昔書いたにっき( https://mjt.hatenadiary.com/entry/20110125/p2 )で取り上げたMCPU( https://github.com/cpldcpu/MCPU/ )を拡張し、それなりの実用性を確保したい話。
作成したものはGitHubに置いてある https://github.com/okuoku/nanocpu 。
できたCPU
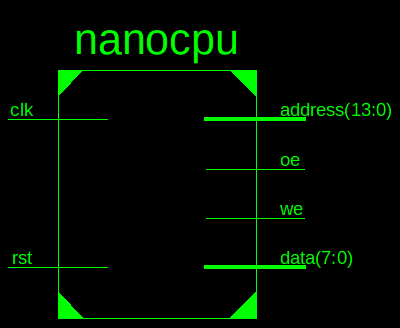
出来たCPU の諸元を簡単に要約すると、
- 64マクロセルCPLDに収まるギリギリのデザイン
- 割り込み機能なし
- ALU命令は 4命令のみ (ADD / NOR / Store / Jump if Clear Carry + carry clear)
- 8bit データ、ALU
- 14bit アドレスバス (8bitセグメント、6bit直接アドレス)
- 非同期SRAMメモリインターフェース
を持つ。このCPUは64マクロセルのXilinx Coolrunner II CPLDに収まり、同じXilinxの8bit CPUであるPicoBlazeが 200マクロセル以上を必要とする ことを考えるとかなり小さいと言える。
できたCPUのソースコード は今のところ98行で、一応100行に収まっている。もっとも、 元にしたMCPUはコメント等抜くと50行くらい なのでさらに小さい。今回のCPUは 14 bitsものアドレスバスがあるということで、16 KiB もの 広大な メモリにアクセスできる。元にしたMCPUは半分の回路規模であるものの、アドレスバスが 6 bits しか無いため、64バイトぶんしかメモリをアクセスできない。
サイズが倍になっているのは、アドレスバスの拡張のためにセグメントレジスタを導入したため。 ...これだけのためにサイズを倍にする必要があるのかは何とも言えない。実用性(?)を確保するためには、もっと良い手法があるかもしれない。
命令
基本命令はOPコード(2bits) + アドレス(6bits)のフォーマットになっており、さらに Jump 命令の定義域を4命令分削った拡張命令としてセグメントレジスタの操作命令(拡張命令)にしている。
- 基本命令
( [aaaaaa] は、メモリの読み取りまたは書き込みを示す: 実際のアクセス先アドレスはセグメントレジスタ、またはスクラッチパッド定数の値が加算される)
| code | sym | name | 動作 |
|---|---|---|---|
| 00aaaaaa | NOR | NOR | ACC NOR [aaaaaa] => ACC |
| 01aaaaaa | ADD | ADD | ACC + [aaaaaa] => ACC,C |
| 10aaaaaa | STA | STore Accumulator | ACC => [aaaaaa] |
| 11aaaaaa | JCC | Jump if Clear Carry | [aaaaaa] => PC if C = 0, 0 => C |
- 拡張命令
| code | sym | name | 動作 |
|---|---|---|---|
| JCC(60) | SWD | SWitch to Data space | データアクセスにデータセグメントを使用する |
| JCC(61) | SWS | SWitch to Scratch space | データアクセスにスクラッチパッドを使用する |
| JCC(62) | LDS | Load to Data Segment | ACC => DS |
| JCC(63) | LPS | Load to Program Segment | ACC => PS |
ロジックの縮小にもっとも貢献しているのは、CPUの命令種が基本の4命令に絞られている点といえる。一応 NOR が 論理的に完備 なので論理演算は全て実装できるし、ADDと論理演算さえ有れば、"負値の加算"という形で減算も表現できる。
今回はMCPUを改造して作っているので、基本4命令のチョイスはMCPUのパクりということになる。実装内容も 元にしたMCPUのpdf に書かれているので割愛。
このISAにとって苦手なのは表引きのような間接アドレッシングで、これはプログラムを自己書き換えすることでしか実現できない。また、左シフトは単純に加算で実装できるが、右シフトには表引きが必要になる。
フロー制御命令は JCC = 条件付きジャンプ命令1つしか存在しない。 JCC 命令はジャンプ条件となるキャリーをクリアするため、絶対ジャンプしたい場合は同じ JCC を2個連続で書けばよい。スタックは存在せず、また、割り込みもサポートしない。
拡張命令はセグメントの末尾4バイトに対する JCC を 削って実装している 。つまり、60 番地以降のアドレスにはジャンプできないことになる。拡張命令は、基本的にセグメントレジスタに関する操作となっている。これらの命令は元のMCPUのアドレス範囲を6bits → 14bitsに拡張するために追加した(後述)。
ジャンプ命令を削るのは、他の命令の定義域を削ってしまうとアクセスできないメモリが出てきてしまうため。先頭と末尾のどちらを削るかは悩ましいポイントだが、意味のあるプログラムコードが64bytesのセグメント一杯まで占められることは殆ど無いだろうと判断して末尾を削った。
レジスタ
アキュムレータが 8 bit なのに、アドレスバスが 14 bit あるため、C言語で言うと 整数型が8bitまでしか無いのにポインタが14bit有る 状況になっている。さすがに14bit CPUにしてしまうと回路規模が大きくなってしまうため、回路規模をケチるために 8086のような セグメント を使用したアドレッシングを採用している。
プログラム用とデータ用の2つのレジスタを用意し、命令のフェッチやデータのアクセスのたびに、アドレスバスに送り出して命令の6bitしか無いアドレス部を補う。
| レジスタ | 巾 | 内容 |
|---|---|---|
| ACC | 8 bit | アキュムレータ 。演算結果の格納と、書き込みデータの保持に使用する |
| PC | 6 bit | プログラムカウンタ 。8bitsの上位2bitをOPコードに使うので、その余り |
| PS | 8 bit | プログラムセグメントレジスタ 。プログラムをアクセスする際の上位8bitsを格納する |
| DS | 8 bit | データセグメントレジスタ 。データをアクセスする際の上位8bitsを格納する。 |
| キャリーフラグ | 1 bit | ADD命令使用時のキャリーフラグ。 |
| スクラッチパッド使用フラグ | 1 bit | このフラグが真の場合、 DS の格納内容ではなく 0x400 のオフセットが替わりに使用される。 |
8086 と異なり本当に単純に連結されるため、アドレスバスの巾は 6(命令部) + 8(セグメントレジスタ) = 14 bitsということになる。
プログラムセグメントレジスタは、PCが 111111 → 000000 のようにオーバーフローしても変わらないため、1セグメント64bytesに収まらないプログラムを書く場合はプログラム中で常に手動でセグメントレジスタを操作する必要がある。自動インクリメントのためには加算器が必要になるが、その加算器がCPLDに収まるかどうか自信が無かったため省略した。
セグメントレジスタの操作は拡張命令で行う。ちなみに、CPLDの容量が足りないのでスクラッチパッドの位置はレジスタで指定できず固定となっている(3bitしか余っていない)。
実装とCPLDへのフィッティング
何も言うことは無い。。元のMCPUのデザインがかなり巧妙で、非常に少い記述で必要なものを一通り実装している。 ...このため、セグメントレジスタのロジックを足すとだいぶカッコ悪い記述になってしまった。元々のMCPUは、論理合成ツールでは一般的な ieee.std_logic_unsigned を使用しているが、今回は標準ベースの ieee.numeric_std に 書き換えて いる。
Xilinxの最新の開発ツールであるVivadoではそもそもCPLDをサポートしていないため、昔懐しいISE WebPACKを使用して論理合成した。
************************* Mapped Resource Summary **************************
Macrocells Product Terms Function Block Registers Pins
Used/Tot Used/Tot Inps Used/Tot Used/Tot Used/Tot
61 /64 ( 95%) 139 /224 ( 62%) 93 /160 ( 58%) 49 /64 ( 77%) 26 /33 ( 79%)
** Function Block Resources **
Function Mcells FB Inps Pterms IO CTC CTR CTS CTE
Block Used/Tot Used/Tot Used/Tot Used/Tot Used/Tot Used/Tot Used/Tot Used/Tot
FB1 16/16* 25/40 28/56 7/ 8 0/1 0/1 0/1 0/1
FB2 16/16* 18/40 30/56 2/ 9 0/1 0/1 0/1 0/1
FB3 16/16* 26/40 51/56 8/ 9 0/1 0/1 0/1 1/1*
FB4 13/16 24/40 30/56 7/ 7* 0/1 0/1 0/1 0/1
----- ------- ------- ----- --- --- --- ---
Total 61/64 93/160 139/224 24/33 0/4 0/4 0/4 1/4
結果、 64マクロセルのうち61個使用 というかなり壮絶な戦いになってしまった。積項(接続部分)はそれなりに余っているので、もうちょっと複雑なロジックを入れる余地はあるものの、マクロセルの余剰が3つしか無いということは、フリップフロップが3つしか余っていない(= 残り3bit) ということになる。元のMCPUでは32マクロセルに収まっているため、コード規模だけでなくリソース規模でもほぼ倍増ということになってしまった。
拡張命令とプログラムセグメントレジスタのロードは states レジスタで実現されるステートマシンに2つステートを足して実現している。 拡張命令はキャリーをクリアしないNot Takenなジャンプ (110) 、プログラムセグメントレジスタのロードはTakenなジャンプの一種 (111) として実装している。ロジックの単純化のため、Takenなジャンプには余計なサイクルが挟まってしまうのはちょっと心残りになった。
GHDL によるエミュレーション
今回VerilogでなくVHDLで書いたのはGHDL( https://github.com/ghdl/ghdl )でエミュレーションしたかったため。GHDLには VHPIDIRECT と呼ばれる簡易的なFFI(異言語インターフェース)が実装されていて、簡単にシミュレーション中にC言語で書いた関数を呼び出すことができる。
シミュレーション用トップレベルとエミュレータI/F
やる気になればテストベンチ全体をCで書くのも不可能ではないが、いちおうバスの本体以外はVHDLで書いた:
-
https://github.com/okuoku/nanocpu/blob/53cf5012d671bbe7edbc016ed1e948b46474c6d0/ghdl_top.vhd
- シミュレーション用のトップレベル。 クロックジェネレータ と リセット回路 も含めている
-
https://github.com/okuoku/nanocpu/blob/53cf5012d671bbe7edbc016ed1e948b46474c6d0/ghdl_emuif.vhd
- ROM/RAMエミュレータとのインターフェース。 エミュレータである
busemu_cycle関数を宣言している
- ROM/RAMエミュレータとのインターフェース。 エミュレータである
-
https://github.com/okuoku/nanocpu/blob/53cf5012d671bbe7edbc016ed1e948b46474c6d0/busemu/busemu_main.c#L124
- C言語で書いたエミュレータ本体。今回CPU側のバスは非同期SRAM I/Fを採用したので、nOE (Output Enable、読み出しアクセス) か nWE (Write Enable、書き出しアクセス) の立ち下がり(?)
falling_edgeで呼ばれる。
- C言語で書いたエミュレータ本体。今回CPU側のバスは非同期SRAM I/Fを採用したので、nOE (Output Enable、読み出しアクセス) か nWE (Write Enable、書き出しアクセス) の立ち下がり(?)
今回GHDLは mcode ビルドを使用したので、各ソースコードをAnalyzeしたら即Runできる。
- Analyze
cc -shared -O3 -g -o busemu.so busemu/busemu_main.c
/opt/ghdl/bin/ghdl -a nanocpu.vhd
/opt/ghdl/bin/ghdl -a ghdl_emuif.vhd
/opt/ghdl/bin/ghdl -a ghdl_top.vhd
- Run
/opt/ghdl/bin/ghdl -r -v ghdl_top --fst=fst.out
(通常のGHDLでは、GCCなりLLVMでコンパイルするElaborateを間に挟むことになる。Elaborateはモデルをコンパイルして実行可能ファイルに変換する。)
C言語関数の呼び出し
GHDLの VHPIDIRECT を使用すると、
function busemu_cycle (addr,datain,xoe,xwe : integer) return integer;
attribute foreign of busemu_cycle : function is "VHPIDIRECT ./busemu.so busemu_cycle";
のようにVHDL中でC言語関数の存在を宣言し、Cでは
int
busemu_cycle(int addr, int datain, int oe, int we){
...
}
のように実装できる。C言語とVHDLとのやりとりには integer 型の変数を使うことになるが、通常VHDLのコードの中で引き廻されることになる std_logic_vector による変数とは変換が必要になる。
例えば、
emu_address := to_integer(unsigned(address));
emu_ret := std_logic_vector(to_unsigned(busemu_cycle(emu_address, 0, 0, 1), emu_ret'length));
のように、 integer のような通常の整数型への変換は to_integer 関数を使い、 std_logic_vector への変換はそのまま std_logic_vector という名前の関数を使う。
バスエミュレータは実際の 8bit データ出力のほかに停止要求出力も入れていて、これをアサートしたらシミュレーションが止まるように仕込んでいる。
if emu_err = '1' then
assert false severity failure;
end if;
シミュレータにサイクル数とかシミュレーション時間を設定するのが面倒だからね。。
簡単なプログラムで動作を確認する
今回は簡単な2セグメント構成(64bytes + 64bytes)のプログラムを書いて動作をGtkwaveで観察してみた。
romの内容はCのマクロを使って直接Cで記述している:
- rom0: https://github.com/okuoku/nanocpu/blob/53cf5012d671bbe7edbc016ed1e948b46474c6d0/busemu/rom0.inc.c
- rom1: https://github.com/okuoku/nanocpu/blob/53cf5012d671bbe7edbc016ed1e948b46474c6d0/busemu/rom1.inc.c
やっていることは、
- (rom0) リセットされるとROM0から実行開始される。 SWS命令で、データアクセスをスクラッチパッドに切り替える 。
- (rom0) リセット直後にACCにゼロが格納されていることを利用し、 0 と 255 をスクラッチパッドに用意 する。
- (rom0) 更に
255+255= (bit列で言うと)11111110となるのを利用し、これを 自分自身とのNORでビット反転して1を生成する 。 - (rom0) 生成した
1を利用して4までの定数を生成する。 - (rom0) いろいろやってから、 NOR allone でACCにゼロを代入 し、 ADD oneでACCを 0 + 1 = 1に設定 する
- (rom0)
LPS命令でプログラムセグメントを1に切り替える 。 自動的に pc レジスタがリセットされ 、次のサイクルからはrom1が実行される。 - (rom1)
LDS命令でデータセグメントに4を設定する 。( バスエミュレータはこの位置にデバッグ用のメモリマップドIOを用意している 。) - (rom1)
SWD命令でデータ操作先をスクラッチパッドからデータ領域に変更した上で、 セグメント '4' の 0 番地に 0 を書き込む 。このアクセスによって バスにエラーを出力させる ことで、エミュレーションは停止する。
例えば1 〜 4の定数を生成しているところを観察すると、
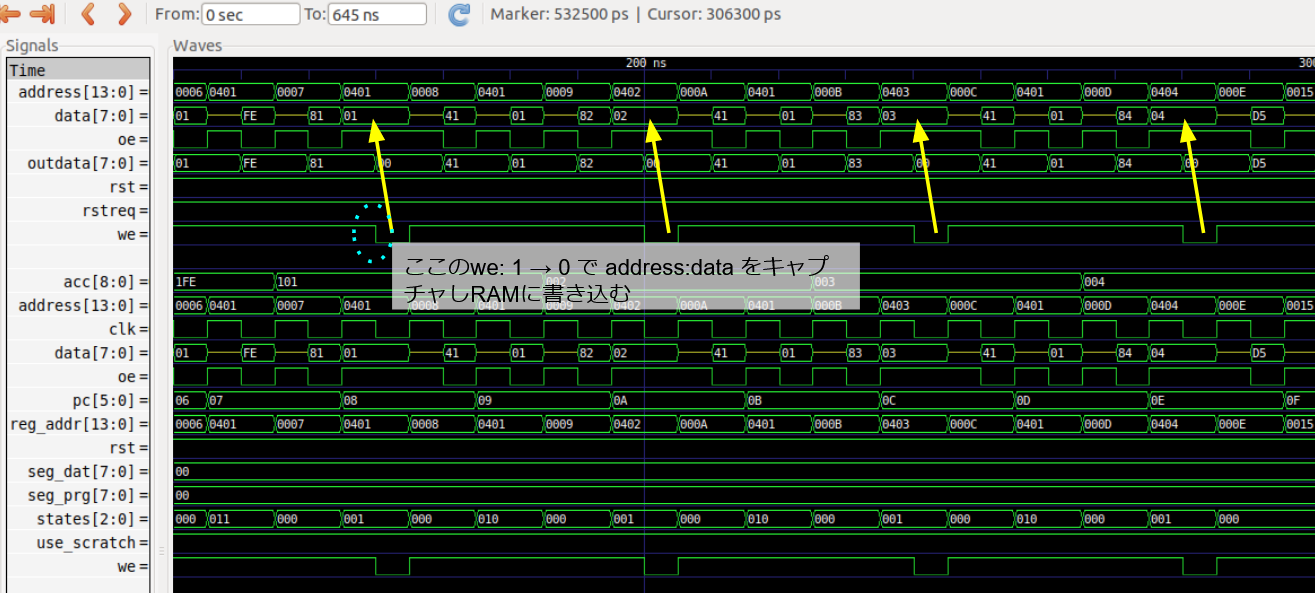
we のパルスが出ているところでちゃんとデータは 01 〜 04 になっており、期待通りの動きをしていることがわかる。
かんそう
実際の仕様出しと改造はこの記事を書くのに掛けた時間の半分以下できたが、正直これがminimalなのかについては自信が無い。つまり、 C言語で書かれたプログラムを実行できる程度の実用性があり、かつ、CPLDに収まるという要件を満たしながら最小規模を突きつめるとしたら、もっと効率的なアーキテクチャが有るかもしれない。
デザインチョイス
例えば命令2 bit、アドレス6 bitの割合を変えたりしても良いかもしれない。MCPUが参考として挙げているMPROZは、命令1bit、アドレス15bitの構成を取り、1命令を1から3ワードとする構成をとっている。(MPROZはFPGA前提のため直接比較はできないが...)

MPROZでは、先頭1bitだけではOPコードを表現せず、最大3ワードを集めて1つの命令として組み立てている。この "垂直" オペコードのデザインは興味深い。
後述のように、今回は内部の記憶容量が64bitsと制約されるところから逆算して、メモリアドレスの拡張を採ることにした。データ用のスクラッチパッドを用意することでデータとプログラムそれぞれ8bits、合計16bitsの追加で済まし、アドレスバッファにも8bitsの追加が必要であることを考えると、総計で24bitsの追加となった。
更に倍のサイズ(128とか256マクロセル)が取れるならば、16bitプロセッサにして命令を拡張しても良いかもしれない。特に、即値のロードや間接アドレッシングは常識的な規模のプログラムには必須と言える。逆に、現状の64マクロセルでは、今回のようなアドレス空間の拡張が、もっとも効率に寄与する拡張と今のところは考えている。ただ、外部にMMUやメモリバンクコントローラを接続する前提であれば、セグメントレジスタの長さを6bitくらいに削り、さらにもう1つセグメントレジスタを増やしても良いかもしれない。
スクラッチパッドは回路規模へのインパクトがそれほど大きくなかったため採用した。このように、簡単にアクセスできるRAMをレジスタや定数テーブル代わりに使うものとしては、6502のゼロページや TMS9900 などに見られる。逆に、プログラムのセグメントを自動でインクリメントするといった機能は省略した。このようなデザインをとったプロセサは多く、8086や SC/MP も同様にセグメント内でのwrap aroundが発生する。
JCC(63)はジャンプ命令として空け、セグメント内でのwrap around(PCが63から0になる点)を起点にプログラムセグメントをACCから更新するデザインも考えたが、ちょっとerror proneな気がして避けてしまった。単純なwrap aroundにはほぼ間違いなく用途が無いので、何かに使えれば良い気はするが。。
実用性
個人的にはツールチェーンさえ揃えればそれなりに実用的なのではないかという気がする。100行くらいで書けるので誰でもスクラッチできるし。ツールチェーンも、今はWeb Assemblyとかが有るので完全なC言語処理系を用意しなくても十分なものができると期待できる。
実際のプログラムを動作させるには、 Apple IIのSWEET16 のようなある種のVMが必須になるだろう。実際、 AVR上にARMエミュレータを実装して、AVRマイコン上でLinuxを動かした 人も居るくらいなので、同じことをすればLinuxを動かしたりすることも可能なのではないだろうか。
流石にエミュレータやOSのような大きなプログラムを動作させるには、MSXやファミコンよろしく メモリバンクコントローラ を外部に用意して16KiBのアドレス空間を更に拡張する必要があるだろう。原理的にはセグメントレジスタの長さを更に8bit伸ばすこと等も考えられるが、64マクロセルには収まらないのは確実なので諦めた。
64マクロセルは特にマジックナンバーというわけでもないが、例えば Digilent Cmod C2 のようなブレークアウトモジュールの形で入手できるPLDとしては、ソフトプロセッサを格納できる最小規模なのではないかと考えている。
( 東工大のUltrasmall のようなFPGA向けにMIPSをシリアル化したものでも、多数のフリップフロップを依然必要とするため、CPLDに収めるのは不可能だろう。)
伝統的なCPLDにCPUを収める難しさ
冒頭に挙げたPicoBlazeのような例外を除けば、ソフトプロセッサは基本的に大規模なASICかFPGAをターゲットにしている。
... "伝統的"と付けているのは、実は現行のCPLDは基本的に単に"不揮発FPGA"であることが多く、XilinxのCoolrunnerのような伝統的なPLAから発達したCPLDは、もう殆ど新製品が無い。例えば https://www.bigmessowires.com/cpu-in-a-cpld/ の記事で挙げられているIntel(旧Altera)のMAX IIは、 マーケティング上は CPLDとされているものの、中身は同社のCyclone譲りのLUTを使用したFPGAに近いものになっている。
※補足
本記事掲載後,Altera社の日本支社である日本アルテラより「MAX IIファミリ」はFPGA製品ではなくCPLD製品であるという申し入れがありました.同社はCPLDの製品カテゴリで,本製品を販売していきます.
(最新のMAX 10では単にFPGAとされ、ブロックRAMのような基本的なFPGA機能も一通り備えるようになった。)
ソフトプロセッサの実装面で最大の違いは、チップ内部のストレージ容量と言える。FPGAは通常分散RAM、ブロックRAM等の形で大量のストレージを内部に持っているのに比べ、CPLDはコンフィギュレーション単位(MacrocellやLE)につき1つのフリップフロップ(= 1bitのメモリ)しか無いことが多く、プロセッサでは大量に必要となるレジスタファイルをチップ内部で供給することができない。
先に挙げたMPROZのように、レジスタアーキテクチャではなくmemory-to-memoryアーキテクチャとすることでサイズの小さいCPLDでも大量のレジスタを(アーキテクチャ的には)持たせることは可能かもしれないが、少くとも既存のプロセッサアーキテクチャとはかなり乖離してしまうことになる。