このページは何?
家ではコープデリのウィークリーコープで毎週食材を届けてもらっています。請求書がWebに上がるので、保存しておきたいのですが、毎週同じようにアクセスするのが面倒です。何より忘れてしまう。そこで、Seleniumで自動的に請求書のページのスクリーンショットを撮ることを行ってみました。
...というのも、たまたまGWにPythonでブラウザ自動操縦してカード明細を自動でダウンロードしよう(その1)の記事を発見し、「おお!これは便利そうだ」とやってみたくなったからです。
Seleniumを初めて触りましたが、日本語の解説記事も豊富ですので、悩まずできました。
Webページの理解
5つのステップに分かれていることを確認します。
| Step | Image |
|---|---|
| 1. ログインページでID情報を入力してログイン | 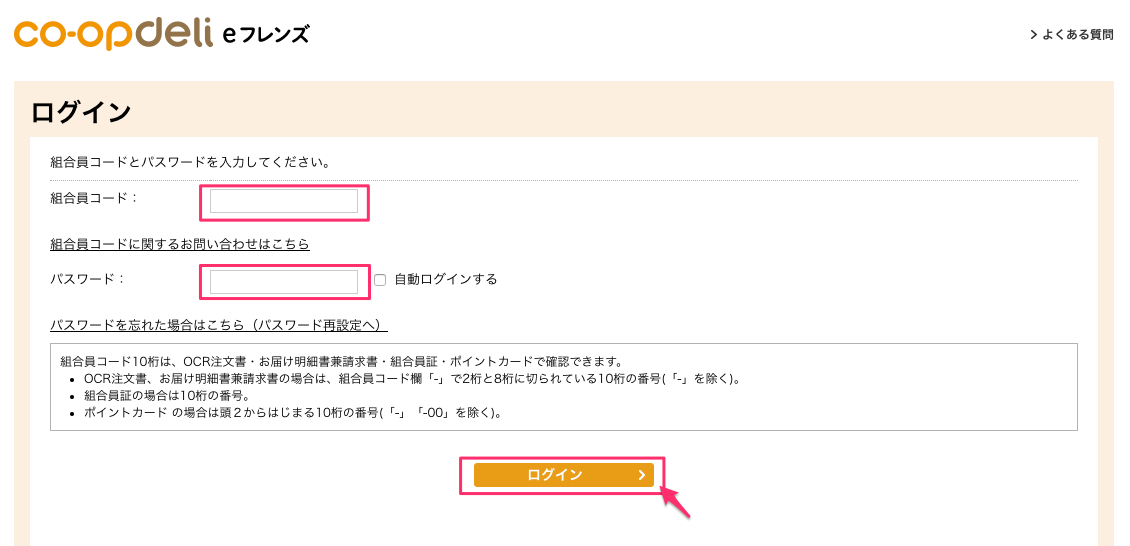 |
| 2. マイページへ移動 | 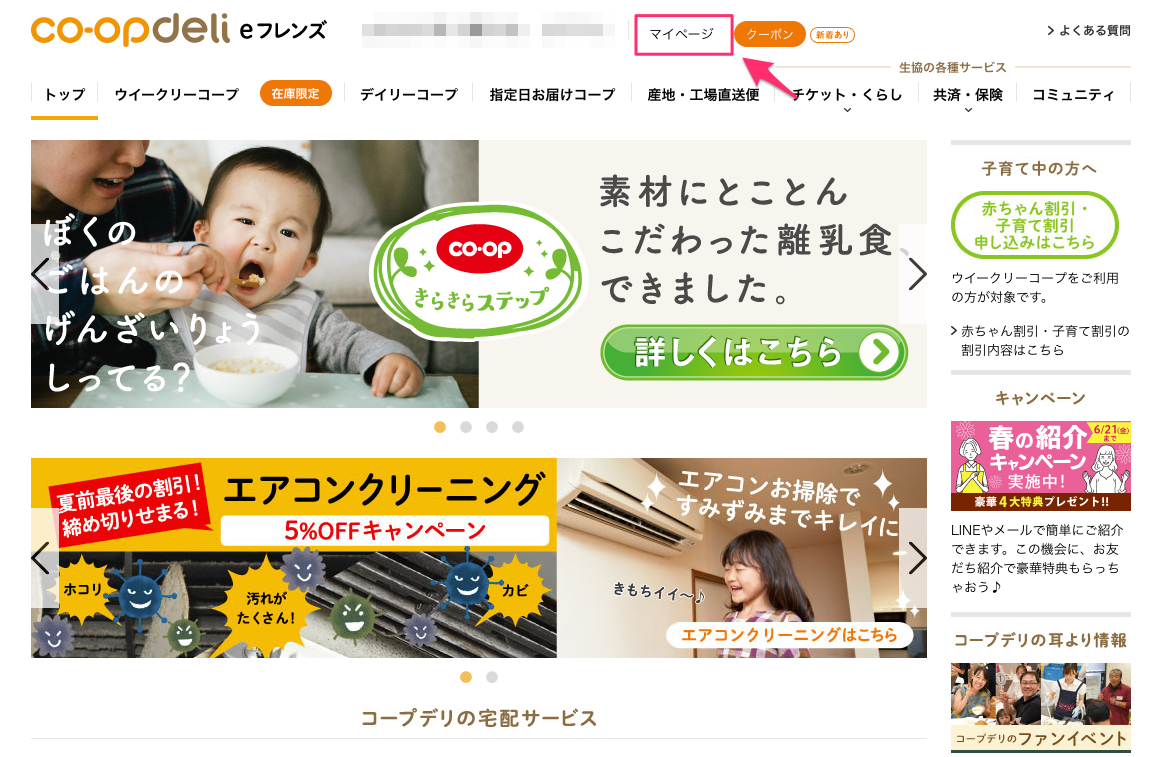 |
| 3. 請求書情報へ移動 | 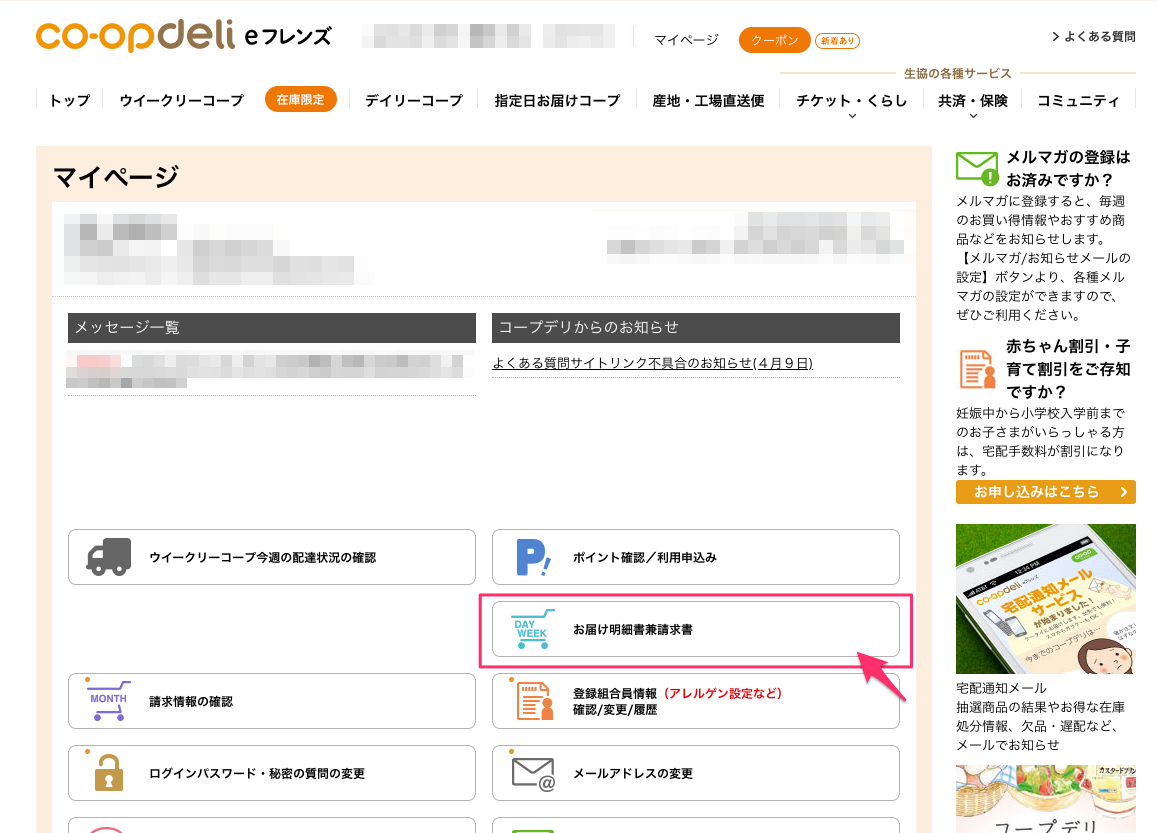 |
| 4. ほしい日付のデータを選択して、表示 | 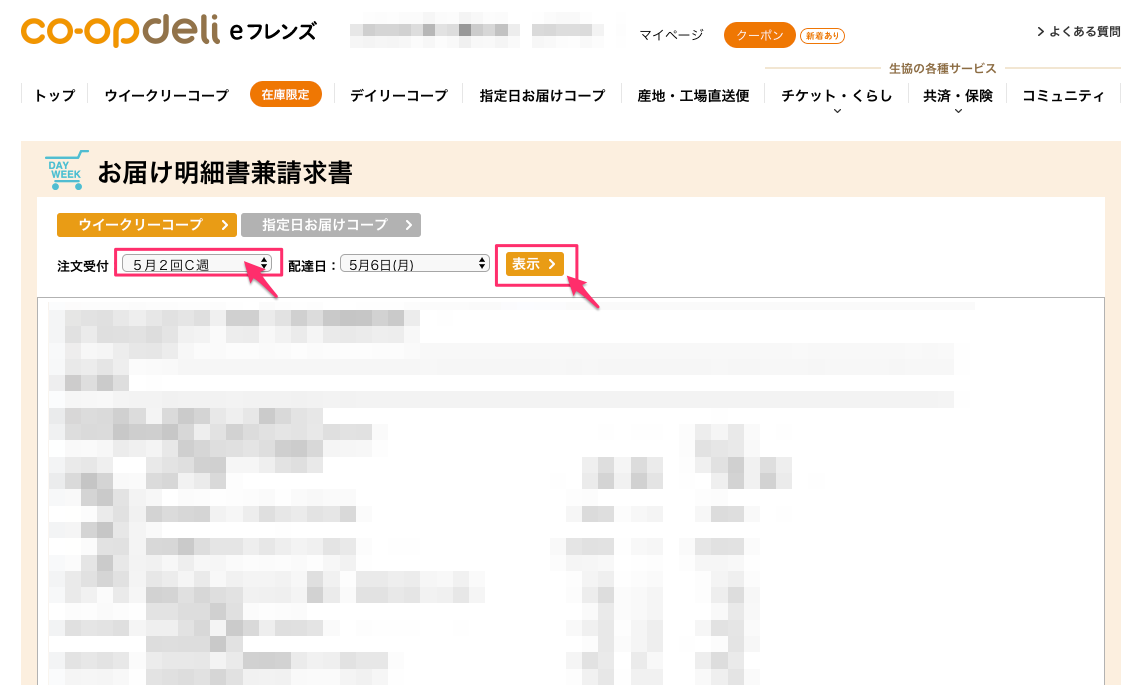 |
| 5. スクリーンショットを撮る | --- |
準備
pythonだと、pipで簡単にインストールできます。注意点として、Chrome Driverを使用する場合、使用しているChromeのバージョンと合わせましょう。現時点ですと、ChromeのVersionが74.X代のものを使用していたので、明示的にそのVersionのChrome Driverをインストールします。
packageのVersionはpypy.orgで探すことができます。
参考 : https://pypi.org/project/chromedriver-binary/#history
$ pip install selenium
$ pip install chromedriver-binary==74.0.3729.6.0
また、chromedriver-binaryのpathを先に調べて、config.iniに記述しておきます。pip show chromedriver-binarなどで検索できます。コープのアカウント情報も合わせて設定しておきましょう。
$ cat config.ini
[selenium]
path = /Users/.../chromedriver_binary/chromedriver
[coop]
user_id = XXX
password = YYY
スクリプト
以下のとおりです。
import time
import configparser
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import Select
# headlessモードを指定
options = Options()
options.add_argument('--headless')
# config.iniからデータを取り出す
inifile = configparser.ConfigParser()
inifile.read('./config.ini', 'UTF-8')
path = inifile.get('selenium', 'path')
user_id = inifile.get('coop', 'user_id')
password = inifile.get('coop', 'password')
# 必要な日付のデータを指定
date = '20190502'
save_path = './'+date+'_meisaisho.png'
# Chromeを起動する
driver = webdriver.Chrome(path, options = options)
# driver = webdriver.Chrome(path)
# コープのログインページを開く
driver.get('https://ec.coopdeli.jp/auth/login.html')
# ページが開くまで待つ
time.sleep(1)
# --------------------
# ステップ1
# --------------------
# 会員ID入力欄にインプット
element_id = driver.find_element_by_name('j_username')
element_id.send_keys(user_id)
# パスワードをインプット
element_pass = driver.find_element_by_name('j_password')
element_pass.send_keys(password)
# ログイン実行
element_pass.submit()
time.sleep(1)
# --------------------
# ステップ2
# --------------------
# "マイページ"をクリック
mypage_link = driver.find_element_by_link_text("マイページ").get_attribute("href")
driver.get(mypage_link)
time.sleep(1)
# --------------------
# ステップ3
# --------------------
# "お届け明細書兼請求書"をクリック
element_meisai = driver.find_element_by_class_name("func01")
meisai_link = element_meisai.find_element_by_tag_name("a").get_attribute("href")
driver.get(meisai_link)
time.sleep(1)
# --------------------
# ステップ4
# --------------------
# ほしい注文受付データを選択
select = Select(driver.find_element_by_id('plc'))
select.select_by_value(date)
time.sleep(1)
# "表示"をクリック
driver.find_element_by_name("WEKPEA0220_NextBtn").click()
time.sleep(1)
# --------------------
# ステップ5
# --------------------
# スクリーンショットを撮る
w = driver.execute_script('return document.body.scrollWidth')
h = driver.execute_script('return document.body.scrollHeight')
driver.set_window_size(w, h)
driver.save_screenshot(save_path)
# 終了
driver.quit()
それぞれのメソッドの解説は参考に載せた記事を読んだほうが理解できるかと思います。Seleniumに入門できたので、他の請求書ダウンロードにも挑戦していこうと思います。
参考
-
Python + Selenium で Chrome の自動操作を一通り
- 必要だった処理をすべてまとめてくれていました。
-
Python: Selenium + Headless Chrome で Web ページ全体のスクリーンショットを撮る
- スクリーンショットの撮り方で参考になりました