はじめに
文分類では、Convolutional Neural Networks (CNN)にmax poolingが使われることが多いですが、他のpooling方法はだめなのかなと思って検証してみました。
データ
- ソースコード
- Chainerで実装してます。
- omr001@github
- データセット
- Stanford Sentiment Treebank (SST)を使ってます。
- こちらでダウンロードできます。
- 単語分散表現
- word2vecの学習済みモデル(GoogleNews-vectors-negative300.bin.gz)を使ってます。こちらでダウンロードできます。
文分類とは?
文のラベルを当てるタスクです。例えば上記のSSTではポジティブとネガティブのラベルが各文についています。
[ポジティブ] 彼女は性格もいいし、なによりスタイルが良いんだ。
[ネガティブ] 今期のアニメは不作ですね。
SSTは英語ですが、日本語の例だとこんな感じです。
ポジネガの他にも、スポーツや政治など何の話題についてかをあてるデータセットもあります。
ネットワークモデル
Convolutional Neural Networks for Sentence Classification[Kim,2014]を元にしました。
自然言語処理の分野では、CNNの話をするときよくこの論文が引用されます。
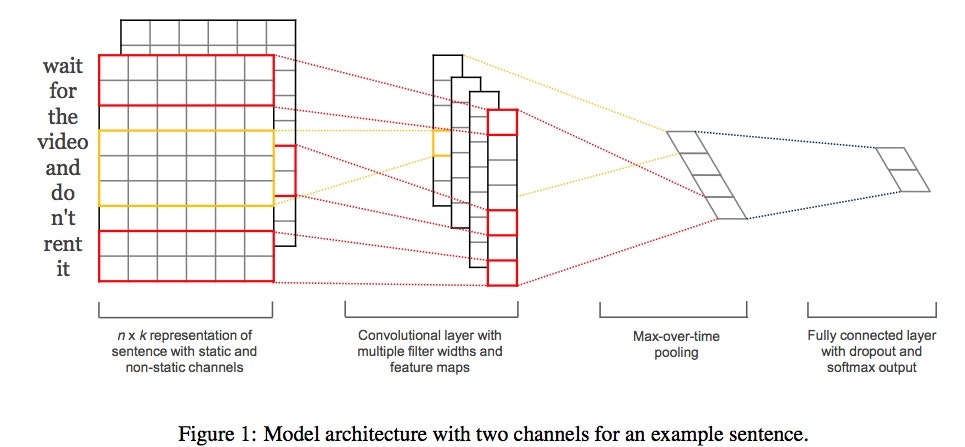
pooling層
上の図のMax-over-time pooling(max pooling)の部分がpooling層です。今回はここの話。
CNNではmax poolingの他にaverage poolingというものも使われることがあります。
max poolingは特徴マップから一番大きい値を取り出しますが、average poolingは特徴マップの値の平均を取り出します。
こちらの論文ではaverage poolingよりmax poolingのほうが一部のデータセットではテキスト分類の正解率が高かったとすでに報告されています。
パディング
じゃあmax poolingでいいじゃんとなりますが、
ただ、自然言語処理では入力文の長さが同じということはないので、入力文長を揃えるパディングという処理が必要になります。
そのため厳密には文長で平均をとっているわけではなく、入力の最大文長で平均をとっています。(上で紹介した論文も多分そう、、、)
それなら、特徴マップの長さ(最大文長)で平均をとったバージョンではなくて、文の長さで平均をとったバージョンのaverage poolingならどうだろうと思って試してみました。
(例です。)
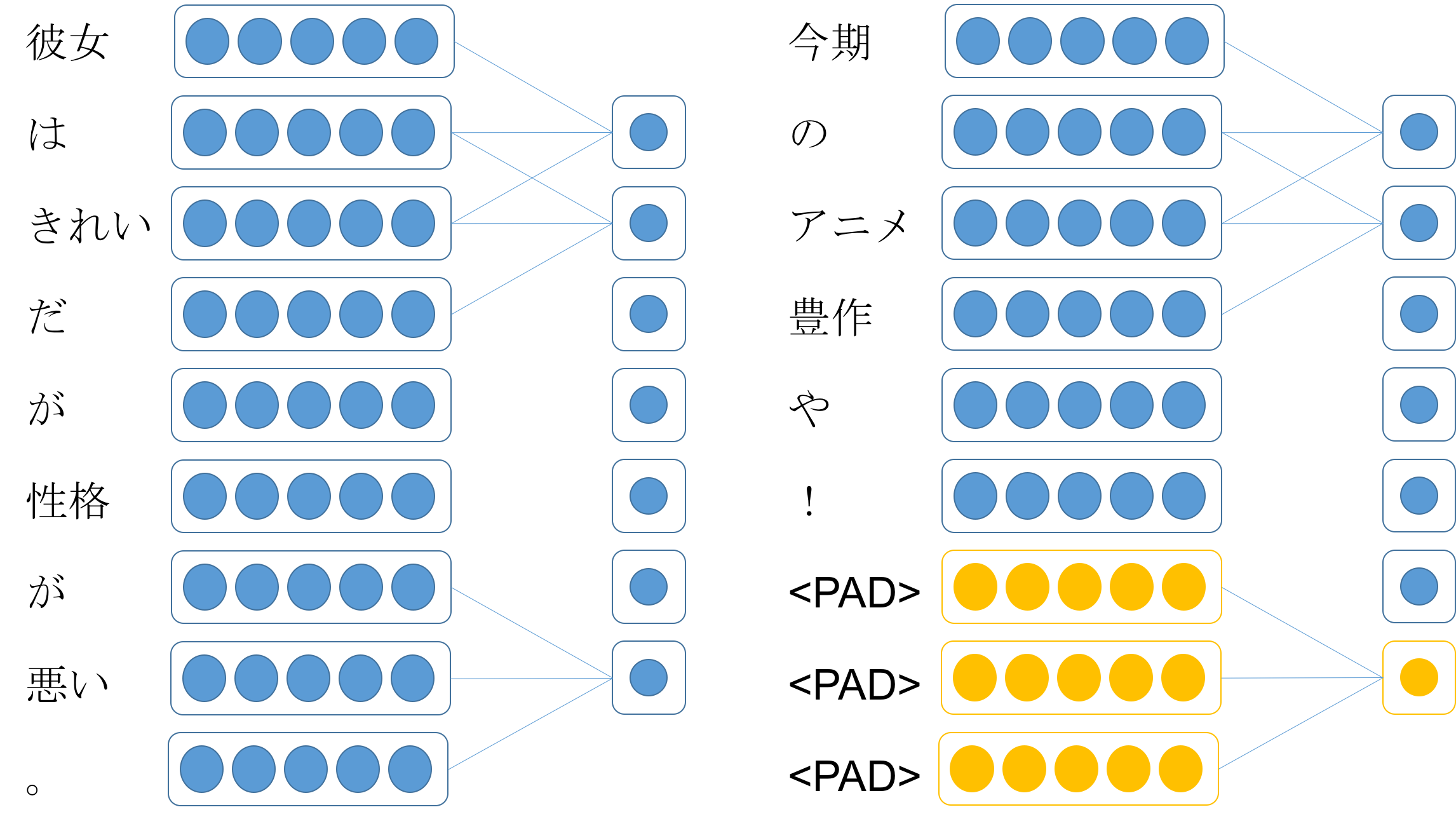
↑このように本来ない部分の<PAD>を畳み込んだ結果も平均を計算するときに足されてしまいます。
([や, !, <PAD>]のような一部に<PAD>が含まれるものは足されます。これも本来は良くないかもしれませんが、今回はあくまで文長で割るということで。。。)
コード(ネットワーク部分)
class CNN_average(Chain):
def __init__(self, vocab_size, embedding_size, input_channel, output_channel_1, output_channel_2, output_channel_3, k1size, k2size, k3size, pooling_units, output_size=args.classtype, train=True):
super(CNN_average, self).__init__(
w2e = L.EmbedID(vocab_size, embedding_size),
conv1 = L.Convolution2D(input_channel, output_channel_1, (k1size, embedding_size)),
conv2 = L.Convolution2D(input_channel, output_channel_2, (k2size, embedding_size)),
conv3 = L.Convolution2D(input_channel, output_channel_3, (k3size, embedding_size)),
l1 = L.Linear(pooling_units, output_size),
)
self.output_size = output_size
self.train = train
self.embedding_size = embedding_size
self.ignore_label = 0
self.w2e.W.data[self.ignore_label] = 0
self.w2e.W.data[1] = 0 # 非文字
self.input_channel = input_channel
def initialize_embeddings(self, word2id):
#w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/glove.840B.300d.txt', binary=False) # GloVe
w_vector = word2vec.Word2Vec.load_word2vec_format('./vector/GoogleNews-vectors-negative300.bin', binary=True) # word2vec
for word, id in sorted(word2id.items(), key=lambda x:x[1])[1:]:
if word in w_vector:
self.w2e.W.data[id] = w_vector[word]
else:
self.w2e.W.data[id] = np.reshape(np.random.uniform(-0.25,0.25,self.embedding_size),(self.embedding_size,))
def __call__(self, x):
h_list = list()
ox = copy.copy(x)
if args.gpu != -1:
ox.to_gpu()
b = x.shape[0]
emp_array = xp.array([len(xp.where(x[i].data != 0)[0]) for i in range(b)], dtype=xp.float32).reshape(b,1,1,1)
x = xp.array(x.data)
x = F.tanh(self.w2e(x))
b, max_len, w = x.shape # batch_size, max_len, embedding_size
x = F.reshape(x, (b, self.input_channel, max_len, w))
c1 = self.conv1(x)
b, outputC, fixed_len, _ = c1.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h1 = self.average_pooling(F.relu(c1), b, outputC, fixed_len, tf, emp_array)
h1 = F.reshape(h1, (b, outputC))
h_list.append(h1)
c2 = self.conv2(x)
b, outputC, fixed_len, _ = c2.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h2 = self.average_pooling(F.relu(c2), b, outputC, fixed_len, tf, emp_array)
h2 = F.reshape(h2, (b, outputC))
h_list.append(h2)
c3 = self.conv3(x)
b, outputC, fixed_len, _ = c3.shape
tf = self.set_tfs(ox, b, outputC, fixed_len) # true&flase
h3 = self.average_pooling(F.relu(c3), b, outputC, fixed_len, tf, emp_array)
h3 = F.reshape(h3, (b, outputC))
h_list.append(h3)
h4 = F.concat(h_list)
y = self.l1(F.dropout(h4, train=self.train))
return y
def set_tfs(self, x, b, outputC, fixed_len):
TF = Variable(x[:,:fixed_len].data != 0, volatile='auto')
TF = F.reshape(TF, (b, 1, fixed_len, 1))
TF = F.broadcast_to(TF, (b, outputC, fixed_len, 1))
return TF
def average_pooling(self, c, b, outputC, fixed_len, tf, emp_array):
emp_array = F.broadcast_to(emp_array, (b, outputC, 1, 1))
masked_c = F.where(tf, c, Variable(xp.zeros((b, outputC, fixed_len, 1)).astype(xp.float32), volatile='auto'))
sum_c = F.sum(masked_c, axis=2)
p = F.reshape(sum_c, (b, outputC, 1, 1)) / emp_array
return p
実験内容
Stanford Sentiment Treebank (SST)をデータセットとして、以下の4つのpooling方法を比較
- max pooling
- average pooling (1/max len) ← 最大文長で平均とるやつ
- average pooling (1/sent len) ← 各文長で平均とるやつ
- attention pooling ← pooling層にAttention機構を使ってみたものです。詳しくはこちら
実験結果
| pooling method | SST-2 | SST-5 |
|---|---|---|
| max | 86.3 (0.27) | 46.5 (1.13) |
| average (1/max len) | 84.6 (0.38) | 46.0 (0.69) |
| average (1/sent len) | 86.6 (0.51) | 47.3 (0.44) |
| attention | 86.0 (0.20) | 47.2 (0.37) |
値は5回試した時の平均で()の中の値は標準偏差です。
SST-5ていうのはvery negative,negative,neutral,positive,very positiveの5値を分類するタスクで、SST-2ていうのはneutral除いてポジネガ分類するタスクです。
max pooling結構揺れるし、やっぱり文長で平均とるaverage poolingが一番良いという結果に、、、
最大文長で平均をとるaverage poolingはたしかにmax poolingよりも弱いですね。。
特徴マップの様子を可視化
[very positive] I admired this work a lot.
という文に対して、max poolingのCNNとaverage pooling (1/sent len)のCNNの特徴マップがどう学習されているかを確認してみました。
admired(賞賛する)というポジティブな意味を表す単語と、それを強調するa lotが予測のポイントとなる文です。
ここでのCNNのウィンドウサイズは3。特徴マップの数は100個です。
まずmax poolingのほう。。。こいつはこの文を[positive]と間違えて予測しちゃいます。惜しい。
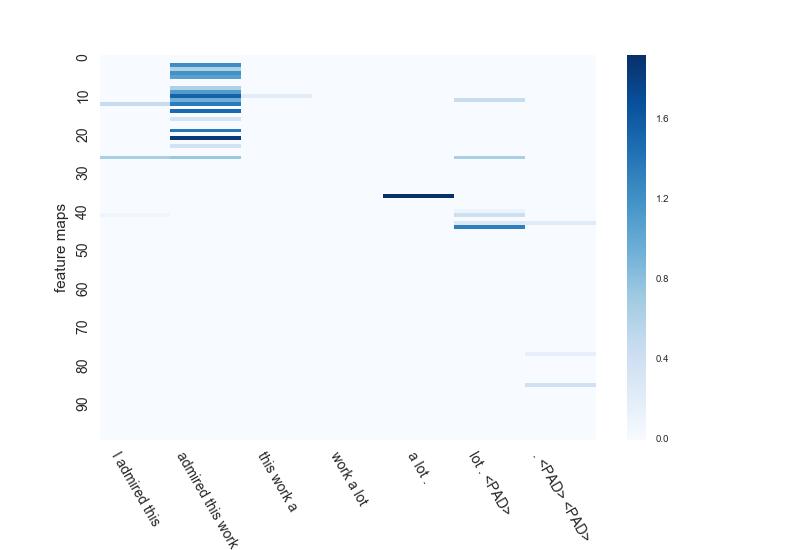
max poolingなので各特徴マップでは色が一番濃い所がこのあと抽出されます。
admired this workの部分が抽出される特徴マップが多いですね。
admired this workとlot . <PAD>は別々の特徴マップで抽出されます。
次に、average poolingのほう。。。こいつはきっちり[very positive]と正解します。可愛い奴め。
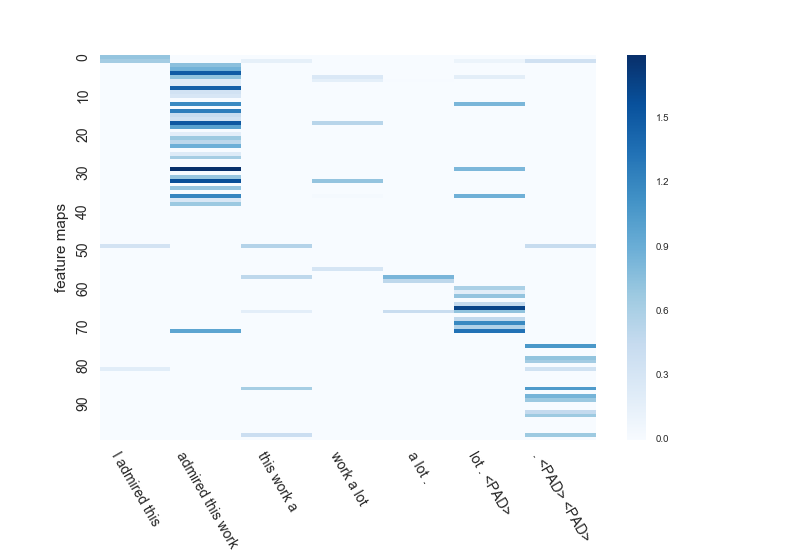
average poolingなので、一番濃い所以外にも二番目、三番目と複数考慮することができます。
admired this workとlot . <PAD>を同時に抽出する特徴マップもみられます。
どうせ最大値しか使わないmax poolingと全ての値を使って平均値を得るaverage poolingでは、同じCNNでもけっこう学習結果が違う模様。
考察
max poolingでは1つの特徴マップから1つの素性しか取り出せないのに対し、
average poolingやattention poolingは1つの特徴マップから複数の素性を取り出すことが可能です。
上の例だと、admiredと少し離れたa lotを1つの特徴マップで同時に考慮することが可能になります。これが良かったのかな。。。
おわりに
自然言語処理ではmax poolingが使われることが多いですが、きちんと文長で割れば案外average poolingも使えることがわかりました。
というか、直感的にもaverage poolingの方が良さそうな気もする。
たしかに計算時間はmaxに比べたらかかりますが、CNN自体がはやいのでそんなに気にならないです。(LSTM使ったRNNよりは全然はやかった。)
これからCNNやるときはaverage poolingも同時に試していきたい。