注意!
- この記事はプログラミング中~上級者向けです。HSP、ポインタ、メモリ、エンディアン、C言語をある程度理解できている人向けです。
- この記事を読んで「ポインタとかわかんないけどこれ読んで理解しよう!!!」と思ったそこの方、私の説明能力が足りませんので無理です。
- HSPの開発サイドの人間ではないので、こういう使い方が良いのか悪いのかとか分かりません。「ひらめいたので勝手にやってみたらできた」、それだけです。
- この記事の情報は、すべてWindows版Hot Soup Processor 3.5に基づいています。HSP2.x、HSP3dish版、Raspberry Pi版HSPなどはこの限りではありません。
概要
dupptrは、公式リファレンスには次のように記されている。
指定したアドレスポインタを指している変数を作成します。
クローン変数は、メモリ上の情報を参照するための数値型配列変数として機能するようになります。
dupptr命令は、 DLL等の外部関数で取り交わすメモリ参照や低レベルでの変数バッファ操作を行なうための機能として用意されています。
「外部DLL使うときは.asをインクルードして偉い人が#deffuncしてくれたやつで使うわ」と思った、大きいアプリを作ったらバグだらけになって挫折するタイプのHSP歴5年のそこのキミ!
これはDLLへのアクセスのみに使うのではない。任意のメモリを変数として定義して使えるこの命令は、コードの可読性向上、一層の高速化、その他諸々のよい効果に繋がる可能性のある、いわば「魔法の命令」なのだ。
どういうことか
この命令は、「アクセス可能なメモリ領域ならどこにでも任意の変数を作れる」という点が優れている。DLLが使ったメモリだけでなく、HSP自身が使用した命令でも変数を作成できる。
dupptrの基礎
次の例を見てみよう。
dim a
dupptr b , varptr(a) , 4 , 4
1行目のdim aは普通にINT型の変数を定義しているだけだ。
2行目でdupptrを使っている。この命令の用法は、
dupptr 変数名,p1,p2,p3
変数名 : クローンを作成する変数名
p1=0~ : クローン元のメモリアドレス
p2=0~ : クローン元のメモリサイズ
p3=1~(4) : クローン変数の型指定
と公式リファレンスに記されている。
1つ目のパラメータ(変数名)は新しく作る変数の名前(ここではb)を指定している。
2つ目のパラメータ(p1)はクローン元のメモリアドレス指定だ。ここではvarptr関数を使用して変数aのポインタを指定している。
3つ目のパラメータ(p2)はメモリサイズの指定だ。ひとつのINT型変数のサイズは4バイトなので、ここでは4を指定している。
4つ目のパラメータ(p3)はクローン変数の型を指定する。bをINT型にしたい場合はここを4にする。
aとbは同じメモリアドレスを指す、同じ形式の変数ということになり、結果として、この操作でクローン変数ができているということになる。
この状態で、
a=1
mes b
などすると、画面に1と表示される。aとbは同一の変数だからだ。
dupptrを文字列変数に使う
本題はここからだ。このdupptr命令は、確保した変数(メモリ)なら型が違っても利用することができる。次のコードを見ていただきたい。
sdim a,8
dupptr b , varptr(a) , 4 , 4
このコードは先程と1行目が違う。aが文字列型変数になっているのだ。この状態でbに値を代入するとどうなるだろう。
b = 65
mes a
とすると、
A
と表示される。
一体どうしてこのようなことが起こるのだろうか。答えは、メモリを視覚化すれば一目瞭然だ。
メモリの中身
日本語が苦手な人は図だけ見てください。
文字列型変数aを定義したとき、実際にはメモリは以下のようになっている。
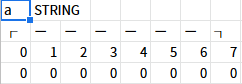
この図では、変数aにどのようなバイナリが含まれているのかを、領域を1バイト単位で区切りながら見ている。上段はメモリアドレス、下段はそれぞれのアドレスに入っているデータである。
変数aは文字列型でサイズは8バイト、そのひとつひとつに0x00が代入されている。(sdimで"初期化"したら内容が0x00になるのは確か仕様には書いてなかったと思うが、必ず0x00になる。)
実際には、変数aの先頭アドレスは0ではないけれど、ここでは便宜上0とする。
この状態で
dupptr b , varptr(a) , 4 , 4
を実行すると、以下のようになる。
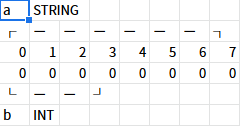
bという名前のINT型の変数を作成するとき、varptr(a)で変数aのポインタを利用している。varptrを使うと引数に指定した変数の先頭アドレスが取得できる。
ここではaの先頭アドレスは0なので、変数bは、"メモリの0番地を起点としたINT型の変数"、ということ、つまり、"変数aの先頭の一部領域を使った変数"になる。
実はHSPのメモリ操作は結構ガバガバだ。C++との相互運用を念頭に置いているのだろうか。
このようになったときに、
b = 65
を実行すると、メモリはこのようになる。
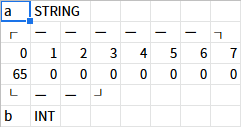
この図を見て、「ん?bに 65 を代入したのになんで 00 00 00 65 じゃなくて 65 00 00 00 なんだ?」と思った人は鋭い。
Intel x86では、下位バイトのほうから先にメモリに配置される。これを「リトルエンディアン」という。例えるなら、「ひゃくにじゅうさん」という数を 「321」 と1の位から準に書くようなものだ。
気持ち悪いよね。私も最初はそう思いました。でもこれはどうやらこの方式のほうが処理のパフォーマンス的に都合が良いらしい。
取り敢えず、分からなければWikipedia見ようか。
bの内容を変更したことで、領域を共有するaの中身も変更された。文字列型変数aの中身はどのようになっているのだろう。
変数aのメモリは、先程の操作で以下のようになった。
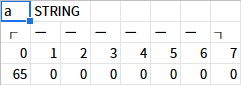
文字列型変数なので、この内容はひとつひとつが文字コードだ。文字に変換してみよう。
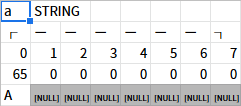
おわかりいただけただろうか。変数aは先頭が"A"、後は全部NULL(無効な文字)が入っている。
なるほど、
mes a
をすると、
A
と表示されるわけだ。
複数個の変数を詰め込む
このようなdupptrの使い方をすると、ひとつの文字列型変数に、複数の変数を詰め込むこともできる。次のコードを見てみよう。
sdim a , 16
dupptr b , varptr(a) , 4 , 4
dupptr c , varptr(a)+4 , 4 , 4
dupptr d , varptr(a)+8 , 8 , 3
先程のように、メモリを可視化してみよう。ひとつひとつコードを読み解いていけば。以外と簡単だ。
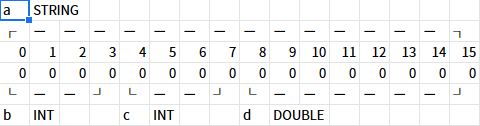
変数cを作成するとき、「クローン元のメモリアドレス」に、varptr(a)+4と、変数aの先頭から4つずらした場所を指定している。こうすることで、変数aの領域上に、かつ変数bの領域と重複しないように、変数cを作成することができる。
変数dは、DOUBLE型になっている。DOUBLE型はサイズが8バイトだが、やることはほとんど同じだ。
注意すべき点は、double型の変数のあとにも別の変数を詰め込むなら、その変数は8つポインタをずらさなければならない。うっかりすれば変数同士の領域が被って、意図せず操作していない変数の中身が変わってしまう事になりかねない。分からなくなれば上図のようにメモリに何を詰め込んでいるのかを書き出してみるのも必要だ。
dupptrを利用することの利点
どのようなときに、dimよりもdupptrのほうが優れているのだろうか。答えは、「複数の変数をまとめてひとつで扱うとき」だ。
ゲームデータのセーブ・ロード
次の動画に、この記事を書きながら30分くらいで作ったクソゲームがある。このゲームを例に取ってみよう。
![[HSP3]dupptr参考動画](https://qiita-user-contents.imgix.net/https%3A%2F%2Fi9.ytimg.com%2Fvi%2FyeM5QFCh4ss%2Fhqdefault.jpg%3Fsqp%3DCJTB_uIF%26rs%3DAOn4CLCnwJSu0ZH16oPEmp9BH8dqzcA6_A?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=bdbc16cbb99c71236ac044388101a204)
このゲームでは、スコア、自機の座標、餌の場所などのデータをすべてdupptrを使って、文字列変数gamedata上に定義している。
このとき、gamedataに操作することでこれらのデータをすべてまとめて1つとして扱うことができるのだ。具体的には、
stick ky,15
//...
if ky&16{
bsave "savedata.bin",gamedata,24
mestxt="saved"
}
スペースキーを押すと、gamedataの内容を"savedata.bin"にセーブする。gamedataにはゲームに関するデータがまるごと入っているので、1行のコードでそれらを一気にセーブできる。
そして、
if ky&64{
bload "savedata.bin",gamedata,24,0
mestxt="loaded"
}
Ctrlキーを押すと、gamedataに"savedata.bin"の内容をロードしている。gamedataの領域は複数のゲームデータに関する変数が共有しているので、結果的に複数のデータを1行で読み込めることになる。
そしてそれらを実際にやっているのが動画だ。セーブしてゲームを閉じてからもう一度ゲームを開いてロードしているが、セーブしたときの状況に復帰していることがわかるだろう。
構造体
同じ原理で、Windows APIの返り値が構造体だったとき、dupptrを使うことで、構造体のメンバひとつひとつをそれぞれ変数として読み出すことができる。ひとつひとつstrmidなりintなりの関数を使うよりも高速だ。
注意すべきは、整数型でも4バイト型ではなく8バイト型や2バイト型だったりすることだ。この場合はdupptrを使うときでも定義する変数はINT型にはできず、STR型の変数としておいて、lpeekなどを使って値を取得することになる。(残念ながらHSPには8バイトpeek命令はない。残念!)
バイナリの読み込み
形式が分かっているバイナリデータを読み込んで、その形式に合わせてdupptrすることで、バイナリデータの項目ひとつひとつを変数として扱うことができる。
しかし、ここでは構造体のときの注意点とは別に、もうひとつ気をつけなければならないことがある。ちょっと前に説明した「エンディアン」のことだ。
一部のバイナリデータは、データが「ビッグエンディアン」で格納されている。(Standard Midi Formatなど。)これを忘れると、INT型などのデータを取得したときに変な値が取れる。
「ひゃくにじゅうさん」を「321」とリトルエンディアンで書いているのを「さんびゃくにじゅういち」と(ビッグエンディアンとして)読むようなもんで、そりゃ正しい値が出てくるはずがない。
エンディアン変換関数はHSPにはないので、この変換は自分で実装するしかない。(簡単なのだが、結果多少パフォーマンスが下がることになってしまう。)
あとがき
HSPを初めて8年が経過したこのタイミングで、こんな便利で興味深い機能を見つけることができたの、やっぱり奥が深い言語だなとおもいました。