はじめに
新型コロナウイルス感染症(COVID-19)に関連して、2020年3月19日、専門家会議による状況分析と提言が出されました。その中で、実効再生産数(感染症の流行が進行中の集団のある時刻における、1人の感染者が生み出した二次感染者数の平均値)に関する分析結果が示されています。北海道では2月中旬からおおむね1を下回る値となっており、収束に向かっているとの見解でした。
先日書いた記事では、単純化したモデルで計算した結果を示しましたが、その時の分析結果でも、おおむね1を下回る点で一致しており、答え合わせが出来たのではないかと思います。ただし、北海道大学の西浦先生の分析では、最尤推定を使ったより精密な分析のようです。恐らく、こちらの論文で示されているように、効果的再生産数(Effectivereproduction number,Rt):「(ある時刻tにおける,一定の対策下での)1人の感染者による2次感染者数」という意味ではないかと思われます。基本再生産数R0といっても、社会や政策と切り離して評価することは困難と思われますので、今回の記事のタイトルは敢えて、効果的再生産数としました。
さて、今回の記事は、都道府県別の再生産数のある期間における平均値のランキングを出したいと思います。先日の専門家会議では、**1.感染状況が拡大傾向にある地域、2.感染状況が収束に向かい始めている地域並びに一定程度に収まってきている地域、3.感染状況が確認されていない地域、**の3つの地域に分けて、バランス良く対応を行うことが提言されましたが、どの地域が特に1に該当するのか、明言されませんでした。なので、具体的に都道府県別の再生産数を計算してランキングしてしまいたい、というのが本記事の主な動機です。
前提
基本的な計算式は、前回の記事の内容と同一です。パラメータも変えていません。また、前回記事と同様、都道府県別新型コロナウイルス感染者数マップ(ジャッグジャパン株式会社提供)において、公開されているcsvデータを使わせて頂きました。
潜伏期間や感染期間を経て、検査陽性が判明するというタイムラグがあるため、直近2週間以前の結果は出ていません。
また、matplotlibで日本語が使えるように、こちらのページを参考にして、IPAexGothicフォントをインストールしています。
Pythonで計算してみる
今回のコードは、GitHubで公開しています。Jupyter Notebook形式で保存してあります。(ファイル名:03_R0_estimation-JPN-02a.ipynb)
- [GitHub: okimebarun /
01_COVID19_analysis ] (https://github.com/okimebarun/01_COVID19_analysis)
コード
長くなるので、コードの全ては記事では記載しませんが、ランキングを作る上でポイントとなる部分を説明します。
図で日本語フォントを使えるようにするおまじないです(フォントの事前インストールが必要です)。
font = {'family' : 'IPAexGothic'}
plt.rc('font', **font)
都道府県名を抽出する関数です。重複する値を削除するため、duplicated()関数を使ってます。
def getJapanPrefList():
# 下記URLよりダウンロード
# https://jag-japan.com/covid19map-readme/
fcsv = u'COVID-19.csv'
df = pd.read_csv(fcsv, header=0, encoding='utf8', parse_dates=[u'確定日YYYYMMDD'])
# 確定日, 受診都道府県のみ抽出
df1 = df.loc[:,[u'受診都道府県']]
df1.columns = ['pref']
df1 = df1[~df1.duplicated()]
preflist = [e[0] for e in df1.values.tolist()]
return preflist
preflist = getJapanPrefList()
都道府県リストに対して、グラフとデータフレームを作る部分です。
def R0inJapanPref2(pref):
keys = {'lp':5, 'ip':8 }
df1 = makeCalcFrame(60) # 60 days
df2 = readCsvOfJapanPref(pref)
df = mergeCalcFrame(df1, df2)
df = calcR0(df, keys)
showResult(df, u'COVID-19 R0 ({})'.format(pref))
return df
dflist = [ [R0inJapanPref2(pref), pref] for pref in preflist]
ある指定した期間での、基本再生産数R0の平均を求める関数です。空白になる場合への対処をしています。
def calcR0Average(df, st, ed):
df1 = df[(st <= df.date) & (df.date <= ed) ]
df2 = df1[np.isnan(df1.R0) == False]
df3 = df2['R0']
ave = np.average(df3) if len(df3) > 0 else 0
return ave
ランキングのためにソートする関数です。
def calcR0AveRank(dflist, st, ed):
R0AveRank = [ [pref, calcR0Average(df, st, ed)] for df, pref in dflist]
R0AveRank.sort(key = lambda x: x[1], reverse=True)
df = pd.DataFrame(R0AveRank)
df.columns = ['pref','R0ave']
return df
ランキングを棒グラフで表示する関数です。X軸を上に持っていくためにset_position関数を使ってます。
def showRank(dflist, maxn, title):
ax = dflist.iloc[0:maxn,:].plot.barh(y='R0ave',x='pref',figsize=(8,10))
ax.invert_yaxis()
ax.grid(True, axis='x')
ax.spines['bottom'].set_position(('axes',1.05))
plt.title(title, y=1.05)
plt.show()
return ax
最後に、ランキングを計算する部分です。
# 2020/2/7 から 2020/3/7
st = pd.Timestamp(2020,2,7)
ed = pd.Timestamp(2020,3,7)
title = "R0ave_ranking_2020207_20200307"
dfR0_1 = calcR0AveRank(dflist, st, ed)
ax = showRank(dfR0_1, 13, title)
fig = ax.get_figure()
fig.savefig("{}.jpg".format(title))
# 2020/2/23 から 2020/3/7
st = pd.Timestamp(2020,2,23)
ed = pd.Timestamp(2020,3,7)
title = "R0ave_ranking_2020223_20200307"
dfR0_1 = calcR0AveRank(dflist, st, ed)
ax = showRank(dfR0_1, 13, title)
fig = ax.get_figure()
fig.savefig("{}.jpg".format(title))
# 2020/3/1 から 2020/3/7
st = pd.Timestamp(2020,3,1)
ed = pd.Timestamp(2020,3,7)
title = "R0ave_ranking_2020301_20200307"
dfR0_2 = calcR0AveRank(dflist, st, ed)
ax = showRank(dfR0_2, 13, title)
fig = ax.get_figure()
fig.savefig("{}.jpg".format(title))
ランキング結果
それでは、いよいよ計算結果を見てみましょう。$R_0 > 1$であれば感染拡大傾向、$R_0 < 1$であれば感染収束傾向、と言えるでしょう。直近の1か月分、2週間分、1週間分と見ていきます。
2020/2/7 から 2020/3/7まで(直近1か月分)のランキング
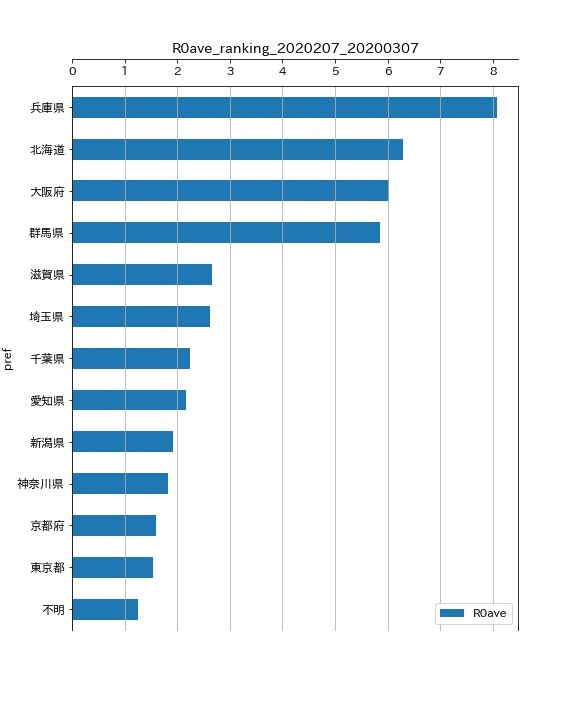
- 兵庫県がトップとなりました。報道されているように、デイケア施設、こども園、病院という複数の箇所で同時にクラスターが発生したためと思われます。
- 続いて、北海道ですが、これはさっぽろ雪まつりの期間(2月4日~2月11日)の期間を含んでいるためと思われます。
- 3位は大阪府です。これも、報道されているようにライブハウスでのクラスター(2月15日~2月24日)を含んでいるためと思われます。1位の兵庫県と3位の大阪府が隣接しているため、往来によってクラスター連鎖が起きることが懸念されます。
2020/2/23 から 2020/3/7まで(直近2週間分)のランキング
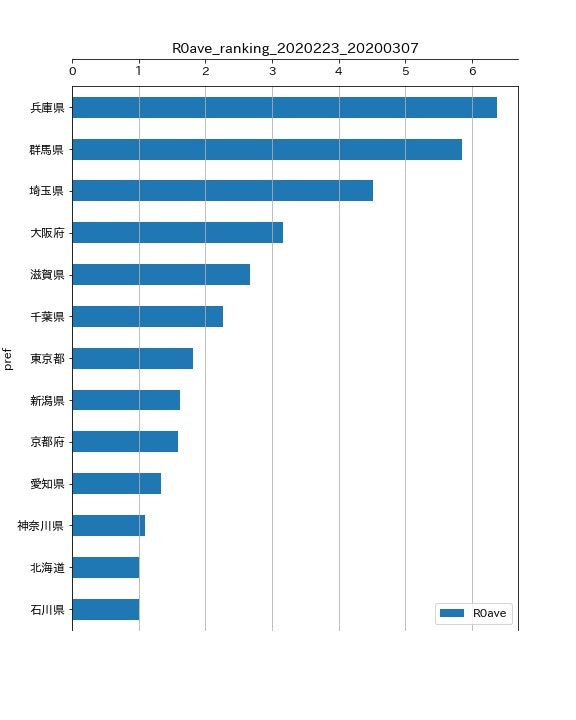
- 兵庫県がトップとなりました。理由は先ほどと同じでしょう。
- 意外ですが、群馬県が2位になりました。これは、最近感染者数が増えだすと、高めに出る傾向があるからだと思われます。3月20日現在、群馬県の感染者数は11名ですが、県内の診療所でクラスターが発生しているとの報道があるようです。
- 3位は埼玉県です。埼玉県のページを見ると、概ね感染者の経路は追えているようです。3月20日現在、埼玉県の感染者数は44名です。
2020/3/1 から 2020/3/7まで(直近1週間分)のランキング
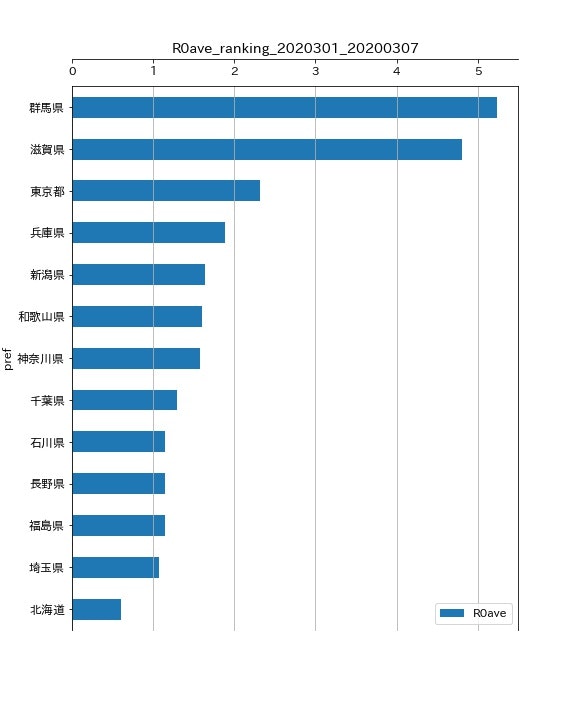
- 群馬県がトップとなりました。理由は先ほどと同じでしょう。
- 続いて、滋賀県です。3月20日現在、滋賀県の感染者数は4名ですので、ごく最近の発生事例のためと思われます。
- 3位は東京都です。直近1か月で見ると1.5くらいなのですが、直近1週間では2.2くらいと、地味に増加傾向にあることが気になります。外務省による渡航制限(中国、韓国、EU、全世界)が強化されて来たことによる、帰国者の増加の影響もあると思われます。
考察
- 感染者が増加傾向($R_0 > 1 $)となる都道府県は、直近1か月では13、直近2週間では11、直近1週間では12、となっており大体13都道府県が該当するようです。
- $R_0 > 4$となるトップ集団、$1 < R_0 < 3$の中堅集団、といった傾向があるようです。
- 隣接する大都市圏で、$R_0 > 1$となる都道府県があり、特に、兵庫-大阪-滋賀、神奈川-東京-埼玉-千葉-群馬、のリンクに注意が必要です。
さらに言えば・・・
- 西浦先生のように、帰国者と居住者を分けて分析した方がいいかもしれません。
- $R_0$を算術平均することに少し疑問を感じるので、もう少し計算方法に工夫が必要かもしれません。幾何平均だと0になる場合があるので算術平均で妥協しました。
- COVID-19(SARS-CoV-2)の特徴として、潜伏期間や感染期間が長いことがありますが、そのため陽性検出までにタイムラグがあり、モグラ叩きのような対策が継続して疲弊してしまうことが懸念されます。
- $R_0$が高い地域のランキングに基づいて、クラスター警戒対策を強化して、自粛要請やリソースの集中投入をした方が効率的ではないでしょうか。
参考リンク
下記のページを参考にさせて頂きました。