はじめに
先日SoraがOpenAIから発表されて、その完成度の高さにみんな驚愕してましたね。
そんなSoraの技術ページを読んでみました。
ページのリンクはこちらです。
完成度の高い動画がいっぱい載ってるので、よかったら一回見てみてください。
()がいっぱい出てきますが、この中に自分の意見を書いていきます。
普通の文章は上記ページを日本語訳したものです。
Video generation models as world simulators
技術的には、色んな時間や解像度、アスペクト比の動画と画像に対して、テキスト条件付き拡散モデルを共同で学習しています。
(動画の時間軸方向に対してのモデリングをどのように工夫するかが、キーポイントになっているようです)
このレポートでは、下記二点に焦点を当てて説明されてます。
- あらゆる種類のvidual dataを、生成モデルの大規模な学習ができる統一的な表現に変換する手法
- Soraの能力と限界の定性評価
そのためモデルと実装の詳細は含まれていません。
(モデルの概要図も示されてないですね。有志の方が実装してるページがあるようです)
Turning visual data into patches
LLMが様々な自然言語を統合するテキストトークンを持つのに対して、Soraではビジュアルパッチを持っています。
我々は、パッチが多様な種類の動画や画像に対して生成モデルを学習するための、拡張性の高い効果的な表現であることを発見しました。
(Vitの入力時パッチに分けますが、それとは意味が違うんですかね?)
具体的には、まず動画を低次元の潜在空間[19]に圧縮し、次にその表現を時空間パッチに分解することで、動画をパッチに変換します。
(これは単純なLDMでした。この後の時空間パッチのところがポイントなのでしょうか?)
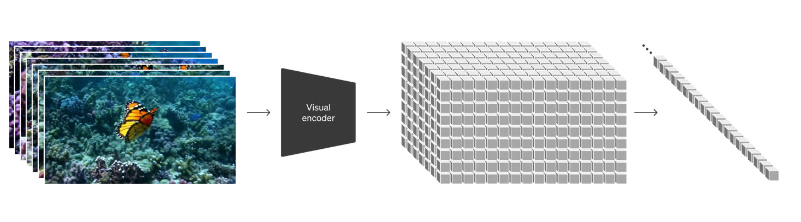
Video compression network
このネットワークでは、visual dataの次元を削減するように訓練します。[20]
生の映像を入力とし、時間的にも空間的にも圧縮された潜在表現を出力します。
Soraはこの潜在空間と共に学習し、動画を生成します。
また、生成された潜像ベクトルをピクセル空間にマッピングするデコーダモデルも学習します。
Spacetime latent patches
圧縮された入力ビデオが与えられると、変換トークンとして機能する時空間パッチのシーケンスを抽出します。
画像は1フレームのビデオに過ぎないので、この方式は画像にも有効です。
パッチベースの表現により、Soraは様々な解像度、時間、アスペクト比のビデオや画像に対して学習することができます。
推論時には、ランダムに初期化されたパッチを適切なサイズのグリッドに配置することで、生成されるビデオのサイズを制御することができます。
Scaling transformers for video generation
Soraは拡散モデルです。
入力されたノイズの多いパッチ(およびテキストプロンプトのような条件付け情報)が与えられると、元のきれいなパッチを予測するように訓練されます。
重要なのは、Soraはdiffusion transformers[26]であることです。

本研究では、diffusion transformersがビデオモデルとしても効果的にスケーリングすることを発見しました。
以下に、シードと入力を固定したビデオサンプルの、トレーニングの進行に伴う比較を示します。
トレーニングの計算量が増えるにつれて、サンプルの品質は著しく向上します。
...(この後の説明は動画がいっぱい出てくるので、上のリンクから見てみてください!)
Variable durations, resolutions, aspect ratios
学習のポイントとしては、これまでの方法では画像や動画生成では、256*256で4秒動画にリサイズ、クロップ、トリミングをしていましたが、本来のサイズのデータで学習することで、いくつか利点が得られました。
- 構図やフレーミングが改善される
- 異なるデバイス向けのコンテンツをネイティブのアスペクト比で直接作成することができる
(確かにサイズの違う動画がサイズを考慮して生成されてそうです)

Language understanding
text-to-video generation systemsの学習には多くのテキストキャプション付き動画が必要です。
DALL-E 3で導入されたリキャプション技術を動画に適用しました。
まず、キャプションモデルを訓練し、それを使って訓練セットのすべての動画にテキストキャプションを生成しました。
ビデオキャプションの訓練は、ビデオの全体的な品質だけでなく、テキストの忠実度を向上させることがわかりました。
また、DALL-E 3と同様に、GPTを活用して短いプロンプトを長いキャプションに変換し、ビデオモデルに送ります。
これにより、Soraはユーザーのプロンプトに正確に従った高品質のビデオを生成することができます。

(ユーザーが投げた短い文章を動画キャプションに変換してから、生成モデルに入れてるイメージでしょうか?)
まとめ
テクニカルレポートを読んでみました。
ポイントとしては下記で、先行研究の論文も読んで理解を深めていこうと思います。
- 既存技術の集合体
- Soraのコア部分はdiffusion transformers
- 学習の工夫として、前処理でリサイズ等を行わず本来のサイズのデータで学習している
- テキストキャプション付き動画データの作成にはDALL-E3のリキャプション技術を使っている
今後はレポート内に載ってる論文も読んで、もっと具体的に理解していきたいです。