これは ZOZO Advent Calendar 2022 カレンダー Vol.4 の 1日目の記事です。
はじめに
こんにちは。今年は自宅でからすみ作りに挑戦している岡本です。
自分の所属チームであるMLOpsブロックでは、主にMLモデルを組み込んだシステムの開発・運用・保守を行なっています。
要件によってシステムの構成は様々ですが、基本的にBatch, API, DBが主な構成要素として存在することが多く、大別すると以下の2種類の構成を取っています。
- オンライン推論を行うケース
- Batchではモデルの学習を行い、APIはリクエスト受けてから学習済みモデルで都度推論を行い、呼び出し元にレスポンスを返す
- オフライン推論を行うケース
- 予めBatchで推論を行った結果をDBに保存しておき、APIはDBのレコードを参照して呼び出し元にレスポンスを返す
基本的にいずれのケースにおいてもAPI, Batchの開発が必要となり、チームの人数に対して管理対象のシステムは少なくとも2つ以上増えていきます。そのため、これらに割く工数を少しでも下げつつ、安定したシステムを構築したいという思いがあり、より良いシステムの構成を模索している今日この頃です。
今回はAPIを構成するためのサービスとして以前から気になっていたVertex AI Endpointsについて、どういったサービスなのか? どういった利用メリット・デメリットがありそうか?という観点から軽く調査を行ったため、今後のAPI設計における資料として残します。
Vertex AIとは
Vertex AIとはGoogle Cloudが提供している機械学習(ML)開発向けの統合プラットフォームです。
MLモデルのトレーニング、精度の評価、ハイパーパラメータの調整、モデルとエンドポイントの管理など、ML開発における便利サービスが多々提供されています。
弊社でもVertex AIで提供されるサービスのうち、Vertex Feature StoreやVertex AI Pipelinesについては既に利用実績があります。特にVertex AI Pipelinesについては弊チームでBatch開発を行う際に標準的に利用させていただいております。
どちらも弊社TECH BLOGに記載があるため、ご興味ある方は参照されてください。
- Vertex Feature Storeの機械学習システムへの導入
- Kubeflow PipelinesからVertex Pipelinesへの移行による運用コスト削減
- Vertex AI Pipelinesによる機械学習ワークフローの自動化
Vertex AIを利用したモデルのサービング
本題です。
極論ですが、MLを利用したサービスを提供するAPIを最小で構成する場合、MLモデルをHTTPリクエストで呼び出せるようにラップしたようになるかと思います。
この最小の構成を実現しつつ、APIのパフォーマンス監視、水平オートスケールの他、モデルのバージョン管理、トラフィックの分割といった機能を提供してくれるサービスが、Vertex AI Endpoints + Vertex AI Model Registryという所感です。
項目ごとに調査(やってみた)内容を記載します。
モデルのサービング
Vertex AIでモデルをAPIとして公開するためには、まずDocker imageを用意する必要があります。(https://cloud.google.com/vertex-ai/docs/predictions/pre-built-containers)
ここではGoogle Cloud側で提供しているビルド済みimage, 独自に作成したimageが利用可能です。
Google Cloud側で提供しているビルド済みimageではTensorFlow, Optimized TensorFlow runtime(Preview), scikit-learn, XGBoostが用意されています。
今回は独自に作成したコンテナイメージをもとにAPIを公開しました。
コンテナイメージの準備
上述のビルド済みimageではHTTPサーバーの機能が用意されていますが、独自にimageを作成する場合はこの機能を提供できるようにcontainerを構成する必要があります。
今回はFast APIを使用してimageの作成を行いました。
カスタムコンテナの要件はhttps://cloud.google.com/vertex-ai/docs/predictions/custom-container-requirements?hl=ja に記載されています。
特に実装時の注意点は以下になります。
- ヘルスチェックのパスが必要
- サービングするモデルごとに指定可能なパスは1つのみ
- APIのリクエスト / レスポンスの形式に制限がある
- リクエスト
- リクエストメソッドはPOSTのみ対応(ヘルスチェックのみGET)
-
Content-Type:application/jsonヘッダーとJSON形式のbodyを持つrequestを受け入れる必要がある - requestのbodyは"instances"のキーを必須で持つ必要がある
- レスポンス
- サイズを1.5MB以下にする必要がある
- responseのbodyは"predictions"のキーのみ指定可能
- responseのbodyで"predictions"のキーに対応する値はJSON値の配列である必要がある
- リクエスト
以下が作成したサンプルのAPIになります。
作成したimageはContainer Registryまたは、Artifact Registryに保存する必要があります。
サンプルコード
from fastapi import FastAPI, Request, Response
from fastapi.routing import APIRoute
from typing import List, Callable
from pydantic import BaseModel
app = FastAPI()
class Item(BaseModel):
feature: float
class Instances(BaseModel):
instances: List[Item]
class Prediction(BaseModel):
id: float
score: float
class Predictions(BaseModel):
predictions: List[Prediction]
class Model:
def predict():
return Prediction(id=1, score=0.98)
@app.get("/healthcheck")
async def healthcheck():
return {"message": "healthy"}
@app.post("/predict", response_model=Predictions)
async def recommend(instances: Instances):
predictions = []
model = Model()
prediction = model.predict()
predictions.append(prediction)
return Predictions(predictions=predictions)
[tool.poetry]
name = "vertex-ai-endpoint-tutorial"
version = "0.1.0"
description = ""
authors = [""]
readme = "README.md"
packages = [{include = "vertex_ai_endpoint_tutorial"}]
[tool.poetry.dependencies]
python = "^3.10"
fastapi = "^0.87.0"
uvicorn = "^0.20.0"
[tool.poetry.group.dev.dependencies]
black = "^22.10.0"
[build-system]
requires = ["poetry-core"]
build-backend = "poetry.core.masonry.api"
FROM python:3.10 AS base
WORKDIR /app
RUN pip install 'poetry==1.2.0'
COPY poetry.lock ./
COPY pyproject.toml ./
RUN poetry config virtualenvs.in-project true && poetry install --only main --no-root
COPY main.py ./
ENV PATH="/app/.venv/bin:$PATH"
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8080"]
モデル(コンテナイメージ)のimport
作成したコンテナイメージをVertex AI Model Registryに取り込みます。
モデル作成時にAPIデプロイ時に呼びだすパスやヘルスチェックのパス、APIで参照する環境変数、ポート等を指定します。
オプショナルな機能として、特徴量がどの程度推論結果に貢献しているのかを説明可能になり、モデルのバイアスを認識してモデルやトレーニングデータの改善方法を確認できるようになる機能が提供されています。(Vertex Explainable AI)
作成手順
1.コンソールのModel RegistryからIMPORTを押下
2.モデル名, リージョン等を指定
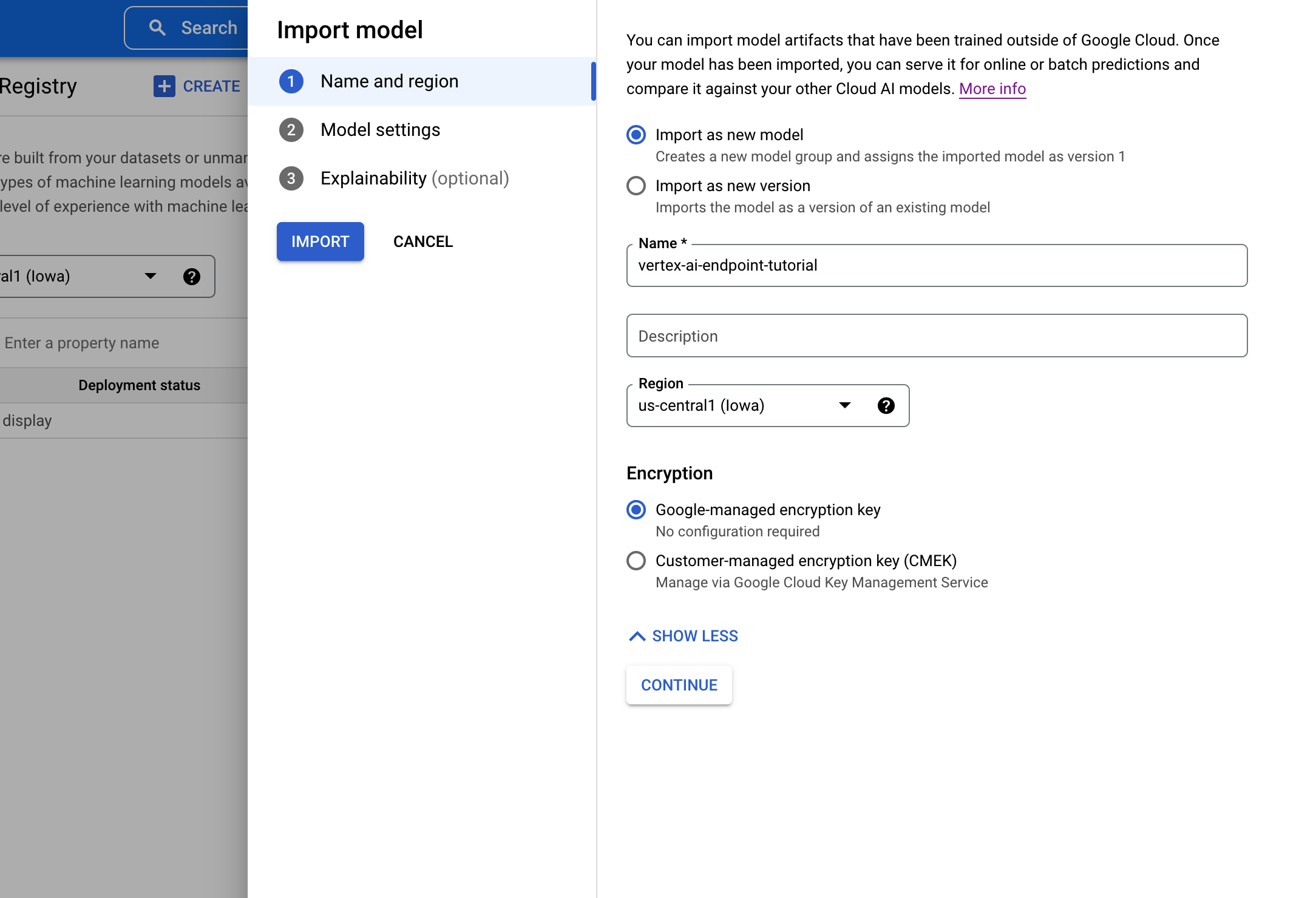
3.コンテナイメージの指定
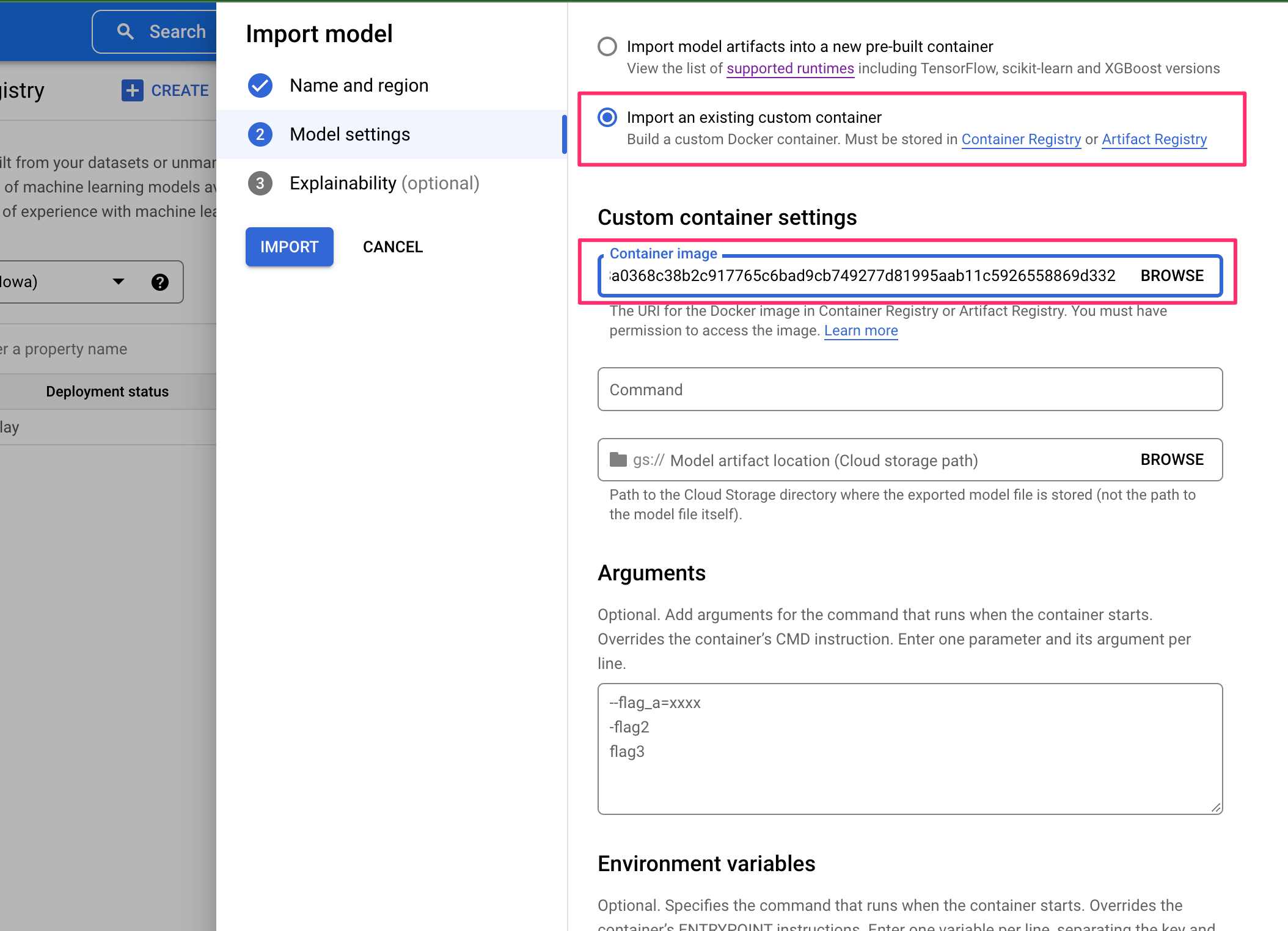
4.環境変数, パス, ヘルスチェック, ポートの指定
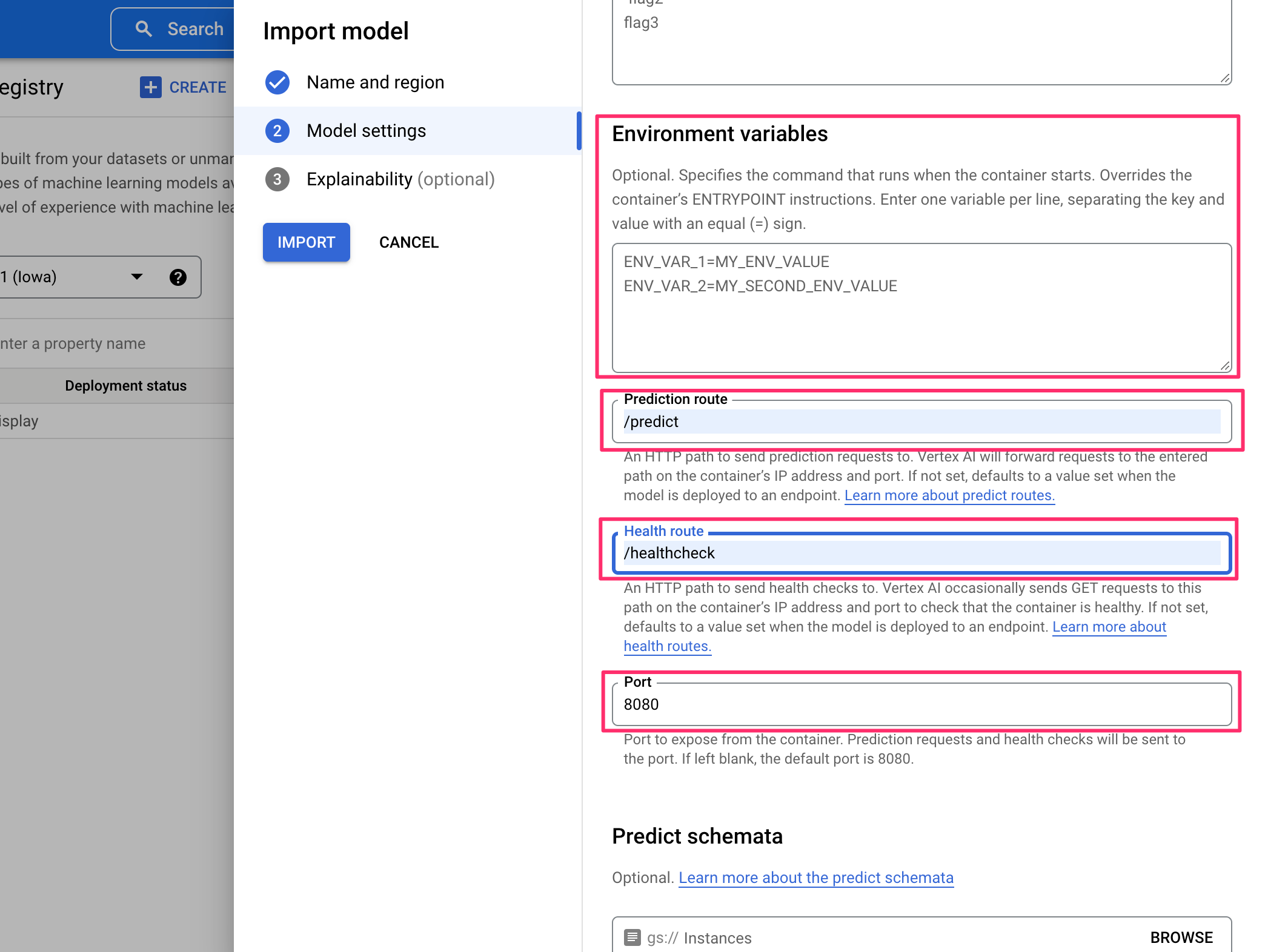
5.説明可能にするためのオプション
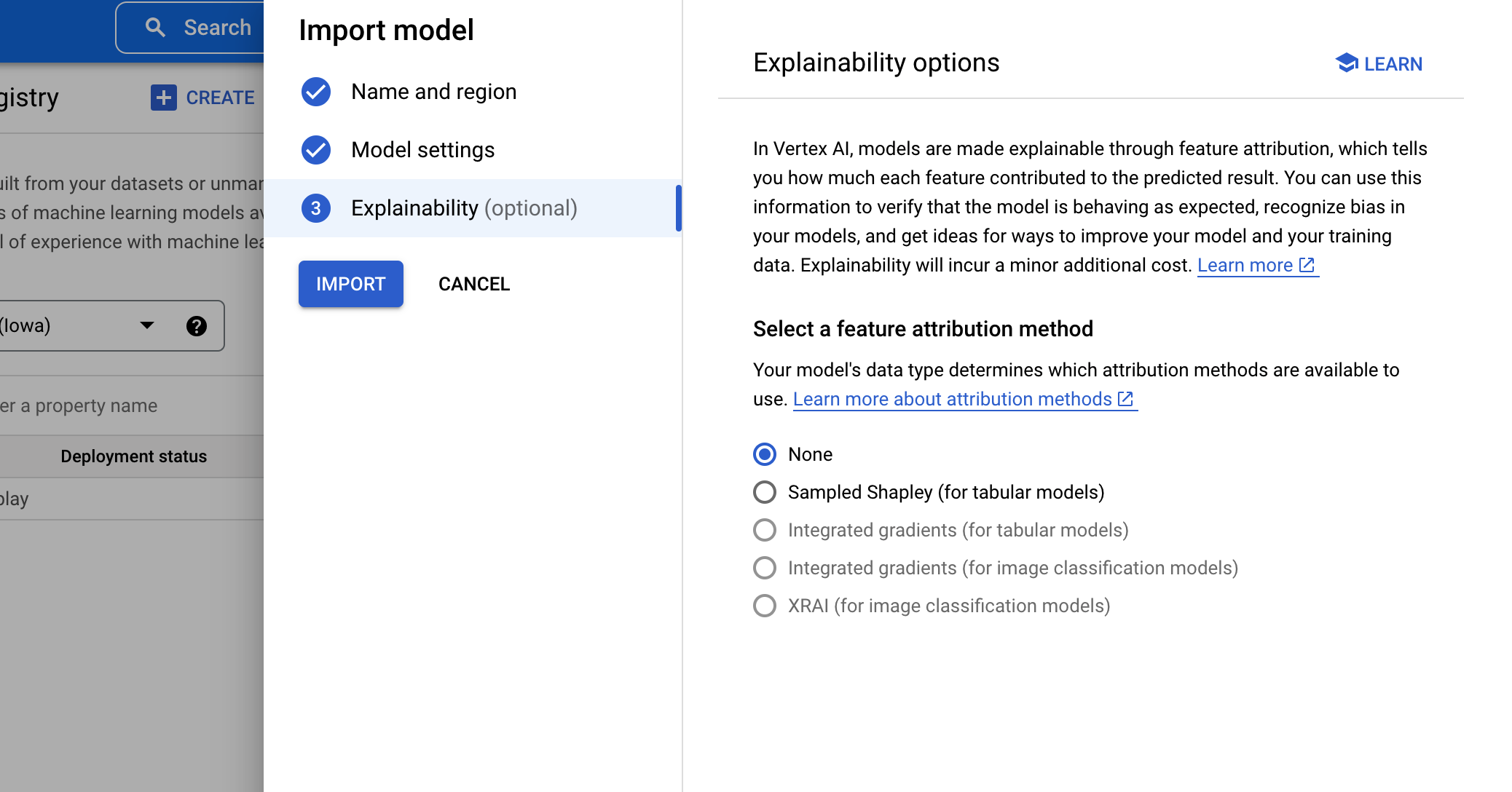
6.IMPORTを押下して作成完了
Endpointsの作成
importしたモデルを提供するエンドポイントを作成します。
エンドポイントの公開方法として、認証付き公開エンドポイントとして公開する方法とVPC Peeringを構成して公開する方法があります。
VPC Peeringを使用して公開する場合、トラフィックの分割をサポートしていないなどの制限があります。詳細はhttps://cloud.google.com/vertex-ai/docs/predictions/using-private-endpoints#limitations を確認してください。
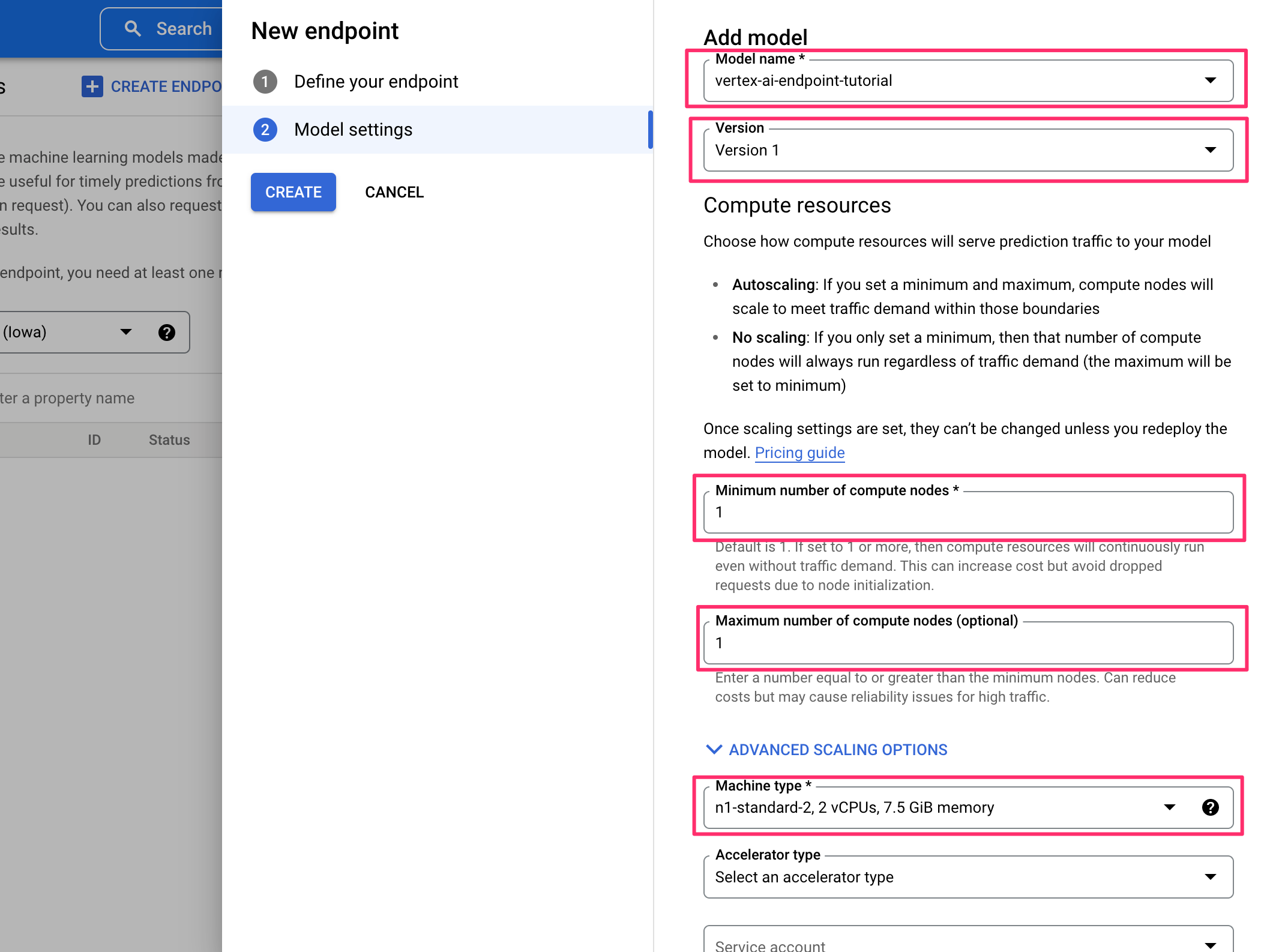
APIが動作するNodeの台数はリソースの使用量に応じてオートスケール可能です。また、CPUの他にGPUを選択することも可能です。
作成手順
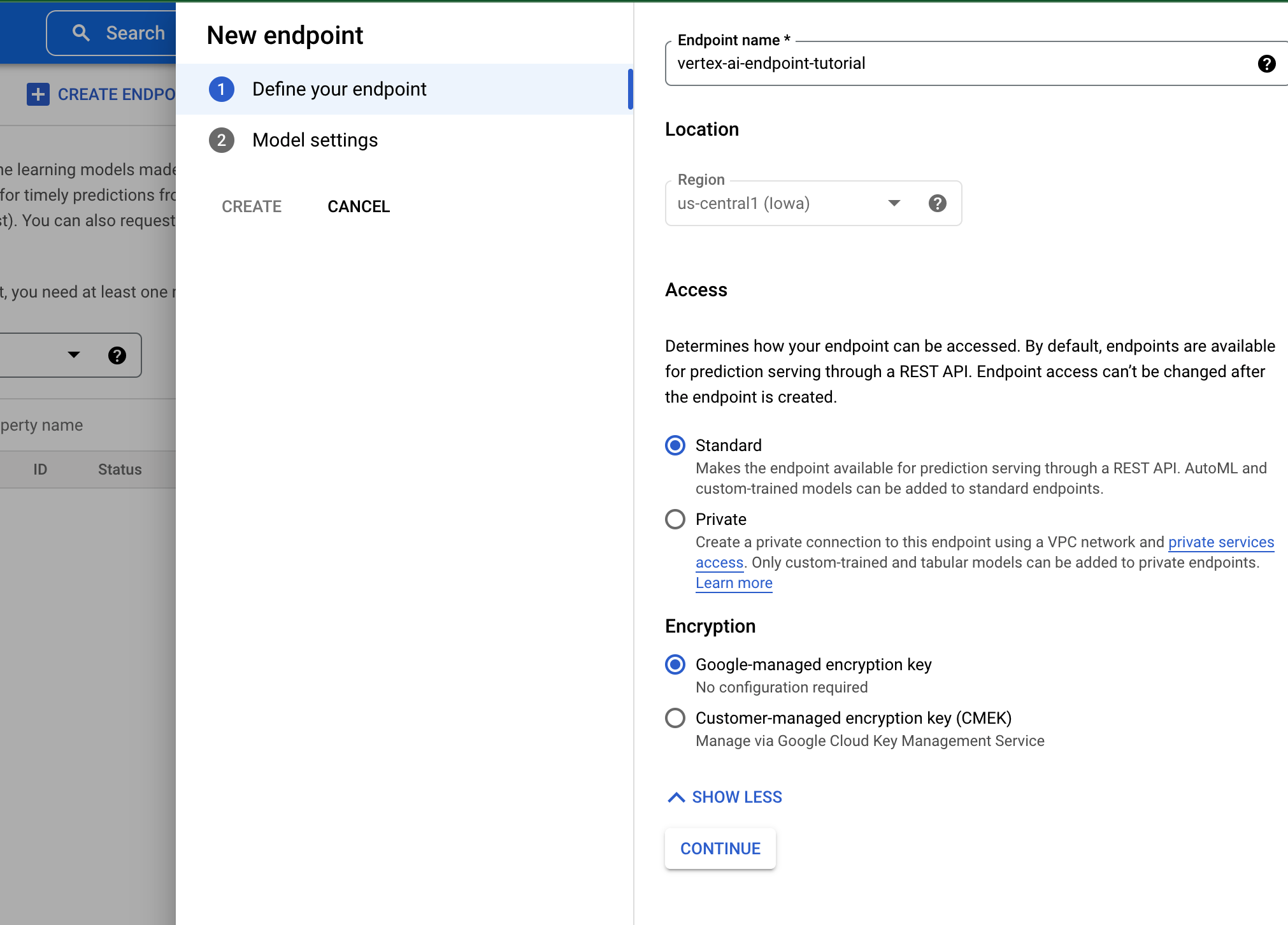
1.コンソールのEndpointsからCREATE ENDPOINTを押下
2.エンドポイント名, リージョン, アクセス方法等を指定します
3.公開するモデル名とバージョン, Nodeの最小台数, 最大台数, マシンタイプを選択する
4.ログの有効化を選択(デフォルトで有効化されている)
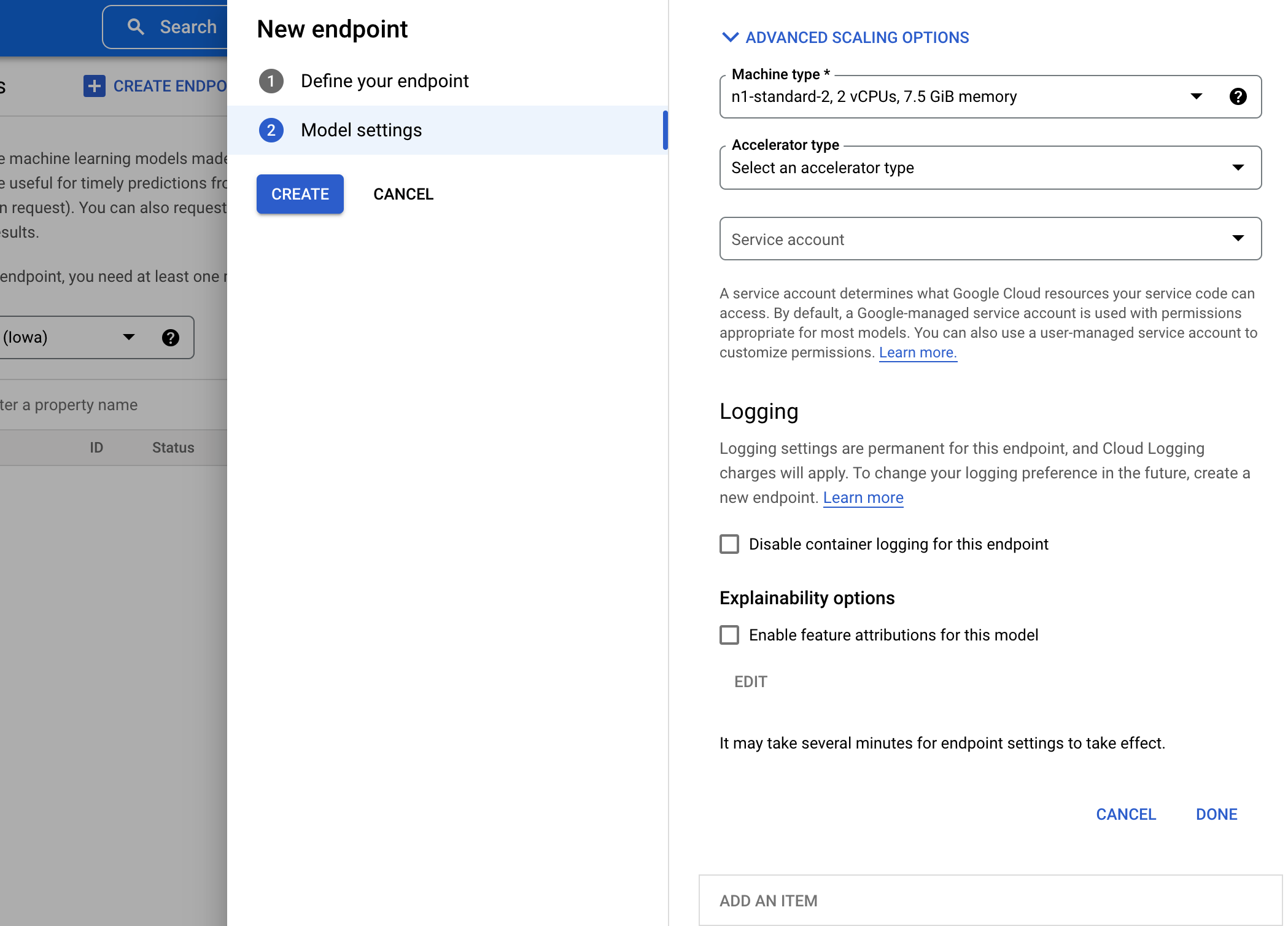
5.CREATEして完了
動作確認
コンソールからAPIの動作確認を行うためのsampleリクエストを確認することができます。
curlでリクエストする場合はaccess-tokenをリクエストのヘッダーに含める必要があります。Service Accountを使用してPython SDK等からリクエストする際はリクエスト時に明示的にトークンを渡す必要はありません。(https://cloud.google.com/vertex-ai/docs/predictions/get-predictions?hl=ja#send_an_online_prediction_request)
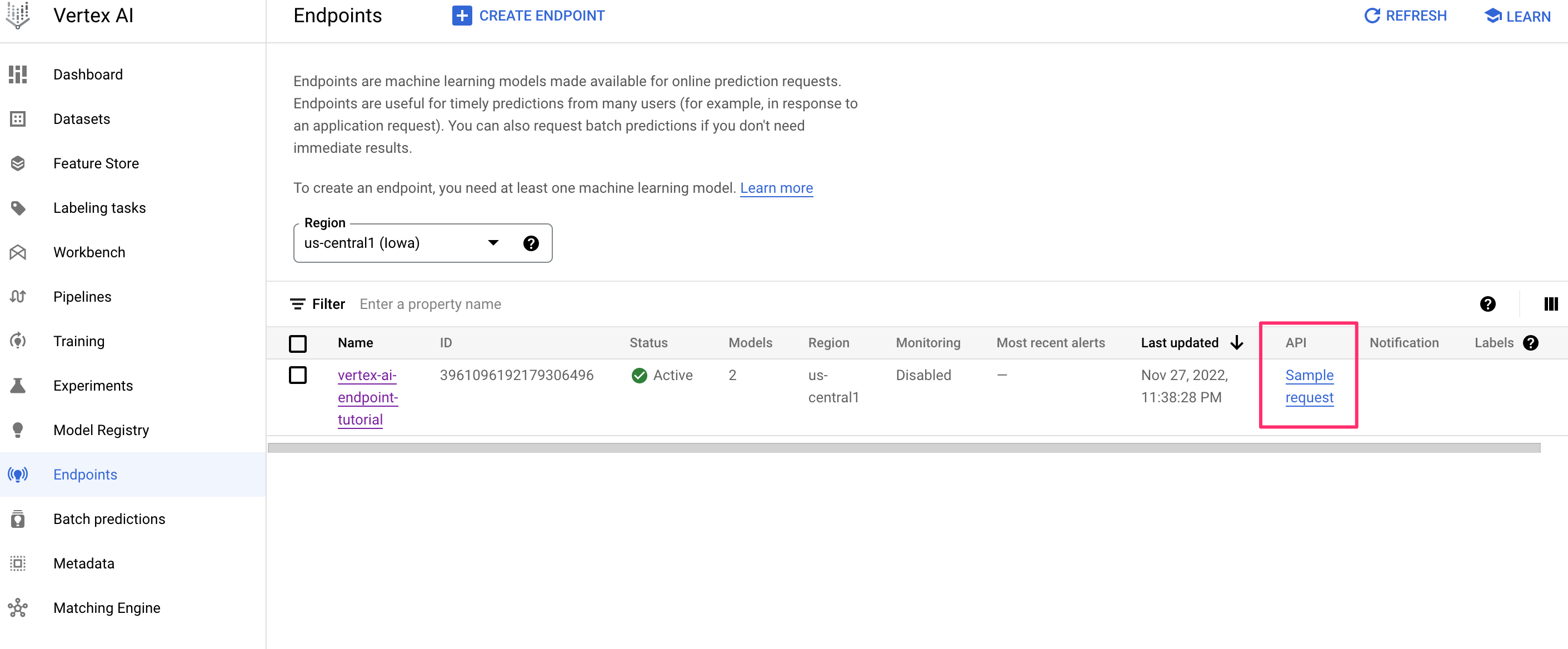
request bodyとして↓のようなsample.jsonを用意しました。
キーとしてinstancesを持つことが注意すべき点です。また、今回はリクエストパラメータは特にないため、オプションのparametersキーはrequest bodyに指定していません。
{"instances": [{"feature": 0.5}]}
以下のようにcurlリクエストを実行するとレスポンスが返ります。
ENDPOINT_ID="3961096192179306496"
PROJECT_ID="hoge"
INPUT_DATA_FILE="sample.json";
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict \
-d "@${INPUT_DATA_FILE}";
{
"predictions": [
{
"id": 1,
"score": 0.98
}
],
"deployedModelId": "3027839518616059904",
"model": "projects/XXXXXXXXXXX/locations/us-central1/models/8307454661661556736",
"modelDisplayName": "vertex-ai-endpoint-tutorial",
"modelVersionId": "2"
}
機能
トラフィックの分割
1つのエンドポイントに複数モデルをデプロイする場合、トラフィックの分割を行うことが可能です。
※ 前述の通り、公開時にPrivate Service Access経由のみのアクセスに絞った場合はこちらの機能は使用できません。(2022/11月現在)
既存のエンドポイントを編集し、Add modelでモデルの追加を行うことで1つのエンドポイントで2つのモデルのサービングが可能になります。
このとき、Traffic splitの値が全てのモデルで合計100になるように構成する必要があります。
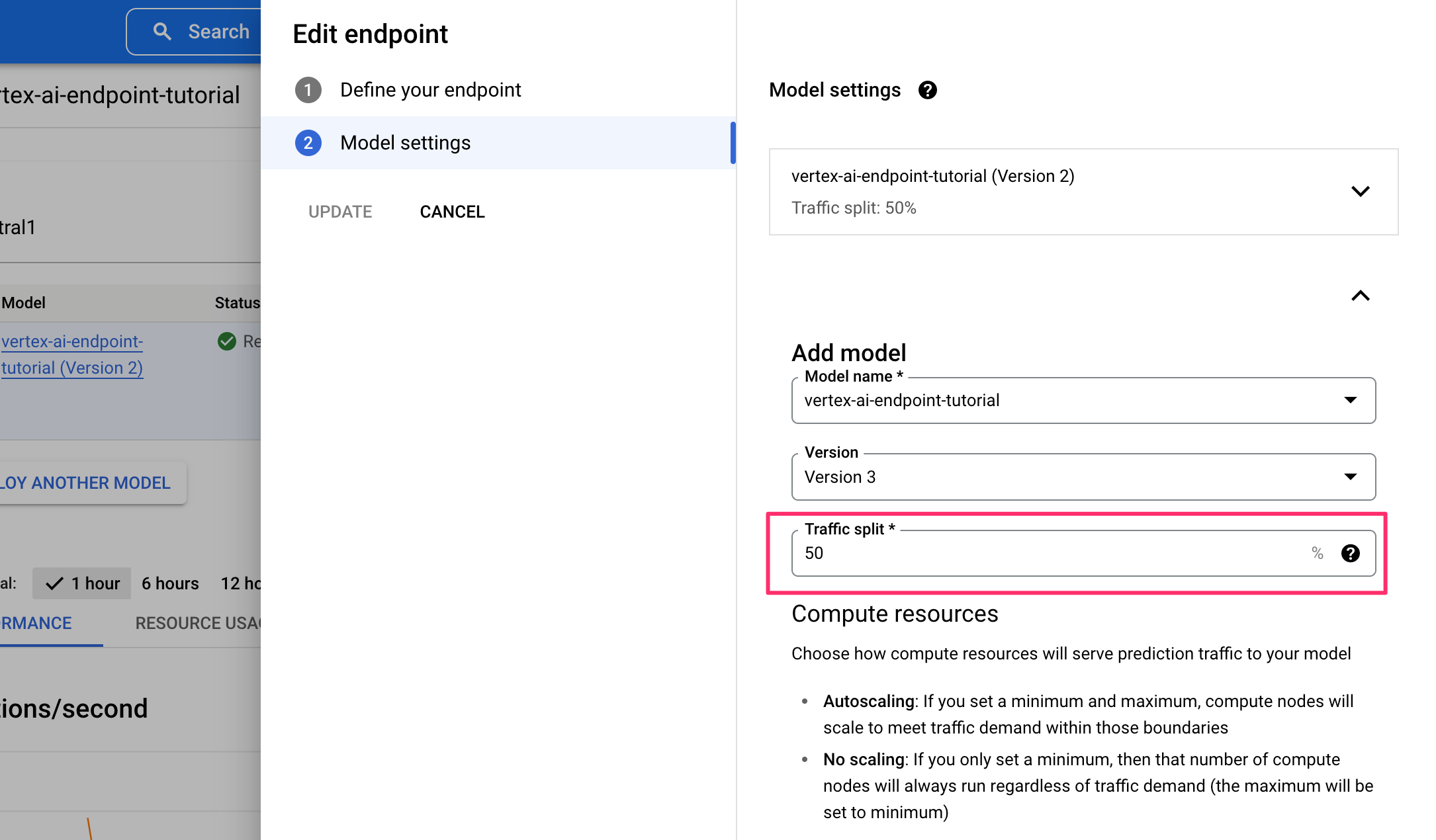
Traffic splitを50%ずつに構成して新しいモデルをデプロイしたところ、1度目と2度目のリクエストのレスポンスが変わっていることが確認できます。
# 1回目のリクエスト
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict \
-d "@${INPUT_DATA_FILE}"
{
"predictions": [
{
"id": 1,
"score": 0.98
}
],
"deployedModelId": "3027839518616059904",
"model": "projects/981965504579/locations/us-central1/models/8307454661661556736",
"modelDisplayName": "vertex-ai-endpoint-tutorial",
"modelVersionId": "2"
}
# 2回目のリクエスト
curl \
-X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json" \
https://us-central1-aiplatform.googleapis.com/v1/projects/${PROJECT_ID}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict \
-d "@${INPUT_DATA_FILE}"
{
"predictions": [
{
"score": 0.85,
"id": 2
}
],
"deployedModelId": "8440040370808553472",
"model": "projects/981965504579/locations/us-central1/models/8307454661661556736",
"modelDisplayName": "vertex-ai-endpoint-tutorial",
"modelVersionId": "3"
}
モデルのバージョン管理
Vertex AI Endpointsのコンソールでは、どのモデル/バージョンがデプロイされており、どの程度トラフィックが分割されているかが確認しやすくなっています。また、モデル名のリンクを押下するとModel Registryのコンソール画面に遷移し、評価やバージョンの詳細情報の確認についても行いやすくなっています。
GKEやCloud RUNといったサービスでMLモデルを組み込んだAPIのサービングを行う場合、環境変数等でモデル名やバージョン等を指定しているとGitでバージョン管理されているとはいったものの、どのAPIでどのモデルが利用されているかを確認するのは手間になるため、Vertex AI Endpoints + Vertex AI Model Registryの構成だとこういったモデルの追跡的な部分は遥かにやりやすそうという印象を受けました。


運用
APIの監視
Endpointsのコンソールから各エンドポイントごとにデプロイされたモデルごとのメトリクスを確認することができます。
- レイテンシ
- リクエスト数
- レスポンスステータスコード
- CPU, メモリ利用率等
例えばレイテンシの場合、以下のようにモデルごとにコンソール上にグラフが描画されます。
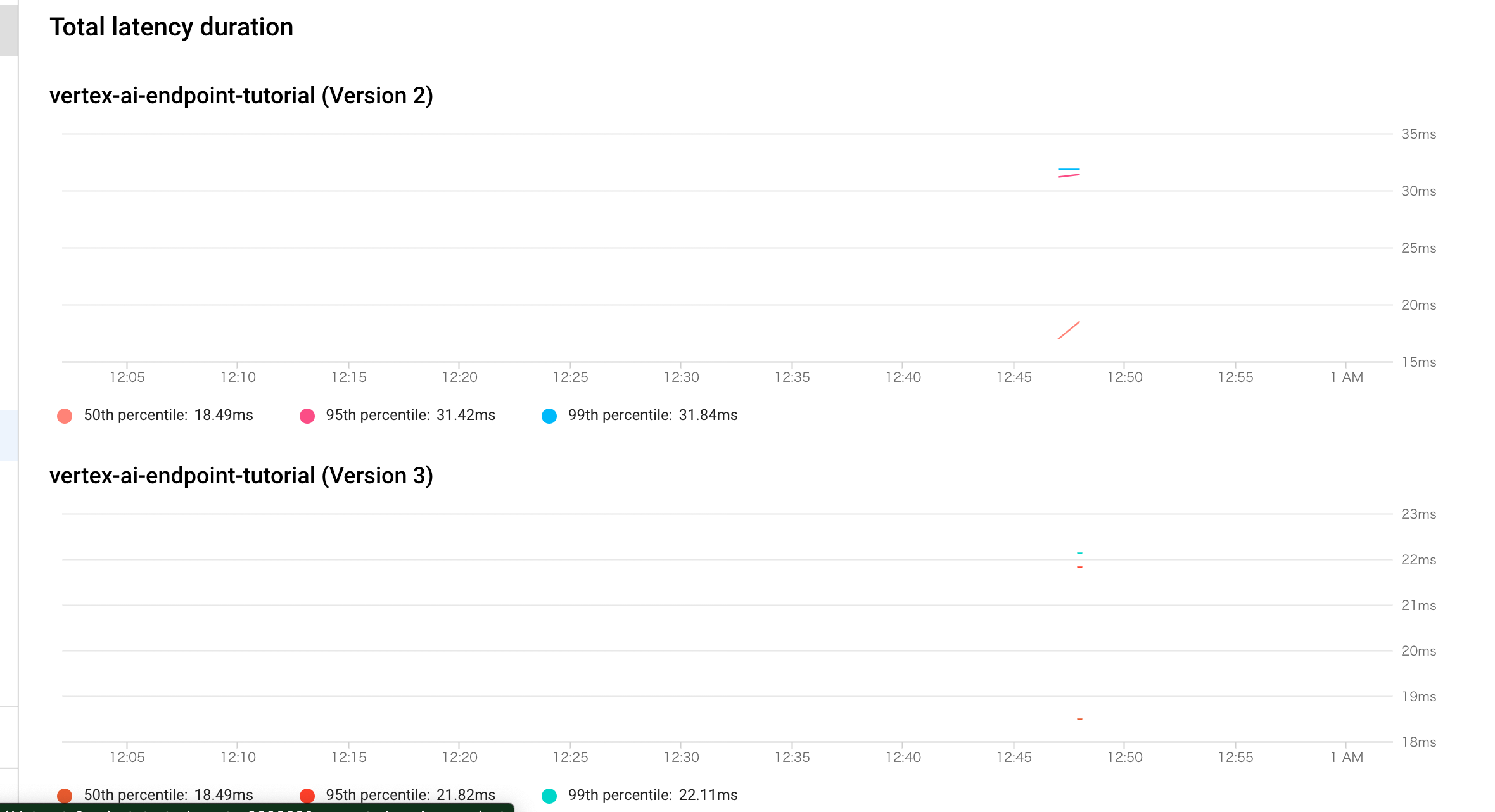
エンドポイントについてCloud Monitoringで確認可能な項目に関する詳細はhttps://cloud.google.com/vertex-ai/docs/general/monitoring-metrics?hl=ja#endpoint_monitoring_metrics を参照してください。
コスト
Vertex AI基本的にノードに割り当てたリソースに対して稼働時間に応じた課金が発生します。(https://cloud.google.com/vertex-ai/pricing)
また、Vertex Explainable AIと関連づけられたノードについては、基本的に予測と同じレートで課金されるものの、処理が増えることが起因して通常の予測よりも時間がかかる分、予測料金が増加する可能性があリマス。
割り当てと上限, SLA
Vertex AIを利用してAPIを構成する場合、1分あたりのオンライン予測リクエストの数に30,000件の上限がある。また、説明リクエストについては1分あたり600件の制限があリマス。(https://cloud.google.com/vertex-ai/docs/quotas?hl=ja#request_quotas)
また、SLAは以下のように定義されています。(https://cloud.google.com/vertex-ai/sla?hl=ja)
| Covered Service | Monthly Uptime Percentage |
|---|---|
| Training, Deployment, and Batch Prediction | >= 99.9% |
| AutoML Tabular and AutoML Image Online Prediction for models deployed on 2 or more nodes | >= 99.9% |
| AutoML Text Language Online Prediction | >= 99.9% |
| Custom Model Online Prediction for models deployed on 2 or more nodes | >= 99.5% |
まとめ
今回は、Vertex AI Endpoints, Vertex AI Model Registryを利用してMLモデルをAPIとしてサービングする方法について調査を行いました。
本番APIとして運用を行うという観点では、GKEやCloud Runと比較して特段サービングが楽になるかと言われるとそこまで大きな恩恵はなさそうという印象ですが、一方でMLモデルをデプロイして継続的に分析・改善を行うという点においては、機能的にGKEやCloud Runと比較して特化しています。
サービングを楽にできるかは微妙なところですが、継続的なモデルの改善については弊チームでもなかなか着手できておらず課題感はあるため、選択肢の一つとしてVertex AIを利用したモデルのサービングも考慮に入れようと思います。