はじめに
なんかシステム、プログラムがうまく動かない、、といった際にどうしていったら良いですか?とか
デバッグがうまくいきませんとか言われることが時々ありますので書き残しておきます。
やりかた
全体フロー
流れとしてはざっくり以下となります。
- 事象、発生条件の整理
- 影響範囲の確定、ステークホルダーへの連絡
- ログの収集
- 被疑コンポーネントの絞り込み
- 原因分析
- 対処
- 解消確認
といった形が自分は多いかなと思います。
影響調査
- 事象、発生条件の整理
- 影響範囲の確定、ステークホルダーへの連絡
- ログの収集
ここの部分を解説します。
最初にエラー発報(運用システム、ツールからの自動連携)にしろ、ユーザー問い合わせからの連絡にしろ、
- 今何がおきているのか
- だれが困っていてだれは困ってないのか
といったところを明確にしていきます。人伝ての連絡ではなく、エラーとなっているエビデンスやログも一緒に確認していったほうがよいです。特にユーザー問い合わせの場合、捉え方が曖昧だったりしますので、その際は、自身で操作して事象を再確認していったほうがよいと思います。
この時点で疑われる箇所含めた一通りのログの収集を実行しつつ、各コンポーネント単位にエラーが出ていないか監視系ツールなどのステータスを確認しましょう。(本番システムの場合)
テスト環境などの場合は、監視系を動かしていないこともあるので、環境に詳しい人に、「今日ってメンテ時間あったっけ?」とか聞いたりして情報を探りましょう。
影響確認では、業務データがどうなっているのかも確認が必要です。データがおかしくなっている場合には、後続業務がある場合、別のシステムや業務担当者にも迷惑がかかってしまうので、データの修正も並行で考えていきます。
切り分け
次に
4.被疑コンポーネントの絞り込み
をやっていきます。ここが本ページで一番言いたかったことになります。
システム、プログラムは様々なコンポーネントで形成されます。
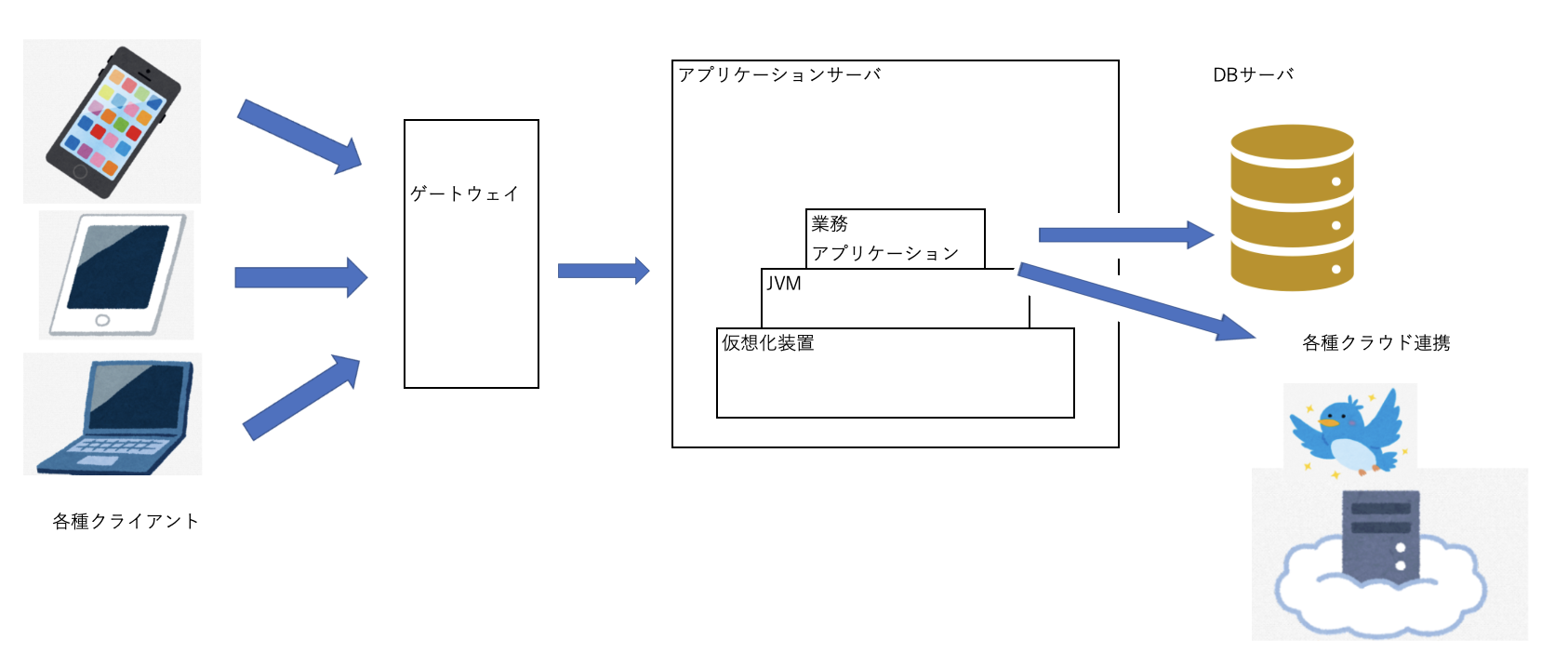
事象から切り分けていきます。
-
システムにはアクセスできるが特定機能だけが動作しない
→プログラムバグ、不整合データの混入(バリデーション漏れ含む)、特定機能にて外部サービスが使われている場合はそのサービスが落ちているもしくは疎通できていない、など -
そのシステムの全機能動作しない
→ NW不通含むプラットフォーム系のHW障害(OS、ストレージなどなど)、メモリ溢れ・CPU100%張り付き(原因は業務アプリケーションの場合あり)など -
特定のクライアントだけ動作しない
→ 特定クライアントの環境依存(OS差異、セキュリティパッチ、ブラウザ設定)など
基本的にはプラットフォーム系の障害の場合は、検知する仕組みがあると思いますのでそこを頼りに復旧させていきます。
上記をより詳細にしたようなシステム全体構成図があれば、その図を流用して、正常に動作している箇所は問題なしとして潰し込み、ちょっとわからないところは保留として調査継続するなど、消去法のような形で切り分けていきます。
プログラムバグやデータ不整合などの場合は、掘り下げるために、ログラムの中身の構造をイメージして調査検討していきます。
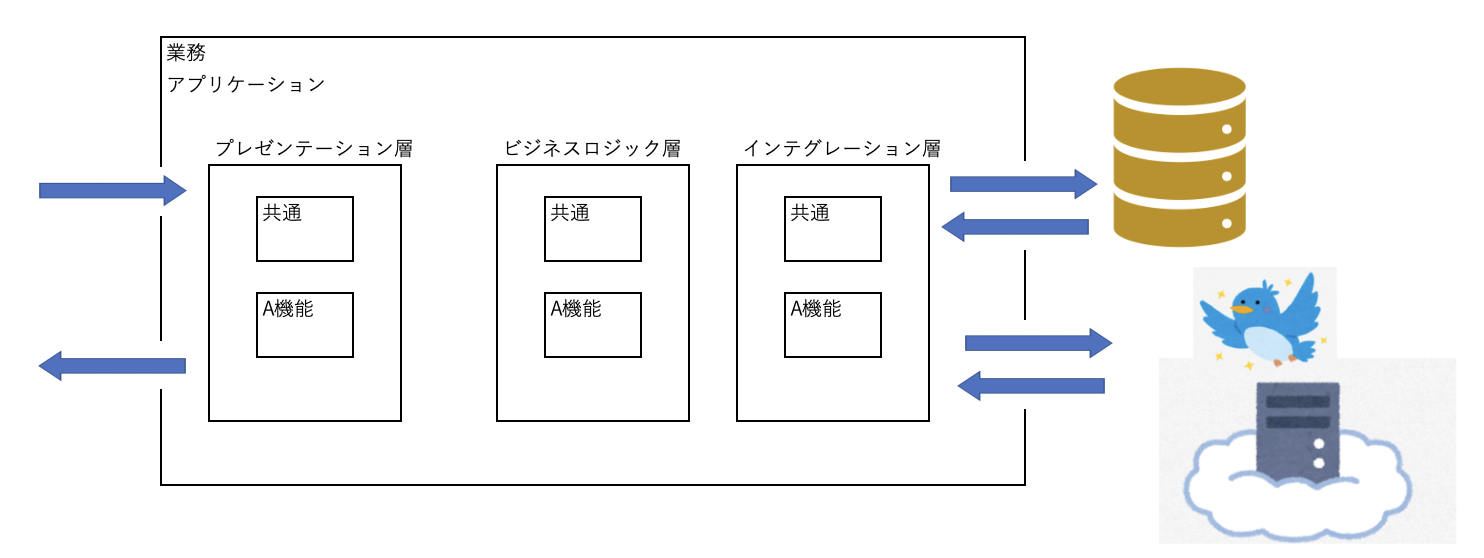
上記はコンポーネント図のように記載されていますが、業務アプリケーション内ではパッケージ構成と思って見てください。
特定ケースでエラーになる場合は、通常の障害が起きていないケースと、今回障害が起きているケースで流れを見比べながら検討していきます。
その際にログも見比べられると、異常がどこで起きているのかを確認することが出来ます。
エラーログが出ている場合について、Javaであればスタックトレースが出ているケースが多いと思いますのでそこの根本例外を確認することでエラー原因が分かることがあります。
エラーログの見方などは基本動作事項になりますので、しっかり身につけましょう。
スタックトレースの見方は上記サイトを例にあげましたが、実際には動かしながら自分で学んだほうが良いかなと思います。
原因特定と対処
ログから被疑箇所がわかったら、原因の特定を行います。プログラムバグなのか、データが想定外なのか、などなどです。
原因が分かっても、その時点ではあくまで仮説です。対処してみて、それが解消されることが確認できたら、真に原因が分かったと言ったほうが硬いかなと思います。
対処についても、安易に対処方法を決定するのではなく、対処した結果他のところに悪影響がでる場合もありますので、レビューやテストはしっかり行いましょう。
テスト環境でしっかり確認するのが良いですね。
まとめ
今回は起きてほしくない障害についての対応方法について観点に記載してみました。起きたものは仕方ない部分もありますので、冷静に迅速に分析、対処していきましょう。
バグや障害も多くの経験を積んでいくことで、前にも踏んだバグだということで即座に見極められたり出来てきますので、大きく成長できるチャンスだとも捉えられるかなと個人的には思います。