本記事の目的
本記事はデータ可視化・視覚化 Advent Calendar 2019の1日目の記事です。
このAdvent Calenderはデータの可視化・視覚化にフォーカスしたものであり、過去のアドベントカレンダーでは2014年のもの、2015年のもの、そして2016年のものがありましたが、いずれもデータ「可視化」にフォーカスされたものであり、また近年は作られていませんでした。
現在、データサイエンティストやデータアナリストといったデータ分析に関する職業が注目を浴びており、また需要が急速に高まっているのは周知の事実でしょう。
そこで今一度、データ分析を何のためにするのか、という視点からデータ可視化・視覚化の重要性を述べていこうと思います。
その前に
データ視覚化と、データ可視化を以下のように勝手に区別します。1
- 視覚化:説明的データビジュアライゼーション (Explanatory data visualization)
- 可視化:探索的データビジュアライゼーション (Exploratory data visualization)
「探索的」・「説明的」はStorytelling data (日本語版:Google流 資料作成術)などでも説明されています。
なぜデータを分析するのか
データ分析に関する技術は興味を惹かれるものが多いです。
目新しい技術が出てくるとついつい試してみたくなります。
しかし、この「方法」から始まった解析は、ついついその方法にフォーカスしすぎてしまい、結果を共有しても他の人(特にデータを見ない人)には理解されないことが少なく有りません(自戒)。
この「方法」から入る分析は、「HOW思考」と呼ばれるものに近いと思います。
HOW思考については以下がわかりやすいでしょうか。
例えば、貯金はどうでしょう。
最近の若い人は、とにかく不安なようです。少しでも将来のためにと思い、少ない原資を貯蓄にまわします。しかし、そもそも将来はどうなっていたいのかが不明確なままなのです。もし、本当にお金の心配をするとしたら、その通貨は本当に日本円で良いのでしょうか。そのようなことを考えることもなく、とりあえず貯金を続けて思考停止に陥ります。将来必要な金額とのギャップが見えているのであれば、選択肢としてのHowの中に、今の自分自身に投資をして、必要なキャッシュを稼ぐという頭に仕上げていく勉強をするなどの項目も出てくるでしょう。
引用元:マイナビ顧問 - 問題解決のための脱HOW思考
上記引用元にも書いてありますが、HOW思考から脱するために、まずWHY、つまりなぜデータ分析をするのか、について考えてみましょう。
哲学的なテーマのように聞こえますが、ここは先人の言葉を引用しましょう。
あらゆるデータ分析は、意思決定に役立つものでないといけない。筋の悪い分析に着手しないためには、具体的にどういう意思決定に役立つかをイメージする必要がある。これを考えるのがデータサイエンティストの仕事だ
引用元:ITMedia News - 「意思決定」の視点がないデータ分析が失敗する理由 元大阪ガスの河本薫氏が解説
つまり、「データ分析は意思決定のためにする」といっても過言ではないでしょう。
これを意識すると、データ分析業務のフローは以下のように捉えられます。

方法はあくまでも仮説を検証するための手段にすぎず、方法に拘る必要はありません。
仮説が検証できれば、方法は何でも良いのです。
データ可視化・視覚化はなぜ重要なのか
上記でも述べたように、
可視化:探索的データビジュアライゼーション (Exploratory data visualization)
視覚化:説明的データビジュアライゼーション (Explanatory data visualization)
と区別します。
まず、データ可視化は、大体の場合は分析する人自身のために行う行為で、仮説をの検証だったり、新たな仮説を立てたりするために行う行為です。
分析をしたことがある人であれば、「取り敢えずプロットしてみて様子見てみよう」と思うことは多々あると思いますし、その重要性は言わずもがなかと思います。
しかし、データ視覚化については、その重要性があまり認識されていない気がします。
私が分析結果を伝える時に気にすることは以下の点です。
- 何を伝えたいか
- 伝える対象が誰であるか(どれぐらいコミュニケーションが取れている人か)
- 伝える対象の数字を見る力はどれほどか
- 伝える対象の背景知識はどれほどか
例:交通事故死亡数 vs 自殺者数
神奈川県のホームページ2にある、交通事故死亡数と自殺者数の推移は以下のように図示されています。

この図では、
- 交通事故死者数はおおよそ毎年減少していっている
- 自殺者数も平成10年から22年までは横這いだが、それ以降は減少していっている
- 平成30年において自殺者数は交通事故死者数の約6倍ある
といったことがわかります。
特に最後の「自殺者数は交通事故死者数の約6倍ある」は右軸を使っているため直感的にわかりずらく、数値を見て判断しないといけません。
同様の理由から
- 平成10年を堺に自殺者数が交通事故死者数を上回るようになった
とも感じられますが、これは事実とは異なります。
数値などをみてもらえればわかりますが、この図の範囲では常に自殺者数の方が上回っています。
(このように、事実を見るために脳のメモリーを使ってしまうので第2軸はあまり用いないほうが良いです)
以上のように、このグラフでは情報量が多すぎて誤って伝わったり、伝えたいことがぼやけたりしてしまいます。
伝える対象を考えることで伝える情報を絞る
それでは、次のようなケースについて考えてみましょう。
- 何を伝えたいか:交通事故死者数より自殺者数の方が多い
- 伝える対象が誰であるか(どれぐらいコミュニケーションが取れている人か):初めて合う小学校高学年の児童
- 伝える対象の数字を見る力はどれほどか:小学生程度
- 伝える対象の背景知識はどれほどか:おそらく交通事故の方が多いと思っている(ニュースでは交通事故のほうが取り上げられやすいため)
このケースでは時系列の情報は落としてしまっていいと考えられます。
ですので、大胆に情報量を減らして以下のようにしても良いでしょう。

また、近年減ってはいるがまだ多い、という情報も追加したいのであれば
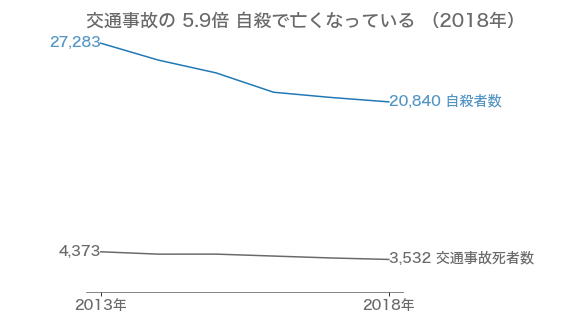
このようにしても良いかもしれません。
以上のように、対象や伝える情報を絞ることで、より伝わりやすいビジュアライゼーションが出来ます。
この記事を読んだ皆様も、この機会にデータ視覚化について意識してもらえると幸いです。
おまけ:最後の図のソース
# データ
suicide = [27283,25427,24025,21897,21321,20840]
traffic_accident = [4373,4113,4117,3904,3694,3532]
year = [i for i in range(2013,2019)]
# 図示下準備
y_datas = [suicide,traffic_accident]
labels = ["自殺者数","交通事故死者数"]
colors = ["#5294C3","dimgray"]
# importとセッティング
from matplotlib import pyplot as plt
plt.rcParams['font.family'] = 'Hiragino Sans' #macならこれ
plt.rcParams['font.weight'] = 'heavy'
# 図示
fig,ax = plt.subplots(figsize=(16/2,9/2))
plt.subplots_adjust(left=0.15, right=0.7, bottom=0.1, top=0.9)
plt.title("交通事故の 5.9倍 自殺で亡くなっている (2018年)",color="dimgray",fontsize=18,fontweight="heavy",loc="left")
## 枠を消す
sides = ['left','right', 'top']
[ax.spines[side].set_visible(False) for side in sides]
ax.plot(year,suicide)
ax.plot(year,traffic_accident,color="dimgray")
ax.set_ylim(0,)
## 数値を図の中に入れる
ax.tick_params(left=False, labelleft=False)
ax.spines['bottom'].set_color("dimgray")
for color,y_data,label in zip(colors,y_datas,labels):
ax.annotate("{:,}".format(y_data[0]),xy=(year[0],y_data[0]),xycoords="data",
ha="right",va="center",color=color,fontsize=14)
ax.annotate("{0:,} {1}".format(y_data[-1],label),xy=(year[-1],y_data[-1]),xycoords="data",
ha="left",va="center",color=color,fontsize=14)
## x軸ラベルの調整
x_label = [year[0],year[-1]]
ax.set_xticks(x_label)
ax.set_xticklabels(['{}年'.format(x) for x in x_label],color="dimgray",fontsize=14,fontweight='bold')