はじめに
動画版のCLIPについて、23年8月の社内勉強会で発表した内容を投稿したいと思います。
※今回はVideoEncoder部分のみにします。
Expanding Language-Image Pretrained Models for General Video Recognition
という論文でx-clipという名前で我らがHugging Faceにも学習済みモデルが公開されています。
背景
text-videoモデルを直接学習するには、下記の理由から現実的ではありません。
- 大規模なvideo-text事前学習データが必要
- 膨大なGPUリソースが必要
そこで事前学習されたtext-imageモデルをvideoドメインに適応させることを考えます。
事前学習されたクロスモダリティモデルをimageからvideoに適応させる場合、次の課題があります。
- videoに含まれる時間情報をどのように活用するか
- videoの識別可能なtext表現をどのように取得するか
これらの課題に対して新たなモデルを提案しました。
提案手法
Video EncoderとText Encoderを共同で学習し、videoの表現とそれに対応するtext表現の位置合わせを学習します。
text-imageモデルを基に構築し、時間的なモデリングでvideoに適応したテキストプロンプトでそれらを拡張します。
これにより既存の大規模な事前学習済みモデルを十分に活用しながら、imageからvideoへシームレスに移行することが可能です。
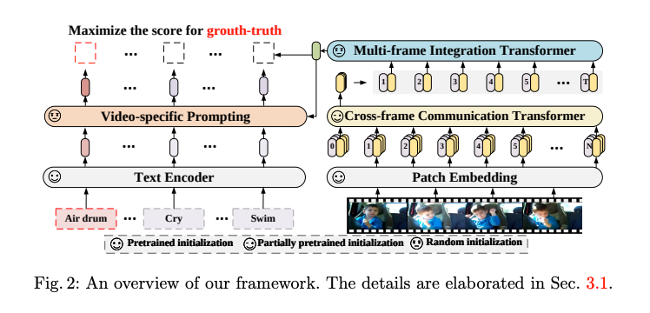
Video Encoder
Video Encoderは2つの構造から成っています。
- Cross-frame Communication Transformer (CCT):フレーム粒度のベクトルを得るTransformer
- Multi-frame Integration Transformer (MIT):フレーム間のベクトルをシンプルに結合してvideoのベクトルを得るTransformer
CCT
ここでは3つのフェーズに分かれています。
- cross-frame fusion attention (CFA):時空間依存性を学習
- intra-frame diffusion attention (IFA):時空間依存性を拡散
- a feed-forward network (FFN)
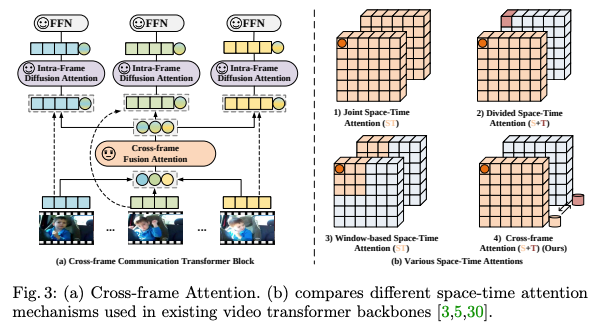
まず動画のフレーム群が与えられたら、1フレームずつVitのようにパッチに分割していきます。
各フレームごとにCLSトークンをくっ付けて、位置エンコーディングを付与します。
最初のAttentionとしてCFCをします。
各フレームのCLSトークンを取ってきて、Attentionをすることで動画間の時空間依存性を学習させています。
CFAで重み付けされたベクトルを元のフレームの所へ戻して、IFAという2回目のAttentionをします。
ここでは時空間依存性をそれぞれのフレームに拡散させながら、各フレームの重み付けを行なっています。
その後FFNしたら、各フレームの特徴量が完成です。
class CrossFramelAttentionBlock(nn.Module):
def __init__(
self,
d_model: int,
n_head: int,
attn_mask: torch.Tensor = None,
droppath=0.0,
T=0,
):
super().__init__()
self.T = T # フレーム数
self.message_fc = nn.Linear(d_model, d_model)
self.message_ln = LayerNorm(d_model)
self.message_attn = nn.MultiheadAttention(
d_model,
n_head,
)
self.attn = nn.MultiheadAttention(
d_model,
n_head,
)
self.ln_1 = LayerNorm(d_model)
self.drop_path = DropPath(droppath) if droppath > 0.0 else nn.Identity()
self.mlp = nn.Sequential(
OrderedDict(
[
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model)),
]
)
)
self.ln_2 = LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = (
self.attn_mask.to(dtype=x.dtype, device=x.device)
if self.attn_mask is not None
else None
)
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x):
l, bt, d = x.size()
b = bt // self.T
x = x.view(l, b, self.T, d)
# cross-frame fusion attention: 各フレームのclsを結合してAttention
msg_token = self.message_fc(x[0, :, :, :])
msg_token = msg_token.view(b, self.T, 1, d)
msg_token = msg_token.permute(1, 2, 0, 3).view(self.T, b, d)
msg_token = msg_token + self.drop_path(
self.message_attn(
self.message_ln(msg_token),
self.message_ln(msg_token),
self.message_ln(msg_token),
need_weights=False,
)[0]
)
msg_token = msg_token.view(self.T, 1, b, d).permute(1, 2, 0, 3)
x = torch.cat([x, msg_token], dim=0)
# intra-frame diffusion attention: 各フレーム内でAttention
x = x.view(l + 1, -1, d)
x = x + self.drop_path(self.attention(self.ln_1(x)))
x = x[:l, :, :]
# FFN
x = x + self.drop_path(self.mlp(self.ln_2(x)))
return x
MIT
CCTで獲得した各フレームごとのベクトル表現を入力として、Attentionする機構です。
ここではCCTのCLSトークン部分のみを使います。(T*512みたいなイメージ)
MultiheadAttentionした後、MLPしてvideo特徴量を得ます。
この特徴量をtextencoderの出力と混ぜてtext-videoの特徴空間の学習に使っていきます。
class ResidualAttentionBlock(nn.Module):
def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):
super().__init__()
self.attn = nn.MultiheadAttention(d_model, n_head)
self.ln_1 = nn.LayerNorm(d_model)
self.mlp = nn.Sequential(
OrderedDict(
[
("c_fc", nn.Linear(d_model, d_model * 4)),
("gelu", QuickGELU()),
("c_proj", nn.Linear(d_model * 4, d_model)),
]
)
)
self.ln_2 = nn.LayerNorm(d_model)
self.attn_mask = attn_mask
def attention(self, x: torch.Tensor):
self.attn_mask = (
self.attn_mask.to(dtype=x.dtype, device=x.device)
if self.attn_mask is not None
else None
)
return self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]
def forward(self, x: torch.Tensor):
x = x + self.attention(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
おわりに
今回はx-clipのvideoencoder部分を紹介しました。
モデリングの論文は日々増えていますが、動画分野に関してはどうやってフレーム間の時間的特徴を学習させるかがキーポイントなのでそこをおさえておくと一見複雑そうな論文や実装も少し理解しやすくなると思いました。