今回のテーマは百人一首AI
と言っても、音を聞いてとるまではパパッとは作れないので、とりあえず決まり字で札を判別できるようなAIを作ってみます!
ルールベースでいけるじゃんと思った方いますよね?
その通りです。。。
ただ、ここはデータサイエンティストとしてあえてルールベースを使わず、上の句と下の句のデータで学習を行い、勝手に決まり字で取れるように進化させることを目標にします!
百人一首とは?
百人一首は5.7.5の上の句と7.7の下の句に分けられ、上の句を読んでいる間に下の句の札を取るという競技です。
例えば「秋の田の かりほの庵の 苫をあらみ わが衣手は 露にぬれつつ」という俳句は「秋の田の かりほの庵の 苫をあらみ」と読んでいるうちに「わが衣手は 露にぬれつつ」という札を取ります。
しかし百人一首には決まり字というものがあり、「あき」までであれば他に「秋風に たなびく雲の たえ間より もれ出づる 月の影のさやけさ」という句があるのでまだどちらの札を取ればいいか判断できませんが、「あきの」で始まる札は他にないのでここまで読まれば「わが衣手は 露にぬれつつ」を取ることができるのです。

今回やること!
 こんな感じでAIを鍛えます!
学習によりAIは上の句を全部読むと下の句がどれか判断できるようになります。
こんな感じでAIを鍛えます!
学習によりAIは上の句を全部読むと下の句がどれか判断できるようになります。

このAIに、決まり字までの上の句を読んだ場合、取るべき札を予測できるかというのがテーマです。

使う手法
Deep Leaningの時系列モデルの1つであるLSTMを使います。
詳しい説明は(こちらのページ)をみてください!
データの準備
データはこちらのページに上がっていた百人一首のcsvを少し改変して使いました。
import pandas as pd
df = pd.DataFrame("data.csv")
df.head(5)
| No | 上の句(ひらがな) | 下の句(ひらがな) | 決まり字 |
|---|---|---|---|
| 1 | あきのたのかりほのいほのとまをあらみ | わがころもではつゆにぬれつつ | あきの |
| 2 | はるすぎてなつきにけらししろたへの | ころもほすてふあまのかぐやま | はるす |
| 3 | あしびきのやまどりのをのしだりをの | ながながしよをひとりかもねむ | あし |
| 4 | たごのうらにうちいでてみればしろたへの | ふじのたかねにゆきはふりつつ | たご |
| 5 | おくやまにもみぢふみわけなくしかの | こゑきくときぞあきはかなしき | おく |
上の句(ひらがな)から下の句(ひらがな)を予測するAIを作り、決まり字のひらがなだけで下の句(ひらがな)を予測できるか検証します。
コーディング
keras使ってLSTMのモデル組みました〜
コードはgithubにあげておきくので見たい人はぜひ!!
結果
上の句全体から下の句を予測する学習は精度100%になりました。
果たして決まり字から予測できたのか!?
結果は。。。4%!?
100枚あって正解は4枚だけ。。。全然ダメでした。笑
合っていたのは決まり字が「あまの」「やまざ」「あさぼらけう」「たま」の4つでした。
なぜだめだったのか?
 今回使用したLSTMという手法は忘却層というものがあり、最初の方の入力、つまり1文字目や2文字目の情報をどんどん忘れていきます。
本来はこれはより複雑なデータを精度良く予測できるのですが、今回は上の句の前半の方から予測するというタスクだったので、前半の方を忘却してしまい、うまくいかなかったのかもしれません。
今回使用したLSTMという手法は忘却層というものがあり、最初の方の入力、つまり1文字目や2文字目の情報をどんどん忘れていきます。
本来はこれはより複雑なデータを精度良く予測できるのですが、今回は上の句の前半の方から予測するというタスクだったので、前半の方を忘却してしまい、うまくいかなかったのかもしれません。
入力を逆さにすればいけるんじゃないか?
逆さにすることで決まり字のあたりの忘却を防ごう!と考え、学習する時に逆さに読むようにしました。

しかし結果は。。。精度2%。。。
ダメダメですね。
またまたなぜダメだったのか?
少し簡略化して説明します。厳密には式がもう少し複雑だったりしますがそこは目を瞑りましょう。
例えばアイスの売り上げを予測するAIはどういう風に予測するのかというと、下の式のようになります。

この時、気温が28度、駅からの距離が100mの場合、
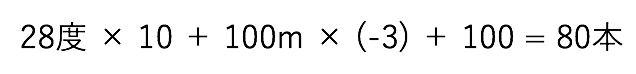
から、アイスの売り上げが80本と求められます。
今回やったタスクは、この時に気温だけからアイスの売り上げを求めるというものになっていました。
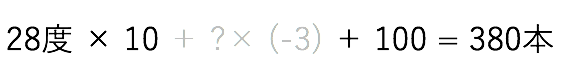
全然違う値になっちゃうんですよね。
今回も「あきのたのかりほのいほのとまをあらみ」から予測するような式を作っていたのに
、「あきの」だけから予測しようとしてもできるはずがないですよね。

失敗を引き起こす原因は以上です。
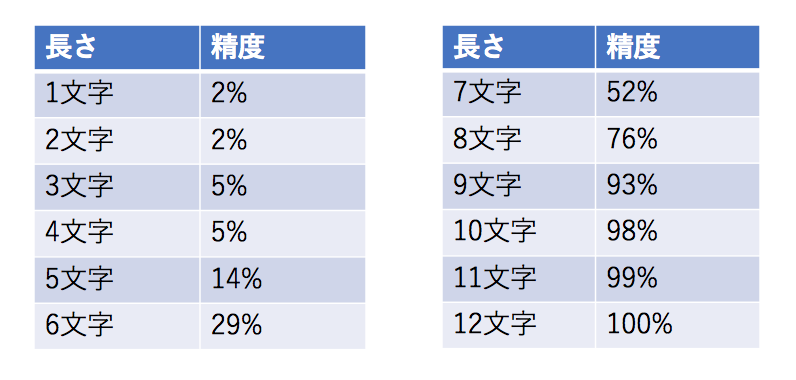
上の句の文字数を増やしながら予測していくと、12文字で精度100%になりました。
上の句は5.7.5で17文字くらい。それよりは少ない文字でも予想できましたね。
文字数を増やすと段々精度がよくなっていることも分かります。つまり学習のデータと検証のデータが似ているほど、AIのパフォーマンスが上がるということですね。
結論
AIを学習するときは、ちゃんと本番と同じ環境のデータで学習しましょう。
今回のように学習のデータは上の句全てで行なったのに、予測の時には決まり字までの数文字で予測するというのではうまくいきません。
これは実社会でも一緒で、学習の時には北海道のアイスの売り上げで学習して、沖縄のお店でアイスの売り上げを予測しようとしてもうまくいきません。
この場合は沖縄のデータで学習しましょう。