みなさんはずんだもんをご存知でしょうか?最近だとずんだもんの解説動画なんかが流行ってますよね。
自分もたまにYouTubeで見てしまうんですが、自分もずんだもんになりたい!と思ったので今回のwebアプリを作成してみました。
今回は生成AIを活用して開発してみたので、その辺りの参考ソースも載せていきたいと思います
2025/02/16 追記
VOICEVOXを完全にVOICEBOXにtypoしていました。適宜読み替えてください
実装方針について
音声認識にあたってWhisperやGoogleのSpeech-to-Text等ありましたが、今回はサクッとお試し的に作成したかったのでWeb Speech APIを利用してみました。今後は音声AIモデルも利用してみたいです
使い方
使い方や実際のデモ動画はGitHubの方に上がっているのでそちらの方を見ていただけると
生成AIを使っての開発
サンプルコードも含めると長いので読み流していただいて大丈夫です
基本はこれらのコードを参考に実装しました。
とりあえずサンプルソースをAIに作ってもらった
ChatGPT(GPT-4o)
web Speech API とVOICEVOXを連携する方法を教えてください
必要なもの
VOICEVOXのインストール
- VOICEVOXエンジンを公式サイトからダウンロードし、ローカルで動作するように設定します。
エンジンが起動していることを確認します(通常はhttp://127.0.0.1:50021で稼働します)。 - ブラウザがWeb Speech APIをサポートしているか確認
Web Speech APIをサポートしているブラウザ(例:Google Chrome)を使用します。 - 開発環境
Webアプリケーションを開発するためのHTML、JavaScript、または任意のフレームワーク。
- Web Speech APIを使って音声入力を取得
以下のコードは、音声認識を有効にするサンプルです。
const recognition = new (window.SpeechRecognition || window.webkitSpeechRecognition)();
recognition.lang = 'ja-JP'; // 日本語を設定
recognition.interimResults = false;
recognition.onresult = (event) => {
const transcript = event.results[0][0].transcript;
console.log(`認識結果: ${transcript}`);
sendToVoicevox(transcript); // 認識結果をVOICEVOXに送信
};
recognition.onerror = (event) => {
console.error(`エラー: ${event.error}`);
};
function startRecognition() {
recognition.start();
}
- VOICEVOXエンジンにテキストを送信して音声合成を行う
VOICEVOXエンジンのHTTP APIを使用して、認識したテキストを音声合成します。
async function sendToVoicevox(text) {
const speakerId = 1; // 話者ID(VOICEVOXで利用可能な話者を選択)
try {
// 音声クエリを生成
const queryResponse = await fetch(`http://127.0.0.1:50021/audio_query?speaker=${speakerId}&text=${encodeURIComponent(text)}`, {
method: 'POST',
});
const audioQuery = await queryResponse.json();
// 音声合成
const synthesisResponse = await fetch(`http://127.0.0.1:50021/synthesis?speaker=${speakerId}`, {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(audioQuery),
});
const audioBlob = await synthesisResponse.blob();
// 音声を再生
const audioUrl = URL.createObjectURL(audioBlob);
const audio = new Audio(audioUrl);
audio.play();
} catch (error) {
console.error('VOICEVOXエラー:', error);
}
}
- HTMLで動作を確認
以下のHTMLを使って、動作確認ができます。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Web Speech APIとVOICEVOX連携</title>
</head>
<body>
<button onclick="startRecognition()">音声入力を開始</button>
<script src="app.js"></script>
</body>
</html>
Claude(3.5 Sonnet)
次の仕様でWeb Speech APIとVOICEBOXを連携したwebアプリを作成してください
仕様する言語、ツールは
・Vite
・React
・tailwind
・TypeScript
機能は
・VOICEBOXのスピーカー一覧を取得して表示する
・音声入力のデバイス選択
・音声出力のデバイス選択
・音声入力開始ボタン
・音声入力終了ボタン
// src/types/types.ts
interface Speaker {
id: number;
name: string;
}
interface AudioDevice {
deviceId: string;
label: string;
}
// src/App.tsx
import { useState, useEffect } from 'react';
import SpeakerList from './components/SpeakerList';
import DeviceSelector from './components/DeviceSelector';
import SpeechControls from './components/SpeechControls';
const App = () => {
const [speakers, setSpeakers] = useState<Speaker[]>([]);
const [inputDevices, setInputDevices] = useState<AudioDevice[]>([]);
const [outputDevices, setOutputDevices] = useState<AudioDevice[]>([]);
const [selectedInputDevice, setSelectedInputDevice] = useState<string>('');
const [selectedOutputDevice, setSelectedOutputDevice] = useState<string>('');
const [isRecording, setIsRecording] = useState(false);
useEffect(() => {
// VOICEBOXのスピーカー一覧を取得
const fetchSpeakers = async () => {
try {
const response = await fetch('http://localhost:50021/speakers');
const data = await response.json();
setSpeakers(data);
} catch (error) {
console.error('Failed to fetch speakers:', error);
}
};
// オーディオデバイスの一覧を取得
const getAudioDevices = async () => {
try {
const devices = await navigator.mediaDevices.enumerateDevices();
const inputs = devices.filter(device => device.kind === 'audioinput');
const outputs = devices.filter(device => device.kind === 'audiooutput');
setInputDevices(inputs.map(device => ({
deviceId: device.deviceId,
label: device.label || `Microphone ${device.deviceId}`
})));
setOutputDevices(outputs.map(device => ({
deviceId: device.deviceId,
label: device.label || `Speaker ${device.deviceId}`
})));
} catch (error) {
console.error('Failed to get audio devices:', error);
}
};
fetchSpeakers();
getAudioDevices();
}, []);
return (
<div className="min-h-screen bg-gray-100 p-8">
<div className="max-w-4xl mx-auto bg-white rounded-lg shadow-md p-6">
<h1 className="text-2xl font-bold mb-6">VOICEBOX Speech App</h1>
<div className="space-y-6">
<SpeakerList speakers={speakers} />
<div className="grid grid-cols-1 md:grid-cols-2 gap-4">
<DeviceSelector
label="入力デバイス"
devices={inputDevices}
selectedDevice={selectedInputDevice}
onSelect={setSelectedInputDevice}
/>
<DeviceSelector
label="出力デバイス"
devices={outputDevices}
selectedDevice={selectedOutputDevice}
onSelect={setSelectedOutputDevice}
/>
</div>
<SpeechControls
isRecording={isRecording}
onStartRecording={() => setIsRecording(true)}
onStopRecording={() => setIsRecording(false)}
selectedInputDevice={selectedInputDevice}
/>
</div>
</div>
</div>
);
};
export default App;
// src/components/SpeakerList.tsx
interface SpeakerListProps {
speakers: Speaker[];
}
const SpeakerList = ({ speakers }: SpeakerListProps) => {
return (
<div className="mb-6">
<h2 className="text-xl font-semibold mb-3">スピーカー一覧</h2>
<div className="grid grid-cols-2 md:grid-cols-3 gap-4">
{speakers.map((speaker) => (
<div
key={speaker.id}
className="p-3 bg-gray-50 rounded-md border border-gray-200"
>
{speaker.name}
</div>
))}
</div>
</div>
);
};
export default SpeakerList;
// src/components/DeviceSelector.tsx
interface DeviceSelectorProps {
label: string;
devices: AudioDevice[];
selectedDevice: string;
onSelect: (deviceId: string) => void;
}
const DeviceSelector = ({
label,
devices,
selectedDevice,
onSelect,
}: DeviceSelectorProps) => {
return (
<div className="flex flex-col space-y-2">
<label className="font-medium">{label}</label>
<select
value={selectedDevice}
onChange={(e) => onSelect(e.target.value)}
className="p-2 border border-gray-300 rounded-md focus:ring-2 focus:ring-blue-500 focus:border-blue-500"
>
<option value="">デバイスを選択してください</option>
{devices.map((device) => (
<option key={device.deviceId} value={device.deviceId}>
{device.label}
</option>
))}
</select>
</div>
);
};
export default DeviceSelector;
// src/components/SpeechControls.tsx
interface SpeechControlsProps {
isRecording: boolean;
onStartRecording: () => void;
onStopRecording: () => void;
selectedInputDevice: string;
}
const SpeechControls = ({
isRecording,
onStartRecording,
onStopRecording,
selectedInputDevice,
}: SpeechControlsProps) => {
const handleStartRecording = () => {
if (!selectedInputDevice) {
alert('入力デバイスを選択してください');
return;
}
onStartRecording();
};
return (
<div className="flex space-x-4">
<button
onClick={handleStartRecording}
disabled={isRecording}
className={`px-4 py-2 rounded-md ${
isRecording
? 'bg-gray-400 cursor-not-allowed'
: 'bg-blue-500 hover:bg-blue-600'
} text-white font-medium`}
>
録音開始
</button>
<button
onClick={onStopRecording}
disabled={!isRecording}
className={`px-4 py-2 rounded-md ${
!isRecording
? 'bg-gray-400 cursor-not-allowed'
: 'bg-red-500 hover:bg-red-600'
} text-white font-medium`}
>
録音停止
</button>
</div>
);
};
export default SpeechControls;
音声認識結果の表示機能を追加して
// src/types/types.ts
interface Speaker {
id: number;
name: string;
}
interface AudioDevice {
deviceId: string;
label: string;
}
// src/App.tsx
import { useState, useEffect } from 'react';
import SpeakerList from './components/SpeakerList';
import DeviceSelector from './components/DeviceSelector';
import SpeechControls from './components/SpeechControls';
import RecognitionResult from './components/RecognitionResult';
const App = () => {
const [speakers, setSpeakers] = useState<Speaker[]>([]);
const [inputDevices, setInputDevices] = useState<AudioDevice[]>([]);
const [outputDevices, setOutputDevices] = useState<AudioDevice[]>([]);
const [selectedInputDevice, setSelectedInputDevice] = useState<string>('');
const [selectedOutputDevice, setSelectedOutputDevice] = useState<string>('');
const [isRecording, setIsRecording] = useState(false);
const [recognitionResult, setRecognitionResult] = useState<string>('');
useEffect(() => {
// VOICEBOXのスピーカー一覧を取得
const fetchSpeakers = async () => {
try {
const response = await fetch('http://localhost:50021/speakers');
const data = await response.json();
setSpeakers(data);
} catch (error) {
console.error('Failed to fetch speakers:', error);
}
};
// オーディオデバイスの一覧を取得
const getAudioDevices = async () => {
try {
const devices = await navigator.mediaDevices.enumerateDevices();
const inputs = devices.filter(device => device.kind === 'audioinput');
const outputs = devices.filter(device => device.kind === 'audiooutput');
setInputDevices(inputs.map(device => ({
deviceId: device.deviceId,
label: device.label || `Microphone ${device.deviceId}`
})));
setOutputDevices(outputs.map(device => ({
deviceId: device.deviceId,
label: device.label || `Speaker ${device.deviceId}`
})));
} catch (error) {
console.error('Failed to get audio devices:', error);
}
};
fetchSpeakers();
getAudioDevices();
}, []);
return (
<div className="min-h-screen bg-gray-100 p-8">
<div className="max-w-4xl mx-auto bg-white rounded-lg shadow-md p-6">
<h1 className="text-2xl font-bold mb-6">VOICEBOX Speech App</h1>
<div className="space-y-6">
<SpeakerList speakers={speakers} />
<div className="grid grid-cols-1 md:grid-cols-2 gap-4">
<DeviceSelector
label="入力デバイス"
devices={inputDevices}
selectedDevice={selectedInputDevice}
onSelect={setSelectedInputDevice}
/>
<DeviceSelector
label="出力デバイス"
devices={outputDevices}
selectedDevice={selectedOutputDevice}
onSelect={setSelectedOutputDevice}
/>
</div>
<SpeechControls
isRecording={isRecording}
onStartRecording={() => setIsRecording(true)}
onStopRecording={() => setIsRecording(false)}
selectedInputDevice={selectedInputDevice}
onRecognitionResult={setRecognitionResult}
/>
<RecognitionResult text={recognitionResult} />
</div>
</div>
</div>
);
};
export default App;
// Previous components remain the same...
// Update SpeechControls.tsx
interface SpeechControlsProps {
isRecording: boolean;
onStartRecording: () => void;
onStopRecording: () => void;
selectedInputDevice: string;
onRecognitionResult: (result: string) => void;
}
const SpeechControls = ({
isRecording,
onStartRecording,
onStopRecording,
selectedInputDevice,
onRecognitionResult,
}: SpeechControlsProps) => {
let recognition: SpeechRecognition | null = null;
const initializeSpeechRecognition = () => {
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition;
if (!SpeechRecognition) {
alert('お使いのブラウザは音声認識をサポートしていません。');
return null;
}
const recognition = new SpeechRecognition();
recognition.lang = 'ja-JP';
recognition.continuous = true;
recognition.interimResults = true;
recognition.onresult = (event) => {
const result = Array.from(event.results)
.map(result => result[0].transcript)
.join('');
onRecognitionResult(result);
};
recognition.onerror = (event) => {
console.error('Speech recognition error:', event.error);
onStopRecording();
};
return recognition;
};
const handleStartRecording = () => {
if (!selectedInputDevice) {
alert('入力デバイスを選択してください');
return;
}
recognition = initializeSpeechRecognition();
if (recognition) {
recognition.start();
onStartRecording();
}
};
const handleStopRecording = () => {
if (recognition) {
recognition.stop();
}
onStopRecording();
};
return (
<div className="flex space-x-4">
<button
onClick={handleStartRecording}
disabled={isRecording}
className={`px-4 py-2 rounded-md ${
isRecording
? 'bg-gray-400 cursor-not-allowed'
: 'bg-blue-500 hover:bg-blue-600'
} text-white font-medium`}
>
録音開始
</button>
<button
onClick={handleStopRecording}
disabled={!isRecording}
className={`px-4 py-2 rounded-md ${
!isRecording
? 'bg-gray-400 cursor-not-allowed'
: 'bg-red-500 hover:bg-red-600'
} text-white font-medium`}
>
録音停止
</button>
</div>
);
};
// src/components/RecognitionResult.tsx
interface RecognitionResultProps {
text: string;
}
const RecognitionResult = ({ text }: RecognitionResultProps) => {
return (
<div className="mt-6">
<h2 className="text-xl font-semibold mb-3">認識結果</h2>
<div className="p-4 bg-gray-50 rounded-lg border border-gray-200 min-h-[100px]">
{text || '音声を認識すると、ここに文字として表示されます。'}
</div>
</div>
);
};
export default RecognitionResult;
// Add type declarations for Web Speech API
declare global {
interface Window {
SpeechRecognition: typeof SpeechRecognition;
webkitSpeechRecognition: typeof SpeechRecognition;
}
}
Reactアプリのディレクトリ構成を考えてもらった
ChatGPT(GPT-4o)
reactの最適なディレクトリ構成を教えてください
src/
├── components/ # 再利用可能なUIコンポーネント
├── features/ # 特定の機能やユースケースに関連するコード
├── pages/ # 各ページ(ルートに対応)
├── layouts/ # ページレイアウト(ヘッダー、サイドバー、フッターなど)
├── hooks/ # カスタムフック
├── contexts/ # Reactのコンテキスト関連
├── services/ # API通信やビジネスロジック
├── utils/ # ユーティリティ関数
├── assets/ # 静的ファイル(画像、フォント、スタイルシートなど)
├── styles/ # グローバルなスタイル(CSSやSassファイル)
├── types/ # TypeScriptの型定義
├── tests/ # テスト用のファイル
├── App.tsx # アプリケーションのエントリーポイント
└── index.tsx # ReactDOM.render()のエントリーポイント
1. components/
再利用可能な小規模コンポーネントを配置します。例えば、ボタンや入力フィールドなどの汎用的なUI要素。
components/
├── Button/
│ ├── Button.tsx
│ ├── Button.test.tsx
│ └── Button.module.css
└── Input/
├── Input.tsx
├── Input.test.tsx
└── Input.module.css
2. features/
特定の機能に関連するコードをまとめます。ReduxスライスやAPI通信、関連するコンポーネントをここに配置します。
features/
├── auth/
│ ├── AuthForm.tsx
│ ├── authSlice.ts
│ ├── authAPI.ts
│ └── AuthForm.module.css
└── todo/
├── TodoList.tsx
├── todoSlice.ts
└── todoAPI.ts
3. pages/
各ルートに対応するページコンポーネントを格納します。これらのコンポーネントは、react-routerで使用されます。
pages/
├── Home.tsx
├── About.tsx
└── Profile/
├── Profile.tsx
└── Profile.module.css
4. layouts/
共通のレイアウトを定義します。ヘッダー、サイドバー、フッターなどを含めます。
layouts/
├── MainLayout.tsx
├── Header.tsx
├── Footer.tsx
└── Sidebar.tsx
5. hooks/
再利用可能なカスタムフックを格納します。
hooks/
├── useAuth.ts
├── useFetch.ts
└── useLocalStorage.ts
6. contexts/
Reactのコンテキストプロバイダーとその関連コードを配置します。
contexts/
├── AuthContext.tsx
└── ThemeContext.tsx
7. services/
API通信や外部サービスとのやり取りを管理します。
services/
├── apiClient.ts
└── authService.ts
8. utils/
汎用的なユーティリティ関数を格納します。
utils/
├── dateFormatter.ts
└── validator.ts
9. assets/
画像、フォント、アイコンなどの静的ファイルを配置します。
assets/
├── images/
├── fonts/
└── icons/
10. styles/
グローバルスタイルやテーマ設定を管理します。
styles/
├── global.css
├── variables.module.css
└── mixins.module.css
11. types/
TypeScriptの型定義を格納します。
types/
├── user.d.ts
└── api.d.ts
Claude(3.5 Sonnet)
ディレクトリ構成を考えたときにどのように分けますか?
Reactアプリケーションのディレクトリ構成について、以下のような構成を提案します:
src/
├── components/ # UIコンポーネント
│ ├── common/ # 汎用的なコンポーネント
│ │ ├── Button.tsx
│ │ └── Select.tsx
│ ├── speech/ # 音声関連のコンポーネント
│ │ ├── SpeechControls.tsx
│ │ └── RecognitionHistory.tsx
│ └── voicebox/ # VOICEBOX関連のコンポーネント
│ └── SpeakerList.tsx
├── hooks/ # カスタムフック
│ ├── useSpeechRecognition.ts
│ └── useVoicebox.ts
├── services/ # 外部サービスとの通信
│ ├── voiceboxApi.ts
│ └── audioDevices.ts
├── types/ # 型定義
│ ├── speech.ts
│ └── voicebox.ts
├── utils/ # ユーティリティ関数
│ ├── audio.ts
│ └── formatters.ts
├── constants/ # 定数
│ └── config.ts
├── contexts/ # Reactコンテキスト
│ └── AudioContext.tsx
├── styles/ # スタイル関連
│ └── tailwind.css
└── App.tsx # アプリケーションのルートコンポーネント
featuresディレクトリを使用する場合どうなりますか?また、voiceboxApi内で呼び出すapiが増えた時どのように分離しますか?
src/
├── features/
│ ├── speech-recognition/ # 音声認識機能
│ │ ├── components/
│ │ │ ├── SpeechControls.tsx
│ │ │ └── RecognitionHistory.tsx
│ │ ├── hooks/
│ │ │ └── useSpeechRecognition.ts
│ │ ├── types/
│ │ │ └── recognition.ts
│ │ └── utils/
│ │ └── recognition-formatter.ts
│ │
│ ├── voice-synthesis/ # VOICEBOX音声合成機能
│ │ ├── components/
│ │ │ ├── SpeakerList.tsx
│ │ │ └── SynthesisControls.tsx
│ │ ├── hooks/
│ │ │ └── useVoiceSynthesis.ts
│ │ ├── types/
│ │ │ └── synthesis.ts
│ │ └── utils/
│ │ └── synthesis-formatter.ts
│ │
│ └── audio-devices/ # デバイス管理機能
│ ├── components/
│ │ └── DeviceSelector.tsx
│ ├── hooks/
│ │ └── useAudioDevices.ts
│ └── types/
│ └── device.ts
│
├── shared/ # 共有リソース
│ ├── components/ # 共通コンポーネント
│ ├── hooks/ # 共通フック
│ ├── types/ # 共通型定義
│ └── utils/ # 共通ユーティリティ
│
└── services/ # API通信
├── voicebox/ # VOICEBOXのAPI
│ ├── speakers/
│ │ ├── types.ts
│ │ └── api.ts
│ ├── synthesis/
│ │ ├── types.ts
│ │ └── api.ts
│ ├── audio-query/
│ │ ├── types.ts
│ │ └── api.ts
│ └── index.ts
│
└── config/
├── axios.ts
└── endpoints.ts
// services/voicebox/config/axios.ts
import axios from 'axios';
export const voiceboxClient = axios.create({
baseURL: 'http://localhost:50021',
timeout: 10000,
headers: {
'Content-Type': 'application/json',
}
});
// services/voicebox/config/endpoints.ts
export const VOICEBOX_ENDPOINTS = {
speakers: '/speakers',
audioQuery: '/audio_query',
synthesis: '/synthesis',
metas: '/metas',
presets: '/presets',
} as const;
// services/voicebox/speakers/types.ts
export interface Speaker {
id: number;
name: string;
styles: SpeakerStyle[];
}
export interface SpeakerStyle {
id: number;
name: string;
}
export type GetSpeakersResponse = Speaker[];
// services/voicebox/speakers/api.ts
import { voiceboxClient } from '../config/axios';
import { VOICEBOX_ENDPOINTS } from '../config/endpoints';
import type { GetSpeakersResponse } from './types';
export const speakersApi = {
getSpeakers: async () => {
const response = await voiceboxClient.get<GetSpeakersResponse>(
VOICEBOX_ENDPOINTS.speakers
);
return response.data;
},
getSpeakerById: async (id: number) => {
const response = await voiceboxClient.get<Speaker>(
`${VOICEBOX_ENDPOINTS.speakers}/${id}`
);
return response.data;
}
};
// services/voicebox/synthesis/types.ts
export interface AudioQueryParams {
text: string;
speaker: number;
style?: number;
}
export interface SynthesisParams extends AudioQueryParams {
speedScale?: number;
pitchScale?: number;
volumeScale?: number;
}
export interface AudioQueryResponse {
accent_phrases: Array<{
accent: number;
mora_count: number;
// ...その他のプロパティ
}>;
// ...その他のプロパティ
}
// services/voicebox/synthesis/api.ts
import { voiceboxClient } from '../config/axios';
import { VOICEBOX_ENDPOINTS } from '../config/endpoints';
import type {
AudioQueryParams,
SynthesisParams,
AudioQueryResponse
} from './types';
export const synthesisApi = {
createAudioQuery: async (params: AudioQueryParams) => {
const response = await voiceboxClient.post<AudioQueryResponse>(
VOICEBOX_ENDPOINTS.audioQuery,
params
);
return response.data;
},
synthesize: async (params: SynthesisParams) => {
const audioQuery = await this.createAudioQuery(params);
const response = await voiceboxClient.post(
VOICEBOX_ENDPOINTS.synthesis,
{
...audioQuery,
...params
},
{
responseType: 'blob'
}
);
return response.data;
}
};
// services/voicebox/index.ts
export * from './speakers/api';
export * from './synthesis/api';
export * from './speakers/types';
export * from './synthesis/types';
// 統合APIも提供
export const voiceboxApi = {
...speakersApi,
...synthesisApi,
};
// features/voice-synthesis/hooks/useVoiceSynthesis.ts
import { useState } from 'react';
import { voiceboxApi } from '@/services/voicebox';
import type { SynthesisParams } from '@/services/voicebox';
export const useVoiceSynthesis = () => {
const [isLoading, setIsLoading] = useState(false);
const [error, setError] = useState<Error | null>(null);
const synthesize = async (params: SynthesisParams) => {
setIsLoading(true);
try {
const audioBlob = await voiceboxApi.synthesize(params);
const audioUrl = URL.createObjectURL(audioBlob);
return audioUrl;
} catch (err) {
setError(err as Error);
throw err;
} finally {
setIsLoading(false);
}
};
return {
synthesize,
isLoading,
error
};
};
featuresディレクトリを使わない場合のディレクトリ構成でuseVoicebox.tsの中身はどうなりますか?
// src/hooks/useVoicebox.ts
import { useState, useCallback } from 'react';
import { voiceboxApi } from '../services/voiceboxApi';
import type { Speaker, SynthesisParams, AudioQueryResponse } from '../types/voicebox';
interface UseVoiceboxReturn {
speakers: Speaker[];
selectedSpeaker: Speaker | null;
isLoading: boolean;
error: Error | null;
fetchSpeakers: () => Promise<void>;
selectSpeaker: (speakerId: number) => void;
synthesizeSpeech: (params: SynthesisParams) => Promise<string>;
clearError: () => void;
}
export const useVoicebox = (): UseVoiceboxReturn => {
const [speakers, setSpeakers] = useState<Speaker[]>([]);
const [selectedSpeaker, setSelectedSpeaker] = useState<Speaker | null>(null);
const [isLoading, setIsLoading] = useState(false);
const [error, setError] = useState<Error | null>(null);
// スピーカー一覧の取得
const fetchSpeakers = useCallback(async () => {
setIsLoading(true);
try {
const fetchedSpeakers = await voiceboxApi.getSpeakers();
setSpeakers(fetchedSpeakers);
} catch (err) {
setError(err instanceof Error ? err : new Error('Failed to fetch speakers'));
} finally {
setIsLoading(false);
}
}, []);
// スピーカーの選択
const selectSpeaker = useCallback((speakerId: number) => {
const speaker = speakers.find(s => s.id === speakerId);
if (speaker) {
setSelectedSpeaker(speaker);
} else {
setError(new Error('Invalid speaker ID'));
}
}, [speakers]);
// 音声合成の実行
const synthesizeSpeech = useCallback(async (params: SynthesisParams) => {
setIsLoading(true);
try {
// 音声クエリの生成
const audioQuery = await voiceboxApi.createAudioQuery({
text: params.text,
speaker: params.speaker
});
// 音声合成の実行
const audioBlob = await voiceboxApi.synthesize({
...audioQuery,
...params
});
// AudioURLの生成
const audioUrl = URL.createObjectURL(audioBlob);
return audioUrl;
} catch (err) {
setError(err instanceof Error ? err : new Error('Speech synthesis failed'));
throw err;
} finally {
setIsLoading(false);
}
}, []);
// エラーのクリア
const clearError = useCallback(() => {
setError(null);
}, []);
return {
speakers,
selectedSpeaker,
isLoading,
error,
fetchSpeakers,
selectSpeaker,
synthesizeSpeech,
clearError,
};
};
このフックを使用するコンポーネントの例:
// src/components/VoiceboxControls.tsx
import { useEffect } from 'react';
import { useVoicebox } from '../hooks/useVoicebox';
export const VoiceboxControls = () => {
const {
speakers,
selectedSpeaker,
isLoading,
error,
fetchSpeakers,
selectSpeaker,
synthesizeSpeech
} = useVoicebox();
useEffect(() => {
fetchSpeakers();
}, [fetchSpeakers]);
const handleSpeak = async (text: string) => {
if (!selectedSpeaker) {
alert('スピーカーを選択してください');
return;
}
try {
const audioUrl = await synthesizeSpeech({
text,
speaker: selectedSpeaker.id
});
const audio = new Audio(audioUrl);
await audio.play();
} catch (err) {
console.error('音声合成に失敗しました:', err);
}
};
if (error) {
return <div>エラーが発生しました: {error.message}</div>;
}
return (
<div className="space-y-4">
<div>
<h3 className="text-lg font-medium mb-2">スピーカー選択</h3>
<select
value={selectedSpeaker?.id || ''}
onChange={(e) => selectSpeaker(Number(e.target.value))}
disabled={isLoading}
className="w-full p-2 border rounded"
>
<option value="">スピーカーを選択</option>
{speakers.map((speaker) => (
<option key={speaker.id} value={speaker.id}>
{speaker.name}
</option>
))}
</select>
</div>
<div>
<h3 className="text-lg font-medium mb-2">テキスト入力</h3>
<textarea
className="w-full p-2 border rounded"
rows={4}
placeholder="合成するテキストを入力..."
onKeyDown={(e) => {
if (e.key === 'Enter' && e.ctrlKey) {
handleSpeak(e.currentTarget.value);
}
}}
/>
</div>
<div>
<button
onClick={() => handleSpeak(textRef.current?.value || '')}
disabled={isLoading || !selectedSpeaker}
className="px-4 py-2 bg-blue-500 text-white rounded disabled:bg-gray-400"
>
{isLoading ? '合成中...' : '音声合成'}
</button>
</div>
</div>
);
};
AIに画面を作ってもらった
Claude(3.5 Sonnet)
下記仕様で画面を作成してください
使用技術・言語
・React
・TypeScript
・tailwindcss
画面仕様
・スピーカー選択のSelectbox
・入力デバイス、出力デバイスを選択するボタン
・音声入力開始、終了ボタン
・音声入力結果を表示するテキストエリア
shadcn/uiは使わないでください
入力デバイスと出力デバイスをselectboxにしてください
import React, { useState, useEffect } from 'react';
const VoiceInputComponent = () => {
const [inputDevices, setInputDevices] = useState<MediaDeviceInfo[]>([]);
const [outputDevices, setOutputDevices] = useState<MediaDeviceInfo[]>([]);
const [selectedInputDevice, setSelectedInputDevice] = useState<string>('default');
const [selectedOutputDevice, setSelectedOutputDevice] = useState<string>('default');
const [isRecording, setIsRecording] = useState(false);
const [transcription, setTranscription] = useState('');
// デバイス一覧の取得
useEffect(() => {
const getDevices = async () => {
try {
const devices = await navigator.mediaDevices.enumerateDevices();
const audioInputs = devices.filter(device => device.kind === 'audioinput');
const audioOutputs = devices.filter(device => device.kind === 'audiooutput');
setInputDevices(audioInputs);
setOutputDevices(audioOutputs);
} catch (error) {
console.error('デバイスの取得に失敗しました:', error);
}
};
getDevices();
}, []);
// 録音の開始/停止
const toggleRecording = () => {
setIsRecording(!isRecording);
if (!isRecording) {
// 録音開始のロジック
console.log('録音を開始します');
} else {
// 録音停止のロジック
console.log('録音を停止します');
}
};
return (
<div className="w-full max-w-2xl mx-auto p-6 bg-white rounded-lg shadow-md">
<h2 className="text-2xl font-bold mb-6">音声入力</h2>
<div className="space-y-6">
{/* デバイス選択 */}
<div className="grid grid-cols-1 md:grid-cols-2 gap-4">
{/* 入力デバイス選択 */}
<div className="space-y-2">
<label className="block text-sm font-medium text-gray-700">
入力デバイス
</label>
<select
value={selectedInputDevice}
onChange={(e) => setSelectedInputDevice(e.target.value)}
className="w-full px-3 py-2 border border-gray-300 rounded-md shadow-sm focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-blue-500"
>
<option value="default">デフォルトマイク</option>
{inputDevices.map((device) => (
<option
key={device.deviceId}
value={device.deviceId || `device-${device.deviceId}`}
>
{device.label || `マイク ${device.deviceId}`}
</option>
))}
</select>
</div>
{/* 出力デバイス選択 */}
<div className="space-y-2">
<label className="block text-sm font-medium text-gray-700">
出力デバイス
</label>
<select
value={selectedOutputDevice}
onChange={(e) => setSelectedOutputDevice(e.target.value)}
className="w-full px-3 py-2 border border-gray-300 rounded-md shadow-sm focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-blue-500"
>
<option value="default">デフォルトスピーカー</option>
{outputDevices.map((device) => (
<option
key={device.deviceId}
value={device.deviceId || `device-${device.deviceId}`}
>
{device.label || `スピーカー ${device.deviceId}`}
</option>
))}
</select>
</div>
</div>
{/* 録音ボタン */}
<button
onClick={toggleRecording}
className={`w-full px-4 py-2 rounded-md shadow-sm flex items-center justify-center gap-2 focus:outline-none focus:ring-2 focus:ring-offset-2 ${
isRecording
? 'bg-red-600 hover:bg-red-700 text-white focus:ring-red-500'
: 'bg-blue-600 hover:bg-blue-700 text-white focus:ring-blue-500'
}`}
>
<span className="text-xl">
{isRecording ? '⏹️' : '⏺️'}
</span>
<span>{isRecording ? '録音停止' : '録音開始'}</span>
</button>
{/* 音声入力結果 */}
<div className="space-y-2">
<label className="block text-sm font-medium text-gray-700">
音声入力結果
</label>
<textarea
value={transcription}
readOnly
className="w-full h-32 px-3 py-2 border border-gray-300 rounded-md shadow-sm bg-gray-50 focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-blue-500 resize-none"
placeholder="音声入力結果がここに表示されます"
/>
</div>
</div>
</div>
);
};
export default VoiceInputComponent;
最終的な実装解説
Viteプロジェクト作成
ひとまずViteプロジェクトをサクッと作成
npm create vite@latest realtime-voicebox -- --template react-ts
tsconfig設定
Viteで@aliasが使えるようにtsconfigを設定します
tsconfig.app.json
{
"compilerOptions": {
"baseUrl": ".",
"paths": {
"@/*": ["src/*"],
}
},
"include": ["src"]
}
vite.config.ts
import { defineConfig } from 'vite'
import react from '@vitejs/plugin-react'
import { resolve } from 'path'
// https://vite.dev/config/
export default defineConfig({
plugins: [react()],
resolve: {
alias: {
'@': resolve(__dirname, './src'),
},
},
})
viteのreact-tsテンプレートはv5系のタイミングでtsconfig.app.jsonとtsconfig.node.jsonに分かれたようです
- tsconfig.app.jsonは主にブラウザ側で実行されるクライアント側の設定
- tsconfig.node.jsonは主にNode.js側で実行されるサーバーサイド側の設定
のようです
tailwind設定
こちらを参考にtailwindを設定していきます。ちなみにv4系の場合はvite.config.tsのpluginに登録する形式に変わりました
npm install -D tailwindcss postcss autoprefixer
npx tailwindcss init -p
postcss.config.js
export default {
plugins: {
tailwindcss: {},
autoprefixer: {},
},
}
tailwind.config.js
/** @type {import('tailwindcss').Config} */
export default {
content: [
"./index.html",
"./src/**/*.{js,ts,jsx,tsx}",
],
theme: {
extend: {},
},
plugins: [],
}
src/index.css
@tailwind base;
@tailwind components;
@tailwind utilities;
ソース解説
ディレクトリ構成
.
├── README.md
├── docs ...ドキュメント置き場
├── public ... 外部公開したい静的ファイル配置。favicon,robots.txt等
├── src ... ソースディレクトリ
│ ├── assets ... 画像、フォント等の静的ファイル置き場。基本はpublicではなくこちらを使用
│ ├── components ... UIコンポーネント置き場。基本的にはtsxファイルのみ配置
│ ├── hooks ... 外部データの保存やstate管理したい場合はカスタムフックを利用
│ ├── services ... 外部APIとの通信やビジネスロジックをここに配置
│ └── types ... 型定義ファイル置き場
index.html
<!doctype html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<link rel="icon" type="image/svg+xml" href="/vite.svg" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>リアルタイムVOICEBOX</title>
</head>
<body>
<div id="root"></div>
<script type="module" src="/src/main.tsx"></script>
</body>
</html>
src/main.tsx
import { StrictMode } from 'react'
import { createRoot } from 'react-dom/client'
import './index.css'
import App from './App.tsx'
createRoot(document.getElementById('root')!).render(
<StrictMode>
<App />
</StrictMode>,
)
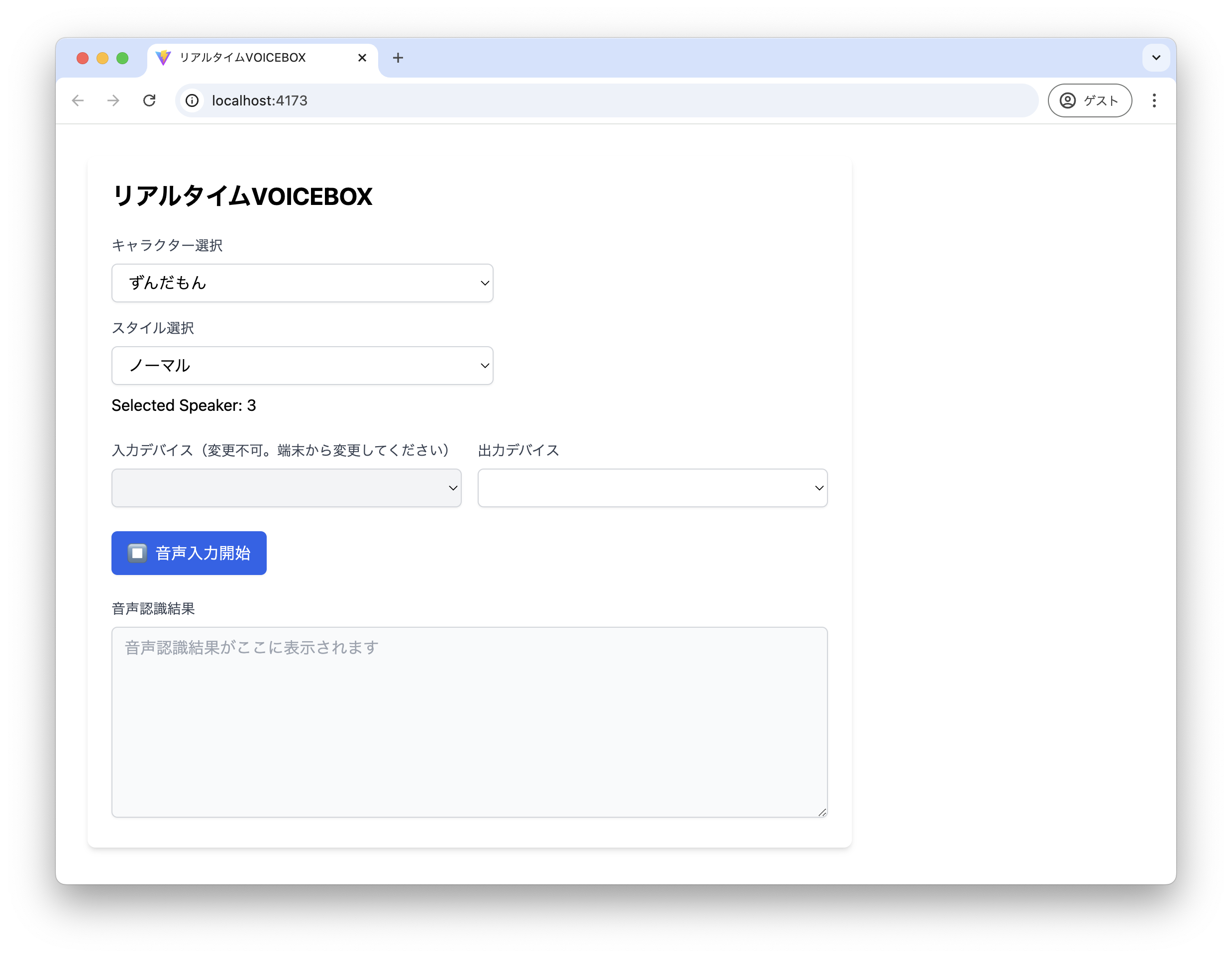
メインページ(App.tsx)
今回は1ページのみの構成なので、コンポーネントやカスタムフックの呼び出しはApp.tsxに集約
ロジックは各ファイルに閉じ込め、必要な変数、関数だけApp.tsxから呼び出します
src/App.tsx
import { useEffect, useState } from 'react'
import { useSpeakers } from '@/hooks/voicebox/useSpeakers'
import { useAudioDevices } from './hooks/useAudioDevices'
import SpeakerList from '@/components/voicebox/SpeakerList'
import AudioDeviceList from './components/AudioDeviceList'
import { useSpeechRecognition } from './hooks/useSpeechRecognition'
import { useSynthesize } from './hooks/voicebox/useSynthesize'
function App() {
// 初期値
const [selectedSpeaker, setSelectedSpeaker] = useState<number>(3) // デフォルト=>ずんだもん
const [selectedInputAudioDevice, setSelectedInputAudioDevice] = useState<string>('default')
const [selectedOutputAudioDevice, setSelectedOutputAudioDevice] = useState<string>('default')
const [isRecording, setIsRecording] = useState(false)
const [recognitionText, setRecognitionText] = useState<string>('')
// データ取得
const { inputAudioDevices, outputAudioDevices, loading: audioDevicesLoading, error: audioDevicesError } = useAudioDevices()
const { speakers, loading: speakersLoading, error: speakersError } = useSpeakers()
const { startRecognition, stopRecognition, onSpeechRecognition, error: speechRecognitionError } = useSpeechRecognition()
const { synthesize } = useSynthesize()
// データ取得時のエラー処理
useEffect(() => {
if (speakersError) {
alert(`キャラクターの取得に失敗しました。\n${speakersError.message}`)
}
}, [speakersError])
useEffect(() => {
if (audioDevicesError) {
alert(`デバイスの取得に失敗しました。\n${audioDevicesError.message}`)
}
}, [audioDevicesError])
useEffect(() => {
if (speechRecognitionError) {
alert(`音声認識に失敗しました。\n${speechRecognitionError.message}`)
}
}, [speechRecognitionError])
// 音声入力の開始/停止
const toggleRecording = () => {
if (!isRecording) {
startRecognition()
} else {
stopRecognition()
}
setIsRecording(!isRecording)
}
// 音声認識
onSpeechRecognition(async (text: string) => {
setRecognitionText(`${recognitionText}\n${text}`.trim())
const { audioUrl, error } = await synthesize({ text, speaker: selectedSpeaker })
if (!audioUrl || error) {
alert('音声合成に失敗しました。' + (error ? `\n${error.message}` : ''))
return
}
const audio = new Audio(audioUrl)
if (selectedOutputAudioDevice && audio.setSinkId) {
audio.setSinkId(selectedOutputAudioDevice)
}
audio.play()
})
return (
!speakersLoading && !audioDevicesLoading && (
<>
<div className="container">
<main className="max-w-3xl m-4 p-4 bg-white rounded-lg shadow-md">
<h2 className="text-2xl font-bold mb-6">リアルタイムVOICEBOX</h2>
<div className="space-y-6">
{/* スピーカー選択 */}
<div className="space-y-2">
<SpeakerList
speakers={speakers}
defaultSpeaker={selectedSpeaker}
onSelectedSpeaker={setSelectedSpeaker}
/>
<p>Selected Speaker: {selectedSpeaker}</p>
</div>
{/* デバイス選択ボタン */}
<div className="space-y-2">
<AudioDeviceList
inputAudioDevices={inputAudioDevices}
outputAudioDevices={outputAudioDevices}
defaultInputAudioDevice={selectedInputAudioDevice}
defaultOutputAudioDevice={selectedOutputAudioDevice}
onSelectedInputAudioDevice={setSelectedInputAudioDevice}
onSelectedOutputAudioDevice={setSelectedOutputAudioDevice}
/>
</div>
{/* 音声入力トグル */}
<button
onClick={toggleRecording}
className={`px-4 py-2 rounded-md shadow-sm flex items-center justify-center gap-2 focus:outline-none focus:ring-2 focus:ring-offset-1 ${
isRecording
? 'bg-red-600 hover:bg-red-700 text-white focus:ring-red-500'
: 'bg-blue-600 hover:bg-blue-700 text-white focus:ring-blue-500'
}`}
>
<span className="text-xl">{isRecording ? '▶️' : '⏹️'}</span>
<span>{isRecording ? '音声入力停止' : '音声入力開始'}</span>
</button>
{/* 音声認識結果 */}
<div className="space-y-2">
<label className="block text-sm font-medium text-gray-700">音声認識結果</label>
<textarea
readOnly
className="w-full h-48 px-3 py-2 border border-gray-300 rounded-md shadow-sm bg-gray-50 focus:outline-none focus:ring-2 focus:ring-blue-500 focus:border-blue-500 resize-y"
placeholder="音声認識結果がここに表示されます"
value={recognitionText}
/>
</div>
</div>
</main>
</div>
</>
)
)
}
export default App
useEffectが2回呼び出される件について
最初はエラーハンドリングの動作確認をしていて気づいたんですが、useEffect内でfetchを実行すると2回エラーのalertが発生する現象に遭遇しました。
とりあえず調べてみると回避策として以下のような方法がありました。
- StrictModeを無効にする
- 開発環境での早期バグの発見や非推奨の検知が出来る機能であり、無効にするのはあまり根本解決になっていないのでやりたくない。。
- クリーンアップ関数を使ってignoreで無視する
- そもそもfetchが2回呼び出されるのを回避したい
- useRefを使って初回レンダリング時に実行させない
- 初回レンダリング時というよりコンポーネントのマウント(使われるタイミング)時に一度実行したいので微妙にやりたい事と違いそう
という事で深掘りした結果、公式ドキュメントを読む事で解決しました!
- そもそもクリーンアップ関数を呼び出すためにuseEffectが2回呼ばれている。
- クリーンアップ関数はuseEffectで実行された処理を停止または元に戻すべき
- そして再度useEffectが呼び出されても問題ないようにするべき(ページを離れて、再度戻るのようにしても不自然な描画にならない)
- そして2回リクエストが走る事自体は問題ない。気になる場合はReact QueryやuseSWRといったキャッシュ機構を使う
という事で腹落ちしました。
詳しくは公式ドキュメントを一読することをお勧めします!
最終的にエラーが2回alertされる問題は、下記のようにerrorの変更を検知する事で解決しました
useEffect(() => {
if (speakersError) {
alert(`キャラクターの取得に失敗しました。\n${speakersError.message}`)
}
}, [speakersError])
コンポーネント(src/components/*.tsx)
componentsディレクトリ以下は基本tsxファイルのUIコンポーネントのみ配置
必要なデータは呼び出し元でのカスタムフックから受け取る
キャラクターの一覧/選択コンポーネント
src/components/voicebox/SpeakerList.tsx
import { Speaker } from '@/types/voicebox'
import { useEffect, useState } from 'react'
type SpeakerListProps = {
speakers: Speaker[]
defaultSpeaker: number
onSelectedSpeaker: (speakerId: number) => void
}
const SpeakerList = ({ speakers, defaultSpeaker, onSelectedSpeaker }: SpeakerListProps) => {
const [selectedSpeaker, setSelectedSpeaker] = useState<string>('')
const [selectedSpeakerStyle, setSelectedSpeakerStyle] = useState<string>('')
const [speakerStyles, setSpeakerStyles] = useState<Array<{ name: string; id: number }>>([])
useEffect(() => {
const speaker = speakers.find((speaker) => speaker.styles.find((style) => style.id === defaultSpeaker))
if (speaker) {
setSpeakerStyles(speaker.styles)
setSelectedSpeaker(speaker.speaker_uuid)
setSelectedSpeakerStyle(String(defaultSpeaker))
}
}, [])
const handleSpeakerChange = (e: React.ChangeEvent<HTMLSelectElement>) => {
const selectSpeaker = speakers.find((speaker) => speaker.speaker_uuid === e.target.value)
if (selectSpeaker) {
setSelectedSpeaker(e.target.value)
setSpeakerStyles(selectSpeaker.styles)
setSelectedSpeakerStyle('')
}
}
const handleSpeakerStyleChange = (e: React.ChangeEvent<HTMLSelectElement>) => {
setSelectedSpeakerStyle(e.target.value)
onSelectedSpeaker(Number(e.target.value))
}
return (
<div className="max-w-sm">
<div className="space-y-2">
<label htmlFor="speaker" className="block text-sm font-medium text-gray-700">
キャラクター選択
</label>
<select
id="speaker"
value={selectedSpeaker}
onChange={handleSpeakerChange}
className="w-full px-3 py-2 border border-gray-300 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500"
>
<option value=""></option>
{speakers.map((speaker) => (
<option key={speaker.speaker_uuid} value={speaker.speaker_uuid}>
{speaker.name}
</option>
))}
</select>
</div>
<div className="mt-4 space-y-2">
<label htmlFor="speaker_style" className="block text-sm font-medium text-gray-700">
スタイル選択
</label>
<select
id="speaker_style"
value={selectedSpeakerStyle}
onChange={handleSpeakerStyleChange}
disabled={!selectedSpeaker}
className="w-full px-3 py-2 border border-gray-300 rounded-md shadow-sm focus:outline-none focus:ring-indigo-500 focus:border-indigo-500 disabled:bg-gray-100 disabled:cursor-not-allowed"
>
<option value=""></option>
{speakerStyles.map((style) => (
<option key={style.id} value={style.id}>
{style.name}
</option>
))}
</select>
</div>
</div>
)
}
export default SpeakerList
音声入力/音声出力デバイスの一覧/選択コンポーネント
入力デバイスをすべてdisabledにしているのは、ブラウザ側の仕様上入力デバイスを変更できないため無効にしています
src/components/AudioDeviceList.tsx
import { useState } from 'react'
type AudioDeviceListProps = {
inputAudioDevices: MediaDeviceInfo[]
outputAudioDevices: MediaDeviceInfo[]
defaultInputAudioDevice: string
defaultOutputAudioDevice: string
onSelectedInputAudioDevice: (deviceId: string) => void
onSelectedOutputAudioDevice: (deviceId: string) => void
}
const AudioDeviceList = ({
inputAudioDevices,
outputAudioDevices,
defaultInputAudioDevice,
defaultOutputAudioDevice,
onSelectedInputAudioDevice,
onSelectedOutputAudioDevice,
}: AudioDeviceListProps) => {
const [inputAudioDevice, setInputAudioDevice] = useState<string>(defaultInputAudioDevice)
const [outputAudioDevice, setOutputAudioDevice] = useState<string>(defaultOutputAudioDevice)
const handleInputAudioDevice = (e: React.ChangeEvent<HTMLSelectElement>) => {
setInputAudioDevice(e.target.value)
const inputDevice = inputAudioDevices.find((device) => device.deviceId === e.target.value)
onSelectedInputAudioDevice(inputDevice?.deviceId || '')
}
const handleOutputAudioDevice = (e: React.ChangeEvent<HTMLSelectElement>) => {
setOutputAudioDevice(e.target.value)
const outputDevice = outputAudioDevices.find((device) => device.deviceId === e.target.value)
onSelectedOutputAudioDevice(outputDevice?.deviceId || '')
}
return (
<div>
<div className="grid md:grid-cols-2 gap-4">
<div className="space-y-2">
<label className="block text-sm font-medium text-gray-700">
入力デバイス(変更不可。端末から変更してください)
</label>
<select
value={inputAudioDevice}
onChange={handleInputAudioDevice}
className="w-full px-3 py-2 border border-gray-300 rounded-md shadow-sm bg-gray-100 cursor-not-allowed"
>
{inputAudioDevices.map((device: MediaDeviceInfo) => (
<option disabled key={device.deviceId} value={device.deviceId}>
{device.label}
</option>
))}
</select>
</div>
<div className="space-y-2">
<label className="block text-sm font-medium text-gray-700">出力デバイス</label>
<select
value={outputAudioDevice}
onChange={handleOutputAudioDevice}
className="w-full px-3 py-2 border border-gray-300 rounded-md shadow-sm"
>
{outputAudioDevices.map((device: MediaDeviceInfo) => (
<option key={device.deviceId} value={device.deviceId}>
{device.label}
</option>
))}
</select>
</div>
</div>
</div>
)
}
export default AudioDeviceList
カスタムフック(src/hooks/*.ts)
カスタムフックについて、非同期的に処理したい場合はdata,loading,errorの3種を返し、同期的に処理したい場合は必要なデータやcallback関数を返すようなイメージで実装しました
キャラクター取得カスタムフック
ずんだもん(speaker=3)や春日部つむぎ(speaker=8)といったキャラクターボイスの設定値一覧を取得します
src/hooks/voicebox/useSpeakers.ts
import { voiceboxApi } from '@/services/voiceboxApi'
import { Speaker } from '@/types/voicebox'
import { useEffect, useState } from 'react'
export const useSpeakers = () => {
const [speakers, setSpeakers] = useState<Speaker[]>([])
const [loading, setLoading] = useState<boolean>(true)
const [error, setError] = useState<Error | null>(null)
useEffect(() => {
const fetchSpeakers = async () => {
try {
const data = await voiceboxApi.fetchSpeakers()
setSpeakers(data)
} catch (err) {
setError(err as Error)
} finally {
setLoading(false)
}
}
fetchSpeakers()
}, [])
return {
speakers,
loading,
error,
}
}
音声入力/音声出力デバイス取得カスタムフック
デバイスのマイクとスピーカーを取得します
src/hooks/useAudioDevices.ts
import { useEffect, useState } from 'react'
type useAudioDevicesProps = {
inputAudioDevices: MediaDeviceInfo[]
outputAudioDevices: MediaDeviceInfo[]
loading: boolean
error: Error | null
}
export const useAudioDevices = (): useAudioDevicesProps => {
const [inputAudioDevices, setInputAudioDevices] = useState<MediaDeviceInfo[]>([])
const [outputAudioDevices, setOutputAudioDevices] = useState<MediaDeviceInfo[]>([])
const [loading, setLoading] = useState<boolean>(true)
const [error, setError] = useState<Error | null>(null)
useEffect(() => {
const getDevices = async () => {
try {
const devices = await navigator.mediaDevices.enumerateDevices()
const audioInputs = devices.filter((device) => device.kind === 'audioinput')
const audioOutputs = devices.filter((device) => device.kind === 'audiooutput')
setInputAudioDevices(audioInputs)
setOutputAudioDevices(audioOutputs)
} catch (err) {
setError(err as Error)
} finally {
setLoading(false)
}
}
getDevices()
}, [])
return {
inputAudioDevices,
outputAudioDevices,
loading,
error,
}
}
音声合成用カスタムフック
- 音声合成用のクエリを作成して
- 作成したクエリから音声データを取得します
src/hooks/voicebox/useSynthesize.ts
import { voiceboxApi } from '@/services/voiceboxApi'
import type { SynthesisParams } from '@/types/voicebox'
export const useSynthesize = () => {
const synthesize = async (params: SynthesisParams) => {
try {
const audioQuery = await voiceboxApi.createAudioQuery(params)
const audioBlob = await voiceboxApi.synthesize({
...audioQuery,
...params,
})
return {
audioUrl: URL.createObjectURL(audioBlob),
error: null,
}
} catch (err) {
return {
audioUrl: null,
error: err as Error,
}
}
}
return {
synthesize,
}
}
音声認識用カスタムフック
- 主にWeb Speech API周りの処理です
- recognition.continuousを設定しないと一度入力されたらそのまま終了してしまうのでtrueにしておきます
- recognition.interimResultsは発言が終了しないと終わりませんが、trueにすると途中経過も取得できます(デバッグ時に有効化すると分かりやすいです)
src/hooks/useSpeechRecognition.ts
import { useState } from 'react'
export const useSpeechRecognition = () => {
const [recognition, setRecognition] = useState<SpeechRecognition>()
const [error, setError] = useState<Error | null>(null)
const initSpeechRecognition = () => {
const SpeechRecognition = window.SpeechRecognition || window.webkitSpeechRecognition
if (!SpeechRecognition) {
setError(new Error('お使いのブラウザは音声認識をサポートしていません。'))
return
}
const recognition = new SpeechRecognition()
recognition.lang = 'ja-JP'
recognition.continuous = true // 継続的に音声認識を行う
// recognition.interimResults = true // 途中結果でも取得する
recognition.onerror = () => {
setError(new Error('音声入力が許可されていません。'))
stopRecognition()
return
}
return recognition
}
const startRecognition = () => {
const recognition = initSpeechRecognition()
if (recognition) {
setRecognition(recognition)
recognition.start()
}
}
const stopRecognition = () => {
recognition?.stop()
}
const onSpeechRecognition = (callback: (text: string) => void) => {
if (!recognition) {
return
}
recognition.onresult = (event: SpeechRecognitionEvent) => {
const result = Array.from(event.results)[event.results.length - 1]
const transcript = result[0].transcript.trim()
console.log('transcript:', transcript)
if (!result.isFinal || transcript === '') {
return
}
callback(transcript)
}
}
return {
startRecognition,
stopRecognition,
onSpeechRecognition,
error,
}
}
サービスクラス(src/services/*.ts)
外部APIとの通信やビジネスロジックをここに配置
Fetch APIについて
クライアント側の接続にFetch APIを使うのですが、このAPIがやや特殊で
- ネットワークエラー等になった場合Errorがthrowされる
- 5xx系や4xx系の場合はErrorがthrowされない
なので、ネットワークエラー等の場合はそのままthrowし、responseがokではない場合もthrowするようにして、呼び出し元でエラーハンドリングさせるよう以下のような実装にしました
src/services/voiceboxApi.ts
import { AudioQueryParams, SynthesisParams } from '@/types/voicebox'
const endpoint = 'http://localhost:50021'
const callApi = async (url: string, options: RequestInit = {}) => {
const response = await fetch(url, options)
.catch((err: Error) => {
throw new Error(`VOICEBOX APIの接続に失敗しました。\n[message: ${err.message}]`)
})
if (!response.ok) {
throw new Error(`VOICEBOX APIのリクエストに失敗しました。\n[message: ${response.statusText}][status_code: ${response.status}]`)
}
return response
}
export const voiceboxApi = {
fetchSpeakers: async () => {
const response = await callApi(`${endpoint}/speakers`)
return response.json()
},
createAudioQuery: async ({ speaker, text }: AudioQueryParams) => {
const response = await callApi(`${endpoint}/audio_query?speaker=${speaker}&text=${encodeURIComponent(text)}`, {
method: 'POST',
})
return response.json()
},
synthesize: async (params: SynthesisParams) => {
const response = await callApi(`${endpoint}/synthesis?speaker=${params.speaker}`, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(params),
})
return response.blob()
},
}
まとめ
AIを活用しての所感
Web Speech APIやVOICEBOX API、ReactのカスタムフックやuseEffect、tailwindなどなどなどほぼ知らない状態で開発進めましたが、生成AIのおかげでかなり開発楽になりましたし、数ヶ月程度で完成させることができました。
ただ、AIが出力してくれるコードのパーツパーツの完成度は高いですが、それを組み合わせて実装するとなるともちろんそのままでは動きませんし、AIの言うとおりに実装すると密結合になりすぎたり、逆に実装が細かく分かれすぎてオーバーエンジニアリングになったりと、アーキテクチャの設計は人間が軸を持って実装しないと、玉石混合で収拾つかなくなりそうだなあと思いました。
今後AIでの実装が増えていくと同時に、大量のコードを瞬時に読み解いて理解するコードリーディング力も求められそうだなと感じました
AIについて
- ChatGPTは言語やツールの使い方に関する疑問や質問、実装方針を相談するのに適しており
- Claudeは具体的な実装、UIコンポーネントや画面を作成したい場合に適していそうです
今回はChatGPTやClaudeといった、対話型の生成AIだったためリポジトリ内に落とし込む手間がありましたが、今後はCursorやClineといったAIエージェントとの対話での開発が便利そうなのでこちらも使っていきたいです
実際AIを触ってみて、TypeScriptとの親和性はかなり高いので今後Typescriptで統一したアーキテクチャも増えていきそうです