最近RPAを初めて触ったのですがその際に詰まった事があり、参考記事が少なかったので共有します。
依頼された要件は毎日手動更新しているものがあるので、スクレイピングをして自動化してほしいという内容です。(対象は自社サイト)
automation anywhereを使用して作成する事も要件にあり、これのみで作成しています。
作成したものの全容です。
csvのURLからサイトの特定のtextを取得してcsvに格納、更新するというものです。
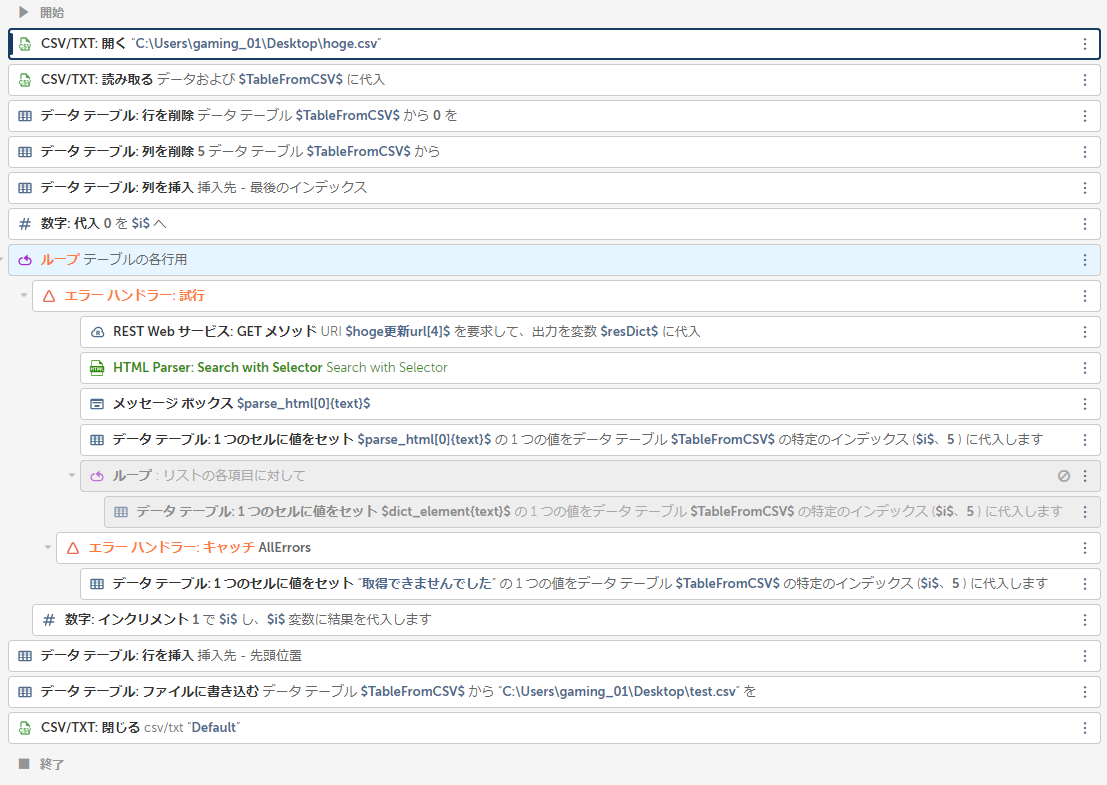
csv読み込み → URLにリクエスト → 特定の値を取得する → csv更新
アクションの解説をしていきます。
csv,ループなど..プログラムの構文と同じ感じで使用できます。
REST アクションではheader、プロキシなど設定ができます。
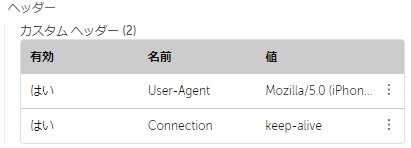
モバイルからのアクセスが必要、URLリストが同一オリジンだった為
User-Agentとkeep-alive(HTTP/1.0の場合)を付与して送信します。
追記: 9/02
HTTP keep-alive
クライアントが接続を開いておく意思があることを示します。接続の維持は HTTP/1.1 の既定の動作です。ヘッダー名のリストは、介在する最初の非透過プロキシーやキャッシュが削除するヘッダーの名前です。既定でした
警告: Connection や Keep-Alive などの接続固有のヘッダーフィールドは、HTTP/2 では禁止されています。Chrome と Firefox は HTTP/2 レスポンスでそれらを無視しますが、Safari は HTTP/2 仕様の要件に準拠しているため、それらを含むレスポンスを読み込みません。
https://developer.mozilla.org/ja/docs/Web/HTTP/Headers/Connection
また最後の通信でConnection: closeを付与するとより早く通信を切断でき、
サーバの負荷を軽減して丁寧かもしれません。(keepalive_timeout値を確認)
またブラウザからもタイムアウト値はせっていでき、ブラウザのタイムアウト値はサーバーより短くしておきます
https://zenn.dev/forcia_tech/articles/202305_http_keepalive
レスポンスは辞書型で返してくれます。

resDictのBodyを※1HTML Parserの CSSセレクタ検索でパースします。
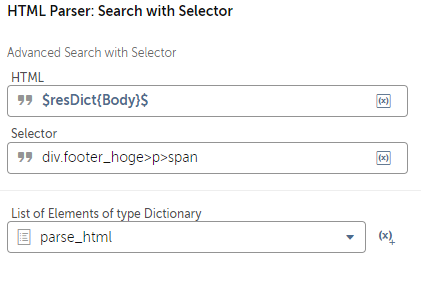
listにdictを格納することができなくなっており、アクションから返り値を作成する事が出来ないので
あらかじめサブタイプを任意にしたリストを用意しておきましょう。
成功するとlistにdictを格納して返してくれます。
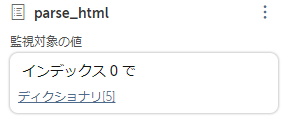
この表示確認出来そうなdictを見るとエラー発生で落ちます。

多次元配列はTable形式でしか直ぐ確認出来ません。
なのでこの中の値を確認する為にループを使用する必要があります。

参照できました。
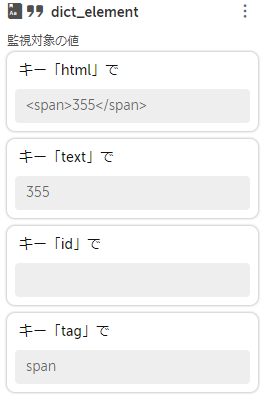
後はリストからも参照は可能なので $parse_html[0]{text}$ でも値を取り出せます。
※1
HTML Parser.pdf
https://s3-us-west-2.amazonaws.com/botstore-media/wp-content/uploads/2020/08/02095120/a2019-html-parser.pdf
英語なのでここに突っ込んでください