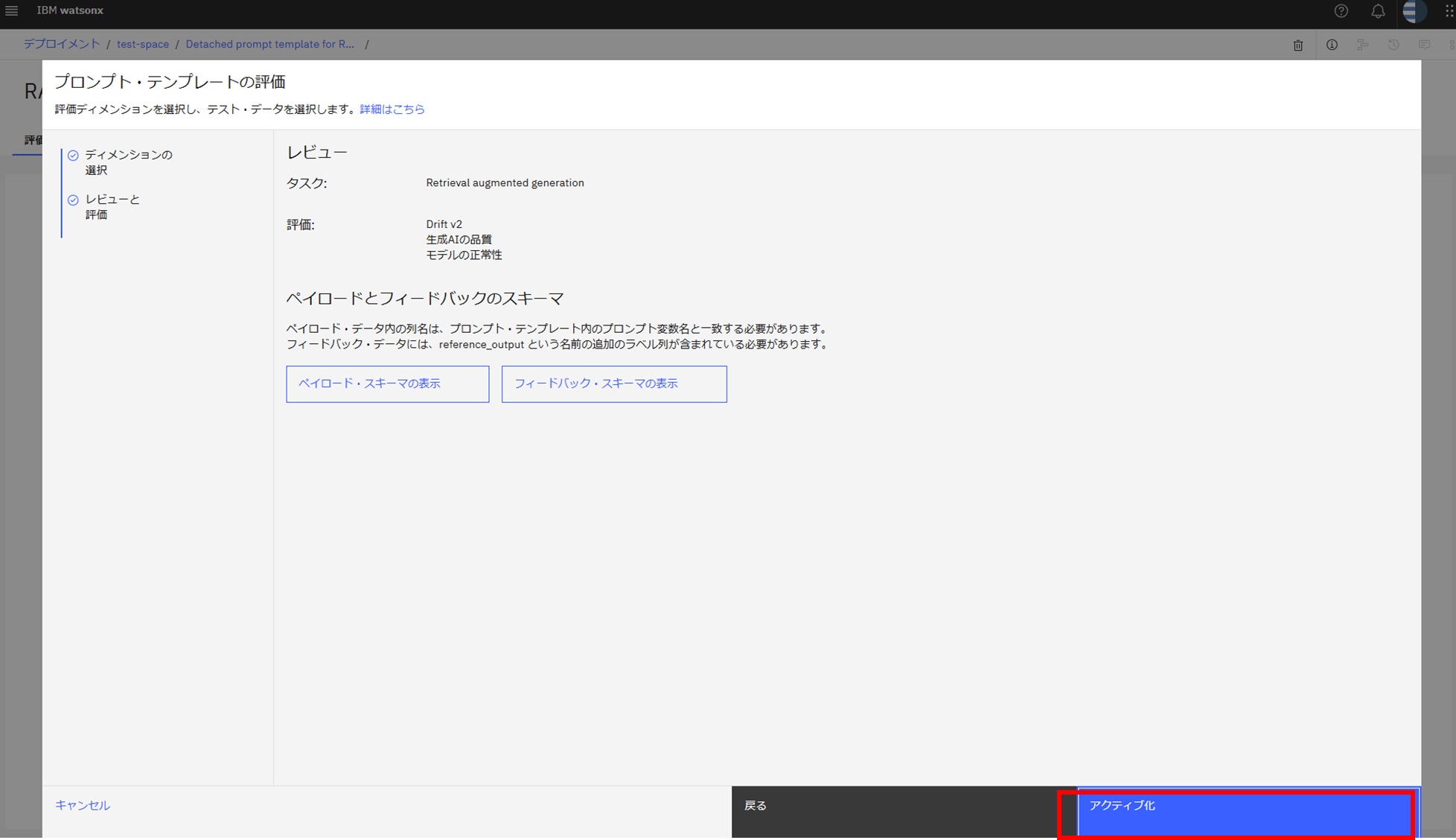
PROMPTE TEMPLATEをproduction(実働)向けのSPACEにPROMOTE&DEPLOY







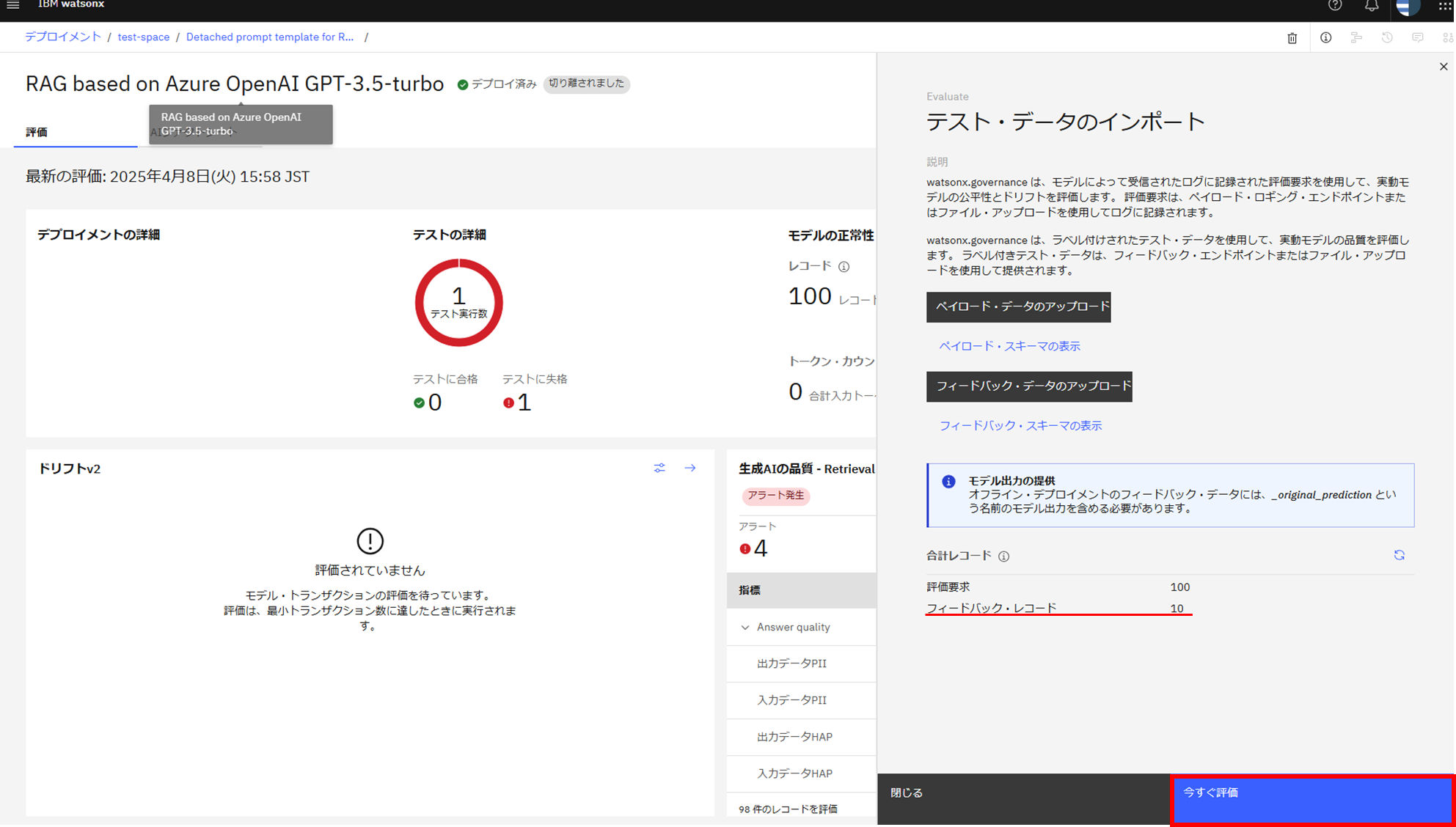
Evaluate(検証)を有効化





SPACE_IDとSUBSCRIPTION_IDの取得



Payloadデータの送信の実装&手動評価
PayloadデータはRAGへの入出力(context、Question、generated_text)のうち正解(reference)を含まないデータのこと。
payload.py
# %%
from dotenv import load_dotenv
import os
load_dotenv()
# %%
from ibm_cloud_sdk_core.authenticators import CloudPakForDataAuthenticator
from ibm_watson_openscale import *
from ibm_watson_openscale.supporting_classes.enums import *
from ibm_watson_openscale.supporting_classes import *
url = os.environ.get("CPD_URL")
username = os.environ.get("CPD_USERNAME")
password = os.environ.get("CPD_PASSWORD")
authenticator = CloudPakForDataAuthenticator(
url=url,
username=username,
password=password,
disable_ssl_verification=True
)
wos_client = APIClient(
service_url=url,
authenticator=authenticator,
)
data_mart_id = wos_client.service_instance_id
print(data_mart_id)
print(wos_client.version)
# %%
subscription_id = os.environ.get("SUBSCRIPTION_ID")
wos_client.monitor_instances.show(target_target_id=subscription_id)
# %%
monitor_definition_id = "mrm"
space_id = os.environ.get("SPACE_ID")
response = wos_client.monitor_instances.list(
data_mart_id=data_mart_id,
monitor_definition_id=monitor_definition_id,
target_target_id=subscription_id,
space_id=space_id)
response.result.to_dict()
# %%
monitor_instance_id = response.result.to_dict()["monitor_instances"][0]["metadata"]["id"]
print(monitor_instance_id)
# %%
import pandas as pd
filepath = "test.csv"
df = pd.read_csv(filepath_or_buffer=filepath)
df
# %%
request_body = []
for index, row in df.iterrows():
print(index)
tmp = {
"request": {
"parameters": {
"template_variables": {
"context": row.context,
"question": row.question
}
}
},
"response": {
"results": [
{
"generated_text": row.generated_text
}
]
}
}
request_body.append(tmp)
# %%
import json
print(json.dumps(request_body, indent=2, ensure_ascii=False))
# %%
from ibm_watson_openscale.supporting_classes.enums import *
data_set_id = None
response = wos_client.data_sets.list(
type=DataSetTypes.PAYLOAD_LOGGING,
target_target_id=subscription_id,
target_target_type=TargetTypes.SUBSCRIPTION)
response.result.to_dict()
# %%
data_set_id = response.result.to_dict()['data_sets'][0]['metadata']['id']
print(data_set_id)
# %%
response = wos_client.data_sets.store_records(
data_set_id=data_set_id,
request_body=request_body,
background_mode=True)
response.result.to_dict()
# %%
wos_client.data_sets.get_records_count(data_set_id=data_set_id)
# %%


Feedbackデータの送信の実装&手動評価
PayloadデータはRAGへの入出力(context、Question、generated_text)と正解(reference)を含むデータのこと。
wxg_feedback.py
# %%
CPD_URL = "<INPUT YOUR CPD_URL>"
CPD_USERNAME = "<INPUT YOUR CPD_USERNAME>"
CPD_PASSWORD = "<INPUT YOUR CPD_PASSWORD>"
CPD_API_KEY = "<INPUT YOUR CPD_API_KEY>"
# %%
SPACE_ID = "<INPUT YOUR SPACE_ID>"
SUBSCRIPTION_ID = "<INPUT YOUR SUBSCRIPTION_ID>"
# %%
from ibm_cloud_sdk_core.authenticators import CloudPakForDataAuthenticator
from ibm_watson_openscale import *
from ibm_watson_openscale.supporting_classes.enums import *
from ibm_watson_openscale.supporting_classes import *
authenticator = CloudPakForDataAuthenticator(
url=CPD_URL,
username=CPD_USERNAME,
password=CPD_PASSWORD,
disable_ssl_verification=True
)
wos_client = APIClient(
service_url=CPD_URL,
authenticator=authenticator,
)
data_mart_id = wos_client.service_instance_id
print(data_mart_id)
print(wos_client.version)
# %%
wos_client.monitor_instances.show(target_target_id=SUBSCRIPTION_ID)
# %%
monitor_definition_id = "mrm"
response = wos_client.monitor_instances.list(
data_mart_id=data_mart_id,
monitor_definition_id=monitor_definition_id,
target_target_id=SUBSCRIPTION_ID,
space_id=SPACE_ID)
response.result.to_dict()
# %%
monitor_instance_id = response.result.to_dict()["monitor_instances"][0]["metadata"]["id"]
print(monitor_instance_id)
# %%
from ibm_watson_openscale.supporting_classes.enums import *
data_set_id = None
response = wos_client.data_sets.list(
type=DataSetTypes.FEEDBACK,
target_target_id=SUBSCRIPTION_ID,
target_target_type=TargetTypes.SUBSCRIPTION)
response.result.to_dict()
# %%
data_set_id = response.result.to_dict()['data_sets'][0]['metadata']['id']
print(data_set_id)
# %%
import pandas as pd
test_data_path = "test_generated_text.csv"
llm_data = pd.read_csv(test_data_path)
llm_data.head()
# %%
llm_data.shape
# %%
test_data_content = []
context_fields = ["context"]
question_field = "question"
feature_fields = context_fields + [question_field] #For Alternative Dataset
prediction_list = llm_data["generated_text"].tolist()
label_column = "reference"
#for _, row in llm_data.iloc.iterrows(): 100件だとなぜかうまく行かないので…
for _, row in llm_data.iloc[:10].iterrows():
# Read each row from the DataFrame and add label and prediction values
result_row = [row[key] for key in feature_fields if key in row]
result_row.append(row[label_column])
result_row.append(row["generated_text"])
test_data_content.append(result_row)
if len(test_data_content) == 10: # 10 records are there in the downloaded CSV
print("generated feedback data from DataFrame")
else:
print("Failed to generate feedback data from DataFrame, kindly verify the DataFrame content")
fields = feature_fields.copy()
fields.append(label_column)
fields.append("_original_prediction")
feedback_data = [
{
"fields": fields,
"values": test_data_content
}
]
feedback_data
# %%
import json
print(json.dumps(feedback_data, indent=2, ensure_ascii=False))
# %%
response = wos_client.data_sets.store_records(
data_set_id=data_set_id,
request_body=feedback_data,
background_mode=True)
response.result.to_dict()
# %%
wos_client.data_sets.get_records_count(data_set_id=data_set_id)
# %%

RAGのWebアプリケーションに実装
app.py
# %%
#!pip install gradio
# %%
import gradio as gr
import os
from rag import vector_store, PROMPT_TEMPLATE, client, AZURE_OPENAI_DEPLOYMENT_NAME
from wxg_payload import wos_client, data_set_id
# %%
# %%
def test(question):
results = vector_store.similarity_search(query=question)
contexts = ""
for result in results:
# print(result)
contexts += result.page_content
contexts += "\n"
contexts += "--------------------------------------------------------------------------------"
contexts += "\n"
content = PROMPT_TEMPLATE.format(context=contexts, question=question)
max_tokens = 4096
response = client.chat.completions.create(
model=os.environ.get('AZURE_OPENAI_DEPLOYMENT_NAME', AZURE_OPENAI_DEPLOYMENT_NAME),
messages=[{"role": "user", "content": content}],
max_tokens=max_tokens
)
answer = response.choices[0].message.content
################################################################################
payload_data = [{
"request": {
"parameters": {
"template_variables": {
"context": contexts,
"question": question
}
}
},
"response": {
"results": [
{
"generated_text": answer
}
]
}
}]
import json
print(json.dumps(payload_data, indent=2, ensure_ascii=False))
response = wos_client.data_sets.store_records(
data_set_id=data_set_id,
request_body=payload_data,
background_mode=True)
print(response.result.to_dict())
################################################################################
return answer, contexts
# %%
with gr.Blocks() as app:
question = gr.Textbox(label="question")
answer = gr.Textbox(label="answer")
contexts = gr.Textbox(label="contexts")
button = gr.Button()
button.click(fn=test, inputs=[question], outputs=[answer, contexts])
# %%
app.launch(server_name="0.0.0.0")
# %%
Qustionをするたびに、入出力データをpayloadデータとして送信する。


↑では3回の質問をしたので100+3で103回のPayloadで蓄積されている
すう追加のQAをした後の評価結果。
