はじめに
Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみようを一通り勉強させていただき、自分なりに工夫したアウトプットと学習ログを残しておこうと考えたため、本稿を記述しています。
本稿はあるページからリンクされている画像やページをマルッとダウンロードする方法について記述しています。
BeautifulSoupやCSSセレクタなどを駆使しますが、サイトからデータをマルッとダウンロードするにはもう一工夫必要のようです。
例えば、<a>タグのリンク先が相対パスになっていたり、リンク先がHTMLである場合など、そのHTMLの内容をさらに解析する場合は、リンク先を再帰的にダウンロードする必要があります。
それらを踏まえたマルッとダウンロードの実現方法のまとめになります。
必要なモジュール
- BeautifulSoup
- urllib(request, urlparse, urljoin, urlretrieve)
- os(makedirs, os.path)
- time
- re
上記で挙げたモジュールをインポートして利用します。それでは、ファイルエディタウィンドウを開いて、任意の名前.pyのファイルを作成・保存してください。
再帰的にHTMLページを処理すること
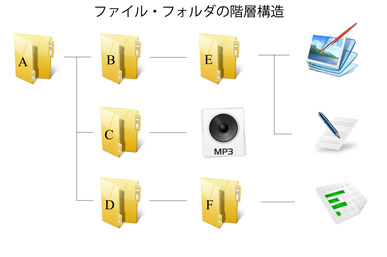
HTMLページはフォルダ構造として考えられます。
「A.html」から「B.html」にリンクしており、「B.html」から「E.html」にリンクしているとします。「A.html」からリンクしているページファイルをマルッとダウンロードしようとするとき、「E.html」もダウンロードしなければローカルでリンクが切れてしまいます。つまり、「A.html」を解析したあとに「B.html」の内容も解析しなければいけません。
HTMLをダウンロードする場合は、再帰的にHTMLを解析していく必要があります。上記のようなデータを解析・処理するためには、関数の再帰処理を利用することになります。
因みに、再帰処理というのは、「ある関数の中でその関数自身を呼び出す」プログラミング技術の1つです。例えば関数”a”がある場合は、関数”a”の中で関数”a”を呼び出すことということです。
memo:今年こそは再帰関数を理解しよう
手順としては、以下のサイクルとなります。
(1) HTMLを解析
(2) リンクを抽出
(3) 各リンク先にて以下の処理を実行
(4) ファイルをダウンロード
(5) ファイルがHTMLならば、再帰的に(1)からの手順を実行
それでは、プログラムを作成していきます。
ダウンロードするプログラム
from bs4 import BeautifulSoup
import urllib
import urllib.request
from urllib.parse import urlparse
from urllib.parse import urljoin
from urllib.request import urlretrieve
from os import makedirs
import os.path, time, re
まずはじめにモジュールの取り込みについて、
BeautifulSoup:HTMLを解析するため
urllib:Webに関するさまざまな関数を含んでいる
urllib.request:インターネット上のデータを取得
urllib.parse:URLの解決を行う
urllib.parse.urljoin:相対パスを展開するため
urllib.request.urlretrieve:リモートURLからファイルをダウンロードするため
os:ディレクトリを作成するため
os.pathパスに関連することについて解決するための「
time:スリープのため
re:正規表現のため
のそれぞれインポートします。
test_files = {}
ここでは、グローバル変数としてtest_filesを初期化します。これは、HTMLファイルの解析を行ったか判断するための変数になります。
HTMLのリンク構造は、「A.html → B.html」の逆「B.html → A.html」でリンクしている場合もあるため、無限ループに陥って処理が終了しない可能性もあります。
そのため、上記のグローバル変数を利用して、同じHTMLは二度と解析しないようにしています。
def enum_links(html, base):
soup = BeautifulSoup(html, "html.parser")
links = soup.select("link[rel='stylesheet']")
links += soup.select("a[href]")
result = []
for a in links:
href = a.attrs['href']
url = urljoin(base, href)
result.append(url)
return result
この関数ではHTMLを解析してリンクを抽出
- <a>タグのリンク、<link>タグのCSSの2種類を抽出
- どちらもBeautifulSoupのselect()メソッドを利用して抽出
- 下のforループではリンクタグのhref属性に記述されているURLを抽出、urljoinを利用して絶対パスに変換
def download_file(url):
o = urlparse(url)
savepath = "./" + o.netloc + o.path
if re.search(r"/$", savepath):
savepath += "index.html"
savedir = os.path.dirname(savepath)
if os.path.exists(savepath): return savepath
if not os.path.exists(savedir):
print("mkdir=", savedir)
makedirs(savedir)
try:
print("download=", url)
urlretrieve(url, savepath)
time.sleep(1)
return savepath
except:
print("ダウンロード失敗:", url)
return None
この関数ではインターネット上からファイルをダウンロード
- はじめに元のURLから保存ファイルを指定し、必要に応じてダウンロード先のディレクトリを作成
- if文のあとは、実際のダウンロードを行うときの処理
- 一時的に処理を停止するtime.sleep()メソッドを利用して1秒間待機させていますが、これはファイルをダウンロードする際にWebサーバに負荷を与えないための処理になります。
def analize_html(url, root_url):
savepath = download_file(url)
if savepath is None: return
if savepath in test_files: return
test_files[savepath] = True
print("analize_html=", url)
html = open(savepath, "r", encoding="utf-8").read()
links = enum_links(html, url)
for link_url in links:
if link_url.find(root_url) != 0:
if not re.search(r".css$", link_url): continue
if re.search(r".(html|htm)$", link_url):
analize_html(link_url, root_url)
continue
download_file(link_url)
この関数ではHTMLファイルを解析して、リンク先をダウンロード
- 解析済みなら同じファイルを解析しないようにする
- 変数であるhtmlとlinksを利用してリンクを抽出
- download_file()関数のurlretrieve()メソッドを利用してダウンロードした後に、ダウンロード済みのファイルを読み込んで処理
- forループは、リンク先を確認してリンクが指定サイト外をさしていた時にダウンロードしないように処理
- もしCSSファイルなら強制的にダウンロードするよう処理
if __name__ == "__main__":
url = "任意のURLを入力"
analize_html(url, url)
このif文ではどのサイトをダウンロードするのか指定
from bs4 import BeautifulSoup
import urllib
import urllib.request
from urllib.parse import urlparse
from urllib.parse import urljoin
from urllib.request import urlretrieve
from os import makedirs
import os.path, time, re
test_files = {}
def enum_links(html, base):
soup = BeautifulSoup(html, "html.parser")
links = soup.select("link[rel='stylesheet']")
links += soup.select("a[href]")
result = []
for a in links:
href = a.attrs['href']
url = urljoin(base, href)
result.append(url)
return result
def download_file(url):
o = urlparse(url)
savepath = "./" + o.netloc + o.path
if re.search(r"/$", savepath):
savepath += "index.html"
savedir = os.path.dirname(savepath)
if os.path.exists(savepath): return savepath
if not os.path.exists(savedir):
print("mkdir=", savedir)
makedirs(savedir)
try:
print("download=", url)
urlretrieve(url, savepath)
time.sleep(1)
return savepath
except:
print("ダウンロード失敗:", url)
return None
def analize_html(url, root_url):
savepath = download_file(url)
if savepath is None: return
if savepath in test_files: return
test_files[savepath] = True
print("analize_html=", url)
html = open(savepath, "r", encoding="utf-8").read()
links = enum_links(html, url)
for link_url in links:
if link_url.find(root_url) != 0:
if not re.search(r".css$", link_url): continue
if re.search(r".(html|htm)$", link_url):
analize_html(link_url, root_url)
continue
download_file(link_url)
if __name__ == "__main__":
url = "任意のURLを入力"
analize_html(url, url)
以上になります。
おわりに
parseして情報を得るだけの簡易スプレイピングなら、BeautifuSoupを使わずにlxmlで十分なのかなという印象がありました。Python(lxml)でhtmlを処理する まとめ
Pythonによるスクレイピング&機械学習 開発テクニック BeautifulSoup,scikit-learn,TensorFlowを使ってみようの2章までは主にスクレイピングの話で、requests+BS4+Selenium+PhantomJSを使った実践的なコードと、cronの操作、WebAPIといった内容になります。
3から7章は、sklearnからTensorFlow、MecabとCabochaによる自然言語処理、ベイズ、マルコフ連鎖の実装、OCRやCNNでの画像認識… といった実践機械学習の内容でした。
一通り触れてみて、PythonによるWebスクレイピングから機械学習分析までの全体感が垣間見える感覚がありました。とはいえまだまだ理解が及んでいないので、少しずつ勉強を進めていきたいと考えています。