ソースコード
ソースコードはゴミ置き場に置いてある
https://github.com/2a3oiUA3zfDtr3py/Misc/tree/master/Sort_Test
実験したアルゴリズムとデータ型
データ型
- uint32_t型 (32Bit符号なし整数)
- uint64_t型 (64Bit符号なし整数)
- float型 (32Bit実数)
アルゴリズム
- 標準ライブラリ qsort
- 非再帰のマージソート
- LSD方式の基数ソート 8bit毎に処理
- LSD方式の基数ソート 16bit毎に処理
- MSD方式の基数ソート 16bit毎に処理
- 雑種(8bit LSD + 8bit MSD + マージ)
符号なし整数の実験結果から、MSD方式及びLSD方式の基数ソート並びにマージソートを組み合わせたハイブリッド方式を作った
実数を扱う場合、NaNの含まれたデータはどの様にソートするべきか?
正の無限大より大きな数字として見做すべきか、負の無限大より小さな数字と見做すべきか?
ハイブリッド方式は実数はデータにNaNが含まれている場合は取り敢えず最後に持っていく事にした。
マージソート、基数ソート、qsortはNaNが無いものと仮定してソートするようしてある
x MBのデータを読み込みN 分割したN個の長さy = x/(N*sizeof())の配列をソートをN回行うプログラムの実行時間を調べた
データは次のように生成した
整数
head -c 536870912 /dev/urandom > temp.bin
実数はBox–Muller法で生成した数値の逆数を出力するプログラムを作った
./generator 134217728 temp.bin
実験環境
Linux 4.12 Gentoo
gcc version 6.4.0 (Gentoo Hardened 6.4.0 p1.0)
作業ディレクトリ /dev/shm
作業マシン:今は死に体の東芝製 dynabook TX/66J
実験結果
複数回実行した中央値のリスト
単位は秒
512MB 32Bit整数
| 配列の要素数 * 分割数 | qsort | Merge | Radix 16 | Radix 8 | Radix MSD | Hybrid |
|---|---|---|---|---|---|---|
| 134217728 * 1 | 41.95 | 28.51 | 11.30 | 7.10 | 25.02 | 4.31 |
| 67108864 * 2 | 40.71 | 26.13 | 8.59 | 7.23 | 42.24 | 4.23 |
| 33554432 * 4 | 37.55 | 25.44 | 7.63 | 7.08 | 79.54 | 3.95 |
| 16777216 * 8 | 35.94 | 24.15 | 7.26 | 6.60 | 154.14 | 3.79 |
| 8388608 * 16 | 35.08 | 23.50 | 7.13 | 6.16 | 300.04 | 3.64 |
| 4194304 * 32 | 32.80 | 23.11 | 7.00 | 5.57 | 3.53 | |
| 2097152 * 64 | 31.45 | 21.85 | 6.95 | 4.93 | 3.41 | |
| 1048576 * 128 | 31.08 | 21.19 | 6.18 | 4.33 | 3.23 | |
| 524288 * 256 | 28.04 | 20.11 | 4.00 | 3.67 | 3.12 | |
| 262144 * 512 | 27.79 | 18.83 | 3.20 | 2.72 | 2.96 | |
| 131072 * 1024 | 25.43 | 17.61 | 3.11 | 2.45 | 2.73 | |
| 65536 * 2048 | 23.61 | 16.72 | 3.47 | 2.36 | 2.64 | |
| 32768 * 4096 | 22.45 | 15.54 | 4.14 | 2.34 | 2.61 | |
| 16384 * 8192 | 20.84 | 14.51 | 5.59 | 2.34 | 2.63 | |
| 8192 * 16384 | 19.45 | 13.29 | 8.55 | 2.36 | 2.65 | |
| 4096 * 32768 | 18.09 | 12.11 | 14.65 | 2.34 | 2.62 | |
| 2048 * 65536 | 16.94 | 11.35 | 27.76 | 2.40 | 2.68 | |
| 1024 * 131072 | 15.40 | 10.26 | 2.58 | 2.84 | ||
| 512 * 262144 | 14.03 | 9.51 | 2.79 | 3.82 | ||
| 256 * 524288 | 12.67 | 8.36 | 3.68 | 3.96 | ||
| 128 * 1048576 | 11.32 | 7.63 | 5.31 | 5.69 | ||
| 64 * 2097152 | 9.87 | 6.92 | 8.55 | 7.15 |
16MB 32Bit整数
| 配列の要素数 * 分割数 | Radix 16 | Radix MSD |
|---|---|---|
| 4194304 * 1 | 17.88 | |
| 2097152 * 2 | 35.48 | |
| 1048576 * 4 | 70.79 | |
| 524288 * 8 | 138.86 | |
| 262144 * 16 | 252.94 | |
| 131072 * 32 | 313.03 | |
| 65536 * 64 | 283.12 | |
| 32768 * 128 | 185.39 | |
| 16384 * 256 | 109.16 | |
| 8192 * 512 | 59.22 | |
| 4096 * 1024 | 31.03 | |
| 2048 * 2048 | 16.29 | |
| 1024 * 4096 | 1.62 | 9.02 |
| 512 * 8192 | 3.19 | 6.21 |
| 256 * 16384 | 6.30 | 6.48 |
| 128 * 32768 | 12.53 | 9.90 |
| 64 * 65536 | 24.93 | 18.25 |
512MB 64Bit整数
| 配列の要素数 * 分割数 | qsort | Merge | Radix 16 | Radix 8 | Hybrid |
|---|---|---|---|---|---|
| 67108864 * 1 | 22.16 | 13.61 | 12.71 | 7.99 | 4.22 |
| 33554432 * 2 | 21.67 | 13.98 | 9.84 | 8.27 | 4.32 |
| 16777216 * 4 | 23.43 | 13.14 | 8.71 | 8.27 | 3.92 |
| 8388608 * 8 | 19.85 | 13.17 | 8.16 | 7.80 | 3.87 |
| 4194304 * 16 | 21.70 | 12.10 | 8.03 | 7.33 | 3.85 |
| 2097152 * 32 | 20.68 | 11.80 | 7.99 | 6.84 | 3.92 |
| 1048576 * 64 | 17.53 | 10.99 | 7.95 | 6.33 | 3.87 |
| 524288 * 128 | 16.57 | 10.74 | 7.17 | 5.76 | 3.68 |
| 262144 * 256 | 16.36 | 10.09 | 5.05 | 4.79 | 3.65 |
| 131072 * 512 | 15.09 | 9.11 | 3.80 | 3.29 | 3.66 |
| 65536 * 1024 | 13.00 | 8.49 | 3.83 | 3.06 | 3.15 |
| 32768 * 2048 | 12.99 | 8.04 | 4.61 | 3.03 | 3.13 |
| 16384 * 4096 | 12.24 | 7.46 | 6.24 | 3.04 | 3.12 |
| 8192 * 8192 | 10.58 | 7.03 | 9.47 | 3.06 | 3.12 |
| 4096 * 16384 | 10.16 | 6.45 | 15.54 | 3.08 | 3.17 |
| 2048 * 32768 | 9.14 | 5.94 | 28.58 | 2.90 | 3.01 |
| 1024 * 65536 | 8.31 | 5.38 | 54.27 | 3.03 | 3.11 |
| 512 * 131072 | 7.69 | 4.97 | 3.42 | 3.49 | |
| 256 * 262144 | 6.88 | 4.42 | 3.92 | 4.02 | |
| 128 * 524288 | 6.16 | 4.01 | 5.77 | 4.08 | |
| 64 * 1048576 | 5.36 | 3.53 | 8.94 | 3.75 | |
| 32 * 2097152 | 4.60 | 3.21 | 15.04 | 3.56 |
16MB 64Bit整数
| 配列の要素数 * 分割数 | Radix 16 |
|---|---|
| 512 * 4096 | 3.19 |
| 256 * 8192 | 6.31 |
| 128 * 16384 | 12.53 |
| 64 * 32768 | 25.01 |
| 32 * 65536 | 50.49 |
512MB float型
| 配列の要素数 * 分割数 | qsort | Merge | Radix 8 | Hybrid |
|---|---|---|---|---|
| 134217728 * 1 | 40.89 | 28.41 | 5.87 | 3.83 |
| 67108864 * 2 | 39.55 | 28.53 | 6.08 | 3.84 |
| 33554432 * 4 | 37.90 | 27.75 | 5.99 | 3.86 |
| 16777216 * 8 | 36.56 | 26.08 | 5.74 | 3.83 |
| 8388608 * 16 | 35.14 | 25.28 | 5.43 | 3.82 |
| 4194304 * 32 | 33.50 | 23.93 | 5.20 | 3.82 |
| 2097152 * 64 | 32.12 | 23.36 | 4.85 | 4.10 |
| 1048576 * 128 | 30.56 | 22.03 | 4.58 | 3.77 |
| 524288 * 256 | 28.68 | 21.10 | 4.04 | 3.66 |
| 262144 * 512 | 27.14 | 19.45 | 3.19 | 3.40 |
| 131072 * 1024 | 25.70 | 18.33 | 2.96 | 3.25 |
| 65536 * 2048 | 24.33 | 17.38 | 2.94 | 3.16 |
| 32768 * 4096 | 22.96 | 16.20 | 2.92 | 3.15 |
| 16384 * 8192 | 21.57 | 15.27 | 2.93 | 3.16 |
| 8192 * 16384 | 20.17 | 14.34 | 2.91 | 3.16 |
| 4096 * 32768 | 18.77 | 12.98 | 2.79 | 3.04 |
| 2048 * 65536 | 17.42 | 12.24 | 2.87 | 3.08 |
| 1024 * 131072 | 16.07 | 10.93 | 3.03 | 3.28 |
| 512 * 262144 | 14.72 | 10.11 | 3.25 | 3.54 |
| 256 * 524288 | 13.32 | 8.91 | 4.11 | 4.58 |
| 128 * 1048576 | 11.97 | 8.04 | 5.90 | 6.35 |
| 64 * 2097152 | 10.54 | 7.10 | 9.29 | 8.02 |
| 32 * 4194304 | 9.12 | 6.35 | 15.80 | 7.42 |
考察
処理速度
16bitごと、8bitごとの基数ソートの速度差はデータの書き込みのランダムさや初期化コストの差の影響かな?
配列Aから一つのデータを読み取り、基数に基づいて配列Bのある地点に書き込むという処理について考える
配列Aから読み込んだデータの一部分8bit分と16bit分の考えられるパターンは8bitの場合は256通りで16bitの場合は65536通り
よって、配列Bにデータが書き込まれる可能性の有る部分は8bitの場合は256、16bitの場合65536
16ビットごとの場合の配列Bに対する書き込みのデタラメさは256倍酷い
またデータの書き込み位置を記録する為の配列も256倍大きいため、初期化する回数は8bitと比べて半分になっているが初期化に掛かるコストも大きい
8bit毎に処理する場合でも、ソートするデータが64bitと32bitの場合で比べると、配列のサイズが1MBを超えたあたりから遅くなっている
これはキャッシュの影響だと思われる
MSD方式の基数ソートは初期化の回数がとにかく多いため遅かった
初期化 → 上位16bitの処理 → 初期化 → 上位16bitがxxxxの場合の処理 → 初期化 → 上位16bitがyyyyの場合の処理 → …
ただし利点はある基数で配列を分類して更に分類されたその配列を分類するためメモリのアクセスの空間局所性は良い
分類した結果が1つだけ場合は明らかに追加で分類する必要が無いため処理を飛ばす
これの影響でグラフをみると変な挙動になっている
これらを検証する為に、MSD方式で配列を分類して、分類された配列が1MBを下回ったらそれをLSD方式をソート
ただし分類された配列がある程度小さいなら代わりにマージソートするハイブリッドを作った
512MBのソートでも性能があまり落ちない
ただし、実用性が無い。
与えられた配列の2倍のメモリを追加で確保している時点で問題がある。
そもそもギガバイト単位の巨大な配列のソートは需要が無いと思われる。
4バイトのデータをソートするなら要素数が128を超えたら基数ソート優位
8バイトの場合は256から優位になる
符号なし整数以外のデータを取り扱う場合に必要な工夫
固定長な符号なし整数へ変換して処理すれば良い。
この変換が兼ね備えているべき機能は、
- 可逆であること
- 変換前のデータ型での順序関係と変換後の符号なし整数での順序関係が同じであること
の2つ。
これさえできれば、基数ソートで処理できる様に変換して後で元に戻すだけ。
浮動小数点の場合は、
- 符号ビットが1の場合:全ビット反転
- 符号ビットが0の場合:符号ビットのみ反転
元に戻す際は、
- 符号ビットが1の場合:符号ビットのみ反転
- 符号ビットが0の場合:全ビット反転
NaNは後でIsNaNの結果を使ってソートすれば良い。
配列の長さと処理時間
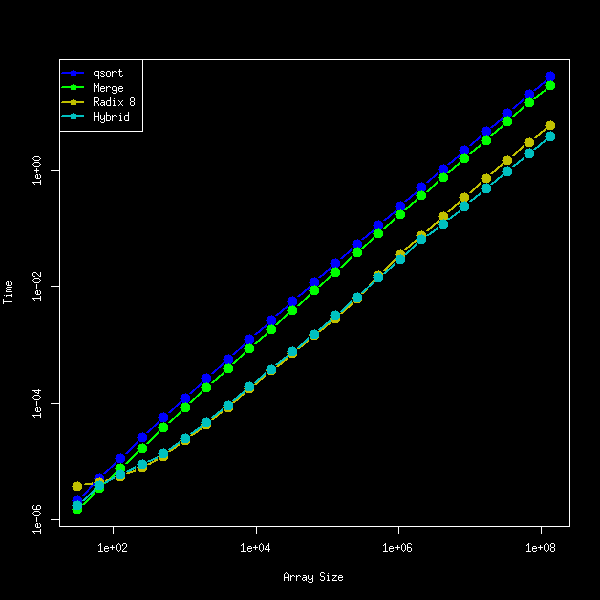
32bit符号なし整数
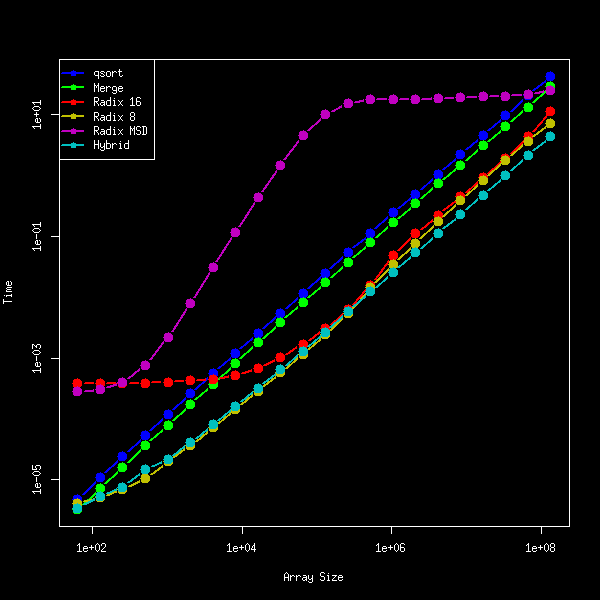
64bit符号なし整数
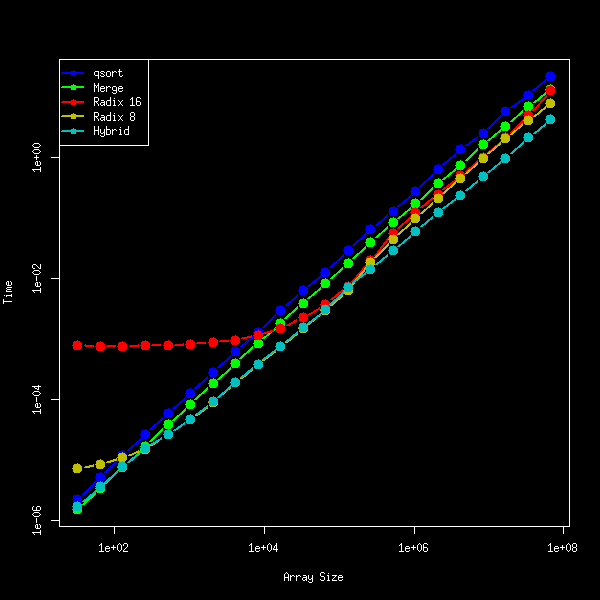
float型