過去に https://qiita.com/okitan/items/00b677df1a941a1e0ba0 を書きました。
当時は、DockerもなくCI環境においてブラウザを動かす(それも複数)のはそれなりの苦労があり、PhantomJSを使う選択肢もあるよ(挫折するよりはある程度妥協してCIを実現したほうがいいよ)というのを提示するために書いたものでした。
時はたち、昨日のアドベントカレンダー(https://qiita.com/re-fort/items/7875d317d406e66072e7 )にもあったようにDockerを使って簡単に環境を作ることができるようになってきました。
今回Selenium使い向けにPuppeteerを紹介する意図としては、クロスブラウザテストをやらないんであれば Seleniumを使わない選択肢もあるよというのを提示できればと思っています。
Puppeteerとは
PuppeteerはChrome Devtools Protocolを利用して、ブラウザの情報を取得したり、操作したりするためのライブラリです。
よく、ヘッドレスChromeをあやつるためのライブラリとかって紹介されていますが、当然ヘッドありでもあやつれますし(開発時は当然そちらの方が簡単ですよね)、デフォルトでは Google Chrome ではなく、Puppeteerインストール時にダウンロードしてきたChrominumが使われます。
なお、 pupetter とかって typo しやすいので注意してください。pとeを重ねます(慣れるまで大変です)
ChromeDriver との違い
SeleniumでGoogle Chromeを動かす時に必要になるChromeDriverも同様にDevtools Protocolを利用しています。なので、ChromeDriverもPuppeteerと同等のことができるのですが、Seleniumはユーザがブラウザ操作時に体験できるものだけをインターフェースとして提供するというポリシーがありますし(なので、例えばWebページのステータスコードを取得するようなインターフェイスとかないですし)、また、クロスブラウザを考えたときに、Google Chromeだけで有効な機能とかはあまり機能としてサポートされていなかったりします。
Puppeteerの簡単な試し方
Try Puppeteerというサイトがあります。
まずは、ここにアクセスしてどういうふうにコードを書いてそれがどういう動きになるかを確認してみましょう。左側にコードエディタがあり、example.comにアクセスしてスクリーンショットを取るコードがデフォルトで表示され、Run Itというボタンを押すと右側にconsole.logで出力したログと、スクリーンショットが表示されるようになってます。
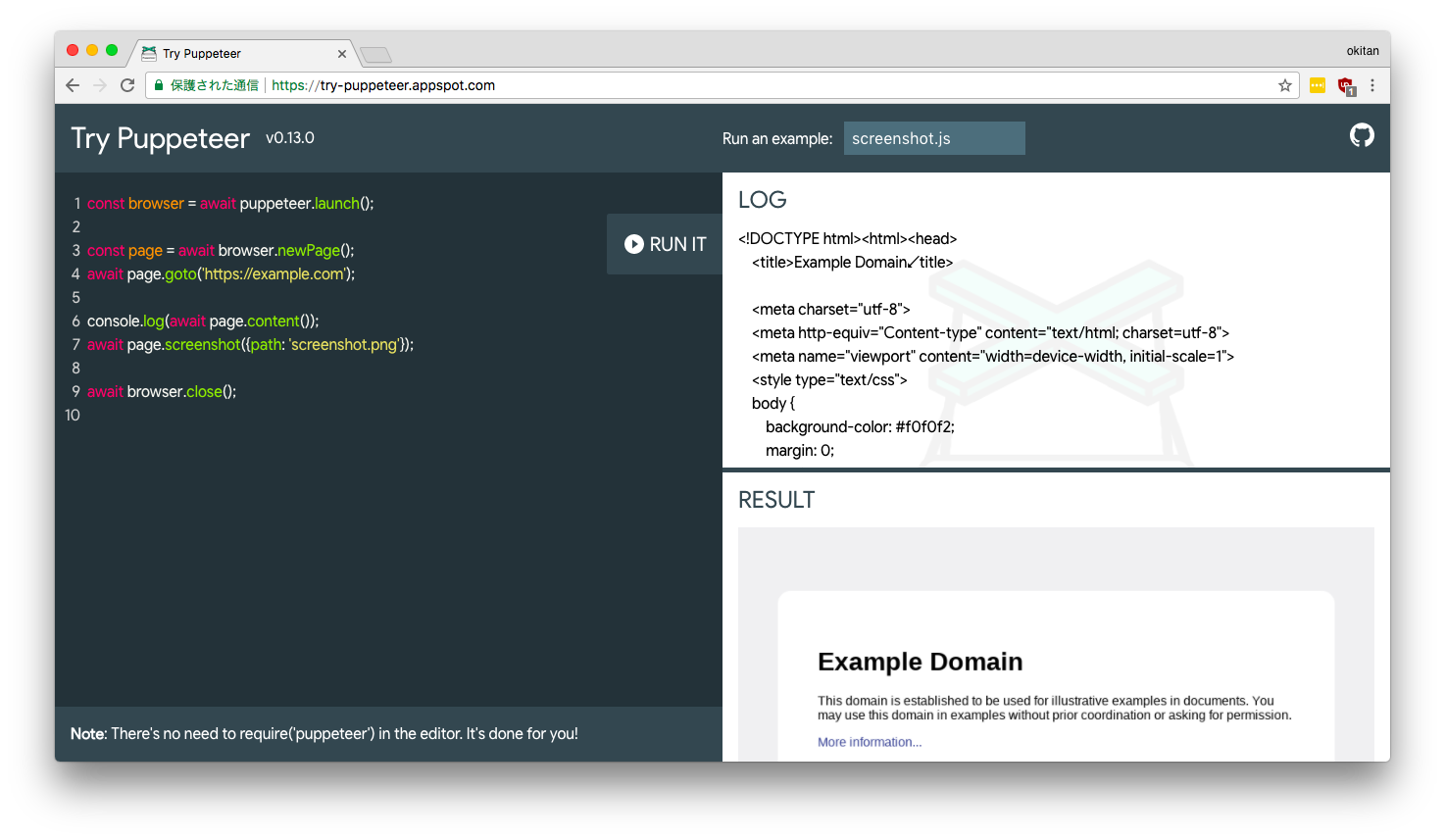
はい。めちゃめちゃ簡単に試せますね。
もちろんコードを書き換えるとその通りに結果も変わります。
Puppeteerをインストールしてみる
PuppeteerはSeleniumとちがいChromeDriverのような追加で必要なアプリはありません。またPuppeteerがデフォルトで使うようになっているChromiumはnpmでのインストール時に自動的にダウンロードされるので、Puppetterをインストールするだけで基本的には準備が整います。簡単ですね。
またそのため、よくあるGoogle Chromeだけオートアップデートでバージョンがあがってしまい、ChromeDriverが古くなっていてテスト動きませんあるあるとかが起こりません。
$ npm install puppeteer
> puppeteer@0.13.0 install /Users/okita.kunio/tmp/puppeteer/node_modules/puppeteer
> node install.js
Downloading Chromium r515411 - 73.2 Mb [====================] 100% 0.0s
(...emit...)
なお、以降はOSXと最新のNode.jsで試しています。Windows環境等では一部コマンドが異なる可能性がありますので、適宜よみかえてください
Try Puppeteerのサンプルコードを手元で動かしてみる。
Try Puppeteerにあるサンプルコードを手元で動かすためには、以下のようにするとよいです。
標準出力にログが出力され、screenshot.pngが保存されていることがわかります。
const puppeteer = require("puppeteer");
(async () => {
// この中に Try Puppeteer からのコードを貼り付ける
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
console.log(await page.content());
await page.screenshot({path: 'screenshot.png'});
await browser.close();
})();
$ node tryPuppeteer.js
<!DOCTYPE html><html><head>
(...emit...)
$ open screenshot.png # screenshot.png を開く
headありで動かす
手元で動かす場合には、ブラウザの挙動をみれた方がdebugが簡単です。それには、{ headless: false } というオプションをつけてlaunchするとよいです。
const browser = await puppeteer.launch({ headless: false });
headありで動かすとOSXのDockに青いChromiumのアイコンが表示されます。
Google Chromeを動かす
注意点
PuppeteerでGoogle Chromeを動かす場合に注意してほしいのは、0.13.0(現在の最新)で Google Chrome を動かす場合、64.0.3265.0 以降のGoogle Chromeじゃないと動きません。今の記事を書いている時点で、Google Chromeは63系なので、Beta版以降を使うか、Puppeteer 0.12.0にダウングレードする必要があります。
(詳しくは https://github.com/GoogleChrome/puppeteer/issues/1507 に書いてあります。)
OSXでのさらなる注意点
OSXではGoogle ChromeとGoogle Chrome BetaやGoogle Chrome開発版は同一マシンにインストールすることができません(WindowsやLinuxでは共存可能です)。
したがって、OSXでPuppeteer 0.13.0を使ってGoogle Chromeを動かす場合は、Google Chrome Canaryが必要になります。
なお、Google Chrome Canaryはテストなしでリリースされているもので、普通に動かなかったりするやつなので、注意が必要です(この記事書いているときには幸いにも動いてくれました)
Google Chrome Canaryをインストールするには、OSXだと以下の方法でできます。
$ brew cask install caskroom/versions/google-chrome-canary
Google Chromeを動かす
スクレイピング等に利用するなら不要でしょうが、テストに利用するのであればなるべくユーザの利用しているブラウザに近いものを使いたいですよね。launch時に同様にexecutablePathというオプションをつけるとよいです。
const browser = await puppeteer.launch({ executablePath: "/path/to/chrome", headless: false });
なお、OSXでGoogle Chrome Canaryを動かす場合、/path/to/chromeは、/Applications/Google Chrome Canary.app/Contents/MacOS/Google Chrome Canaryとなります。
Puppeteer 0.13.0での変更点
先程も触れましたが、Puppeteer 0.13.0において、Google Chromeを利用するには、64.0.3265.0以降のバージョンが必要になるとのことです。
先程の解説ではGoogle Chrome Canaryを使ってまで説明をしていたのですが、0.12.xで説明せずにわざわざ0.13.0で説明したのは理由があります。
多分Puppeteerがバズった当初に触ってみたSeleniumユーザの方は気づかれたと思うのですが、Elementからさらに子要素を取ることが0.13.0になるまでできませんでした。これはどういうことかというと、例えばある要素に対する子要素をまとめて管理する等(例えばformとそのinputのような親子関係の場合)が難しかったということです。
したがって、Page ObjectパターンだとかScreen Playパターンだとか、Seleniumを上手に書くためのデザインパターンがそのままでは適用しづらい状況になっていました。
しかし、ようやくPuppeteer 0.13.0でelementHandler.$だとかelementHandler.$$だとかが実装され、Seleniumで普通に使えた機能がだいたい出揃ってきました。
Before Afterの例を書きます。両者とも、tableの中のkeyとvalueのセルの組み合わせの一覧を取ってきます。
Before
Beforeは"table tr"というcssセレクタで取ってきたtr達に対して、td.keyとかtd.valueの子要素を見つけることがPuppeteerでできないため、ブラウザのコンテキストにおいてevalをかけてます。。なんという力技。。
trList => {}というFunctionはブラウザ上で評価されるため、ここにNode.jsで保存している変数とかは当然利用できません。
つまり、td.keyとかはべた書きしないといけないということです。。。
これでは、evalごとに何度も同じことを書かないといけなくなり、共通化が難しくなります。
page.$$eval("table tr", trList => {
return trList.map(tr => {
return {
key: tr.querySelector("td.key").innerText.trim(),
value: tr.querySelector("td.value").innerText.trim()
};
};
}); //#=> [ { key: "key1", value: "value2" }, ... ]
After
After においては await 地獄感ありますが、Puppeteerに対する操作のみで実現できています。
const trList = await page.$$("table tr");
await Promise.all(trList.map(async tr => {
return {
key: (await (await (await tr.$("td.key")).getProperty("innerText")).jsonValue()).trim(),
value: (await (await (await tr.$("td.value")).getProperty("innerText")).jsonValue()).trim(),
}
}); //#=> [ { key: "key1", value: "value2" }, ... ]
まとめ
Puppeteerは次期バージョンが1.0.0らしいのですが、機能もほぼほぼ揃ってきてSeleniumと同等のことができるようになってきました。
ようやくPuppeteerでも利用できるPage Objectパターンのライブラリも出だしてきた印象で、Puppeteerを使ったメンテナブルなテストの土台が整ってきたといえます。
現在のWebアプリケーションの開発スタックにおいてはjavascriptは当然不可欠なものになっています。寿命の長いUIテストの条件のひとつに開発者の巻き込みとそのためにプロダクトで使っている言語を利用するものがあり、Node.jsを使ってテストを書くことは今後増えて行くと思います。その中でテストの狙いにもよるのですが、クロスブラウザテストを行わないような場合にSeleniumではなくPuppeteerを検討するというのはどうでしょうか?
明日のアドベントカレンダーはまだ予定が決まっていないところにこういう記事ですがw誰かつなげてくださいよろしくおねがいします!