はじめに
この記事はPython-Sounddevice ASIOで使える音響信号処理モジュール[基本編]の続きになっています。sounddeviceを使う前の準備から使う上での初期設定の方法、そしてsounddeviceでの基本的な再生方法、録音方法、同時録音再生方法、ストリーミングの方法についてはこちらをご覧ください。
この記事で扱う項目
この記事ではsounddeviceによるチャンネルマッピングの方法(マルチチャンネル環境で好きなマイクから入力、好きなスピーカから出力する方法)について書いていきたいと思います。
詳しくはこちらを参照してください
Python sounddevice公式
追記
アップデートに伴って、操作がより簡単になったようです。
以下の記事はより昔のバージョンについての説明となっていますので、公式ドキュメントを確認してください。
チャンネルマッピングの基本的な方法
例えばこのようなスピーカーアレイがあったとします

5チャンネルの音源を5チャンネル分のスピーカーから順番に出力したい場合はsounddevice側が自動でチャンネルを割り振ってくれるので問題ありません。
1チャンネルの音源を任意のスピーカー(今回は3番目のスピーカー)1チャンネルから出力したい場合は次のようにします。
out = [-1,-1,0,-1,-1]
sd.play(..., mapping = out ,...)
次に、3チャンネルの音源を任意のスピーカー(今回は2番目、3番目、5番目のスピーカ)3チャンネルから出力したい場合は次のようにします。
out = [-1,0,1,-1,2]
sd.play(..., mapping = out ,...)
つまり出力したくないスピーカには[-1]、出力したいスピーカには0ベースで[0][1][2]..を当てたリストを作ってmappingに入れてやれば割り振ってくれます。また、
out = [-1,1,0,-1,2]
sd.play(..., mapping = out ,...)
としてやれば音を出すスピーカーの順番を変えられます。
APIごとの設定
ASIO、Core Audio、WASAPIなど固有のAPIを通じて入出力をコントロールする場合の設定方法について説明します。現在自分のマシンがサポートしているAPIを確認するには使用機材の初期設定か次のコマンドを試してください。
sd.query_hostapis(index=None)
戻り値
({'name': 'Core Audio',
'devices': [0, 1, 2],
'default_input_device': 0,
'default_output_device': 1},)
ASIO
ASIOでのチャンネルマッピングの設定はこちら。
スピーカー出力が5チャンネル、マイク入力が2チャンネルの環境があるとしてこれを制御します。
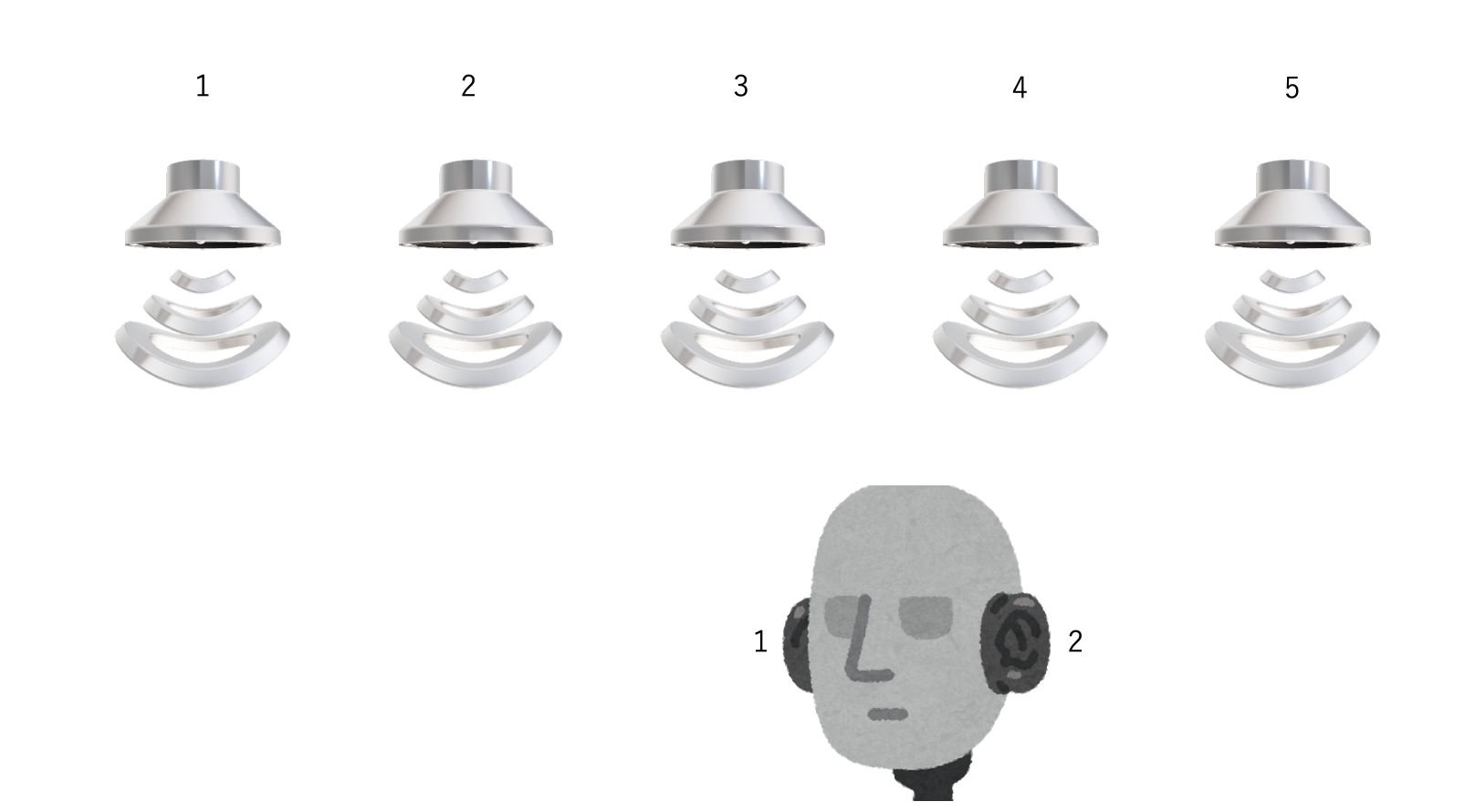
out = [0,1,2,3,4]
in = [0,1]
asio_out = sd.AsioSettings(channel_map = out)
asio_in = sd.AsioSettings(channel_map = in)
# 再生
sd.play(..., extra_settings=asio_out)
# 録音
recdata = sd.rec(..., channels=2, extra_settings=asio_in,...)
# 同時録音再生
recdata = sd.playrec(...,channels=2, extra_settings=(asio_in,asio_out),... )
extra_settingについてはずっと同じ設定を使うことが分かっているならデフォルトとして設定することもできます。
out = [0,1,2,3,4]
in = [0,1]
asio_out = sd.AsioSettings(channel_map = out)
asio_in = sd.AsioSettings(channel_map = in)
sd.default.extra_settings = (asio_in,asio_out)
Core Audio
やり方についてはASIOの時とほとんど一緒です
out = [0,1,2,3,4]
in = [0,1]
ca_out = sd.CoreAudioSettings(channel_map = out)
ca_in = sd.CoreAudioSettings(channel_map = in)
# 再生
sd.play(..., extra_settings=ca_out)
# 録音
recdata = sd.rec(..., channels=2, extra_settings=ca_in,...)
# 同時録音再生
recdata = sd.playrec(...,channels=2, extra_settings=(ca_in,ca_out),... )
WASAPI
WASAPIの場合も一緒です
out = [0,1,2,3,4]
in = [0,1]
wasapi_out = sd.WasapiSettings(channel_map = out)
wasapi_in = sd.WasapiSettings(channel_map = in)
# 再生
sd.play(..., extra_settings=wasapi_out)
# 録音
recdata = sd.rec(..., channels=2, extra_settings=wasapi_in,...)
# 同時録音再生
recdata = sd.playrec(...,channels=2, extra_settings=(wasapi_in,wasapi_out),... )
最後に
これにてsounddeviceについての説明は以上です。願わくばsounddeviceユーザがこの世に増えsounddeviceを使ったいろんな超便利最強プログラムが世界に溢れることを祈って終了したいと思います。
最後に私が使ったマルチチャンネルスピーカアレイからダミーヘッドまでのインパルス応答をDAWソフトなどを通さずに自動で求めるプログラムをぶん投げてお別れとします。お疲れ様でした。
サンプル インパルス応答測定プログラム
解説記事は気が向いたら書きますが多分これを使う人は解説なんていらないよね...
import numpy as np
import scipy as sp
import sounddevice as sd
import wave
import struct
# Setting
Fs=44100
small=1000000 #small分の一の音量に調節 用意したwavファイルの音がでかすぎたので
# sounddevise Setting
sd.default.samplerate=Fs
print(sd.query_devices())
# 接続されているデバイスの一覧が出るのでデバイスIDを入力してください
deviceNo = input("Please enter the ID of the device to use :" )
sd.default.device = int(deviceNo)
area = 1
# mapping
out1 = sd.CoreAudioSettings(channel_map=[0,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1])
out2 = sd.CoreAudioSettings(channel_map=[-1,0,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1])
out3 = sd.CoreAudioSettings(channel_map=[-1,-1,0,-1,-1,-1,-1,-1,-1,-1,-1,-1])
out4 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,0,-1,-1,-1,-1,-1,-1,-1,-1])
out5 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,0,-1,-1,-1,-1,-1,-1,-1])
out6 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,-1,0,-1,-1,-1,-1,-1,-1])
out7 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,-1,-1,0,-1,-1,-1,-1,-1])
out8 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,-1,-1,-1,0,-1,-1,-1,-1])
out9 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,-1,-1,-1,-1,0,-1,-1,-1])
out10 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,-1,-1,-1,-1,-1,0,-1,-1])
out11 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,0,-1])
out12 = sd.CoreAudioSettings(channel_map=[-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,-1,0])
ca_in = sd.CoreAudioSettings(channel_map=[0,1])
def wavread(filename):#Reading 16bit WAVE files
wf = wave.open(filename,'rb')
buf = wf.readframes(wf.getnframes())
data = np.frombuffer(buf, dtype = "int16")
return data
TSP=wavread("tsp.wav")/small
# ホワイトノイズか、Swept Sine信号(TSP)信号を入れてください
# Convolution インパルス応答を計算します
def IR(rTSPdata,outputfilename):
rTSPdata=rTSPdata.T
ipls=np.real(sp.ifft(sp.fft(rTSPdata)*sp.fft(np.flipud(TSP),rTSPdata.size)))
c=np.fft.fftshift(ipls/max(ipls))
int16amp=32768 / int(c.max())
y2 = np.array([c * int16amp],dtype = "int16")[0]
y4 = struct.pack("h" * len(y2), *y2)
w = wave.Wave_write(outputfilename)
w.setparams((
1, # channel
2, # byte width
44100, # sampling rate
len(y4), # number of frames
"NONE", "NONE" # no compression
))
w.writeframesraw(y4)
w.close()
# Playrec
def PlayRec(outmap,IDnumber):
#sd.play(TSP,Fs,extra_settings=outmap,blocking=True)
TSP1=sd.playrec(TSP,Fs,channels=2,extra_settings=(ca_in,outmap),blocking=True)
TSP2=sd.playrec(TSP,Fs,channels=2,extra_settings=(ca_in,outmap),blocking=True)
TSP3=sd.playrec(TSP,Fs,channels=2,extra_settings=(ca_in,outmap),blocking=True)
#加算重合を行っていますが、最近では長めのホワイトノイズかSwept Sine信号(TSP信号)を用意して
#加算重合せずに一発で求めてしまうのが主流らしいですよ。
rTSP = TSP1 + TSP2 + TSP3
#録った応答を反転させてIRを求めます
rTSP1 = rTSP[:,0]
rTSP2 = rTSP[:,1]
rTSP3 = rTSP[:,2]
rTSP4 = rTSP[:,3]
rTSP5 = rTSP[:,4]
rTSP6 = rTSP[:,5]
rTSP7 = rTSP[:,6]
rTSP8 = rTSP[:,7]
rTSP9 = rTSP[:,8]
rTSP10 = rTSP[:,9]
#出来上がったインパルス応答に名前をつけてWAVファイルでフォルダに書き出します
IR(rTSP1,"IR"+str(IDnumber)+"1.wav")
IR(rTSP2,"IR"+str(IDnumber)+"2.wav")
IR(rTSP3,"IR"+str(IDnumber)+"3.wav")
IR(rTSP4,"IR"+str(IDnumber)+"4.wav")
IR(rTSP5,"IR"+str(IDnumber)+"5.wav")
IR(rTSP6,"IR"+str(IDnumber)+"6.wav")
IR(rTSP7,"IR"+str(IDnumber)+"7.wav")
IR(rTSP8,"IR"+str(IDnumber)+"8.wav")
IR(rTSP9,"IR"+str(IDnumber)+"9.wav")
IR(rTSP10,"IR"+str(IDnumber)+"10.wav")
print("測定開始")
PlayRec(out1,1)
PlayRec(out2,2)
PlayRec(out3,3)
PlayRec(out4,4)
PlayRec(out5,5)
PlayRec(out6,6)
PlayRec(out7,7)
PlayRec(out8,8)
PlayRec(out9,9)
PlayRec(out10,10)
PlayRec(out11,11)
PlayRec(out12,12)
print("測定終了")
リファレンス
Python sounddevice公式
Python-Sounddevice ASIOで使える音響信号処理モジュール[基本編]