最近、仕事関係でElasticsearchを使い始めました。
メモとして、データ投入からスコアリングまで使った・学んだことを書いてみようと思います。
全部書くのは結構長くなりますので、前後編に分けて書きます。
前編はインストールからデータの投入まで、
後編は検索とスコアリングの話しようと思っております。
インストール
とりあえず、必要なものをインストールします。
開発環境はCentOS7です。
Elasticsearch requires at least Java 8. Specifically as of this writing, it is recommended that you use the Oracle JDK version 1.8.0_73.
バージョン8以上のJavaが必要です。
Javaのインストール
まずはJava 8をインストールします。
こちらを参考しながら進めます。
もし、すでにJava1.7の古いバージョンが入っていれば、上記のリンクにはJavaVMの切り替え方法も書いてあります。
Java7を削除してJava8を再インストールしてもいいです。
$ sudo yum remove -y java-1.7.0-openjdk
$ sudo yum install -y java-1.8.0-openjdk-devel
$ sudo yum install -y java-1.8.0-openjdk-debuginfo --enablerepo=*debug*
バージョン確認
$ java -version
java version "1.8.0_111"
Java(TM) SE Runtime Environment (build 1.8.0_111-b14)
Java HotSpot(TM) 64-Bit Server VM (build 25.111-b14, mixed mode)
Elasticsearchのインストール
yumでインストールできるのは2.xの古いバージョンです。
ここではElasticsearch5.0を使うので、Elasticsearch5.0をインストールします。
(最近、6もリリースされたみたいです。)
インストールはElasticsearch Docsの手順に従って進めばよいですが、起動はうまくいけませんでした。( ;∀;)
別方法として、rpmからインストールします。(現在、6はrpmインストールできません。)
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
# vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-5.x]
name=Elasticsearch repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# yum install elasticsearch
# systemctl enable elasticsearch
# systemctl start elasticsearch
起動できたかテスト
# curl localhost:9200
{
"name" : "3Y-W_H1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "cYenb8Q8S22EHcxJPL7k2Q",
"version" : {
"number" : "5.0.0",
"build_hash" : "253032b",
"build_date" : "2016-10-26T04:37:51.531Z",
"build_snapshot" : false,
"lucene_version" : "6.2.0"
},
"tagline" : "You Know, for Search"
}
起動できましたね。
kibanaのインストール
Elastic Docを参考に。
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
# vim /etc/yum.repos.d/kibana.repo
[kibana-5.x]
name=Kibana repository for 5.x packages
baseurl=https://artifacts.elastic.co/packages/5.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# yum install kibana
# systemctl enable kibana
# systemctl start kibana
接続を設定します。
# vim /etc/kibana/kibana.yml
network.host: "0.0.0.0"
elasticsearch.url: "http://localhost:9200"
# systemctl restart kibana
ブラウザで開きましょう。
http://192.168.216.128:5601
無事につなぎました。((´∀`))
Kuromojiのインストール
日本語分析用のpluginもインストールしましょう。
# /usr/share/elasticsearch/bin/elasticsearch-plugin install analysis-kuromoji
# systemctl restart elasticsearch
# curl -X GET 'http://localhost:9200/_nodes/plugins?pretty'
…
"plugins" : [
{
"name" : "analysis-kuromoji",
"version" : "5.0.0",
"description" : "The Japanese (kuromoji) Analysis plugin integrates Lucene kuromoji analysis module into elasticsearch.",
"classname" : "org.elasticsearch.plugin.analysis.kuromoji.AnalysisKuromojiPlugin"
}
],
…
おまけ
クラウド版のElastic Cloudもあります。(14日の無料試用期間があります。)
Elasticさんは独自のサーバーではなくて、AWSのサーバーを利用しています。
完全にブラウザでGUI操作は便利ですけど、サーバーの裏側(CUI)に入れないとも不便です。
Pythonを使ってデータの投入
一つ目はkuromojiを使ってみたいので、Twitter情報を取り込んで、日本語分析してみます。
二つ目はkibanaの地図を使ってみたいので、地震情報を投入してみます。
1.Twitter情報の分析
Twitter収集などにはあまり詳しくないので、こちらの内容を参考にして進めていきます。
# python -V
Python 3.5.2 :: Anaconda 4.1.1 (64-bit)
まずは、必要なパッケージをインストールします。
# pip install twitter
# pip install elasticsearch
マッピング
SQLみたいに、Elasticsearchも事前にデータ構造を決めた上で、データを投入しなければなりません。
Elasticsearchはindex-type-idの構造になっています。
データを投入する時に、indexとtypeは指定する必要がありますが、idは指定しなくていいです。
この場合は、自動で22桁のUUIDsが入ってきます。
| SQL | Mongo | Elastic |
|---|---|---|
| DB | DB | index |
| table | collection | type |
curlを使ってマッピングできますが、kibanaのDev Toolsではもっと便利だと思います。
PUT /twi_index
{
"settings":{
"index":{
"analysis":{
"tokenizer" : {
"kuromoji" : {
"type" : "kuromoji_tokenizer",
"mode" : "search"
}
},
"analyzer" : {
"japanese" : {
"type": "custom",
"tokenizer" : "kuromoji",
"filter" : ["pos_filter"]
}
},
"filter" : {
"pos_filter" : {
"type" : "kuromoji_part_of_speech",
"stoptags" :["接続詞","助詞","助詞-格助詞","助詞-格助詞-一般","助詞-格助詞-引用","助詞-格助詞-連語","助詞-接続助詞","助詞-係助詞","助詞-副助詞","助詞-間投助詞","助詞-並立助詞","助詞-終助詞","助詞-副助詞/並立助詞/終助詞","助詞-連体化","助詞-副詞化","助詞-特殊","助動詞","記号","記号-一般","記号-読点","記号-句点","記号-空白","記号-括弧開","記号-括弧閉","その他-間投","フィラー","非言語音"]
}
}
}
}
},
"mappings": {
"twi_type":{
"properties":{
"created_at" : {
"type" : "date"
},
"text" : {
"type" : "text",
"analyzer": "japanese",
"fielddata": true
},
"track": {
"type": "keyword"
}
}
}
}
}
settingsでanalyzerを定義します。
textにはTwitter内容保存用として、日本語分析が必要なので、analyzerを指定します。
trackは分析したくないので、typeはkeywordを指定します。
kuromojiの設定方法はこちらが参考になります。
ここでは、kuromoji_part_of_speechのフィルターを使って、特定の品詞(助詞、格助詞、記号)を除外します。
データ投入
ほとんど丸ごとでyoppeさんのスクリプトを使います。
ほんの少し修正したスクリプトはGithub上に入れました。
結果
ちょっと時間を経ってから、Kinabaでデータを確認しましょう。
データをkibanaにインポートします。
Discover - trackを選択します。
Visualize - pie chart - twi_index
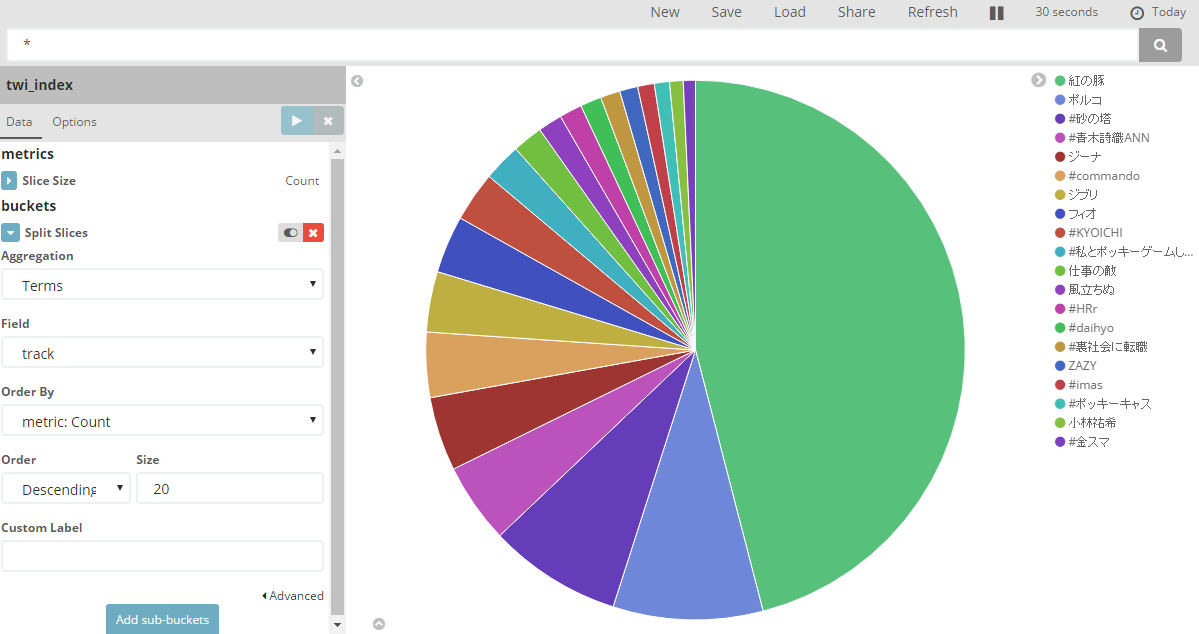
この日(16/11/11)にテレビで「紅の豚」が放送されてたので、Twitterで話題になりました。( ´∀` )
*その他
・GET _aliasesを使って、index一覧をチェックできます。
・Field datatypeについて
・2.xでテキストはstringタイプを使用しますが、5.xからはtextとkeywordになっています。
Keyword fields are only searchable by their exact value.
If you need to index structured content such as email addresses, hostnames, status codes, or tags, it is likely that you should rather use a keyword field.
・textは分析が必要の際に使用、keyworsは検索の際に完全一致の必要がある場合に使用します。
最後に、せっかくkuromojiを使ったので、効果を確認しましょう。
kuromojiを使わず:
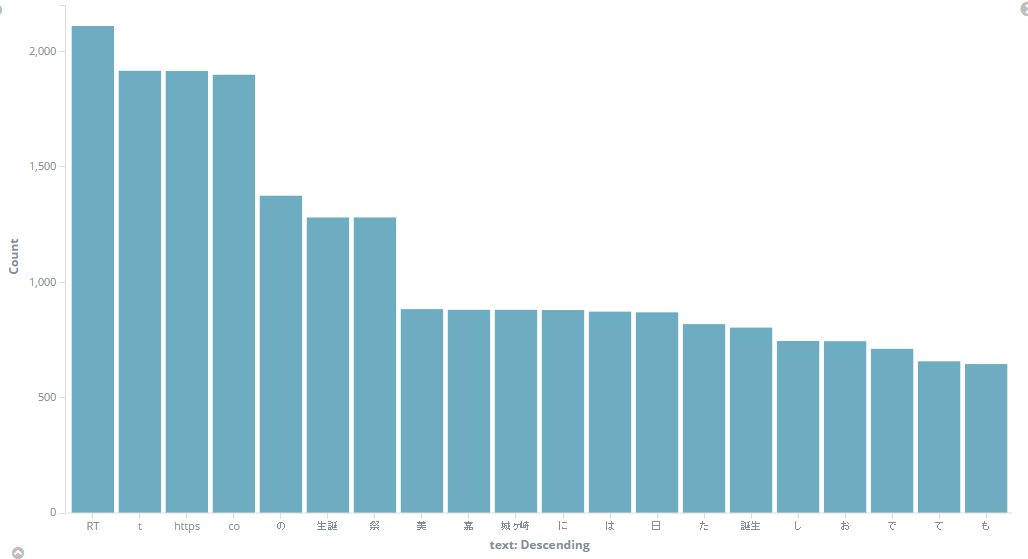
kuromojiを利用:
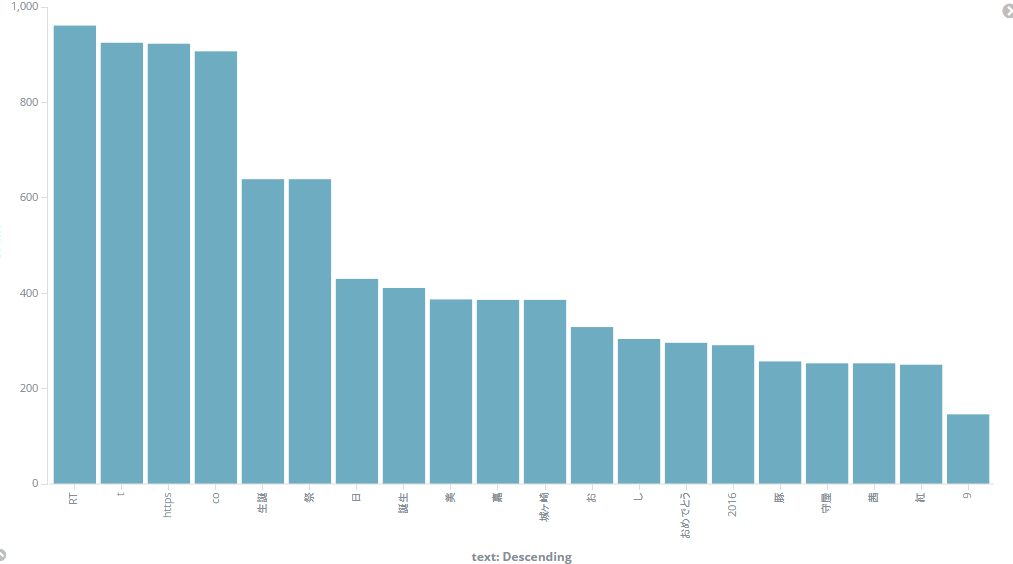
微妙だけど、少しよくました。
まぁ、Twitterで流している情報は専用名詞が多くあるから、ユーザ辞書を定義しないと、分析は難しいですね。
2.地震情報
使用する情報源はP2P地震情報さんが提供してるJSON APIです。
マッピング
PUT /earthquakes
{
"mappings": {
"earthquake": {
"properties": {
"time": {
"type": "date",
"format":"yyyy/MM/dd HH:mm:ssZ"
},
"place": {
"type": "text"
},
"location": {
"type": "geo_point"
},
"magnitude": {
"type": "float"
},
"depth": {
"type": "float"
}
}
}
}
}
データ投入
スクリプトはGithubに置きました。
実は半年前に書いたコードなんです。
実行はできますけど、おかしなところもありますね。
時間があれば、直します。
結果
Kibanaで確認しましょう。
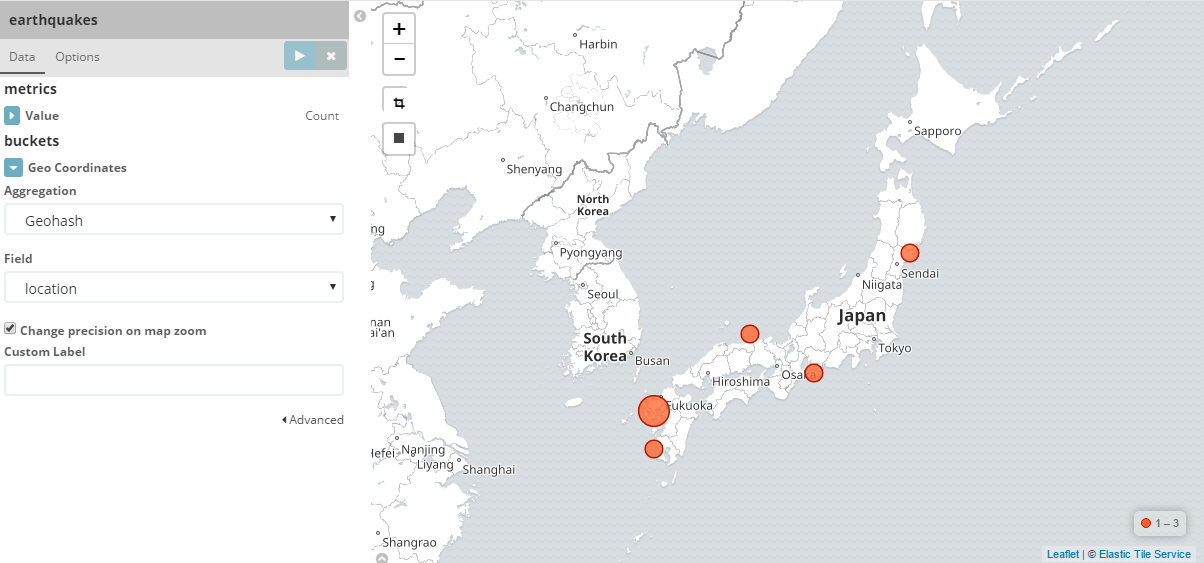
前編はここまでです。
後編の検索、スコアリングについてはどんなデータを分析しようかなを考えてます。