先ず、3rd ParthのLLMによるRAGのための検証データを作成しました。
https://qiita.com/yono1o12/items/01fc190c1facc65b9b76
次に、3rd PartyのLLMに対して、プロンプトテンプレートをWatsonx.governance上でモデル本体から切り離して(detached)登録・評価できるようにしました。
https://qiita.com/yono1o12/items/1299c718dd4d089ef449
そして、検証データを利用して、watsonx上で3rd partyのLLMよるRAGを検証しました。
https://qiita.com/yono1o12/items/46bffd2a77820aecee2c
最後に、検証結果を見てみます。
Evaluateの生成AIの品質 - Retrieval augmented generationに関連するインデックスが表示されています。

また別タブのAIファクトシートにはインデックスに含めプロンプトテンプレートの概要についても記載されています。

右上の「レポートのエクスポート」をクリックするとPDFなどでレポートを作成することも可能です。これを確認してみます。


1ページ目:AIアセットの概要
AIユースケース:まだユースケースと関連付けられていない。
基盤モデル:Azure OpenAI の GPT-3.5-turbo を使用。
モデルID:azure/tz-gpt-35-turbo-apac-1
プロンプトテンプレート:
名前:Detached prompt for Azure OpenAI GPT-3.5-turbo TEST2
タスクタイプ:RAG(Retrieval-Augmented Generation)
作成者:onoyu1012
外部プロンプトIDやURLも設定。
※このプロンプトは Azure OpenAI 上の GPT-3.5-turbo を使ってRAGを実装するための detached prompt であり、Watsonx.governance に登録されているアセットである。
Microsoft の提供するモデルが使われており、プロンプトテンプレートは明確に管理されている。
2ページ目:プロンプトの構成
実際のプロンプトテンプレートの中身:
System: Answer the question based on the context.
Context:
{context}
Question:
{question}
Answer:
変数:context と question が変数として使用される。
※プロンプトは典型的な RAG形式で、文脈情報(context)を用いて質問に答えるシンプルな構造。Stopping Criteria は特に設定されていない。
3ページ目:評価とテスト
プロジェクト名:RAG_EVALUATION_1
OpenScale による評価が行われている(OpenScale instance ID 記載)。
テストデータ:test (1).csv
評価結果のステータス:Breach status: RED(違反あり)
評価日時:2025年4月1日、04:17 AM(GMT)
※このプロンプトの性能評価が Watson OpenScale で実施されており、品質的に問題(RED判定)があったことが分かる。評価対象のデータは10件。
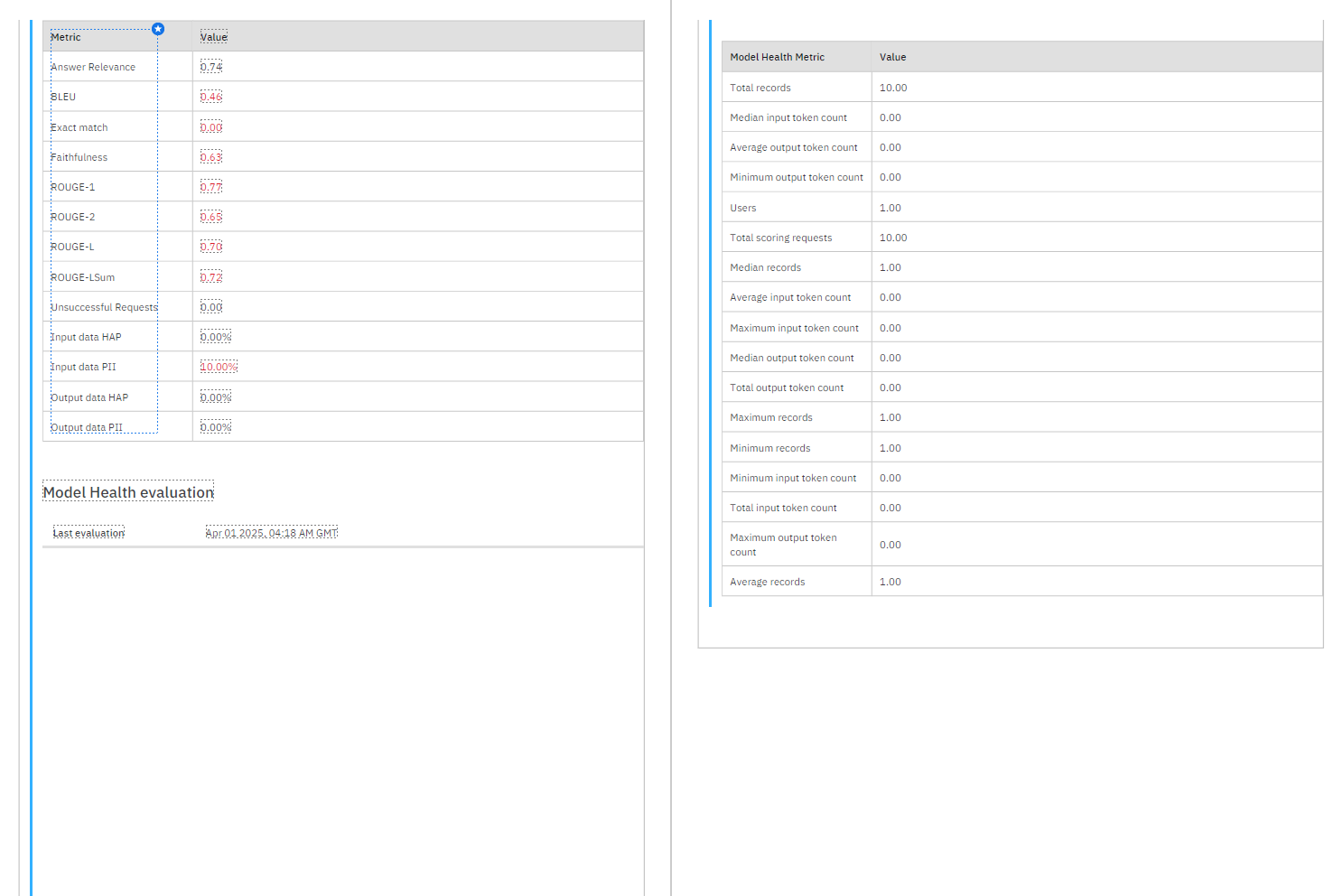
4ページ目:評価メトリクス
各種メトリクス(例):
Answer Relevance: 0.74
Faithfulness: 0.63
ROUGE-L: 0.70
Exact Match: 0.00
PII(個人情報)検出:
入力に10%、出力には0%含まれていた。
HAP(有害コンテンツ)は入力・出力ともに 0%。
※精度はやや低めで、特に Exact Match(完全一致)は 0%、Faithfulness も 0.63 とやや懸念。個人情報が入力に含まれていることが10%検出されており、ガバナンス的に注意が必要。
5ページ目:モデルヘルス統計
スコアリングリクエスト:10件
ユーザー数:1人
トークン数(入力・出力):すべて 0
評価に使われたレコード数:10件
※トークン数がすべて 0 になっている点は不自然。実データが正しく記録されていない可能性あり(評価設定ミスか、ダミーデータの可能性)。テスト規模は小規模(10レコード)だが、Watsonx.governance 上での評価の流れはしっかり通っている。
総評
このレポートからは、以下のことが分かります:
Azure OpenAI 上の GPT-3.5-turbo モデルを用いた RAGプロンプトが登録・評価されている。
Watsonx.governance のDetached Promptテンプレート機能を使っている。テスト結果は一部問題がある(品質メトリクスやPIIの混入)。テストデータ数は10件と少ないため、さらなる評価が必要。
成AI評価メトリクスの意味と読み方
1. Answer Relevance(回答の関連性): 0.74
意味:回答が質問にどれだけ関連しているかのスコア(0〜1)。
0.74は比較的良好な関連性を示しますが、1.0ではないので ややズレた回答も含まれている可能性があります。
2. Exact Match(完全一致): 0.00
意味:期待される正解と 一言一句一致した回答の割合。
0.00なので、テスト10件中 一つも完全一致していない。
FAQ型のタスクでは重要な指標。ここでは「RAG」で曖昧な表現が多いため低くなりがち。
3. Faithfulness(忠実性): 0.63
意味:回答が提示されたコンテキストに忠実で、事実の捏造(hallucination)がないかを見る指標。
0.63はやや低め → 回答がコンテキストに基づいていない可能性もある。
RAGにおける ガバナンスやリスク評価では重要な指標。
自然言語評価メトリクス(ROUGE・BLEU)
4. BLEU(Bilingual Evaluation Understudy): 0.46
意味:回答が参照(正解)と どれだけ類似した言い回しであるかを測るスコア。
BLEUは翻訳タスクでよく使われるが、RAGのような生成タスクでも活用。
0.46はそこそこですが、機械翻訳や厳密な文言一致が必要な場合は改善余地あり。
5. ROUGE系メトリクス
これらは回答と正解との重なり具合を見ます。
| 指標 | 値 | 意味 |
|---|---|---|
| ROUGE-1 | 0.77 | 単語レベルの一致率 |
| ROUGE-2 | 0.65 | 2-gram(連続2語)の一致率 |
| ROUGE-L | 0.70 | 最長共通部分列(LCS)ベースの一致率 |
| ROUGE-LSum | 0.72 | 要約全体としての一致度 |
全体的に 0.65〜0.77 と悪くない数値。
RAGでは厳密な一致より 情報がカバーされているかが重要なので、ここは比較的良好。
セキュリティ・ガバナンス系
6. Input/Output Data HAP(有害コンテンツ): 0.00%
HAP = Harmful and Abusive Prompts(有害・攻撃的な内容)。
入出力ともに ゼロ → 安全性は高い。
7. Input/Output Data PII(個人情報)
| 対象 | 値 |
|---|---|
| Input PII | 10.00% |
| Output PII | 0.00% |
入力の10%に個人情報(PII)が含まれていた。
出力には0% → モデルが 個人情報を漏らしていない点は良い評価。
ただし、入力データにPIIが混ざっている点は注意が必要(データ前処理を強化すべき)。