DeepFake関連の研究に興味があり現状どれくらいの動画が作れるのか気になったので、簡単なフェイク動画を作ってみました。
細かい手作業の編集や面倒なアノテーションは一切やらずにほぼDL技術のみで実装しています。
フェイク動画の対象としてヒカキンさんを利用させていただいています。
10周年おめでとうございます。
結果
まず結果をお見せすると、このような動画になりました。
フェイク動画と言えるような動画にはなりませんでしたが、データ作成も動画生成も自動で行っている割にはよくできているのではないかと思います。
他の手法を使ったり音声のアノテーションをすることでより良いフェイク動画になると思います。
以下で概要を説明していきます。
DeepFakeとは
高度な画像生成技術を駆使して合成され、偽物とは容易に見抜けないほど作り込まれた偽動画の通称である
Weblio辞書の定義ではこのようになっています。主にDeep Learningを用いて作られて高精度なフェイク動画のことを言うのだと思います。
フェイク動画例
DeepFakeによって作られた有名なフェイク動画として以下のものがあります。
オバマ前大統領のフェイク動画で、トランプ前大統領の悪口を言っていたりするのですが
動画の後半で分かるとおり、コメディアンの動画をオバマ前大統領に変換したものになっています。
こちらはエリザベス女王がクリスマスのスピーチをする動画ですが、これもフェイク動画でフェイクニュースへの警鐘を鳴らす目的で製作されました。
こちらがエリザベス女王のフェイク動画に関するメイキング映像で
女優の方がスピーチしている映像を、顔入れ替えなどの技術でエリザベス女王へと変換しているのが分かります。
作成方法
DeepFake技術に関するgithubリポジトリも充実してきており
中でも DeepFaceLab というのが有名で
これを用いることで顔の入れ替え、若返りなどが簡単にできます。
ただ、上であげたようなフェイク動画の生成は少し複雑で
1. 偽人物で変換先となる動画を撮影
2. DeepFakeモデルを学習
3. 1の動画の顔を有名人で置換
4. After Effects等の編集ソフトで編集
+ 音声変換
といった作業が必要になります。
ヒカキンのフェイク動画作成
ヒカキンさんのフェイク動画を作ってみようと思ったのですが、上記のような作業をするのは相当な手間なのでより単純な方法での作成を目指しました。そこで今回は
テキストからのフェイク動画生成
つまり、喋らせたい文章のテキストから対象人物がそれを喋っている動画の生成
に絞って手法を選定しました。
関連研究
テキストや音声からフェイク動画を生成する手法をまとめました。
音声から生成する手法では、音声合成も学習させることでテキストからの生成が可能になります。
-
ObamaNet: Photo-realistic lip-sync from text (NIPS 2017) [github (unofficial)]
-
Synthesizing Obama: Learning Lip Sync from Audio (SIGGRAPH 2017) [github(非完全版?)]
-
Talking Face Generation by Conditional Recurrent Adversarial Network (IJICAI 2019) [github]
-
Talking Face Generation by Adversarially Disentangled Audio-Visual Representation (AAAI 2019) [github]
-
Text-based Editing of Talking-head Video (SIGGRAPH 2019)
-
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose (2020) [github]
-
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021) [github(学習部分なし)]
この中からgithubが公開されており、比較的自然な動画が生成できていた
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose
を使用しました。
この手法は音声からの動画生成なので、まずは音声合成から行います。
音声合成
音声合成はテキストから音声を生成することで、TTS (text-to-speech) とも呼ばれます。
今回は2017年にGoogleから発表された Tacotron2 (+WaveGlow) を使用しました。
githubも充実しており、高精度の音声合成が可能であり人気な手法です。
音声合成の他の手法やTacotron2については以下の記事を参考にしてください。
学習データの準備
音声合成の学習には
音声データと対応するテキスト
が必要です。
できるだけ綺麗な音声を使用する必要があり
通常は、準備された文章を朗読し録音することでデータを作成します。
10時間ほどのデータがあるとかなり綺麗な音声が合成できます。
しかし今回はヒカキンさんで音声合成をするので喋ってもらって録音することはできません。
そこで YouTube上の動画の音声 と 自動字幕 を利用することにしました。
綺麗なデータではないので精度は落ちますが大量のデータを用意することができます。
YouTubeからできるだけBGMや笑い声などノイズが少ない動画を探してきていくつか利用しました。
ダウンロード方法、データの分割方法などについては以下の記事を参考にしました。
今回は行っていませんが、音声に対してアノテーションして綺麗なデータを用意することで、より良い音声合成ができるようになります。(アノテーションは地獄です)
Tacotron2の学習
コードは NVIDIA/tacotron2 を使用しました。
以下の記事を参考にして、上で作成したデータを読み込みました。
コードは扱いやすく記事に従っていくと簡単に動かすことができます。
結果
Qiitaでは音声ファイルが載せられないようなので以下でお聞きください。
聞き取れるレベルで発音はできていますが、やはりノイズが多くなっています。
原因としては
- 話し言葉である
- 笑い声、どもり
- 自動字幕の間違え
- データの区切りがおかしい
などが考えらます。そもそも話し言葉の音声合成は難しい課題とされています。
それ以外の問題については手動での区切り、アノテーションでなんとかなります。
やはりより精度を高めるためには手作業で頑張る必要がありそうです。
フェイク動画生成
Audio-driven Talking Face Video Generation with Learning-based Personalized Head Pose
を利用してフェイク動画を生成します。
- 音声
- 対象人物の10秒ほどの動画
の二つを与えることで、対象人物がその音声を喋っている動画を生成することができます。
デモ動画は以下から確認することができます。
発音に合わせて口の形やポーズが生成されていることがわかります。
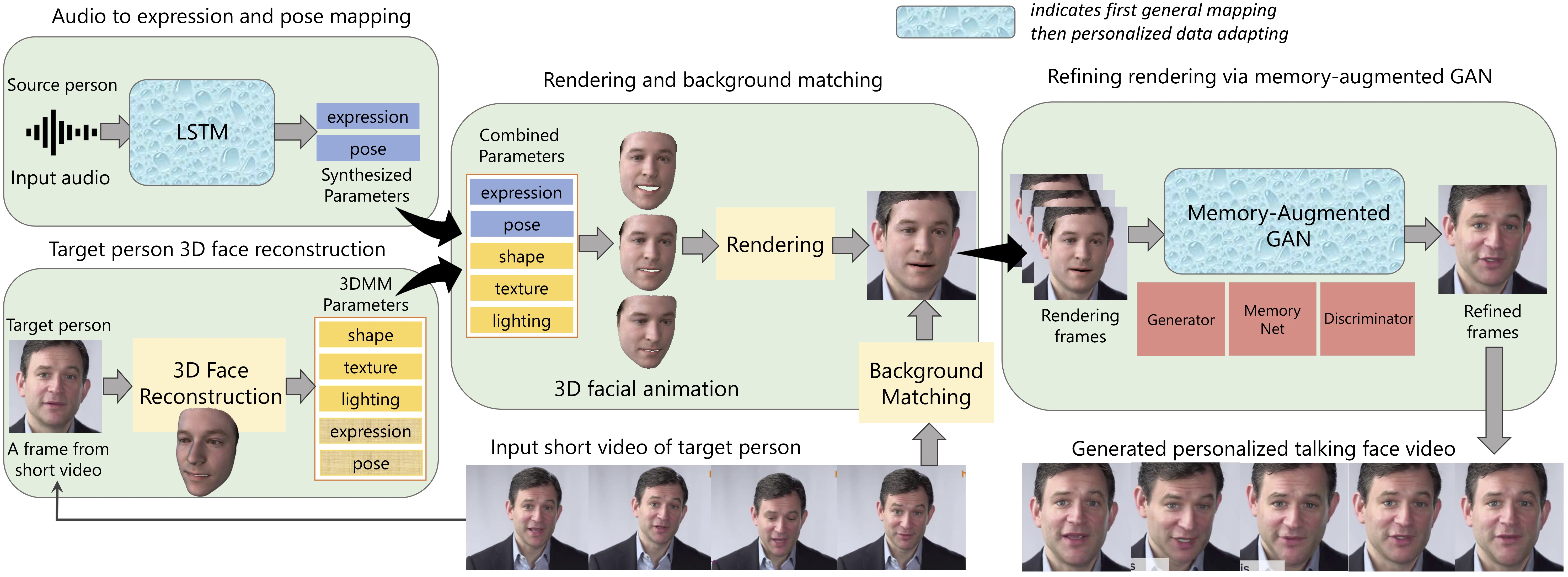
パイプラインはこのようになっています。
学習には動画のみを使用します。
10秒ほどの動画を用いて、左上のLSTMと最後のGANを追加で学習させることで生成が可能になります。
学習後は任意の音声に対して動画の生成を行うことができます。
今回は 音声合成で生成されたヒカキンさんの音声 と YouTube動画から10秒ほど切り抜いたもの を使用して実行しました。
MATLABが必要であったりするのですが、READMEにしたがって実行していけば動くと思います。
以上になります。
ありがとうございました。