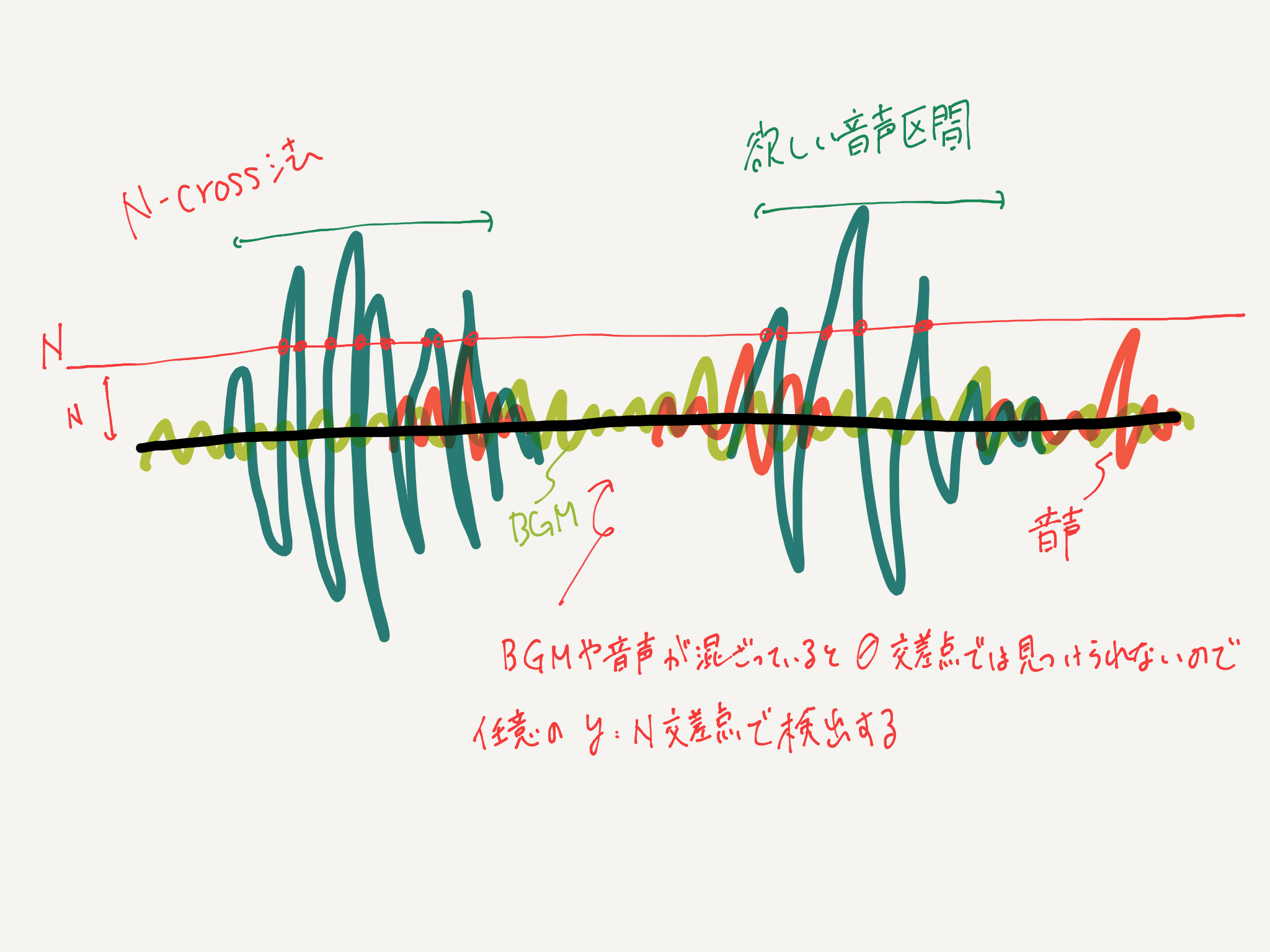
実装
Pythonで実装しました。ColabとかJupyterで動かしてください。
import numpy as np
from tqdm import tqdm
import librosa
def NcrossVAD(data,N=0.02,frame = 320,threshold = 0.99):
"""
VAD for Ncross Method
'''
data :音声データ(ndarray)
N :N-Crossライン.背景ノイズの大きさにあわせて決めてあげてください(0~1)
frame :分析窓.この範囲でどれくらいN-Crossライン上の正負が切り替わったかを分析します
threshold :分析窓の中でどのくらい正負が切り替われば音声とみなすかの閾値です(0~1)
return ノイズ部分がバッサリ切られたデータ
"""
data /= np.max(np.abs(data))
data += N
data_pad1 = np.sign(np.pad(data, [0,1], 'constant'))
data_pad2 = np.sign(np.pad(data, [1,0], 'constant'))
dif = data_pad1-data_pad2
zerocross_list = np.where(dif==0, 1, 0)[:-1]
cnt = len(zerocross_list)
ret=[]
zero_cross=[]
for i in tqdm(range(int(cnt/frame))):
seg = zerocross_list[i*frame:(i+1)*frame]
add = np.sum(seg)/frame
if add < threshold:
ret.append(data[i*frame:(i+1)*frame])
zero_cross.append(1)
else:
zero_cross.append(0)
return np.concatenate(ret)
data, sr = librosa.load("vadtest.wav",sr=32000)
ret = NcrossVAD(data,N=0.02,frame = 320,threshold = 0.99)
実行するとYouTuberみたいな喋ってない部分をばさばさカットしたみたいな音声が出てきます
元の音声
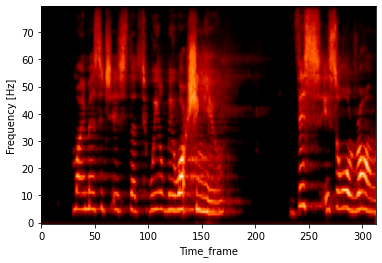
VADしたあとの音声