こんにちは、玉置絢(@OKtamajun)です。
今日は AIの女の子たちがわいわい競馬予想するシステムを個人展示したらオッズ2000倍の馬券が当たってしまった というイベントの顛末についてお話します。
何が起きたのか
生成AIが好きな個人がなんでも出展できる、
「なんでも生成AI展示会」 というイベントがありまして、
11/16(土) 12:30 ~ 18:00にて「#生成AIなんでも展示会」を開催します🎉
— ようさん (@ayousanz) September 28, 2024
個人の方が生成AIで作っているものを見ることができる・体験することができるイベントになっています!
申し込みURLは以下⬇️https://t.co/aNIQ6myJ4q
以下の方との共同主催です@sald_ra @GianMattya @miketako3 @Yanagi_1112
人づてに出展しないか誘われたので、ストレス解消がてら9月頃から「マルチエージェントLLM(大規模言語モデル)オーケストレーション」というコンセプトで競馬予想をするシステムをシコシコと土日に作っておりました。
(ふだんは仕事でウケ狙いに命をかけるみたいな商売をしているのですが)
個人の趣味展示でウケを狙うとしたら何がいいかな……?🤔
と色々考えた結果、
- 開催時間中にリアルタイムに進行している競馬を利用してAI予想したらライブ感があって面白い
- 「AIの女の子たちに詰め寄られて買った馬券で大金を失うおじさん」を実演したらもっと面白い
- AIがうまく作れなくて当たらなくても面白い
- 開催時間中にどんどんお金が減っていく様子は面白い
というネタで、競馬予想どころかゲーム以外のプログラムは作ったことなかったのですが、競馬予想システムを作ることにしました。
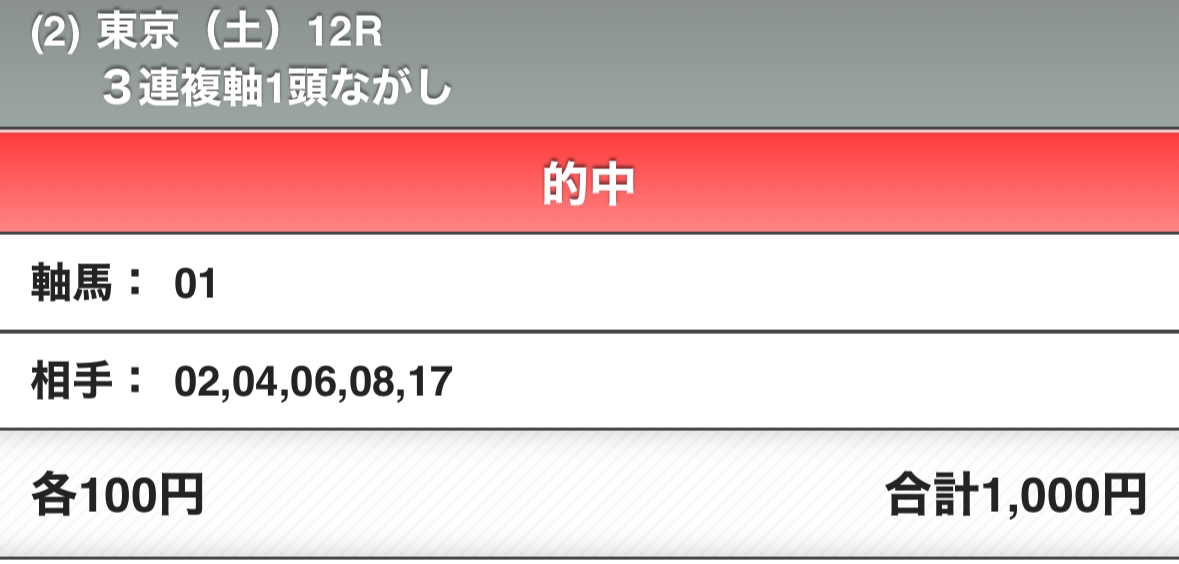
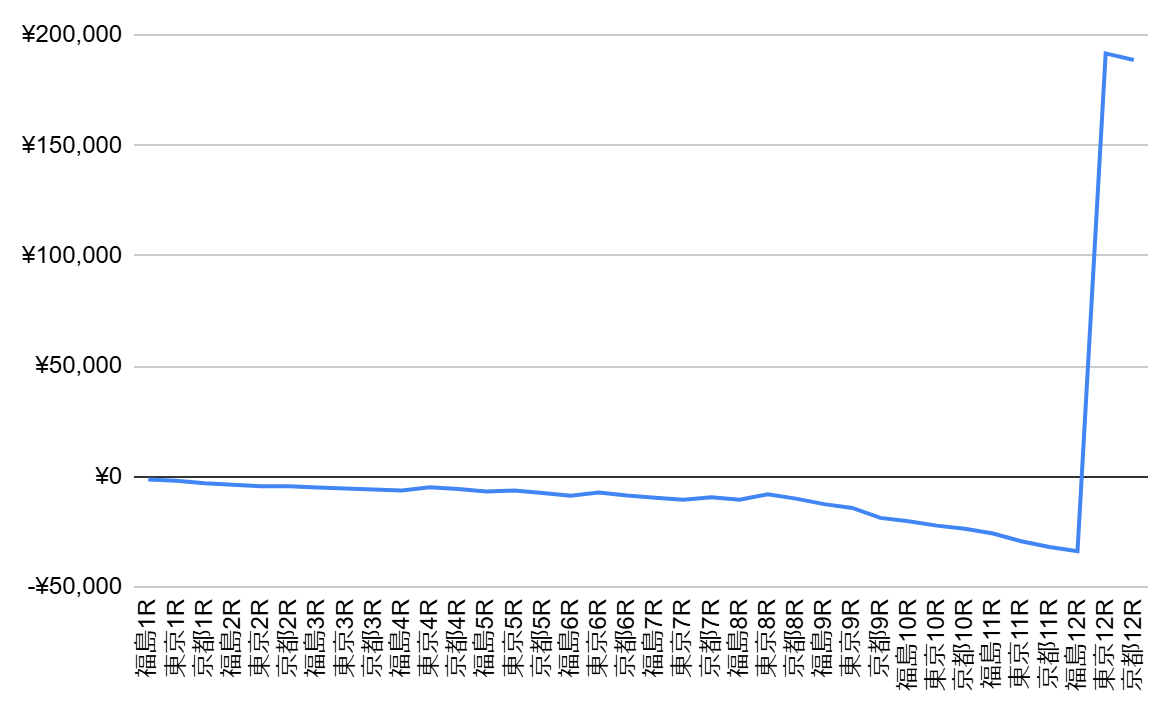
そんな経緯で、「とほほ・・・もうAIで金儲けはこりごりだよぉ~」(例の◯の中に顔のやつ)みたいなオチがやりたかったのですが、なんと最終レースでオッズ2275.3倍の馬券が当たってしまったので見え方が変わってしまいました。
 |
 |
 |

草
何を作ったのか
こんな感じのシステムです。
「GALLOPIA」の概要
AIの女の子が8人住んでいるグループチャットがあって、そこにレースを指定して予想依頼を出すと、話し合いでおすすめの馬券を提案してくれます。
工夫したポイント
それぞれのキャラがアドバイスをしてくれるときにちゃんと画面右側にエビデンスを出してくれるところを頑張りました。後に書く「AIに必要なのは知能だけでなく、説得力と共感力である」ということに繋がるポイントです。
なぜ書くのか
展示会の序盤からみなさま温かい目でAIの言われるがままに諭吉か栄一を捨てるおじさんを見守っていただいていたのですが、
最終レースで1,000円が227,530円に化けてしまってからというもの
「これは売れる」
「このサービスに加入したい」
という掛け声が出るようになり(そういうことはやりません!)、やべえ!
このまま調子に乗ってたら怖い人とか危ない人が来てシャレにならなくなるかも?!
違う意味で◯の中に顔がハマってしまうため、
「全てをお話します」スタイルでノウハウを共有し、作りたい人がいれば勝手に作ればいいじゃんというスタイルを取ることで危機を逃れようと、展示会翌日の筋肉痛でキーを打つのもつらいのですが記事を書くことにしました。
あくまで展示用&個人用に作ったものなので、どこまで正しい理解をしているかは不明です。AIも競馬もニワカなヤツが書いていると思って読んでくださいね。
なぜ当たったのか
わかりません。
当日だけでも36回、実際にはもっと試行しているわけで、サイコロで決めたのと同じかもしれないし、まともな人なら低確率の当たりを引いても「自分の頭がいいから予想が当たった」とは自惚れないのと同じように、「AIが強かったから当たった」と無邪気に信じるのはアブナイ感じがします。
この展示の趣旨は「AI同士が何やら怪しい知識や主張で『この馬が来る!』『いやこっちが来る!』とかワイワイ言い合ってるところを楽しむ」 であり、
ガチの競馬予想AIではないです。たぶん本気の予想AIは言語系のLLMではなくDNN(ディープニューラルネットワーク)などを使っているし、そのほうが正しいはずです。たぶん。(詳しくない)
ワイワイ予想してくれる8人のAIたち
後の記事で細かく解説しますが、まずは簡単にご紹介します。
| 放課後バケン部のメンバー | |||

勝星みちる 主人公 |

本所しらべ データ担当 |

樹ちあき 血統分析担当 |

時任はやて 調教LAP 分析担当 |

人見ゆかり 関係者分析 担当 |

史堂あゆみ 前走分析担当 |

時任つばさ 過去レース LAP分析担当 |

板倉ふみの 板書・書記係 |
8人の話し合い
基本的には以下のような構造で8人は話し合います。
細かい仕組みは別記事で解説します。
まずはこの構造自体が必要な理由から、
バケン部のリーダーである勝星みちると一緒に読み解いていきましょう。
複合AIシステム(CAIS, Compound AI Systems)の魅力
|
みちる |
Q. 20万馬券も的中させたのに 私たち(AI)のおかげとは言い切れないってひどくない!? |
まあ…このシステムが予想に強いかどうかは疑問符としておいても(それが目的ではないし)、設計思想の話で言えば 「複合させたLLM」は「シングルLLM」より優秀 とは言える気がします。
DNN(ディープニューラルネットワーク)タイプの予想AIに対してLLM(大規模言語モデル)タイプの予想AIが一方的に強いということは原理上ないと思うのですが、少なくともLLMだけの世界の中では、単体のLLMよりも複数のLLMを組み合わせたほうが良いユースケースも多いということ自体は、おそらく事実かと思います。そのことをプレゼンしたかったという目的もあるので、そう思う理由を以下の項で述べていきます。
なお、実演で見ていた方からの質問で一番多かったのは「使ってるモデルは?」というものだったので、多くの方が「ひとつのプロダクトをひとつのLLMモデルで実現する」という発想をお持ちだったのかなと思います。実際には、以下のモデルを組み合わせて使っています。
| モデル | 用途 |
|---|---|
| gemini-1.5-pro | 大量データから有利不利点の導き出し |
| GPT-4o | 少量データから有利不利点の導き出し、みちるの意思決定 |
| GPT-4o-mini | ホワイトボードへの議論まとめ書き込み |
| claude-3-5-sonnet-20241022 | 各人の主張の骨子作成 |
| claude-3-haiku-20240307 | キャラセリフ作成、個人単位の要約 |
このように複数をAIを組み合わせる手法を複合AI、CAIS(Compound AI Systems)と呼びます。
話が長いとAIも頭がパンクする
競馬予想のように考えさせるデータが多い分野でLLMにあらゆる情報を与えて「ハイ答えて」で1発回答を得ようとするのは悪手です。よく言われることですが、プロンプトが一定の長さを超えると、タスクに対する成果は悪くなりがちなためですね。
プロンプトの冒頭と末尾は効いても中間が弱くなるLost in Middleという現象もあるし、
もっと単純に 「一気にズラズラと話されて、あれもこれも求められると、何を考えればいいのか、ユーザーが何をしてほしいのかの解釈が分散してしまう」 という人間と同じことが起きます。
一気にごちゃごちゃ一杯言われると集中力が失われて頭も悪くなるのは人間も同じかと思います。
ですから、人間が大きな仕事に取り掛かる時と同じ 「大きなタスクは分割し、細切れにして順番に取り掛かる」 ことが有効なライフハックになります。
つまり、短いプロンプトでLLMを何回もコールするほうが思考の品質は良くなりがちなわけです。
多様な専門知識が必要な用途では特に複合AIが強い
特にドメイン知識が多いタスクにおいてはタスク分割・マルチLLMの手法が有効です。
ある分野に対する経験や知恵、ルールや法則などを「ドメイン知識」と呼ぶ場合、競馬予想にはたくさんの独立したドメイン知識が必要になります。
実際に今回展示したGALLOPIAというシステムでは以下の情報を考慮に入れています。
予想にあたって考慮しているファクタ(クリックで展開)
- 競馬場ごとの違い
-
- 右回りか左回りか
- 最終直線は長いか短いか
- ゴール前が急坂か緩坂か平坦か
- 当日情報
-
- 天気
- 馬場(良馬場、重馬場…)
- 斤量(騎手がつける重り)
- 馬体重
- オッズ
- 馬のプロフィール
-
- 血統(親や祖先が同じ馬から能力を推測)
- 関係者の成績傾向
- 騎手
- 馬主
- 生産者
- 調教師
- 厩舎の東西所属
- 調教時の成績
-
- 坂路コースの走破タイム
- ウッドチップの走破タイム
- 過去走での成績・対戦相手
-
- 連対したレースの格
- 過去連対時に先着した馬
- 斤量・馬体重が過去連対範囲か
- レース条件に対する懸念
- ブリンカーの装着状況
- 過去ラップ
-
- 1F, 2F, 4Fを利用した能力推測(参考文献)
これらの情報を一気にChatGPTに入れてワンボタンで予想なんかさせても、うまくいかないであろうことは想像に難くないと思います。めちゃくちゃくプロンプトが長いため入らないか、どれを特に重要視するかはAIの特性やムラや運まかせになるため、信頼度は低いです。(RAGを使っても何を切り落とすかをベクトルで決める話になるため同じ)
ドメイン知識ごとに分割して、それぞれ別個にLLMに分析させて、それら同士を後から別のLLMにマージさせていくほうが有効ではないか? というのが、今回の展示のアイデアです。
AIにもプライドはある
|
みちる |
Q. じゃあ、細切れにしたタスクを ひとつのAIがひとつずつ解けばいいんじゃない? どうして8人も必要なの? |
もちろん、AIを擬人化してワイワイ会話しているところが見たかったからというのが一番の理由ですが、
そもそもLLMを複合的に使うならタスクごとに「何をするか」だけではなく「(擬人化的に)誰がやるか」という 役割(Role) を付与してタスクをカテゴリ分けし、それぞれを個別の行動主体(エージェント)とみなして、それら同士を会話させる 「マルチエージェントLLM」 の考え方で設計したほうが結果の精度的に有利という面があります。
というのは、LLMに過去の記憶として「これがここまでの流れです」という情報を与えたときに1人(同一人物扱いするAI1つ)しかいないと、
「これがここまでの『あなた』の発言です。これを参考にして考えてください」というプロンプトになるわけですが、
このようなやり方でLLMに多段階の分析をさせると、 AIは「最初の意見を曲げずに貫く」方向に極端にふれる 傾向がしばしば見られるためです。
そもそも、ビジネス用途においてもプログラミング用途においても AIが「主張の一貫性」を持っていることはとても重要 です。チャットボットが直前まで言っていたアドバイスを(人間の発言に影響されすぎて)すぐ翻したり、既に書かれたプログラムの構造やスタイルを無視して、バラバラでその場しのぎなソースコードばかり吐き出すようなことがあっては使い物になりません。
ですから、AI(LLM)は普通、単体では「過去の自分の意見を簡単に曲げるのは恥ずかしいことだ」という、一種のプライド意識、心の芯の強さを持っているかのようにふるまいます。
しかし、さまざまな角度から多様な意見を順番に考察・出力していくような用途ではこれが邪魔な時もあります。 最初のほうの考察で仮に固めた意見をなかなか曲げなくなってしまい、後ろのほうで実行した考察や分析が何も結論に影響を及ぼせないので無意味になってしまう のです。行き過ぎると、大量かつ良質な情報を与えても「自分がこれまでしてきた主張と一致するエビデンスだけを取り上げ、それ以外は無視する」といったことも起きてしまいます。
プライドがあると「自己正当化」してしまうのは人間もAIも同じであるということです。
そうすると、せっかく多種多様な専門知識や考え方の流派・派閥、さまざまな切り口のデータを組み合わせ、戦わせてベストな結論を出したいのに、多様な意見が公平に統合されない という問題が起きてしまいます。
これを解決するのがRoleで、先ほどの登場人物紹介のように、ドメイン知識に応じてキャラクターが分かれており、それぞれが個別に独立した人格・役割・記憶をあたかも持っているかのように設計することで、「それぞれのAIは一貫性がある形で自分の主張を『思い込んで』いるけれど、それぞれのAIの主張同士を戦わせるうえでは公平にマッチできる」ということができます。
実装としては、そのタスクまでの考察や分析について同じキャラの主張や結果だけでフィルタリングしてLLMに渡すことで実現できます。
実際にそういった用途を想定して、今回使っているLangChainというライブラリではChatMessageというオブジェクトにroleという属性が設けられています。
こうして、8人それぞれにキャラをもたせ、マルチエージェントシステムとして扱うことで、「自分なりの芯のある考え方をもったAI同士が、それぞれ違う立場から議論を刻んでよりベターな解に向けて漸進する」といったことができるようになるわけです。
マルチエージェントLLMオーケストレーションの弱点
処理に時間がかかる
何度も何度もLLMをコールするということは、当然LLMに投げるプロンプトも重複箇所が増えます。ということは、インプットするトークン数に無駄が多いため、処理の総量としては時間が相対的にかかってしまいます。
コストが高い
時間がかかるということは、API提供されているLLMを使う場合には同じようにコストも増えるということです。特にデバッグ中のAPI代消費がつらく、休みの日にデバッグしていると何度もOpenAIから引き落としのメールが来てしまいます。どんどんAPIコストは安くなってきてはいますが、各社のAPIコストがもっと安くならないと、なかなか個人ではやれることが限られてしまいます……。(もっと安くして!)
正確性の問題
「求めるタスクに対して多角的・総合的によりよい答えを出す」という意味では強いのがマルチエージェント型ですが、一方でハルシネーションだけを見ると多段階にLLMを使うことには弱みがある(相対的に誤り率が高い)ということをタスクテスト~統計で示した論文があります。これは、手前のLLM処理で一定のハルシネーションがどうしても混入してしまうと、それ自体が「どの後続の処理に何をさせるか」に影響するため、掛け算的に誤り率が高くなるというメカニズムで説明されています。
OpenAI o1のような1個体だが多段階推論するAIの登場
o1はタスクを分割して時間をかけて処理をするという意味では複合AI(CAIS)と似ていますが、実際には個別のAIモジュールが組み合わさったシステムではなく、ひとつのモデルとして訓練されているAIだということをサム・アルトマン氏が発言しています。
例えるなら、マルチエージェントLLMオーケストレーションのような設計思想は「複数のキャラが会議をする」という感じですが、 o1はいわば「ひとつの人の頭の中に複数の人格があって、その中で話し合っている」 という感じです。
これはとても優れたアイデアで、何が良いかというと、入出力のトークン数的に重複が少ないのでその分コストも時間も有利であるということと、それぞれの人格同士が脳内ゆえに「明確に固定化された言語」で話さなくてもよく、もっと低レイヤーに考えを「脳内会議」で交わし巡らせられる(tokenizerが不要で、言語別のナレッジや表象の偏りも考慮不要)ということになるからです。そのぶん、ChatGPTでo1-previewを動かせばわかる通り、処理中に何を考えているかが人間にはうっすらしか分かりません 。
このようなAIのことを私は「モノリシックなAI」と呼んでいます。電子工学などで使われる言葉ですが、ICのように「一体化していて、バラして動かすものではない」というニュアンスです。
マルチエージェントLLMオーケストレーションの利点
人間がAIに運命を託すためには「賢い」だけでは足りない
モノリシックなAIは途中の経緯をうっすらしか把握できず、結論だけが得られますが、これは「自分のお金をどう使うかAIに決めさせる」といったような用途では問題です。
実際に例の20万馬券のレースは、
| 着順 | 馬名 | オッズ |
|---|---|---|
| 1着 | ナファロア | 221.9倍(14番人気) |
| 2着 | レッドアトレーヴ | 7.1倍(4番人気) |
| 3着 | ニシノインヴィクタ | 20.5倍(9番人気) |
という結果で、この3頭を全部当てないとお金が2000倍にはならないわけですが、
AIに「いいから14番人気の221.9倍の馬を買え!!」と言われても、にわかには信じられないわけです。14番人気はいわゆる「大穴」、18頭中14番目の人気ということは、ほとんどの人は来ない馬だと思っていたということです。そして実際、ほとんどのレースではやはり上位人気の馬が3着以内を占めることが多いのが競馬です。
特に11/16展示当日の東京競馬場でのレースは以下のように例のレース以外は1~2番人気の馬が1着になっており、例の12Rだけが異常 な結果なのは一目瞭然です。
| 1R | 2R | 3R | 4R | 5R | 6R | 7R | 8R | 9R | 10R | 11R | 12R | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 人気 | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 2 | 2 | 1 | 1 | 14 |
| 倍率 | 4.0 | 3.7 | 1.8 | 2.7 | 1.2 | 1.7 | 3.2 | 4.2 | 2.3 | 2.9 | 2.2 | 221.9 |
このような状況でいきなり14番人気の馬を買うというのは、人間にとってはあまりにも「ありえない」選択肢です。そうなると、神にも近い知能のAIが仮に存在したとして、そのAIに「14番人気の馬を買え!」と言われても、流石に躊躇してしまうのが人間というものでしょう。
つまり、このような人間にとって重大な決断をする場面をサポートするAIは、どうしても 「知能」だけでなく「説得力」と「共感力」 を兼ね備えたものでないといけません。たとえ賢く正解を導けていたとしても、人間が共感でき説得できなければ意味はありません。
こういった場面では、「どうして14番人気の馬が1着になると思うの?」という人間からの怪訝そうな問いに対して、 「うまく人間の言葉は説明できないんですが、私の脳内会議ではそうなったんです。私はいま世界で一番優秀なAIです、信じてください」 と言われるよりは、 「これがAI8人みんなで考えた会議の議事録です!ほら、ナファロアは14番人気ですけど、イスラボニータという馬の子どもで、イスラボニータの子どもはこのレースと同じ芝1600mのレースでこれまで2着以内に入った確率が28.2%あるんです。これは平均より高いし、ゴール前の400mで走る速さが全18頭中1位タイなんです。これは来るかもしれないでしょ!?」 と言われたほうが、信じてやろうかなという気にもなるというものです。
こういったAIが出す結論に対して説得力や共感力をもたせる取り組みは、画像生成なども含めて「説明可能なAI(Explainable AI)」という分野で研究されています。
今回の展示を通して体感できることですが、仮に将来AGI(人間なみのAI)やASI(人間以上のAI)が完成したとして、はたして人間は十分な経緯説明も共感できる要素もなしにそのAIに運命を託すことができるでしょうか? 競馬で5万円預けるだけでも信用できないのですから、命や財産、キャリア、人間関係など、人間にとって大事な分野で活躍するAIを作るためには、とても重要な課題であることはお分かりいただけるかと思います。
メンテナンスが簡単
これはマイクロソフトが「Magnetic-one」というマルチエージェントLLMシステムの構築を通して発表した論文でも書かれていることなのですが、自作パソコンのほうが完成品のノートパソコンなどよりパーツの修理や清掃、アップグレードが簡単であるのと同じように、個別に独立したAIエージェントが会議をするタイプのシステムはメンテナンスが簡単という利点があります。
実際に今回展示したシステムでは、最初はまず3人の専門家(血統分析のちあき、調教分析のはやて、関係者分析のゆかり)+みちる・しらべ・ふみの、の6人構成でしたが、予想精度に納得が行かなかったため、後から2人の専門家(過去走分析のあゆみ、過去LAP分析のつばさ)を追加しました。また、当初の設計よりも担当する仕事を増やしたキャラもいます。このように、 少しずつ作り足していく開発手法や後から改良したりバグ取りをするようなアドリブ性の強い開発を気軽に行えるのが、モノリシックではないマルチエージェントLLMの強みです。
エンタメに向いている
なにより、 AIたちがひとつの場所に集まって議論をしている様子は、それだけで楽しく、愛着が湧きます。 愛着が湧くと、それもまた共感力が上がり、人間が信じやすいAIになるということでもあります。今回のように展示会の見世物として作るといったエンタメ用途でもAIとしては、マルチエージェントLLMオーケストレーションはとても楽しいシステムとして提供が可能です。
まとめ
このように、多くの切り口から、今回の展示では「マルチエージェントLLMオーケストレーション」という手法の魅力を伝えることができました。
次回の記事ではより細かく、8人のAIがどのようなプロンプトを与えられていたか、どのような実装をしていたか(特にLangGraph、LangChainの良いところ)を説明したいと思います。お楽しみに!
次の記事を投稿しました!
次回記事ではマルチエージェントの構造をご説明しています。
