CapsNetについて少し調べて、まとめました。
CNNの欠点
I believe Convolution, but I don't believe Pooling. - Geoffrey Hinton
Geoffrey HintonさんがMITでの講演でそう言いました。
- CNNでは、オブジェクトの向き、空間的な特徴の抽出は難しいです。
畳み込みはオブジェクトの特徴を抽出するだけです。周囲の情報には全く関心を持っていません。
例えば、人間の顔に対して、CNNはこの画像に耳、鼻、目、口があるかどうかしかに興味がありません。どこにあるのかは如何でもいいです。

(From: Capsule Networks Explained)
- プーリング層の使用は大間違いです。
この問題を解決するため、プーリング層が導入されてました。プーリングの処理によって、モデルが微小な変化に対する不変性があります。
The pooling operation used in convolutional neural networks is a big mistake and the fact that it works so well is a disaster. - Geoffrey Hinton
プーリングの処理は空間変化の同等性(Translation Equivariance)ではなくて、空間変化の不変性(Translation Invariance)です。
微小な変化に対する不変性が持つと同時に、実際の大事な空間情報が失われます。
- CNNでの学習は大量なデータが必要となります。
空間の特徴が学習できないため、オブジェクトの向き、場所が違う大量なデータを用意しなければなりません。
Capsule
プーリングでの処理は空間特徴の抽出ではなくて、オブジェクトの回転、移動に対する不変性です。Hintonさんは、不変性ではなくて、その回転、移動の特徴を認識できるモデルを作りたいです。そうして、「Capsule Network」が誕生されました。
- Capsuleには下層からの空間情報が保存されます。
- 画像特徴の場所が変化する時、認識の結果は変わらないですが、空間情報が変わります。
下図はcapsuleと従来Neuronの違いを示しました。
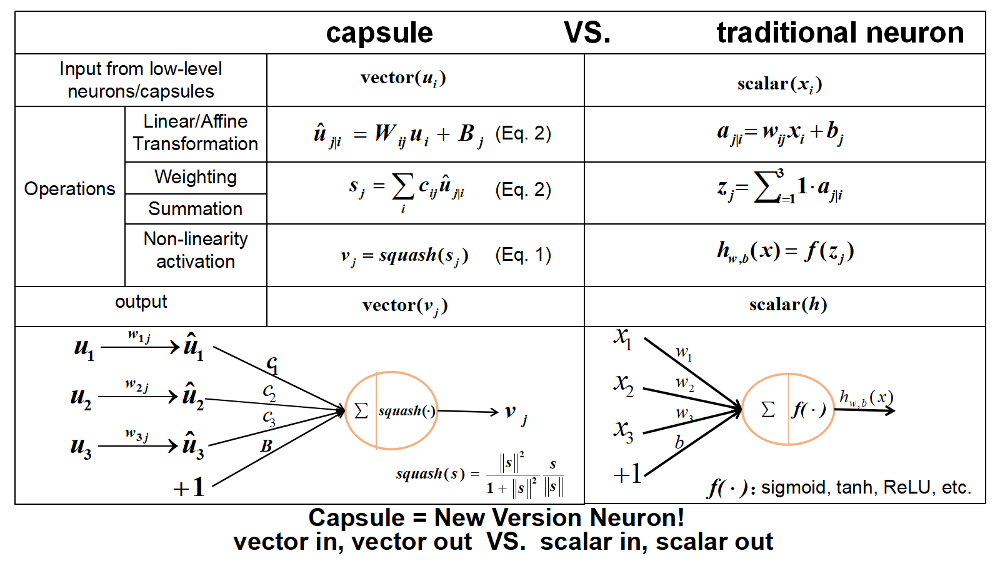
(From: Github: CapsNet-Tensorflow)
自分の理解では、従来Neuronの入力はスカラー量、計算はベクトルラベルであり、capsuleの入力はベクトル、計算はテンソルレベルです。
簡単に理解すると、「capsule = 従来Neuron + 一次元の情報」です。
下図はcapsule各部分についての説明です。
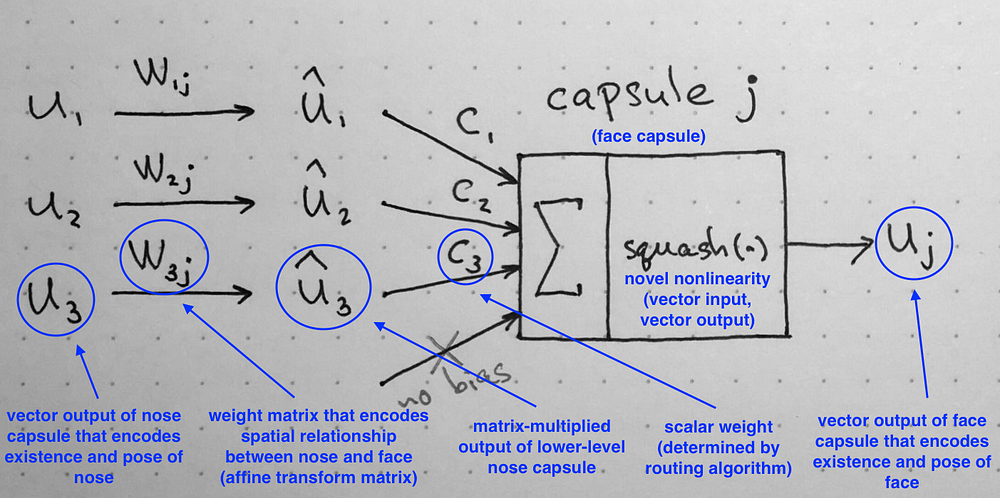
(From: Understanding Hinton’s Capsule Networks. Part II: How Capsules Work.)
- $ w_{ij} $には、Low-layerから入力された特徴の空間情報を保存します。
- Capsuleの重み$ c_{i} $は、従来CNNの重みのイメージです。ある出力に対して、各特徴$ \hat{u}_{i} $の重みを保存します。
- しかし、$ c_{i} $の学習は従来CNNのBP法ではなくて、Dynamic Routingの新しい手法を使っています。ここで、何回の内部学習で、$ c_{i} $を計算します。
CapsNet on MNIST
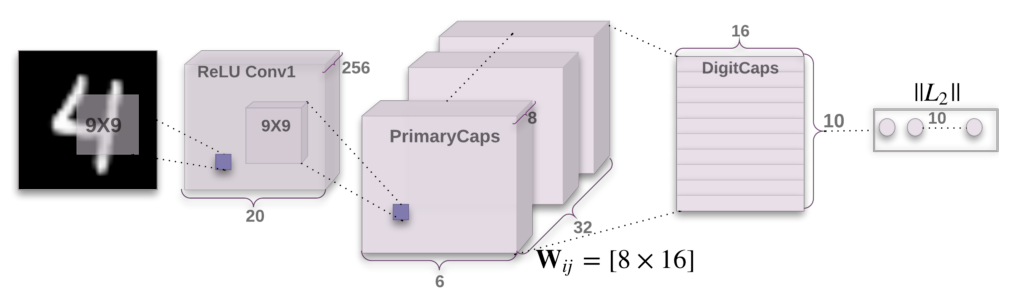
論文Dynamic Routing Between Capsulesで紹介されたMNISTへの応用です。
まずは、32 channels 9x9 kernelsの畳み込み層です。
「なぜ最初はCapsuleを使わず、普通の畳み込み層となっていますか?」っていう質問があるかもしれません。
Capsuleはhigh-level特徴から空間情報の抽出するのはうまくできるが、ピクセル単位での処理は逆に良くない結果が出てくるかもしれません。
Relu Conv1では、256 x 20 x 20の入力から32 x 8 x 6 x 6の出力へ変換します。
普通の畳み込み処理では(1 x) 6 x 6の出力ですが、ここでは、「1」のScalar から 長さ「8」のVector になります。
PrimaryCapsでは、上記のCapsuleの処理を行います。
DigitalCapsはVector単位の全結層のイメージです。
普通のCNNでは、各クラスの確率を出力するんですが、ここでは、長さ「16」のVector の出力になります。
最後にL2ノルマをかけて、各クラスの確率を出力します。
結果としては、
- MNIST: 0.25% test error rate(3Layers+3Routingの単純なモデル)
- CIFAR-10: 10.6% test error rate(背景の影響が考えられる。さすがにモデルが単純すぎるかな。)
- smallNORB: 1.4% test error rate
感想
かなり面白い研究だと思います。
CNNと比べると、CapsNetがより人間視覚処理に近づいています。
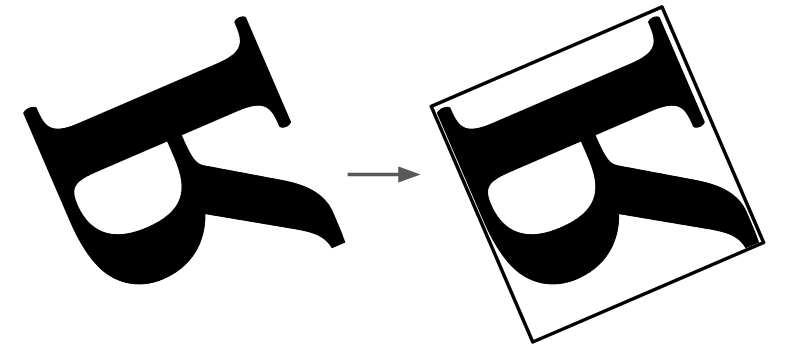
下の画像を見てください。
「R」だと思う人はほとんどだと思いますが、実はこれが水平反転したRです。
人間の脳には、座標みたい空間情報が何らかの形式で保存されますが、CNNでは同じような処理が難しいじゃないですか。
論文で紹介されたモデルは単純な3レイヤー構造のみです。
応用にはもっと複雑なモデルを構築する必要がありますが、今後の発展に期待しています。
REFERENCES
- Paper: Dynamic Routing Between Capsules
- Paper: MATRIX CAPSULES WITH EM ROUTING
- Understanding Hinton’s Capsule Networks. Part I: Intuition.
- Understanding Hinton’s Capsule Networks. Part II: How Capsules Work.
- What is a CapsNet or Capsule Network?
- Capsule Networks Explained
- Github: CapsNet-Keras
- Github: CapsNet-Tensorflow
- Kaggle: CapsuleNet on MNIST
- Video: Geoffrey Hinton talk "What is wrong with convolutional neural nets ?"
- Zhihu (Chinese)