免責事項
この記事は個人メモとして書き留めておいたものを、分かりやすく纏めてみたものです。記事内容に間違い・補足事項等の指摘があれば適宜修正したいと思いますが、記事の内容を100%保証するものではありません。予めご了承ください。
はじめに
(私だけかもしれませんが)インデックスがきちんと利用されているかを、実行計画で確認したりせずに、永らくSQLを利用してきました。『(最近の)オプティマイザは優秀なので、ある程度は自動的に的確な形でSQL実行計画を立ててくれる』という記事を鵜呑みにしてきたからです。それはきっとある程度正しく、またよく使うクエリはDB内でのキャッシュ機構が働くため、中小規模のシステムであれば、問題が表面化することも少ないと思います。
しかし、何事でもそうですが、特にIT系の仕事に於いては、きちんと『基本』を抑えておくことは極めて重要です。
この記事は、SQLServerに作成したテストデータの実行計画(SQL実行プラン)を題材として、インデックスと実行計画についての基礎的な理解を深める一助となることを目的としています。
『実行計画の見かた』について
ここでは説明を省かせていただきます。
https://use-the-index-luke.com/ja/sql/explain-plan
などを参考にしてください。
本記事の閲覧にあたっては、基本的に『Seek』は索引機能が利用されていて、『Scan』は"全件捜査"しながら条件を満たすかチェックされるという点だけ、抑えてあれば十分です。
一般には『Seek』になっていれば索引が使われ、効率的な処理が行われています。
ただ、後述しますが、データの実情によっては、必ずしも『Seek』が使われていれば高速だとは限りません。必要に応じてWITH句で利用するインデックスを指定できるのは、DBのオプティマイザ(クエリの最適化を行うエンジン)が必ずしも常に最適な判断をしているわけではないことの裏返しでもあります。そして、優秀だが万能ではないオプティマイザを補完できるのは、人間の頭脳以外にありません。我々(私だけ?)もインデックスと実行計画について理解を深めなければならない理由が、そこにあります。
以下、本題となりますので、である調に変更します。
テストデータについて
テスト用に用意したseiseki(成績)テーブルの構成は以下のとおり。
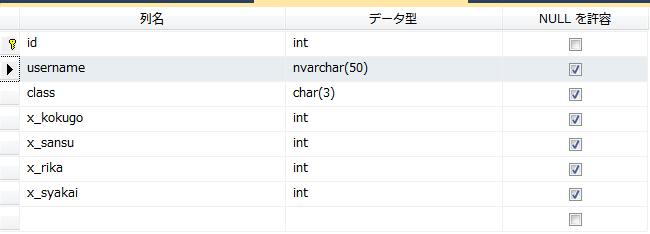
データは以下のように用意した。
生徒と国語・算数・理科・社会のテスト点数を格納しているが、特定の点数の生徒数が偏らないよう、現実味のない点数となっていることについてはご理解頂きたい。
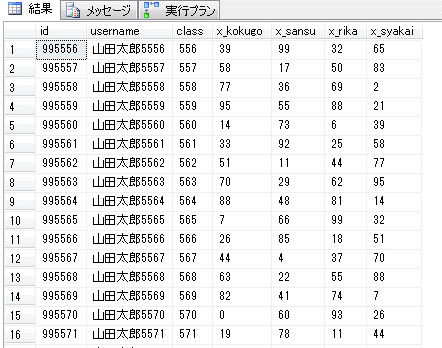
件数は100万件。
usernameは「山田太郎+idの下4桁(ただし先頭0は省く)」をセット。(同一氏名が100人いる。)
classはidの下3桁で文字列型。0~999のクラスに各1000人の生徒が所属している。
インデックスは以下のとおり作成した。
氏名。
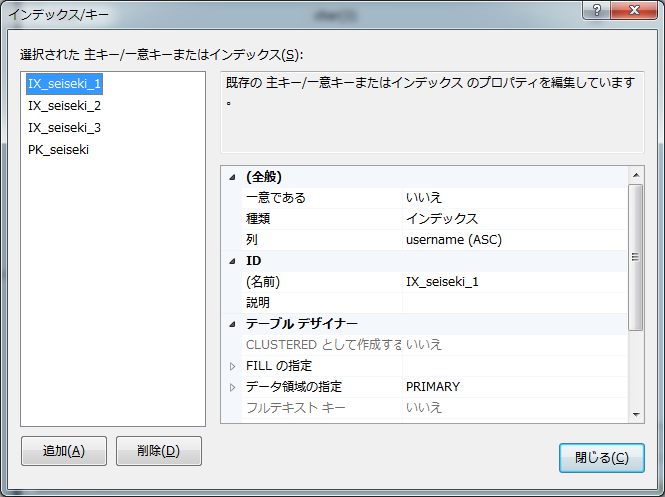
クラス。
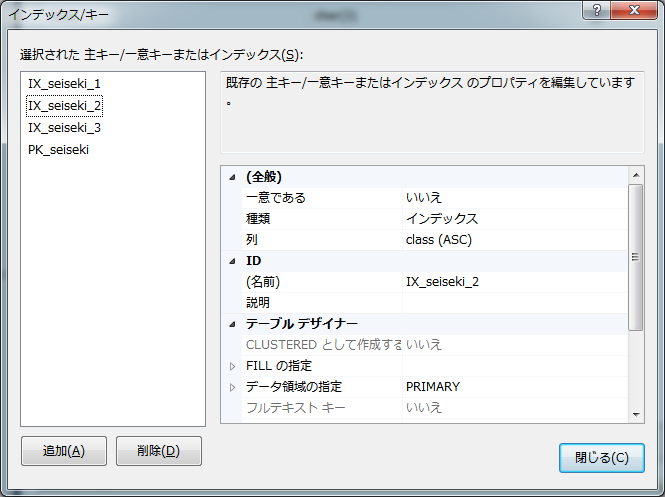
国語、算数、理科の点数。(敢えて社会は除く。)
ディスク使用量。
実データ83MBに対して、インデックスが64MB。
検証① 数値型の変換ルールとインデックス
- SQLServer(に限らない話だが)は、文字型と数値型の比較では、数値型にして比較しようとする
- そのためインデックスが貼ってあるカラムが、文字型の場合、検索条件として数値を指定するとインデックスが使用されない
- where句の検索条件は、数値を文字型として指定しても問題ないが、一方で、数値型では問題が起きることがある
検証内容
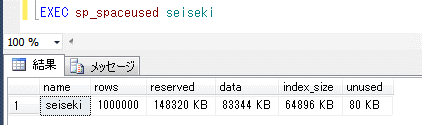
文字型のclass列に対して、SQLで検索条件を数値型にすると、低速なIndex Scanになる。
※列classの実際の値を、逐次、数値に変換して比較となるため、インデックスは機能しない。
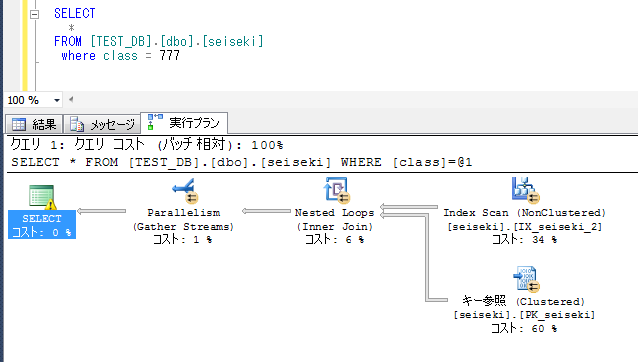
SQLで検索条件を、文字列型にすると、高速なIndex Seekになる。
逆の事例を挙げる。
国語と算数の点数(数値型)にはインデックスを貼っている。
数値型の検索条件を指定すると、当然機能する。
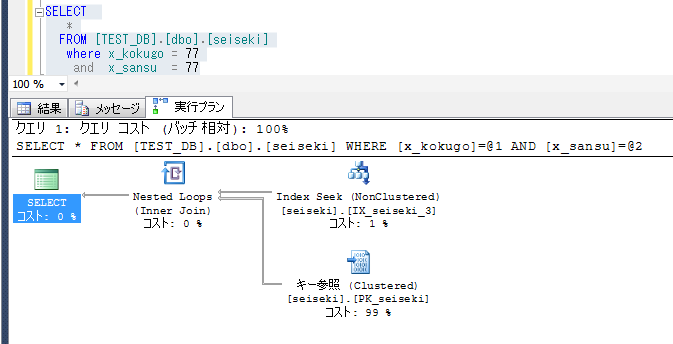
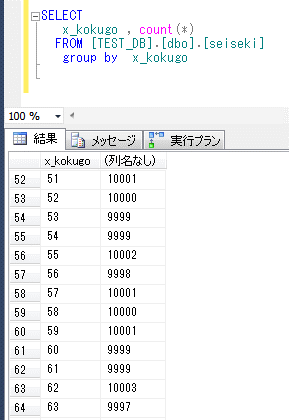
※なお、ある程度、各テスト教科の点数は分散されるようにしていて、国語が77点の生徒はおよそ1万人前後、さらに且つ算数が77点の生徒はおよそ100人前後となるようにしている
一方で、文字列型を指定した場合も、数値型で比較しようとするため、文字列77は、数値77に変換された後で動作し、高速なIndex Seekで動作する。
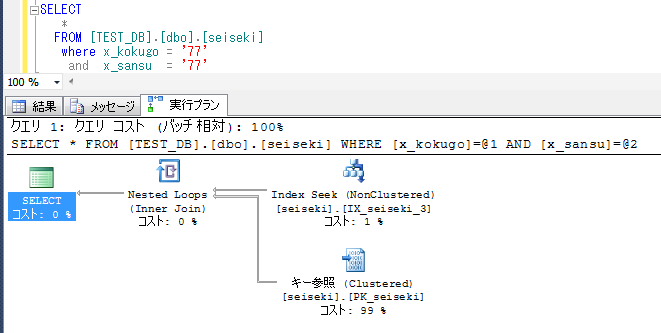
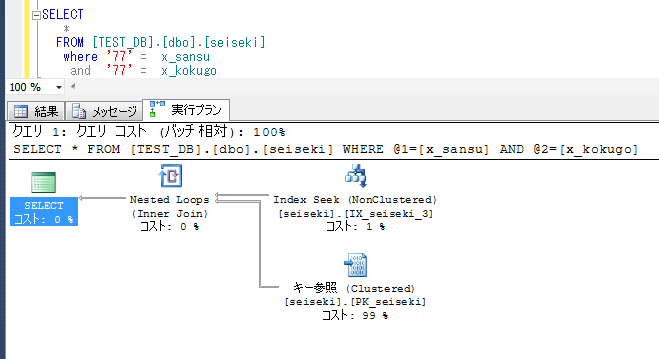
左側を文字列にしたり、検索条件の順番を入れ替えてもIndex Seekとなり、正しく処理される。
検証② like句とインデックス
- like句では、前方一致でインデックスが効果的と判断された場合に機能する。
- 後方一致(および部分一致)ではインデックスは機能しない
- データの実情によっては、前方一致でのインデックス活用は逆効果となる場合もあり、インデックスを利用しないようWITH句にてヒントを明示したほうがいい場合もある
検証内容
次にlike文による検証を示す。
like文により前方一致させた場合、下記の結果件数は、555、および5550~5559の1100件となる。
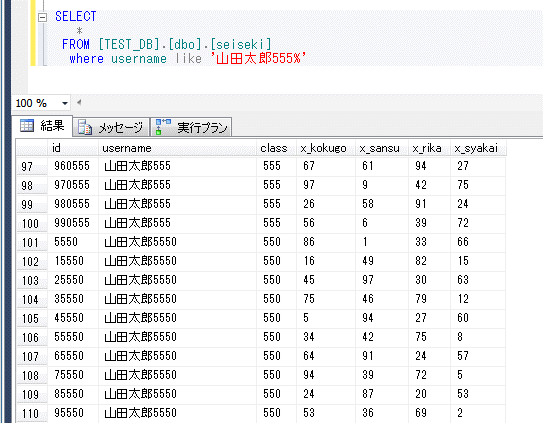
この場合、オプティマイザは効率がいいと判断して、Index Seekが利用される。
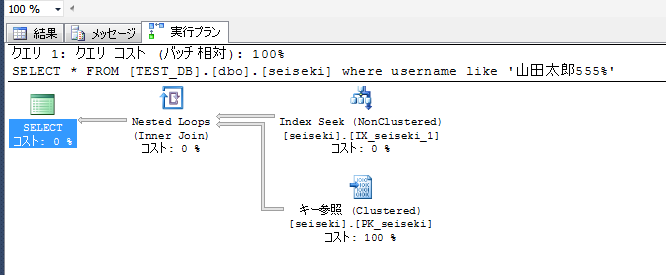
なお、この場合、シーク述語としては、文字ソート順による不等号での条件指定に変換される。
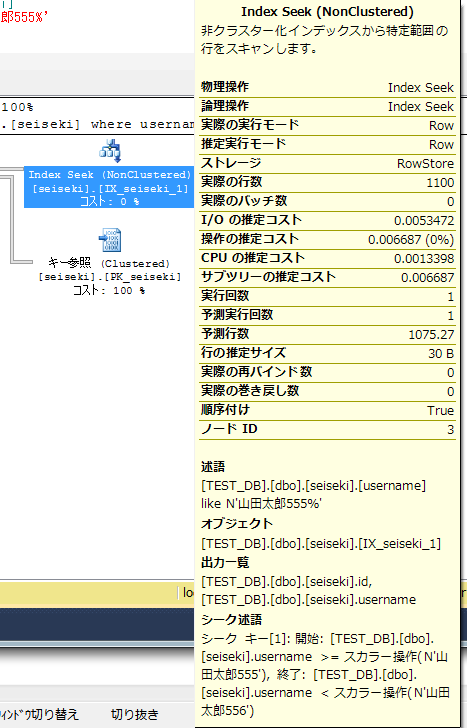
中間にワイルドカードがある場合でも利用される。
この場合の、シーク述語は、「山田太郎5~山田太郎6の範囲指定」となっている。※ソート順で、6は5の次の文字のため。
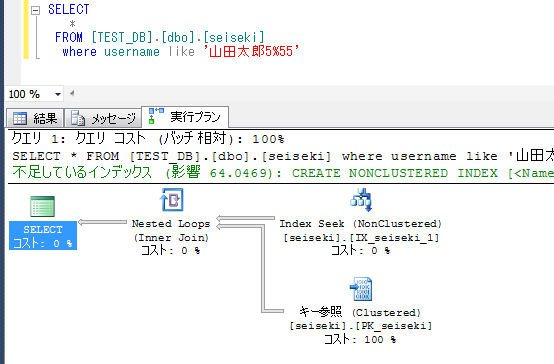
当然ながら、後方一致にした場合は、Index Scanとなり、Indexの全件スキャンとなるため、索引としての機能は機能しない。
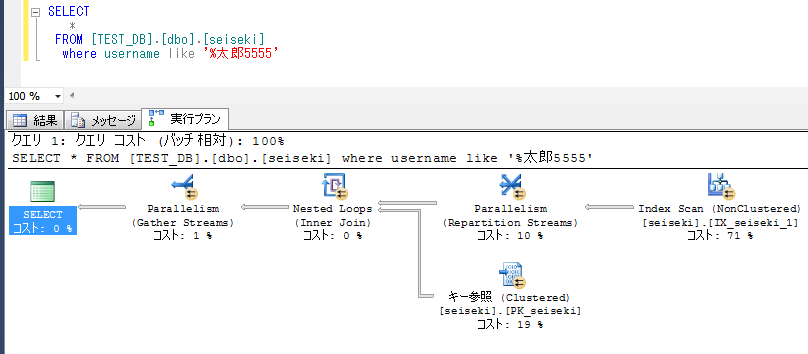
ここで、実行プランにて、Index Seekであれば、高速であるとも限らないことに注意されたい。
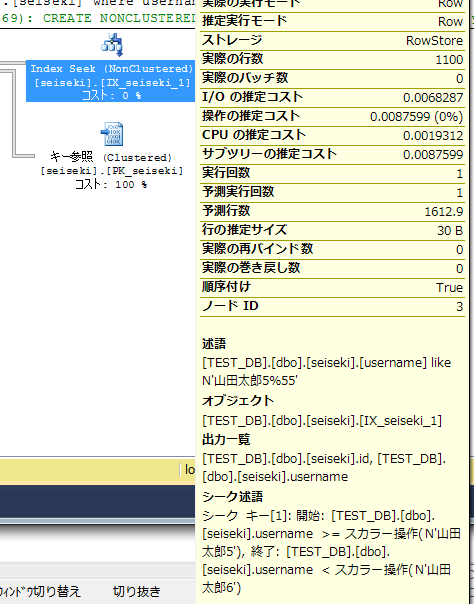
下記のシーク述語は、インデックスが全て「山田太郎」で始まるため、事実上、IX_seiseki_1の全件スキャンとなる。
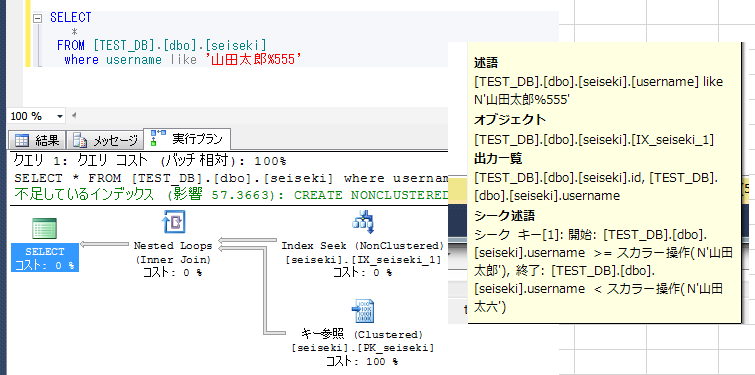
この場合、直接テーブルスキャンを行ったほうが速い可能性もある。
インデックスとして、主キーのPK_seisekiを明示的に指定した場合と比較してみる。
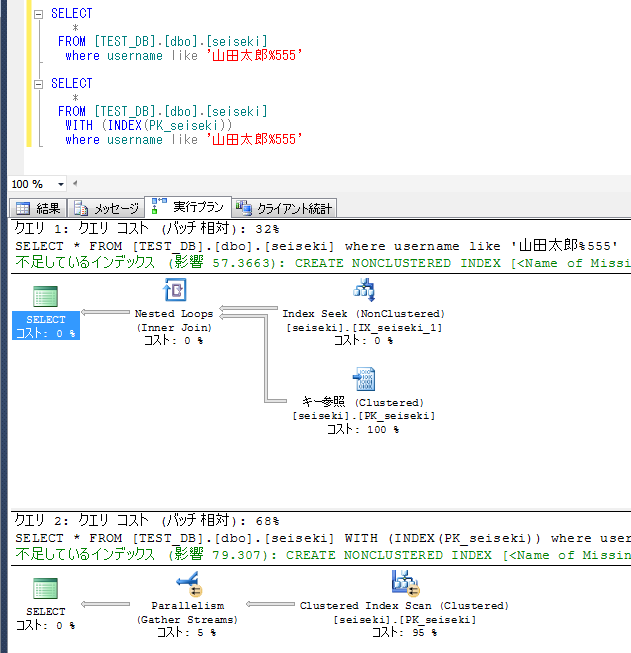
下図で、理論上のコストでは、32:68のコスト比となっていて、PK_seisekiを使用したほうが遅いということになっている。
WITH句なしでは、自動判定で、IX_seiseki_1が効率がいいとして使用されているので、当然なのだが、
あくまでオプティマイザが理論的(または統計的)に判定した予測であって、現実は異なるケースも存在する。
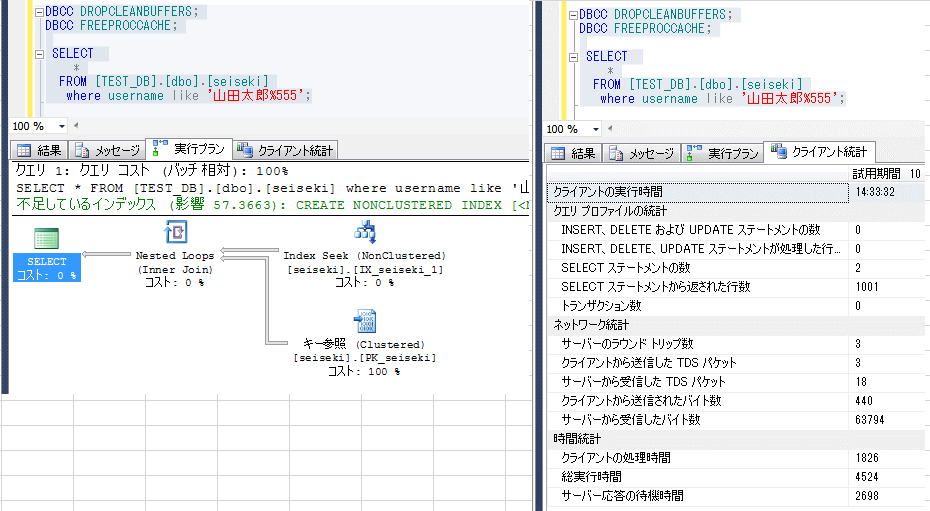
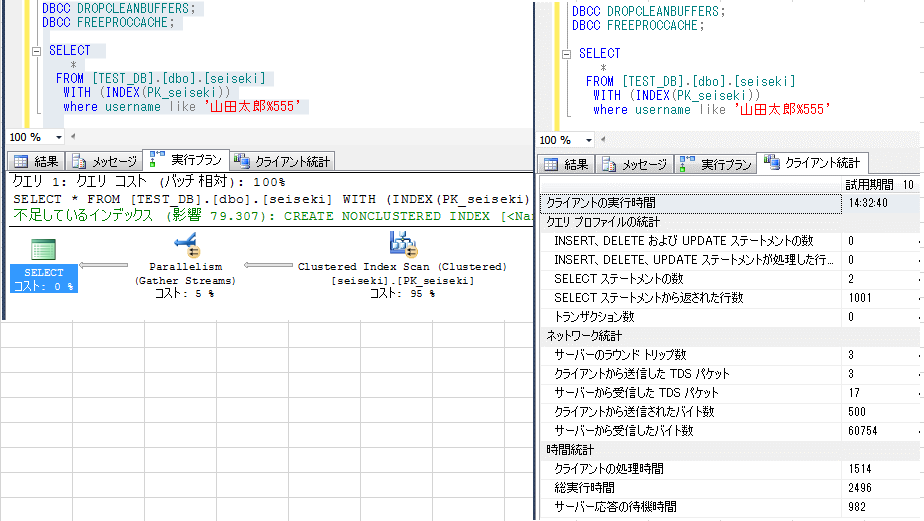
統計情報を削除しつつ、上記のSQLを実行した結果を下図に示す。
クライアント統計の時間統計を確認すると、インデックスを使用しないほうが高速な結果となっている。
検証③ 検索条件とインデックス適用について
- インデックスが適用されるかはオプティマイザの判断による(利用するインデックスを明示的に指定することは可能)
- 基本的に、インデックスの先頭から指定されている条件があるかどうかが判断に大きな影響を与える
検証内容
国語と算数の点数で抽出すると、Index Seekとなり、インデックスが機能する。
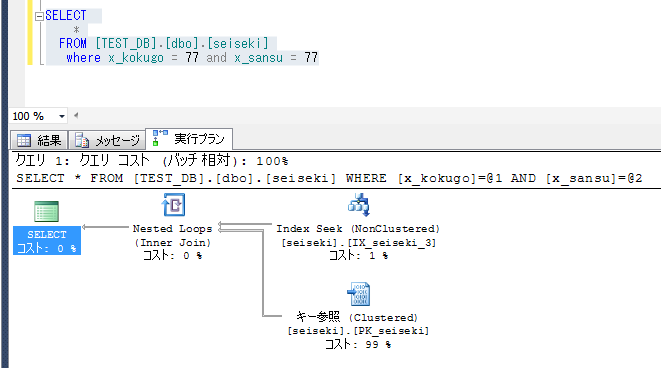
記述上の国語と算数の順番は、結果に影響しない。(オプティマイザがきちんと処理してくれる)
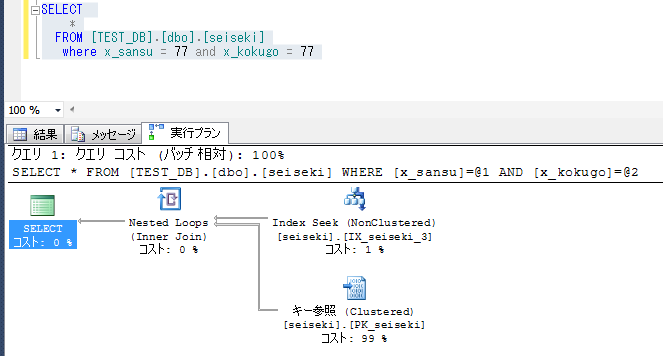
国語の検索条件をはずすと、テーブル全件スキャンとなる。※インデックスを利用しても意味がないと判断される。
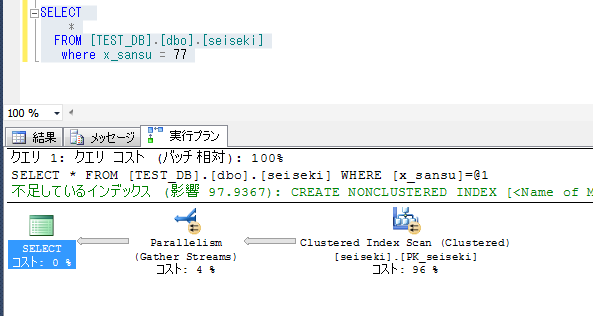
範囲指定でもインデックスは機能する
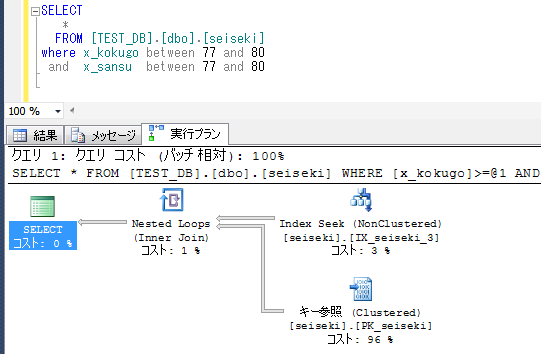
★国語と算数で不等号の範囲指定も含めて処理される

国語と理科を指定した場合、算数はないが、実際のところ国語だけである程度の絞込みが出来で、それが効率がいいと判定された場合、インデックスが利用される。
ここでは国語の77~80でIndex Seekでは4万件に絞り込まれ、その後、理科の条件も合致した1600件が、キー参照で実テーブルに照会される。
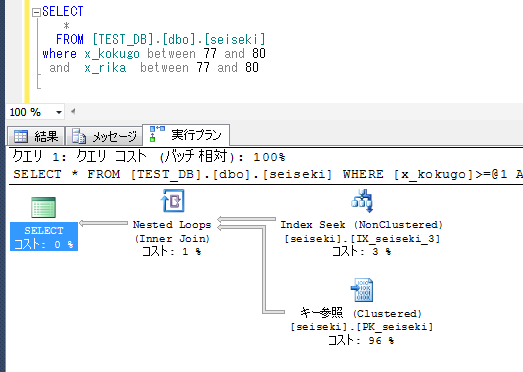
★Index Seekで使われてるのは国語だけ。

なお、ある程度、各点数の件数は分散されるようにしている。
そのため、国語だけで、1/100の絞込みが可能となっている。
※0~99点が約1万件ずつでトータル100万件。
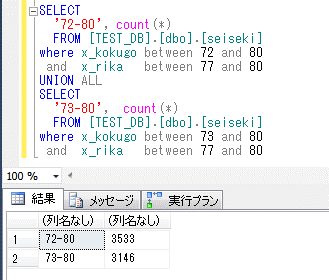
国語を72点~80点に広げると、まず9万件⇒結果が約3500件、73点~80点の場合は、まず8万件⇒結果が約3100件となる。
この場合、72点~80点に広げるとインデックスが使用されなくなるが、前述のとおり、オプティマイザの予測がいつも正しいわけではなく、このケースではインデックスを使用したほうが処理が軽いため、WITH句でインデックスを指定すべきケースとなる。
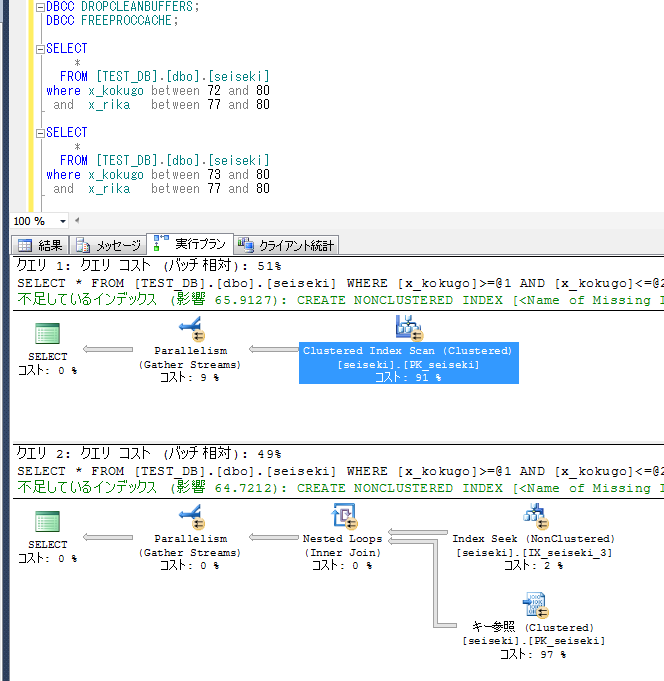
検証④ カバーリングインデックスについて
- インデックスは目次であり、実際のデータは目次からページを辿る
- 1件なら高速だが、結果の件数が1万件など、多くなるにつれて、ページを辿るコストが大きくなる
- そのため必要なデータもインデックスに格納すると早くなる⇒カバーリングインデックス
- 一方でカバーリングインデックスはストレージの容量を圧迫するデメリットがある(トレードオフ)
- システムの処理速度が問題になっている場合に、データベース処理の高速化のメリットが大きければ、トレードオフを加味して判断する
検証内容
前述のとおり、インデックスは[国語、算数、理科]に対して貼られている。
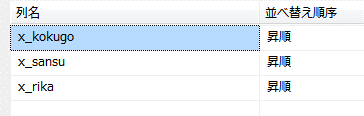
もし結果として、理科の点数を表示する形であれば、インデックス内にデータが格納してあるため、処理がインデックスのみで完結する。
このため、索引として使用しないデータを敢えてインデックスとして格納することで、処理の高速化が実現できると分かる。
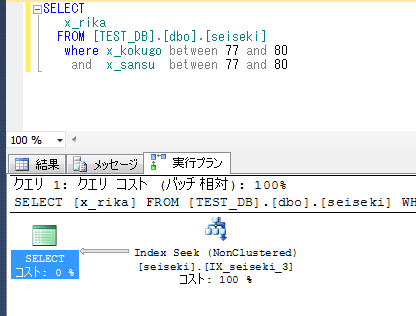
ここで違いを見るため、指定条件下の生徒の、理科と社会の平均点数をそれぞれ調べる。
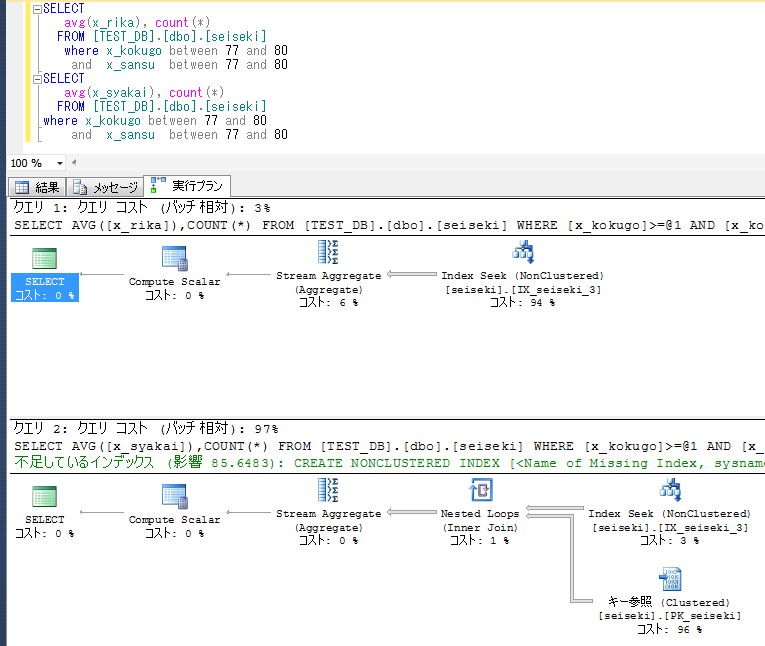
理科と同様に社会をインデックスに盛り込めば、処理が高速化されることになる。
DB高速化のためよく使われるこの手法が、カバーリングインデックスである。
カバーリングインデックスはインデックスのサイズ増加のデメリットがあり、処理高速化のメリットと天秤に掛けて、都度判断する必要がある。
参考までに、今回のケースで下記のインデックスを新規に作成し、サイズ増加を見てみる。
※本来であれば既存のインデックスに追加したほうが良いが、ここではディスク増加量の確認のため新規とした。
追加前

追加後

64MB⇒86MBに増加となった。
このとおり基本的にはカバーリングインデックスはトレードオフとなるため、
クエリの実行頻度、結果件数とその負荷具合など、様々な要素を加味して、
総合的に判断する必要がある。
最後に
まとめではありません。
執筆者の理解も道半ばだからです。
今まで、索引を作るべきか、はたまたカバーリングインデックスも作るべきか、そもそも必要ないのか・・・と判断に迷うことがありました。そして迷ったときは、たいてい何もしませんでした。判断をする前提の知識がなかったからです。
もちろんそういった判断をするための知識としては、この記事だけでは十分ではありませんし、実際に自分でテストしていろいろと理解していく必要があります。この記事が、少しでもその一歩を踏み出す手助けになれば幸いです。