たくさんのドキュメントから特定のドキュメントに類似のものを探します。
経緯
ドキュメントクラスタリングがしたかった。
手始めに雑に類似ドキュメント検索を実装してみた。
使うデータ
livedoorニュースコーパス
https://www.rondhuit.com/download.html#news%20corpus
こんな感じでクリエイティブ・コモンズ・ライセンスが適用された記事のファイルがテキストで保存されている。
概要
やることをざっくり書く
- ドキュメントを全部形態素解析して出現する名詞を網羅して次元とする
- ドキュメントごとに各単語が出現する・しないでバイナリエンコーディング
- 選択したドキュメントと他の全ドキュメントとの類似度を計算する
- 類似度: ここでは単にバイナリベクトルの積
- 類似度が高い順にソート
1. 前準備: 次元の定義
ドキュメントの名詞を全て抽出してエンコーディングの次元を決定する。
Kuromojiで形態素解析をするとこのようなJSONが得られる。
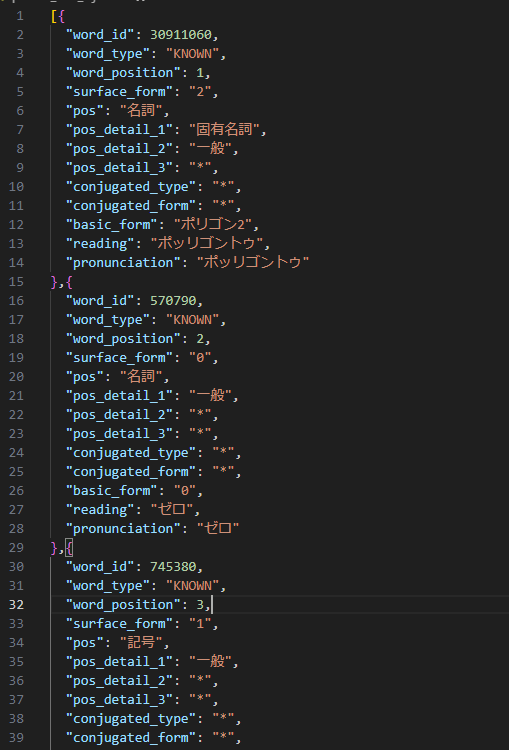
これから名詞のみを抽出、重複を排除して名詞ベクトルにする。これを次元とする。
2. ドキュメントのバイナリエンコーディング
各ドキュメントを再度形態素解析して、1で作成した名詞ベクトルと突き合わせて名詞の有無でバイナリエンコーディングする。
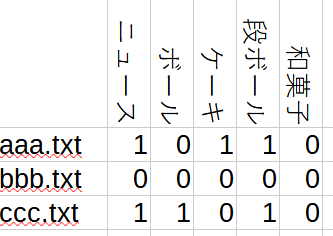
バイナリエンコーディングのイメージはこんな感じ。
実際には全ドキュメントから名詞を抽出しているので単語数は10万ほど。つまり10万列ほどになる。
3. 類似度計算
ターゲットのドキュメントを決めて全てのドキュメントとの類似度を計算する。
今回は単にベクトル積を類似度とする。
例えば、aaa.txt と ccc.txt を比較する場合、ニュースと段ボールのカラムが両方1なので類似度2になる。
これは同じ単語が両方のドキュメントに含まれていることを意味する。
4. 実際に計算してみる
ターゲットドキュメント: このドキュメントに近いものを検索する
http://news.livedoor.com/article/detail/4429538/
2009-11-09T13:00:00+0900
倖田來未と「ル パティシエ タカギ」、クリスマスケーキで夢のコラボ!
倖田來未さんが、あの「ル パティシエ タカギ」のタカギシェフに、「食べてしまうのがもったいなくなるカワイイケーキ」をリクエストしちゃいました!
「上と下で味が違う、1つで2度美味しい、そしてアラザンやリボンでオリジナルなデコレーションを楽しめるクリスマスケーキがいい!」…そんなワガママなお願いを、見事叶えてくれたタカギシェフ。
二段重ねのケーキは、上段がアーモンドベースの生地とチョコレートガナッシュのアクセントが効いた苺ムース。下段はカスタード風味のクリームとピンクのスポンジを三層に重ねて。表面はかわいいピンクのグラサージュで仕上げ、青いリボンを施してあり、このカラフルさが倖田來未さんらしいと思いませんか? さらに、嬉しいサプライズプレゼントまであるのだとか。
くぅちゃんの想いがこもった可愛くて美味しい「Xmas LOVE」で、想い出に残るクリスマスを送ってみては?
☆「〈倖田來未さん×ル パティシエ タカギ〉Xmas LOVE」
価格: 8,925円(税込、配送料込み、冷凍)
サイズ: 直径 下段約15センチ、上段約9センチ、高さ約12センチ
個数: 限定3000個
□販売方法: 10月27日(火)よりそごう・西武各店 食品売場にてご予約承ります
□配送日: 12月22日(火)、23日(水・祝)、24日(木)のいずれかをお選びいただけます
■関連リンク
・西武
・そごう
計算結果: ファイル名と類似度 (トップはターゲットと同じドキュメント)
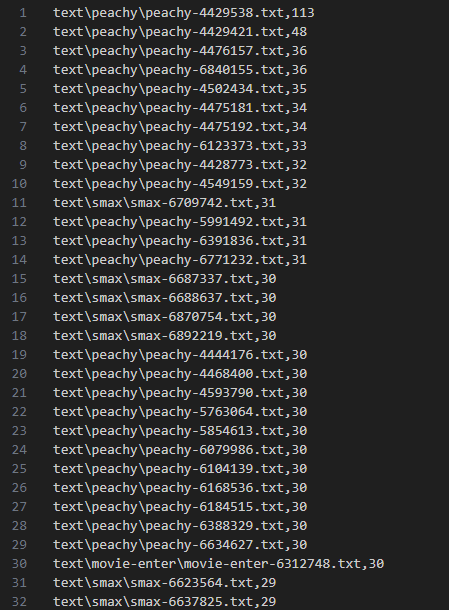
中を見てみる
http://news.livedoor.com/article/detail/4429421/
2009-11-05T10:00:00+0900
「ハートフル」なクリスマスケーキはいかが?
社会全体になんとなく元気のなかった2009年も、あと2ヶ月で終わり。せめて、締めくくりは、大切な人たちと温かくやさしい気持ちで過ごしたい…。
そんなあなたは、希望の象徴である「星」や、きずなのイメージを託した「リボン」をモチーフにしたクリスマスケーキをチェックしてみてはいかが?
西武池袋本店、今年のクリスマスケーキのテーマは「ハートフル」(=心のこもった、優しさがあふれた)。聖夜に祈りを託して。2010年は、ハートフルな年になりますように!
★家族や仲間との「ハートフル」な時間を彩るケーキ
☆スーパーパティシエ4人の8アソートケーキ(直径約15?)6,300円[配送料込・冷凍]
(そごう・西武限定)
実力派パティシエが自慢のケーキをアソートした贅沢な一品。
マルメゾン:パンプキンキャラメル、マルメゾン:マロンショコラ、アニバーサリー:ストロベリークリュ、ガトー・ド・ボア:ラマンボ、ル パティシエ タカギ:キャラメルショコラ、アニバーサリー:フロマージュクリュ、ガトー・ド・ボア:ノエル グリオット、ル パティシエ タカギ:フランボワーズピスターシュ
☆パティスリー・サダハル・アオキ・パリ/クレーム フレーズ(直径約18cm)5,670円
(西武池袋本店限定)
バニラを贅沢に使用したリッチなシャンティークリーム仕立て、AOKI初のクリスマスショートケーキです。
☆ショコラティエ・パレ・ド・オール/ノエルの贈り物(直径約15cm)4,200円
(西武池袋本店限定)
チョコレート生地の間にキャラメルとバニラのムースをサンドし、カカオムースで包み込んだやさしい味わいのチョコレートケーキ。
☆新宿高野/ノエルブラン(直径約19?)10,500円
(西武池袋本店限定)
レアチーズと苺のサンドのデコレーションにホワイトチョコのソースをかけ、フルーツをたっぷり飾ったパーティサイズのケーキ。
★大切な人に「ハートフル」な気持ちを伝える特別なケーキ
☆ル パティシエ タカギ/リューバンドーム(直径約15?)6,825円 [配送料込・冷凍]
(そごう・西武限定)
ホワイトチョコレートのムースにフランボワーズをしのばせ、かわいらしいピンクのショコラをかけました。大切な人とのハートを結ぶリボンがアクセント。
☆ヴィタメール/リュバン・ショコラ(縦約11?×横約12?×高さ約6.5?)4,200円
(西武池袋本店限定)
ショコラカフェムースとキャラメルムースの深い味わいを楽しめるケーキ。大切な人に贈る気持ちを込めてチョコレートのリボンを添えました。
☆ヨックモック/天使からの贈りもの(直径約15?)3,990円
(西武池袋本店限定)
ショコラ生地にホワイトチョコレートのムースと苺のジュレを合わせました。ピンクと白、ルージュの組み合わせでハートフルをイメージ。
☆エコール・クリオロ/バニーユ・フレーズ・クリスマス(直径約15cm)4,830円 [配送料込・冷凍]
(そごう・西武限定)
世界パティスリー2009で最優秀味覚賞を受賞したサントスのショップ。ストロベリーのピューレをサンドしたバニラ香るムースにスポンジ。ストロベリーのコンポート。
□会期: 2009年10月13日(火)〜12月13日(日)
*そごう・西武限定ケーキは12日(土)まで
□ご予約承り会場: 西武池袋本店 地下1階ギフトサロン、洋菓子各売場
□お渡し・お届け方法: 西武池袋本店限定ケーキは、店頭でのお渡し、そごう・西武限定ケーキはご配送のみの承り
■関連リンク
・2009年西武のクリスマスケーキ
http://news.livedoor.com/article/detail/4476157/
2009-11-30T12:40:00+0900
玉川高島屋S・Cのイチオシクリスマスケーキ!
今年のクリスマスケーキをどうするか、もう決めましたか? 玉川髙島屋S・C 本館・南館B1フーズシティから、イチオシのケーキ情報が届きました。数に限りがあるので、食べたいケーキが売り切れてしまわないうちに、予約はくれぐれもお早めに!
☆<ホテルオークラ グルメブティック(本館B1)> ブッシュ・ド・ノエル
3,675円 (15×7×8cm)
プラリネクリームのロールケーキにチョコレートクリームを塗って薪の形に仕上げたクリスマス定番のブッシュ・ド・ノエル。プラリネアーモンドの香ばしさが際立つホテルメイドの美味しさをお楽しみください。
*予約受付: 12月15日(火)まで <限定20台>
*お渡し期間: 12月23日(水・祝)〜25日(金)
*店頭取扱: 12月23日(水・祝)〜25日(金) <限定20台>
☆<Boon’s CREAM PUFF (本館B1)> ザ・フラワーガーデン
2,940円 (5号・直径15cm×高さ9cm)
クリーム・パフ専門店から、3種類のチョココーティングと4種類のクリームが入ったプチパフをトッピングしたクリスマス限定ケーキが登場。色々なパフとスポンジケーキの両方が味わえる欲張りさんにおすすめのケーキ。
*予約受付: 12月13日(日)まで <限定30台>
*お渡し期間: 12月23日(水・祝)〜25日(金)
*店頭取扱: 12月23日(水・祝)〜25日(金) <限定20台>
☆<anew (南館B1)> シャンパンムースのクリスマスケーキ
3,336円 (5号・直径15cm)
ほのかに香るシャンパン風味のムースとラズベリーの酸味が効いた甘酸っぱい大人のケーキ。ムースの中に入っているフルーツ(洋梨、杏、オレンジ)がアクセント。口の中でふわっと溶けるムースの食感をお楽しみください。
*予約受付: 12月10日(木)まで ※予約販売のみ。店頭販売はございません
*お渡し期間:12月25日(金)まで
■関連リンク
・玉川髙島屋S・Cホームページ
結果考察
ターゲットのドキュメントと類似度が高いドキュメントには「クリスマス」「ケーキ」などの単語が含まれる。
何となく雰囲気が近いドキュメントが検索できたといえる。
- 次元数が10万、かなり大きいので共起表現を畳み込んで次元数を削減してもいいかも
- 単語の重みが考慮されていない。
ターゲットドキュメントを例にするとジャンルは「倖田來未」とすべき。
今回の方法だと「ケーキ」「クリスマス」「倖田來未」各単語の重みは等しい。
tf-idf で単語の重みづけをしてもいいかも。 - 今回の方法だと、全ての単語を含む長いドキュメントがあったとすれば、類似度が高くなる。
One-Hotエンコーディングで頻度も重みづけに考慮するとベターだろう。
(データがかなり大きくなってしまうが)
宣伝
Kuromojiで精度の高い形態素解析ができるようにNeologdをビルドしておきました。
よかったら使ってね。
https://www.npmjs.com/package/kuromoji-neologd
プログラム
ちょっと雑ですがスクリプトおいておきます。
import kuromoji from "kuromoji";
import { globSync } from 'node:fs';
import { neologdDict } from "kuromoji-neologd";
import fs from "fs";
import JSONStream from "JSONStream";
import * as readline from 'node:readline';
let tokenizerPromise = null;
function getTokenizer() {
if (!tokenizerPromise) {
tokenizerPromise = new Promise((resolve, reject) => {
kuromoji.builder({
dicPath: neologdDict
}).build((err, tokenizer) => {
if (err) return reject(err);
resolve(tokenizer);
});
});
}
return tokenizerPromise;
}
let parse_all_words_to_file = (async ()=>{
let file_paths = globSync('./text/**/*.txt');
let file_paths_texts = file_paths.map(path => [path, fs.readFileSync(path, 'utf-8')]);
let all_text = file_paths_texts.map( e => e[1]).join("\n");
let tokenizer = await getTokenizer();
let all_text_tokenized = tokenizer.tokenize(all_text);
const stream = fs.createWriteStream('parsed_text_full.json');
stream.write('[');
let isFirst = true;
let i = 0;
for (const item of all_text_tokenized) {
if (item["pos"] != "名詞") continue;
if (!isFirst) {
stream.write(',');
}
stream.write(JSON.stringify({
word_id: item["word_id"],
surface_form: item["surface_form"],
pos: item["pos"],
}, null, 2));
isFirst = false;
}
stream.write(']');
stream.end();
});
let make_parsed_text_shrinked = () => {
const readStream = fs.createReadStream("./parsed_text_full.json", "utf-8");
const jsonStream = JSONStream.parse('*');
readStream.pipe(jsonStream);
const stream = fs.createWriteStream('parsed_text_shrinked.json');
let isFirst = true;
stream.write('[');
jsonStream.on('data', (item) => {
if (item["pos"] != "名詞") return;
if (!isFirst) {
stream.write(',');
}
stream.write(JSON.stringify({
word_id: item["word_id"],
surface_form: item["surface_form"]
}, null, 2));
isFirst = false;
});
jsonStream.on('end', () => {
console.log('JSONの読み込み完了');
stream.write(']');
stream.end();
});
jsonStream.on('error', (err) => {
console.error('エラー:', err);
});
}
let make_words_distinct = () => {
const data = JSON.parse(fs.readFileSync('./parsed_text_shrinked.json', 'utf8'));
let ar = Array.from(new Set(data.map(d => d["surface_form"])));
fs.writeFileSync("words_distinct.json", JSON.stringify(ar, null, 2));
}
let make_word_vector = async (file_name, words_vec) => {
let text = fs.readFileSync(file_name, 'utf-8');
let tokenizer = await getTokenizer();
let words = tokenizer.tokenize(text).map(t => t["surface_form"]);
let vector = []
words_vec.map( vec_word => {
if(words.includes(vec_word)) {
vector.push(1);
} else {
vector.push(0);
}
});
return file_name + "," + vector.join(",");
}
let make_all_file_to_vector = async () => {
let words_vec = JSON.parse(fs.readFileSync('./words_distinct.json', 'utf8'));
let file_paths = globSync('./text/**/*.txt');
const stream = fs.createWriteStream('file_words_vec.csv');
for( let file_name of file_paths ){
console.log(file_name);
stream.write((await make_word_vector(file_name, words_vec)) + "\n");
}
stream.end();
}
(async () => {
//parse_all_words_to_file();
//make_parsed_text_shrinked();
//make_words_distinct();
//let words_vec = JSON.parse(fs.readFileSync('./words_distinct.json', 'utf8'));
//console.log(await make_word_vector("./text/dokujo-tsushin/dokujo-tsushin-4788388.txt", words_vec));
//make_all_file_to_vector();
//let file_text = fs.readFileSync("./file_words_vec.csv", 'utf-8');
let rl = readline.createInterface({
input: fs.createReadStream("./file_words_vec.csv", 'utf-8'),
crlfDelay: Infinity
});
let target_file = "peachy-4429538.txt";
let target_vec = null;
for await (const line of rl) {
if(line.includes(target_file)){
target_vec = line.split(",");
}
}
rl = readline.createInterface({
input: fs.createReadStream("./file_words_vec.csv", 'utf-8'),
crlfDelay: Infinity
});
let file_calc = [];
for await (const line of rl) {
let points = 0;
let line_vec = line.split(",");
target_vec.map((el, idx) => {
return [el, line_vec[idx]];
}).forEach(el => {
if(("1" == el[0]) && ("1" == el[1])) points++;
});
file_calc.push([line_vec[0], points]);
}
let sorted = file_calc.sort((a, b) => b[1] - a[1]);
fs.writeFileSync("file_calc.csv", sorted.map(a => a[0] + "," + a[1]).join("\n"));
console.log("finished");
})();
使用したデータの記事引用元
- トピックニュース
http://news.livedoor.com/category/vender/news/ - Sports Watch
http://news.livedoor.com/category/vender/208/ - ITライフハック
http://news.livedoor.com/category/vender/223/ - 家電チャンネル
http://news.livedoor.com/category/vender/kadench/ - MOVIE ENTER
http://news.livedoor.com/category/vender/movie_enter/ - 独女通信
http://news.livedoor.com/category/vender/90/ - エスマックス
http://news.livedoor.com/category/vender/smax/ - livedoor HOMME
http://news.livedoor.com/category/vender/homme/ - Peachy
http://news.livedoor.com/category/vender/ldgirls/