はじめに
超解像について調べていましたが、せっかくなので調べた内容をQiitaに残していきます。
今回はDeepLearning導入期の単眼超解像のモデルについて、紹介します。
目次
単眼超解像とは?
超解像とは、低解像度から高解像度の画像を再構成するComputer Visionのタスクです。特に単眼超解像(Single Image Super Resolution/SISR)とは、(動画などではなく)1枚の低解像度画像から、高解像度の画像を再構成するタスクです。
SRCNN
超解像のタスクにDeepLearningが初めて取り入れられたのは[1]で、Super-Resolution Convolutional Neural Network(SRCNN)というモデルです。
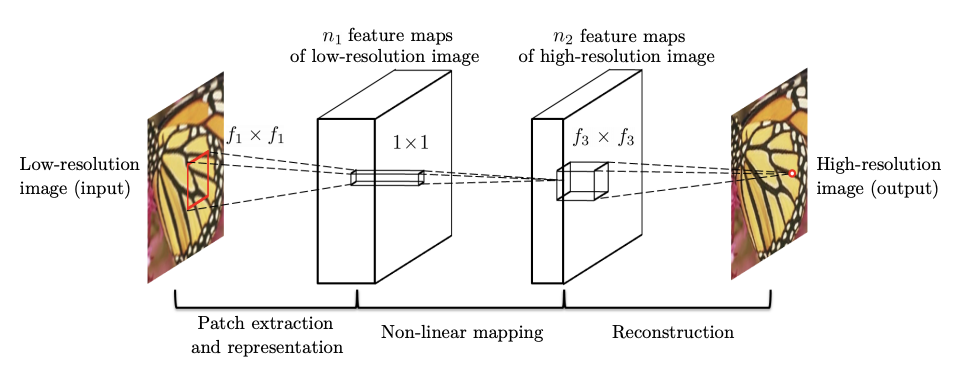
上記のように、まず低解像度画像をbicubic補間を、高解像度画像と同じ解像度にした後、
- $f_1\times f_1$ Conv/ReLU
- $1\times 1$ Conv/ReLU
- $f_3\times f_3$ Conv/ReLU
という3つの畳込みで構成されている大変シンプルなものです。損失関数にはピクセルごとのMSEを使用します。これだけでも2014年、当時としてはSOTAを達成することができました。この研究は空間コーディングベース手法というアプローチの影響を強く受けております。空間コーディングベース手法は以下の構成だったようですが、それぞれがConvolutionで置き換えられています。
- 画像からオーバーラップするパッチを取り出して前処理
- 低解像度の辞書でエンコード
- 高解像度の辞書に渡して、射影して再構成画像を生成する
この論文によって、従来よりもPSNRといわれる指標でSOTAを、そして従来手法よりも再構成のスピードが格段に向上しました。
VDSR
SRCNNの研究には課題があり、[2]ではVDSRというモデルでそれらの問題を改善しています。SRCNNでは層ごとに別の学習率が採用されており、その学習率は$10^{-4}$や$10^{-5}$などという小さい学習率を使っていたため、訓練が遅い問題がありました。それゆえに、層を深くすることができませんでした。この問題に対して、[2]では、勾配クリップを使って、高い学習率でも学習できるようにしました。ただの勾配クリップではなく学習率に応じて、クリップのしきい値を変えているところが特徴的です。
さらに、グローバルな残差学習を使って効率的に学習するようにしました。ここでグローバルな残差学習とは、ResNetに出てくるような残差ブロックではなく、全体としての残差を学習させるという意味です。低解像度画像と高解像度画像は同じような情報を持っているため、低解像度画像と高解像度画像の差を学習させることで足りるという意味です。また、
それだけでなく、SRCNNでは単一の複数スケールの高解像度画像しか再構成できませんでしたが、VDSRでは複数の解像度の画像を同時に学習させることで、1つのネットワークから複数スケールの画像を再構成できるようにしました。単に複数スケール対応にできただけでなく、性能向上も実現しています。
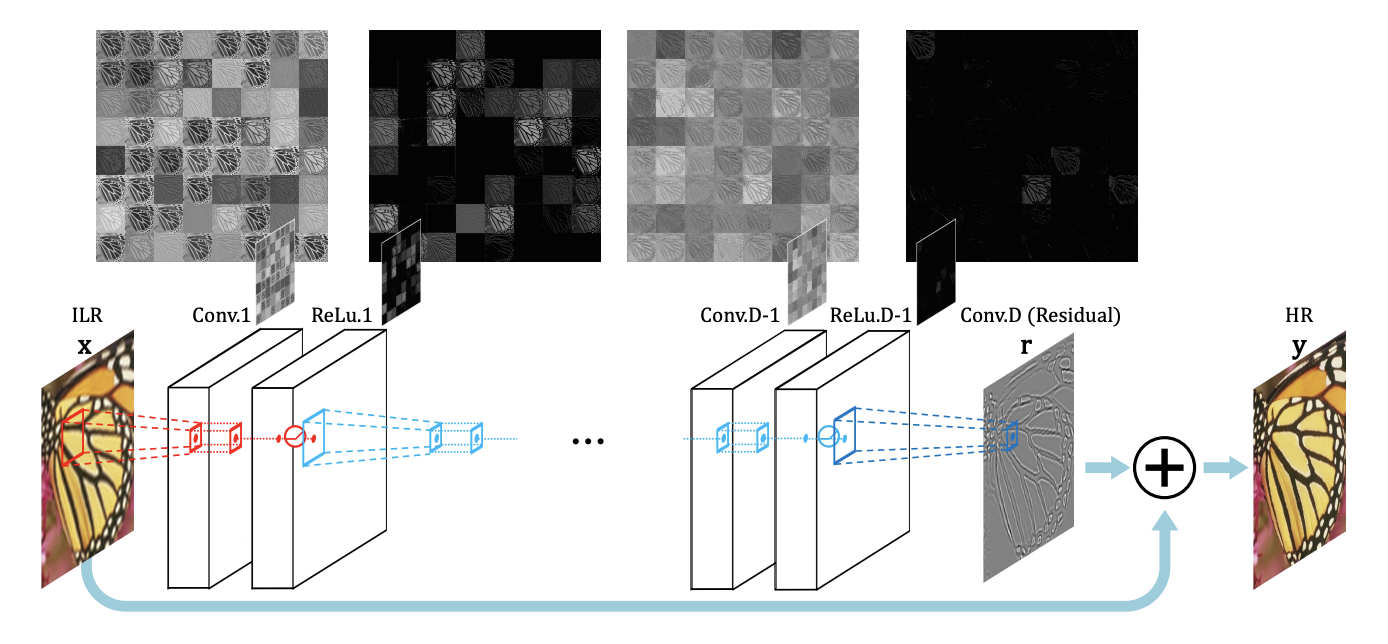
VDSRでは畳み込みの部分は$3\times 3$Convを繰り返すことで、大きめのカーネルを使用していたSRCNNに比べて、パラメータ効率がよいネットワークデザインとなっています。
FSRCNN
SRCNNには他にも課題がありました。最初に高解像度画像と同じ解像度にしてから畳み込むため、計算コストが高いのです。また、SRCNNは従来の研究よりは高解像度画像への再構成の速度は速かったのですが、それでもリアルタイムの画像を処理できる速さではありませんでした。この問題を解決したのが[3]で導入されたFSRCNNとリアルタイム用により高速化したFSRCNN-sです。
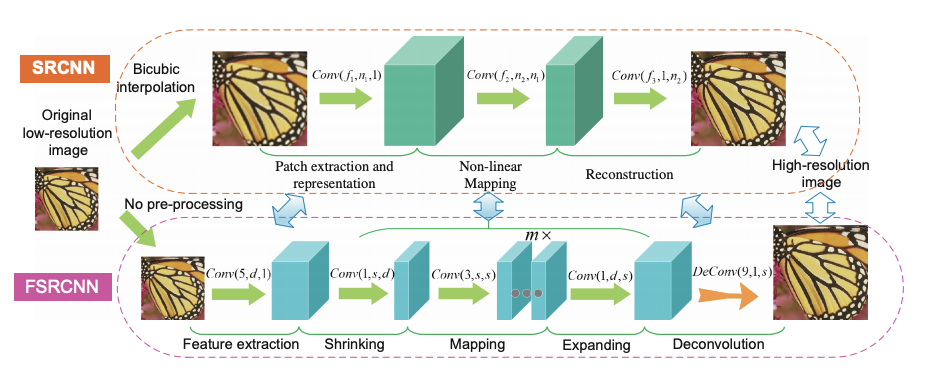
計算コストの問題に対しては、最初に使用していたbicubic補間をやめて、低解像度画像のまま畳み込みを行う方式に変更しました。解像度の調整は最後に行うことにし、そこでは画像がぼやけてしまうbicubic補間ではなく、学習可能な逆畳み込みを使用することで、より鮮明な画像を再構成することはできるようになりました。
また、特徴抽出や、計算量削減のための収縮・拡大などの工夫がされています。また、細かいところでは、ReLUの代わりにPReLUを採用しています。これらの工夫により、SRCNNと比較して精度を改善するだけでなく、速度面で大幅な改善を果たしました。特にFSRCNN-sのモデルでは24fps以上の速度を達成しており、動画のリアルタイム推論にも耐えうる速度となりました。
参考文献
- [1] Dong, Chao, Chen Change Loy, Kaiming He, and Xiaoou Tang. 2014. “Learning a Deep Convolutional Network for Image Super-Resolution.” In Computer Vision – ECCV 2014, 184–99. Springer International Publishing.
- [2] Kim, Jiwon, Jung Kwon Lee, and Kyoung Mu Lee. 2016. “Accurate Image Super-Resolution Using Very Deep Convolutional Networks.” Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition 2016-Decem: 1646–54.
- [3] Dong, Chao, Chen Change Loy, and Xiaoou Tang. 2016. “Accelerating the Super-Resolution Convolutional Neural Network.” In Computer Vision – ECCV 2016, 391–407. Springer International Publishing.