Tactico
私は先日、趣味とビジネスが半々のプロジェクトTacticoをβリリースしました。
これは株価の表示とスクリーニングのためのツールで、こんなスクリーンショットです。

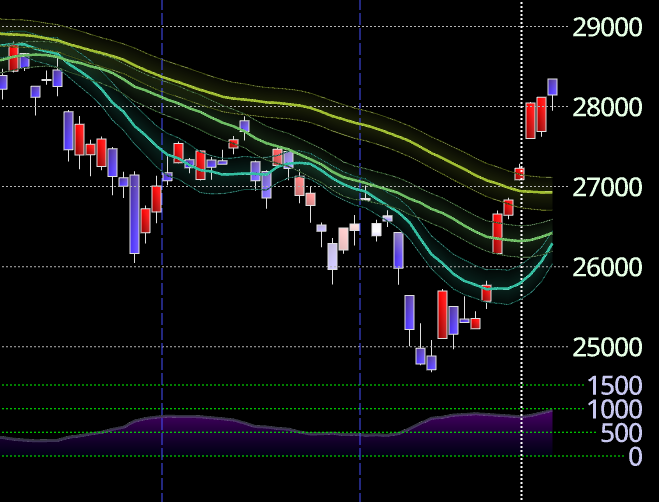
こいつのバックエンドはAWSで、主に Lambda と API Gateway で構成されてますが、これはAWS入門者向けにちょうどいい記事になりそうなので整理して書いてみることにしました。このグラフィックも自信作なんですがそれは別の話として機会があれば書きます。
特定の銘柄の株価データをよこせ、とAPIコールすると、それがLambdaを起動し、S3上に置いてあるデータを読んで加工して応答してやる、という流れです。
それ以外のプロジェクトでも類似の機構は何度も使ったことがあって定石化しており、一回マスターするとノウハウが使いまわしできるので非常に効率よく開発できます。
ユースケース
LambdaとAPIGatewayでやる、というのは今流行のサーバレスアーキテクチャの中でも頻出のパターンですね。外部からのWeb APIのHTTPコールがあったらLambdaを起動し、その応答をクライアントに返してやる、というものです。多くの場合は往復ともJSONで構成したデータをやりとりするでしょう。
最大の特徴は無計画にスタートしても低コストです。今回のように個人的にやるような小規模なプロジェクトだと、毎月1万円もしない範囲でかなりのアクセス数が捌けます。しかも万一アクセスが急増するようなことがあっても全部AWSにお任せできるのがすばらしい。Lambda登場以前は、小さいEC2インスタンスを常時立ち上げていたりして面倒でしたし、オートスケーリングのような仕組みを導入してもどのくらい機能するかの検証が難しかった。そこらへんのわずらわしさがないのでLambdaは便利です。
Lambdaの特徴
もうちょっとLambdaの特徴を書いていきます。
ホットスタートとコールドスタート
Lambdaは呼び出されたときにはじめて起動されるので、初回起動は立ち上がりに数秒の時間を要します。これがコールドスタートです。その後すぐに別のリクエストがくると、同じLambdaインスタンスが使いまわされてクライアントにはすぐレスポンスが返せて(つまりメモリの状態も保持されたまま次のLambda実行が始まる、これがホットスタート)、しかも 複数スレッドで同時実行されるかもしれない ので、Lamdbdaのコード側ではそのことを考慮(スレッドセーフでないポイントは適切に同期を入れる)しなければいけません。また、暫くアクセスがないとAWS側の判断でインスタンスはアンロードされ、次回使用はコールドスタートになります。この条件やタイミングには介入できません。
ひっきりなしに何かのアクセスがあり、いつもLambdaインスタンスが動いてる状態で新しいバージョンのLambdaがデプロイされるとどうなるか? これはちゃんと検証したことがないですが、両バージョンのLambdaが同時稼働する時間帯が短いながらも存在する、という前提でいたほうがよい気がします。
ローカルストレージなし
サーバレスなので、Lambdaから見るとローカルのファイルシステムは存在しません(厳密には、/tmp だけはあるみたいですが、重要なものを置く用途ではありません。)。特に外部のライブラリを使うとき、例えばそのライブラリがローカルファイルシステム上の設定ファイルの存在を仮定していたりすると面倒なことになります。何か回避しないといけません。/etc や /home や C:\ のディレクトリすらそもそも存在しません。
(今調べたら、AWS EFSを作って適切に設定してやればファイルシステムとしてLambdaから扱えるようです)
ストレージを使いたいときは、S3やDynamoDB等を使うことが多いでしょう。RDBMSは、コネクションプーリングとLambdaは相性が悪い(コールドスタート時のレスポンスがさらに悪くなるし、DBサーバから見ても同時接続数がいくつになるのか予測できなくなる)ので、使用しないで済むならそれにこしたことはありません。しかし現実のアプリではRDBMSは避けられないことも多いので、これがLambdaの普及がイマイチな最大の要因と思います。
時間制限あり・メモリ上限あり
Lambdaはコールされてから処理完了までの時間制限があります。これは設定可能ですが、15分より長い時間は設定できません (昔は5分が上限だった!)。APIの応答としてLambdaを使うぶんには全く問題ない制限ですが、バッチ系の処理ではこの制限にかかりそうになったら別の手段を考える必要があります。最初は短時間で済んでいたが、機能追加やユーザ数増加に伴って時間制限を超えてきてしまうというのはありがちな罠です。
短期的には、処理を分割したうえでLambdaが別のLambdaを非同期に起動する方法で凌げます。もっと大規模になったらStep Functionsとかの出番でしょうが、そこまで大げさにしたくないが15分は超えそう、みたいなときには現状僕はノープランです。メモリは増やせてもプロセッサを強化することはできないですからね...
なお時間制限に達するとLambdaは強制終了になり、CloudWatch等に痕跡は残るものの、Lambda自体から「俺は強制終了になった」と外部に通知することはできません。APIの応答なら正常応答にならないのですぐわかりますが、CRON系の処理でこれに陥ると困ります。
一方メモリはもちろん余裕を持たせた設定がいいですが、増やし過ぎればコストに跳ね返ります。実際に使った量はCloudWatch等で事後に確認できます。経験上のことですが、ちょっとメモリ枯渇気味、くらいだと実行に時間はかかるもののエラーにはならず正常に処理完了するので、枯渇していることに気づきにくいです。
JSONでのやりとり
すっぴんのLambdaでは、伝統的なプロセスの標準入出力と同様に、ストリームを受け取ってストリームを返すスタイルになります。
using System.IO;
public class MyLambda
public Stream Main(Stream stream) {
...(本体)...
}
}
しかしAPIGatewayと接続するときは往復ともJSONなのでただのストリームではやりづらい。今回はC#でLambdaを実装したので、こうやってアセンブリにAttributeを1つ書くだけで、NewtonsoftのおなじみJObjectでいけます。これはやらない手はありません。ついでにasyncにします。
なお、APIGatewayからのコールだけでなく、CloudWatchからCRONで定期実行する際も、Lambda起動パラメータとして固定値のJSONが渡せます。そうするとLambda側からは、APIGatewayからの呼び出しかCRONでの呼び出しかJSONの中身を見れば判定できます。別のLambdaを用意するより管理がしやすいです。
using Newtonsoft.Json.Linq;
[assembly:LambdaSerializer(typeof(Amazon.Lambda.Serialization.Json.JsonSerializer))]
public class MyLambda {
public async Task<JObject> Main(JObject input, ILambdaContext context)
...(本体)...
}
}
C#以外の言語でも類似の機能はあると思いますが調べてはいません。
APIGateway
さてLambdaの話は終わりにしてAPIGatewayです。
APIGatewayを使うと、外向けのpublicなAPIを定義して一瞬でデプロイできます。APIが呼ばれたときに何をするかのアクションもいろいろあるらしいんですが、設定が複雑すぎる上にブラウザ上の設定画面はわかりにくく、ドキュメントもそう細かくは書かれてないのでここははまりやすい。(それでも昔に比べればマシになりました)
とにかくこの Lambdaプロキシ統合の使用 をチェックするのがポイントです。余計なことは考えずに、すべてのリクエストをまずLambdaで受け取り、正当な呼び出しかどうかはLambda内で判定するのが簡単確実です。このへんの設定を間違えてても、エラーメッセージからは何がまずいのか全然読み取れないんですよ... (繰り返しますが、昔のAPIGatewayはこのへんが本当にひどかった。今はかなりマシになりましたが、初心者殺しなのは相変わらず)

HTTPメソッドもANYにして全部受け取るのがよいです。処理本体はGETやPOSTだけであっても、CORSの preflight request の都合とかでどのみち HTTP OPTIONS メソッドとかも対応しないといけなくなります。
パス設計
特に(自分のアプリで使うだけでなく)API自体を外部に公開する場合、URLの設計を凝りたくなります。/some/awesome/featureがいいか /feature/some/awesome がいいか、HTTPの GET/POST/PUT のどれにすべきか、QueryStringはどうするのか、みたいなので悩んだ経験は誰でも一度ではあるんじゃないでしょうか。
経験上、ここは凝らずに単一エンドポイントが楽です。一個のエンドポイントのURLだけ用意するか、APIGatewayの設定で最初からプロキシリソースにしておいて、そこから先はパスのパース含めて全部Lambdaでやって分岐するなりエラーで返すなりするタイプです。

APIGatewayの場合、エンドポイント毎にLambdaの呼び出し許可の設定をしなければならない ので、エンドポイントがたくさんあるとその管理だけで日が暮れてしまう。特に開発中はエンドポイントの定義が頻繁に変わるので本当に困ります。
どうしてもエンドポイント設計を凝りたいときは、YAML形式でインポート・エクスポートできる機能があるのでそれを使ってgit管理下におき、かつWebのコンソールでなくaws cliで権限設定含めデプロイを一発できるようにできるようツール整備すべきです。(疲れすぎるので自分でやったことはありません)。APIの見た目以前に、AWSのWebのコンソールで長時間プチプチ設定するのだけは何としても避けるべきです。
ステージ変数
APIGatewayのステージとは、例えばステージングと本番で2種類のAPI構成を用意して、中身はだいたい同じなんだけど接続しにいくLambdaが違う、みたいなやつです。これは、例えばステージ変数 lambdaName を定義して、それぞれステージングのAPIGatewayではステージング用のLambda,本番用のAPIGatewayでは本番のlambda、を参照するようにしておけば、各エンドポイントでは$(lambdaName)としてラムダ名の決め打ちを避ける、ことができます。が、結局Lambdaの呼び出し権限設定まわりが面倒くさくなるのであまりオススメしません。でもデプロイツールさえ整備されてくればいい感じになるでしょう。
HTTP403
その権限設定と関係して、最大のハマりポイントはこれです。APIGatewayでは、typoとかでうっかり存在しないエンドポイントをコールしても、HTTPのステータスコードは403 Forbiddenになってしまいます。(404にはならない!)
すると、エンドポイントが存在しないのか、エンドポイントはあるが何か権限設定が間違ってるのか、APIGatewayの応答からは判別ができません。セキュリティ上はこのほうがいいのは理解できますが、開発時にこれはなかなかつらい。
JSON例
APIGateway経由でLambdaを呼んだとき、Lambdaが受け取るJSONとLambdaが返すJSONの例をここに書いておきます。HTTPヘッダやAPIGatewayのステージ名のような情報もセットになってるので、ここの情報どうやって取るんだったかな~、というときの参考にしてください。Lambda/APIGateway間通信では、HTTPヘッダもまとめてJSONの一部になること、APIGatewayをコールするユーザ側との受け渡しをするJSONはString化してAPIGatewayのbodyフィールドになることがポイントです。
これに限らずAPI開発の基本ですが、クライアントのリクエストの内容に問題があるときは、HTTP 400の応答を返しつつ、リクエストにどのような問題があるのかをわかりやすいエラーメッセージで返すのが重要です。一人で開発しててもこれは痛感するので、チームでやるときはなおさらです。HTTP 500は100%サーバ側に責任があるときだけです。
なお、JSONではないデータをやりとりする方法もあるはずですが、これはやったことがないのでよくわかりません。APIGatewayの場合バイナリデータはBASE64になるらしいので、通信量は増えそうです。
(Lambdaが受け取るJSON)
{
"resource": "/bulk",
"path": "/bulk",
"httpMethod": "POST",
"headers": {
"Accept": "*/*",
"Authorization": "Bearer eyJhbGciOiJSUzI1...",
"Cache-Control": "no-cache",
"Content-Type": "application/json",
"Host": "api-dev.tactico.jp",
"Postman-Token": "0ff8b7db-b8ee-40a8-b2e4-4e3a473332d2",
"User-Agent": "PostmanRuntime/7.28.4",
"X-Amzn-Trace-Id": "Root=1-623ead4e-42732f0f38ac4013160ee85a",
"X-Forwarded-For": "111.90.98.218",
"X-Forwarded-Port": "443",
"X-Forwarded-Proto": "https"
},
"multiValueHeaders": {
"Accept": [
"*/*"
],
"Authorization": [
"Bearer eyJhbGciOiJSUzI1NiIsIn...."
],
"Cache-Control": [
"no-cache"
],
"Content-Type": [
"application/json"
],
"Host": [
"api-dev.tactico.jp"
],
"Postman-Token": [
"0ff8b7db-b8ee-40a8-b2e4-4e3a473332d2"
],
"User-Agent": [
"PostmanRuntime/7.28.4"
],
"X-Amzn-Trace-Id": [
"Root=1-623ead4e-42732f0f38ac4013160ee85a"
],
"X-Forwarded-For": [
"111.90.98.218"
],
"X-Forwarded-Port": [
"443"
],
"X-Forwarded-Proto": [
"https"
]
},
"queryStringParameters": null,
"multiValueQueryStringParameters": null,
"pathParameters": null,
"stageVariables": {
"bellagioLambda": "bellagio-dev-basic"
},
"requestContext": {
"resourceId": "pscggq",
"resourcePath": "/bulk-dev",
"httpMethod": "POST",
"extendedRequestId": "PlAEOGZINjMFeWw=",
"requestTime": "26/Mar/2022:06:06:06 +0000",
"path": "/bulk",
"accountId": "831712911924",
"protocol": "HTTP/1.1",
"stage": "dev",
"domainPrefix": "api-dev",
"requestTimeEpoch": 1648274766021,
"requestId": "41257378-37dc-4507-a32f-35e5649f0b89",
"identity": {
"cognitoIdentityPoolId": null,
"accountId": null,
"cognitoIdentityId": null,
"caller": null,
"sourceIp": "111.90.*****",
"principalOrgId": null,
"accessKey": null,
"cognitoAuthenticationType": null,
"cognitoAuthenticationProvider": null,
"userArn": null,
"userAgent": "PostmanRuntime/7.28.4",
"user": null
},
"domainName": "api-dev.tactico.jp",
"apiId": "65hh04028j"
},
"body": "{\"method\":\"echo\"}",
"isBase64Encoded": false,
}
(LambdaからAPIGatewayへの応答例)
JObject headers = new JObject {
{ "Content-Type", "application/json" },
{ "Set-Cookie", "...." },
...
};
return new JObject {
{ "statusCode", 200 },
{ "headers", headers },
{ "body", body.ToString(Newtonsoft.Json.Formatting.None) }
};
さいごに
当Tacticoプロジェクトの他、自分の個人的なことを書いたブログTactico Blogもありますのでどうぞご覧ください。
個人的にはLambdaがどうAWS内で実装されているのかが気になります。dockerをベースに、AWS用に魔改造されたシステムが使われてるのではないかと推定します。