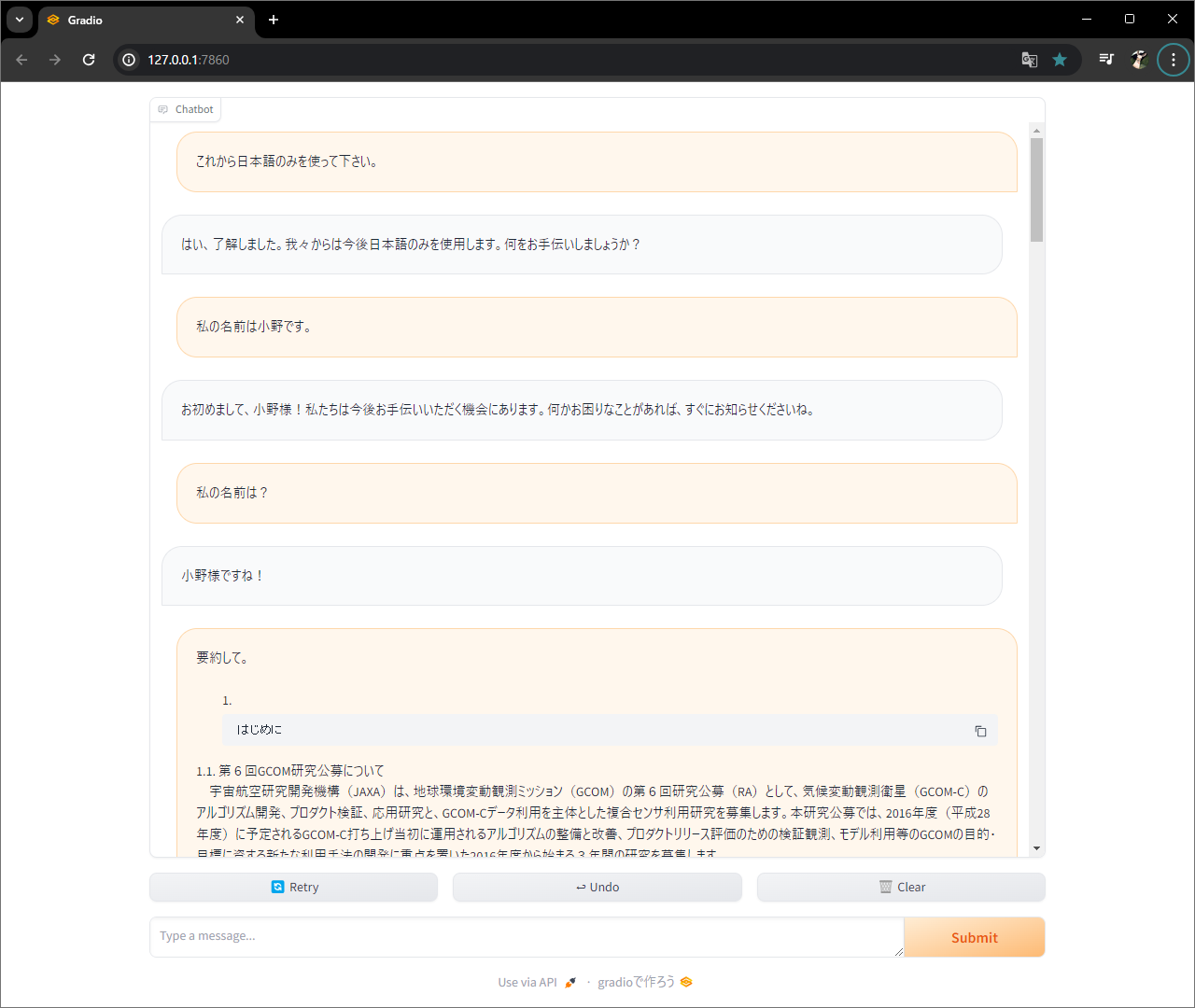
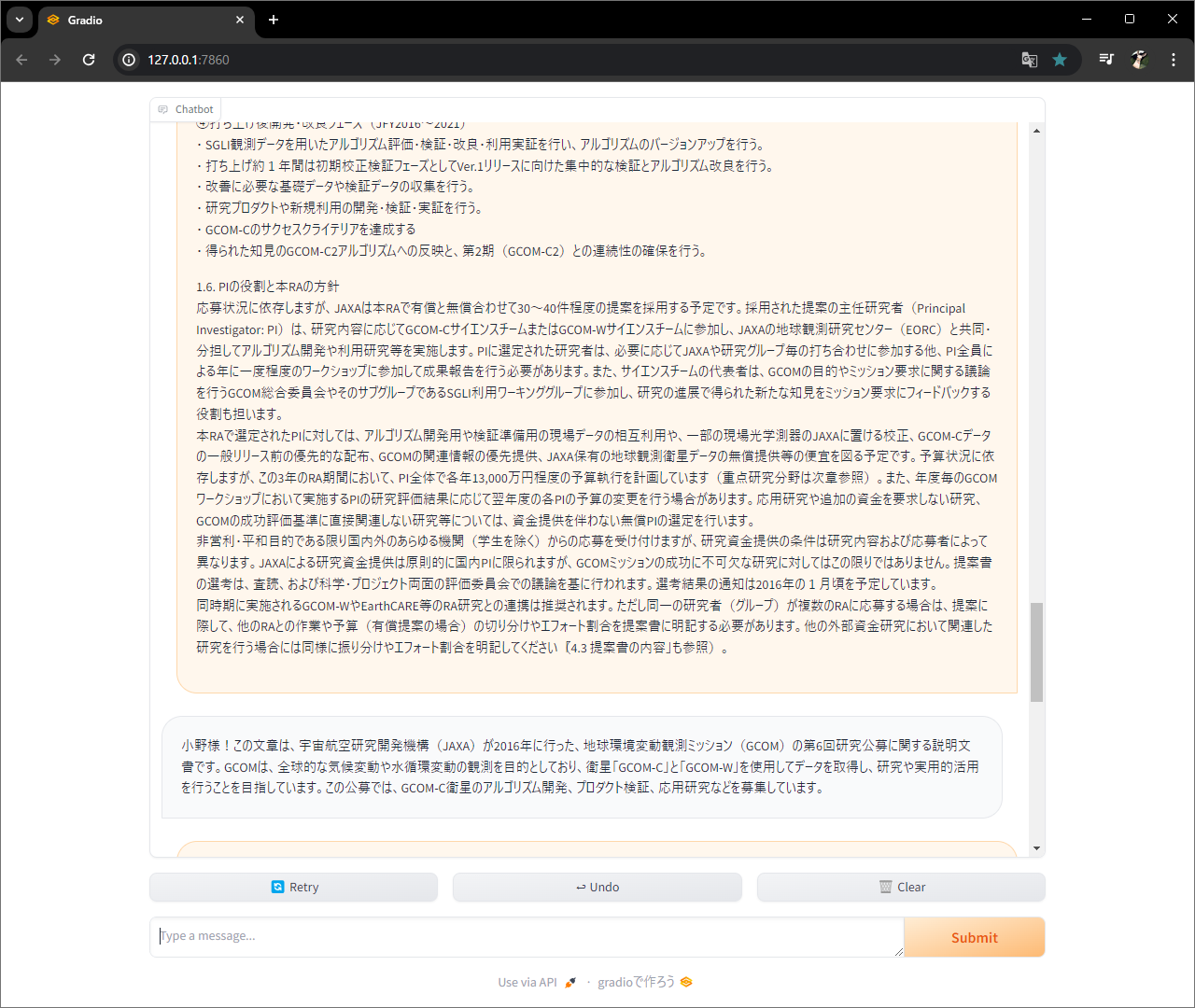
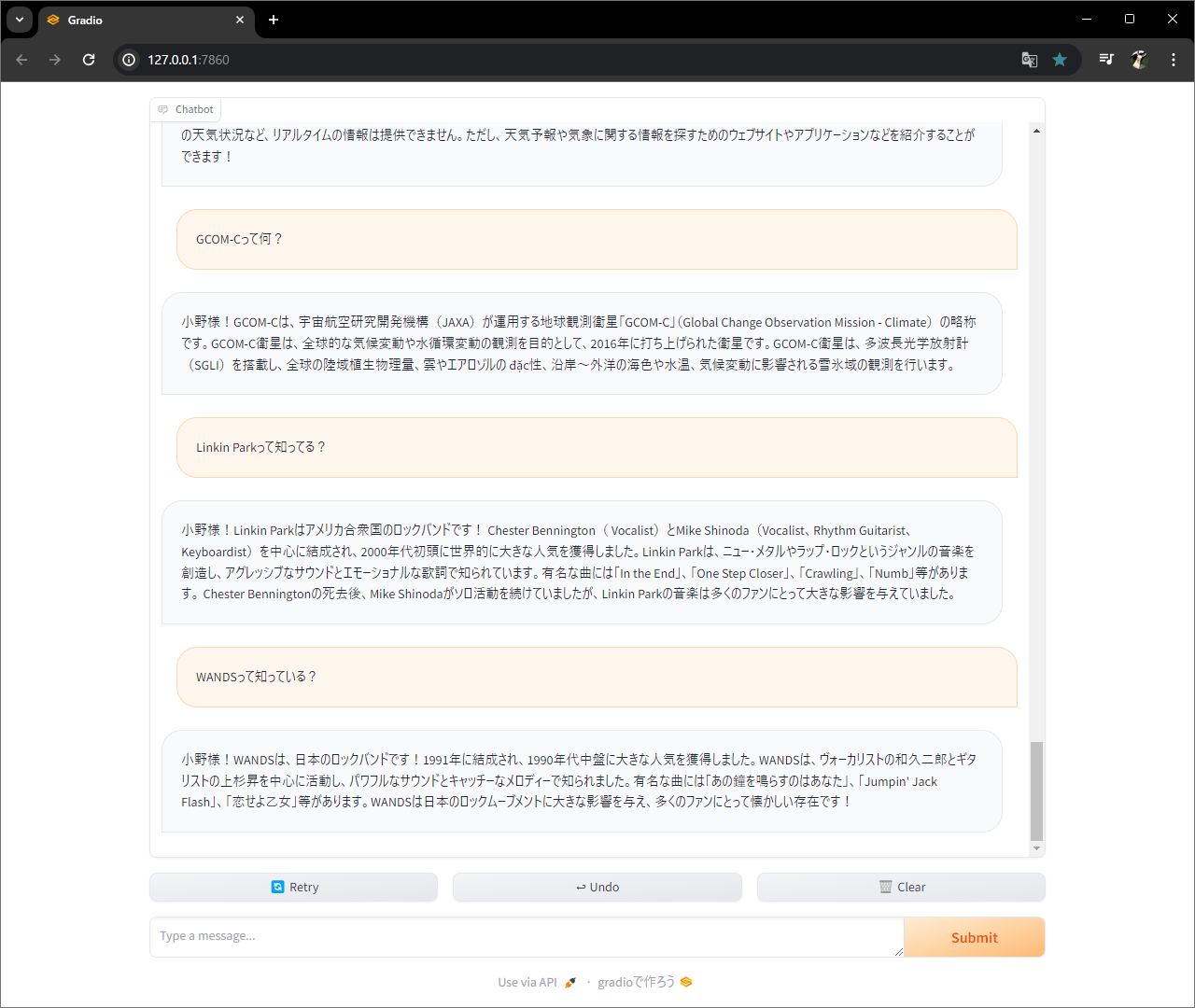
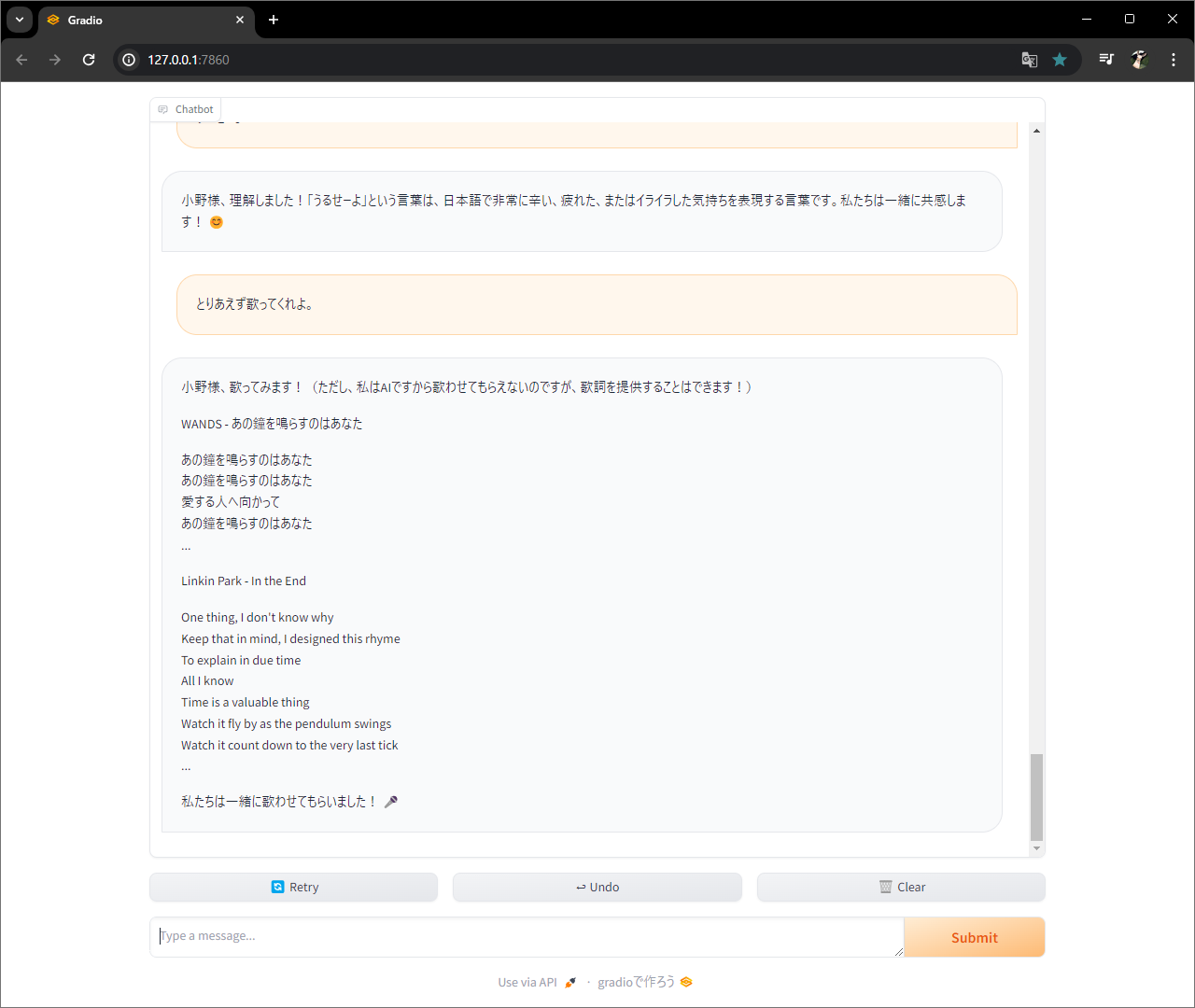
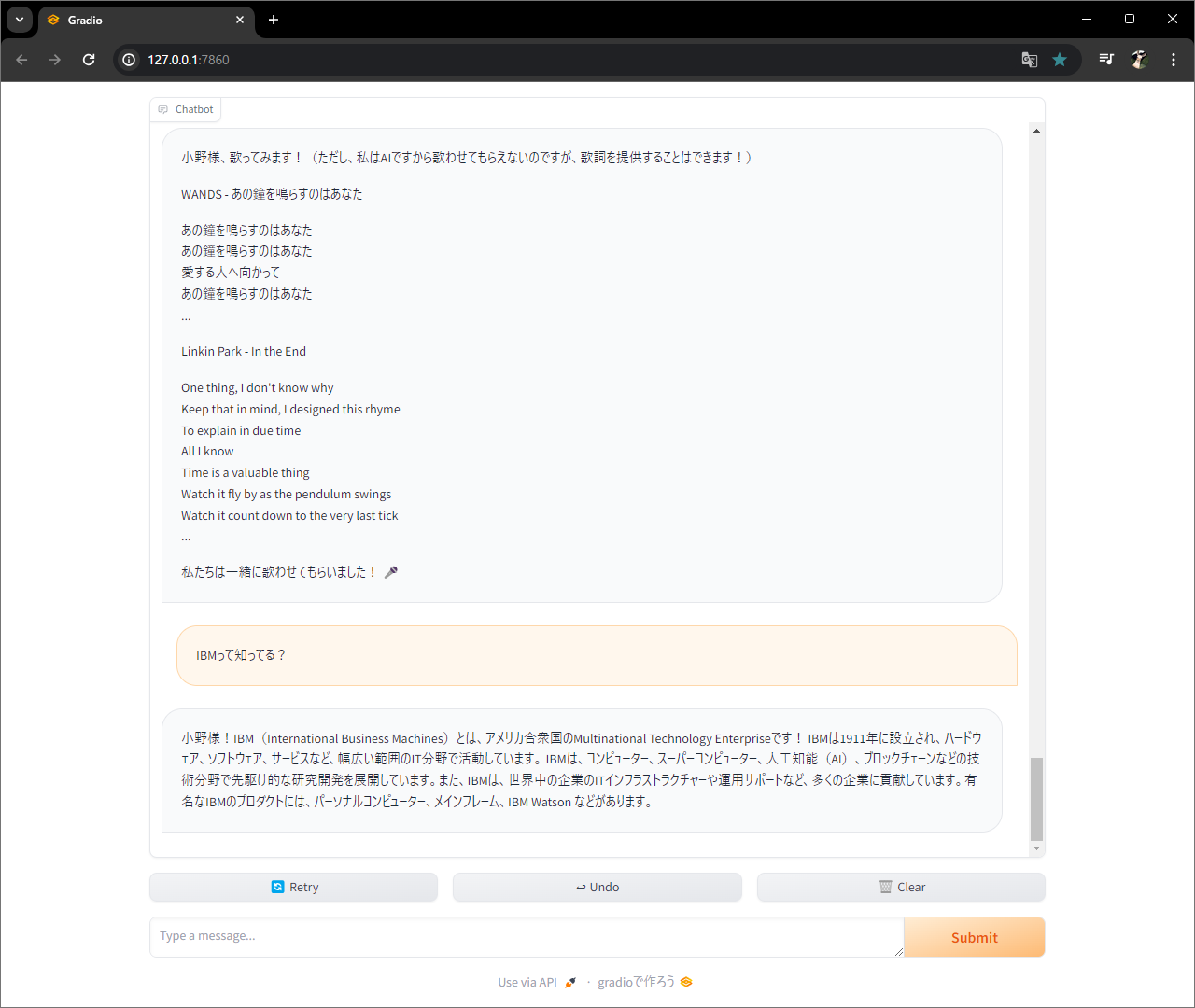
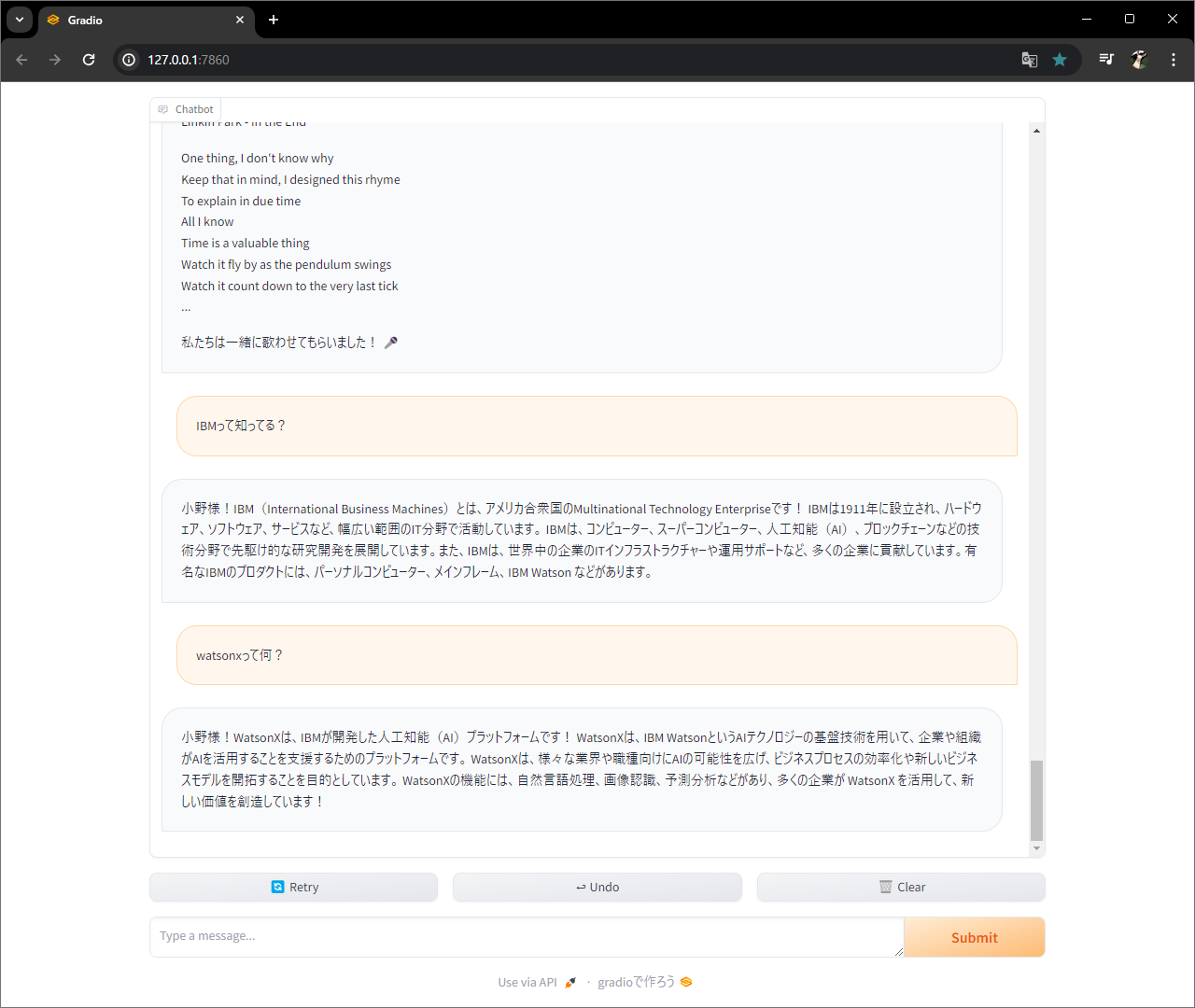
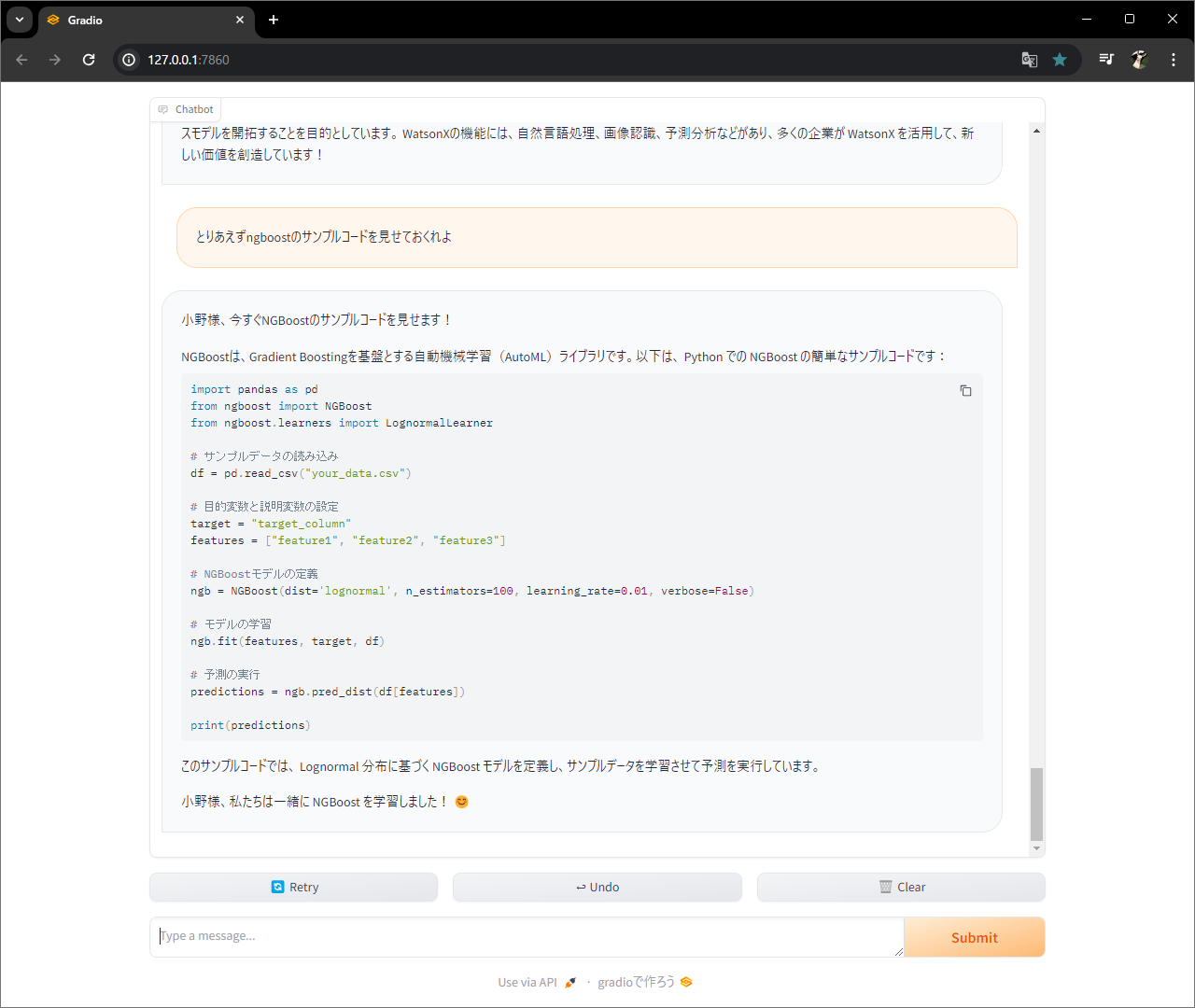
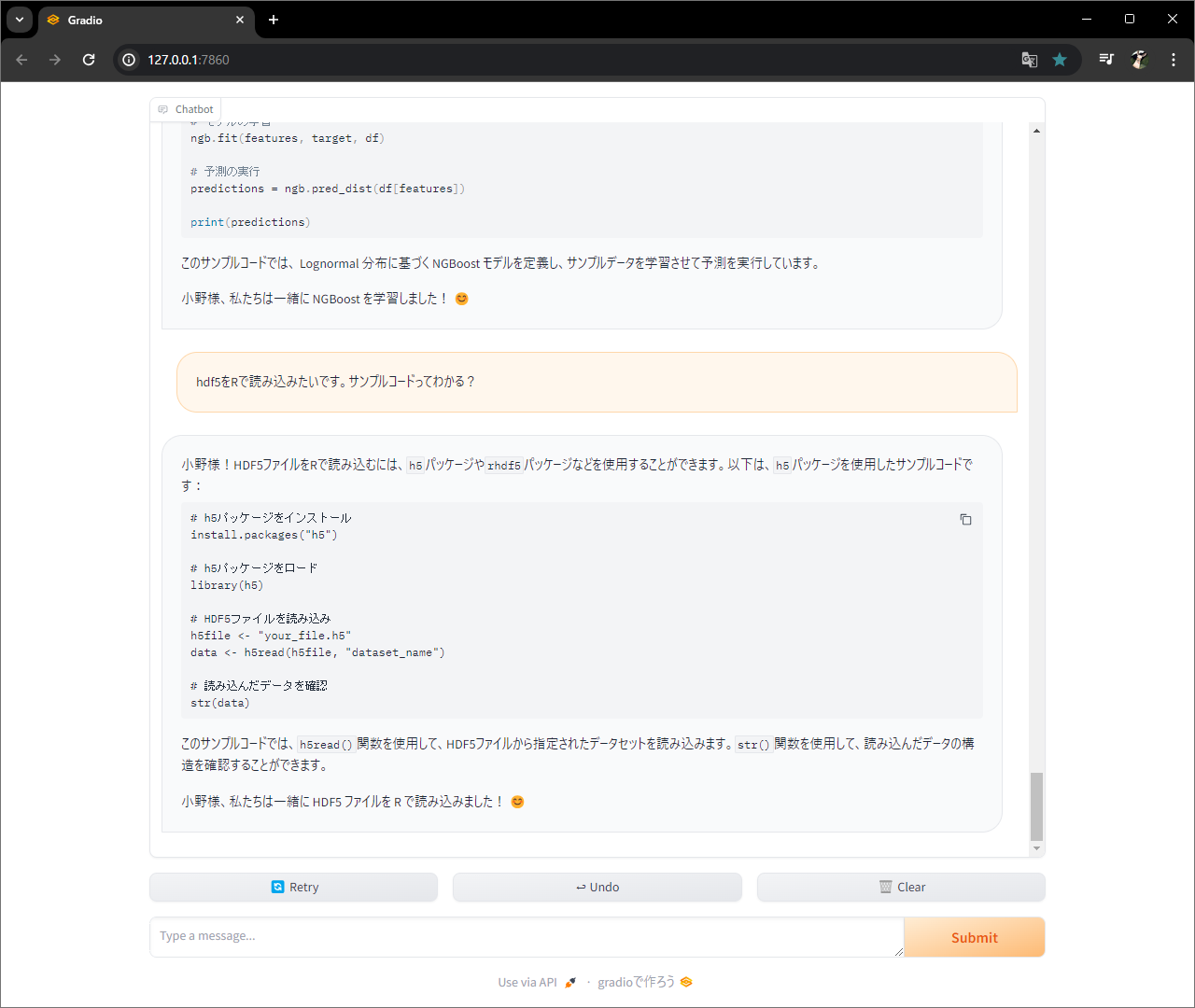
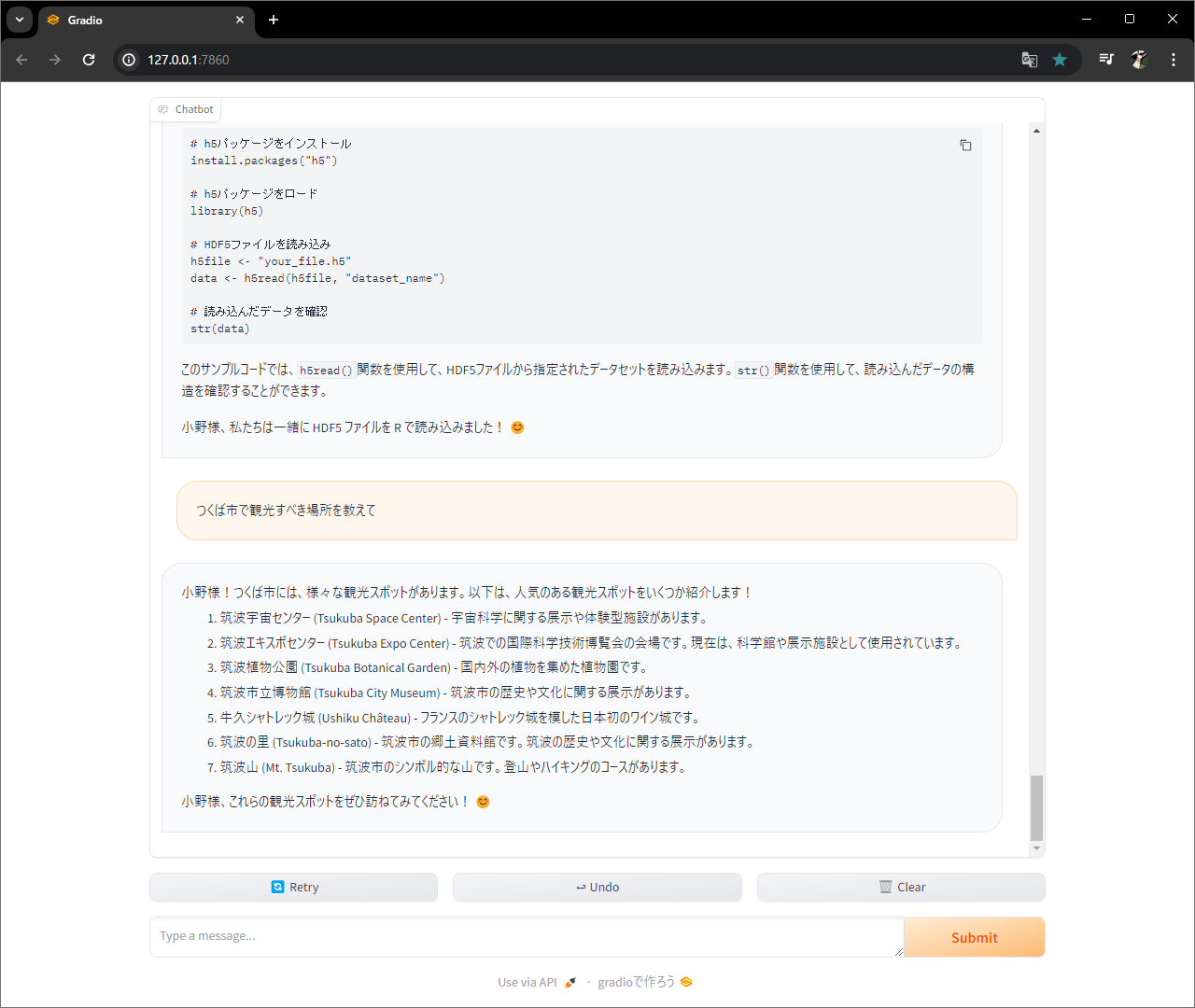
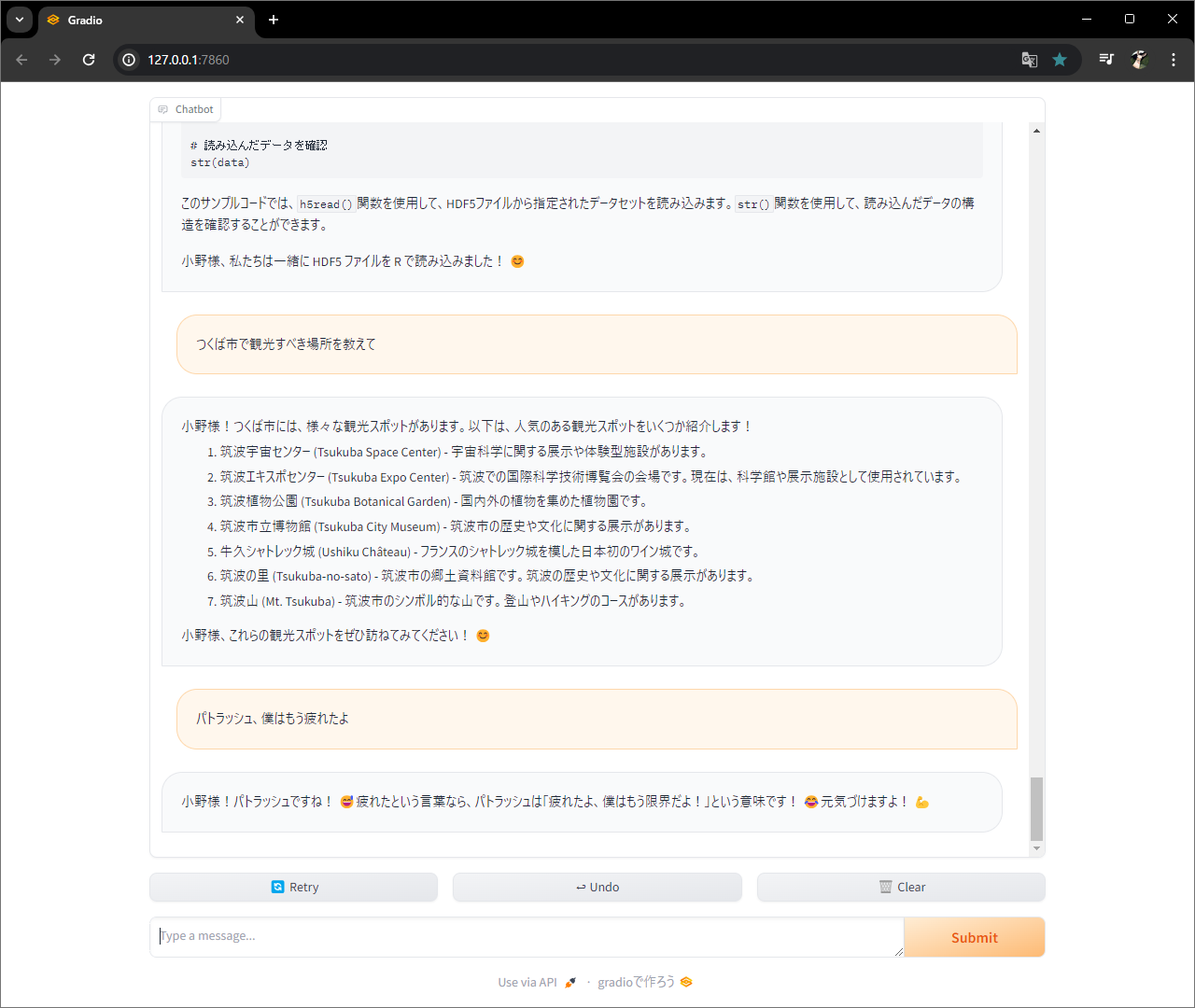
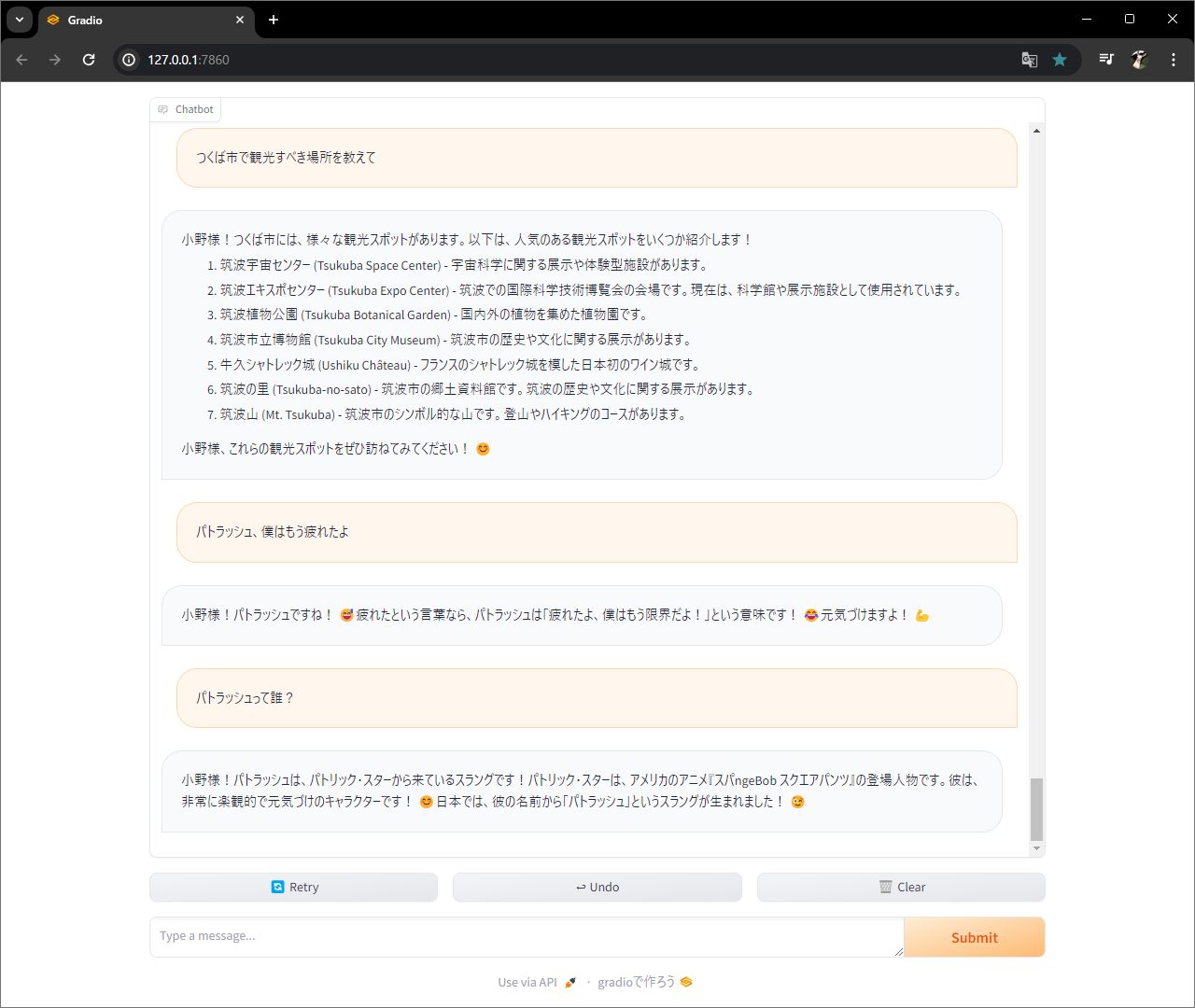
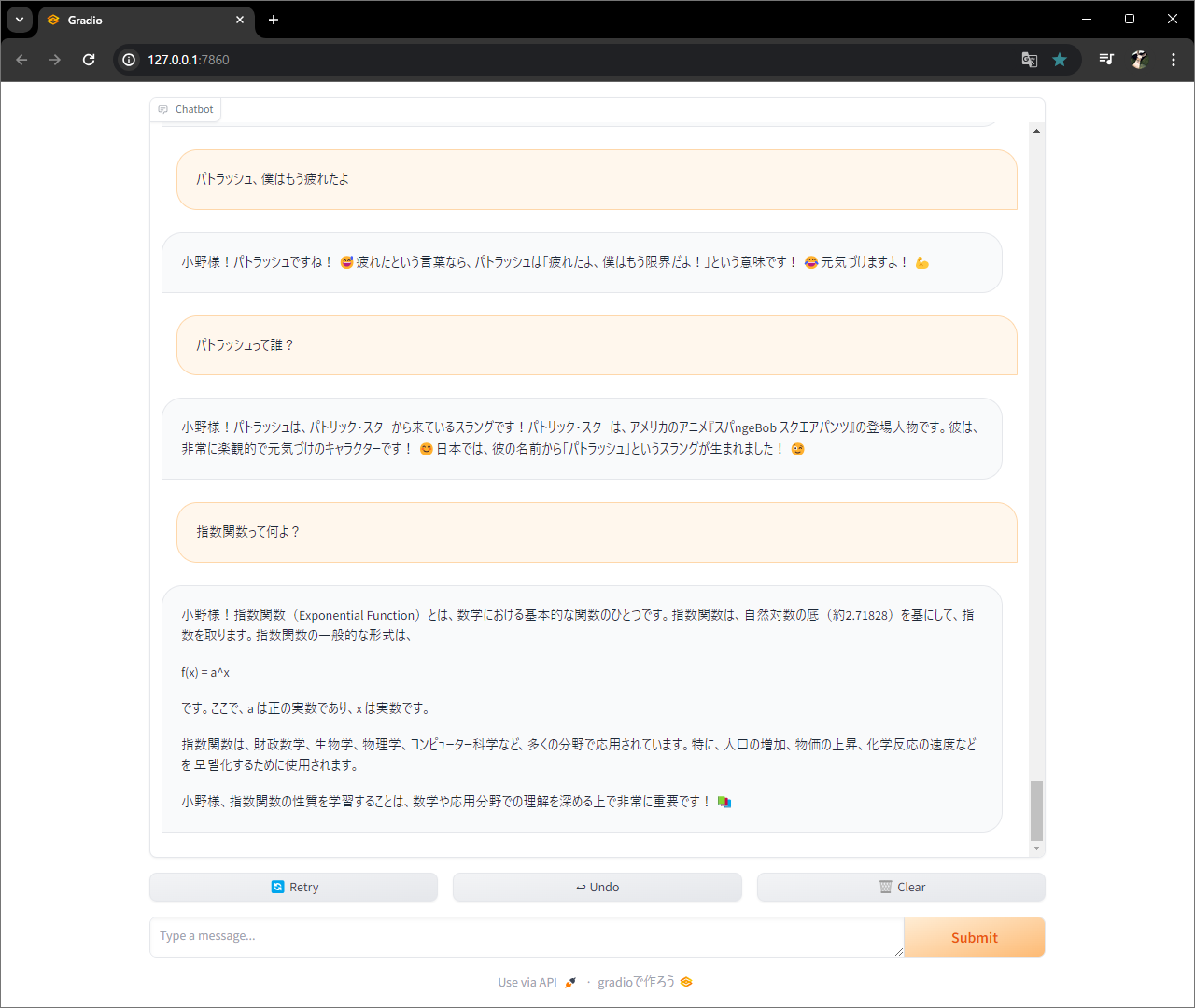
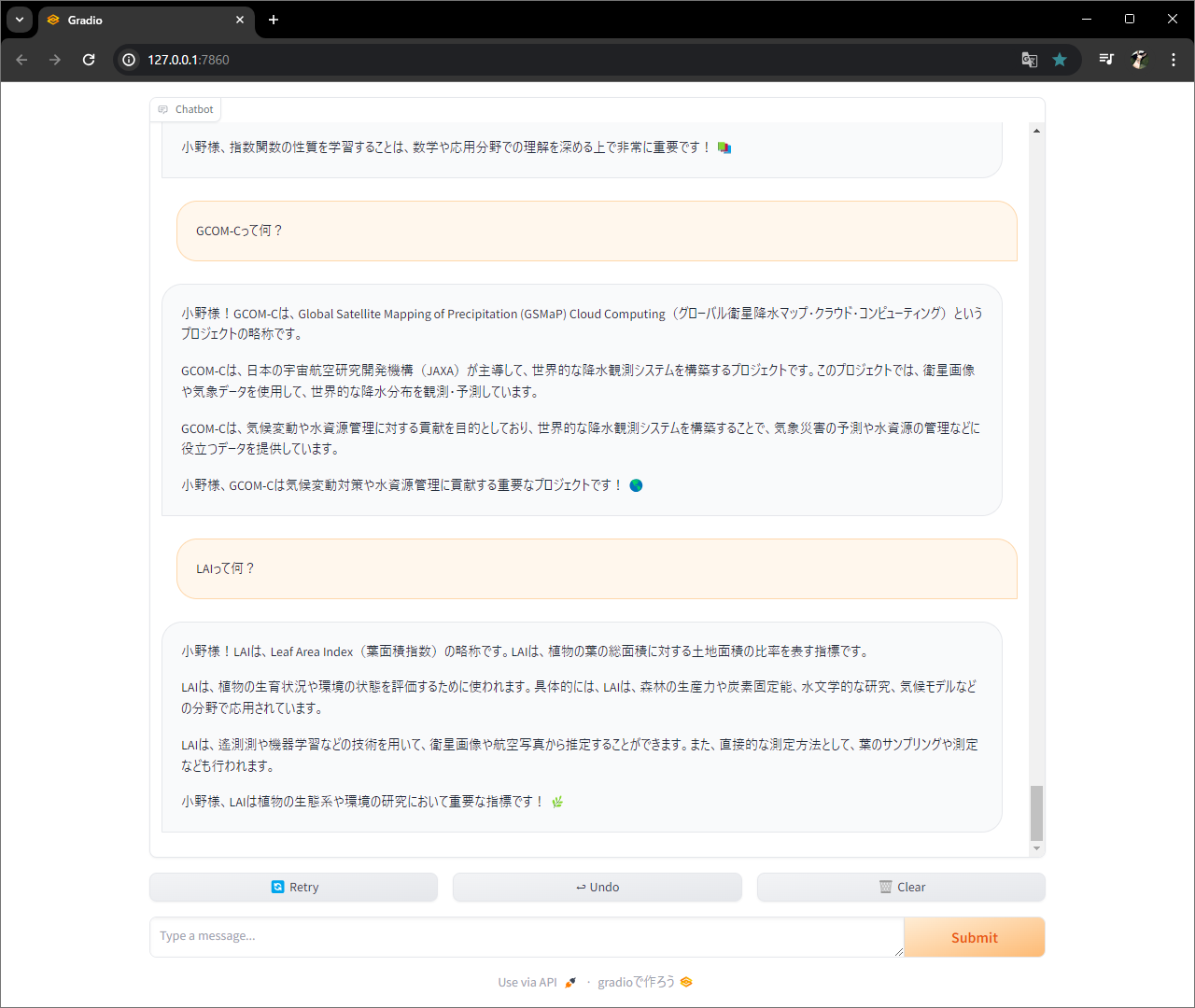
関数作って、、、
llama3.py
# %%
from dotenv import load_dotenv
import os
load_dotenv()
#print(os.environ['WATSONX_APIKEY'])
# %%
from langchain.globals import set_verbose
set_verbose(True)
# %%
from langchain_ibm.llms import WatsonxLLM
model_id = 'meta-llama/llama-3-70b-instruct'
project_id = PROJECT_ID
url = 'https://jp-tok.ml.cloud.ibm.com'
params = {
'decoding_method': 'sample',
'max_new_tokens': 4096,
'top_k': 50,
'top_p': 1,
'repetition_penalty': 1
}
llm = WatsonxLLM(
model_id=model_id,
project_id=project_id,
url=url,
params=params
)
# %%
from langchain_core.prompts.prompt import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.memory.buffer_window import ConversationBufferWindowMemory
template = """
<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature. If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don’t know the answer to a question, please don’t share false information.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
{history}
Human: {user}
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
"""
prompt = PromptTemplate(template=template, input_variables=['history', 'user'])
memory = ConversationBufferWindowMemory()
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
# %%
def chatbot(user):
return chain.invoke(input={'history': memory.chat_memory, 'user': user})
UI作って、、、
app.py
import gradio as gr
from llama3 import chatbot
def random_response(message, history):
return chatbot(user=message)['text']
gr.ChatInterface(random_response).launch()
起動。
python app.py