はじめに
ひょんなことから、"Orange3"というGUIベースの機械学習用ソフトウェアの存在を知った。どうやら、Scikit LearnとScipyでできることは大体できる、というソフトウェアらしい。簡単に触ってみたところ、「コーディングはしたことがないけれど、機械学習のプロセスを学びたい」という人にはちょうど良さそうだった。せっかくなので、Orange3上での操作と、それに該当するPythonのコードを併記することにした。これを一緒にみれば、機械学習のプロセスとコーディングを同時に学べるのでは?という目論みである。
この記事で対象とする人
・コーディングしたことはないけれど、機械学習の勉強をしたい人
・↑のような初心者用の教材を探している人
・管理職やマネージャーなんかで、現場からは距離があるし今さらコーディングを勉強するのは無駄では?しかし部下の評価をしなければ、、、という人
使用するソフトウェアとパッケージ
Orange3は、以下からダウンロードできる。インストールは、ダウンロードしたものをダブルクリックすることにより行う。この記事の執筆時点では、最新は3.32.0になっている。
Pythonのコードの方では、以下のパッケージを使用している
・Pandas
・Scikit Learn
・matplotlib
今回使ったくらいのコードなら、おそらくどのバージョンでも(よほど古くない限り)エラーは出ないと思う。
使用するデータ
この記事では、下記の記事で作成したデータを使っている。もちろん、手持ちのデータで試してもらっても問題はない。
実際の操作とコード
まずはOrange3を起動し、最初に出てくる画面を閉じる。すると、アイコンの並んだ列と、何も書かれていない白い部分が出てくると思う。この白い部分に、機械学習(というか、データ解析)のフローを作っていくことになる。
まずは、ここに「データを読み込む」という命令をおいてみる。↓の動画には、該当のアイコン(CSV File Import)が隠れている可能性も考えて、隠れていた場合に必要なアイコンを探す操作も入れてみた。

↑の動画を見てもらえばわかる通り、「Data」や「Transform」など、操作がいくつかのカテゴリに分かれている。データ読み込みは、この中で「Data」のカテゴリに入っている。アイコンを見つけたら、動画のように、画面右の白い部分にドラッグ&ドロップで配置する。場所はどこでもいい。
続いて、配置したアイコンをダブルクリックすることにより、ファイルを選択することができる。OSによって画面は違うと思うが、MacOSでは、下記の通り。データを入れてあるcsvファイルを選ぶ。
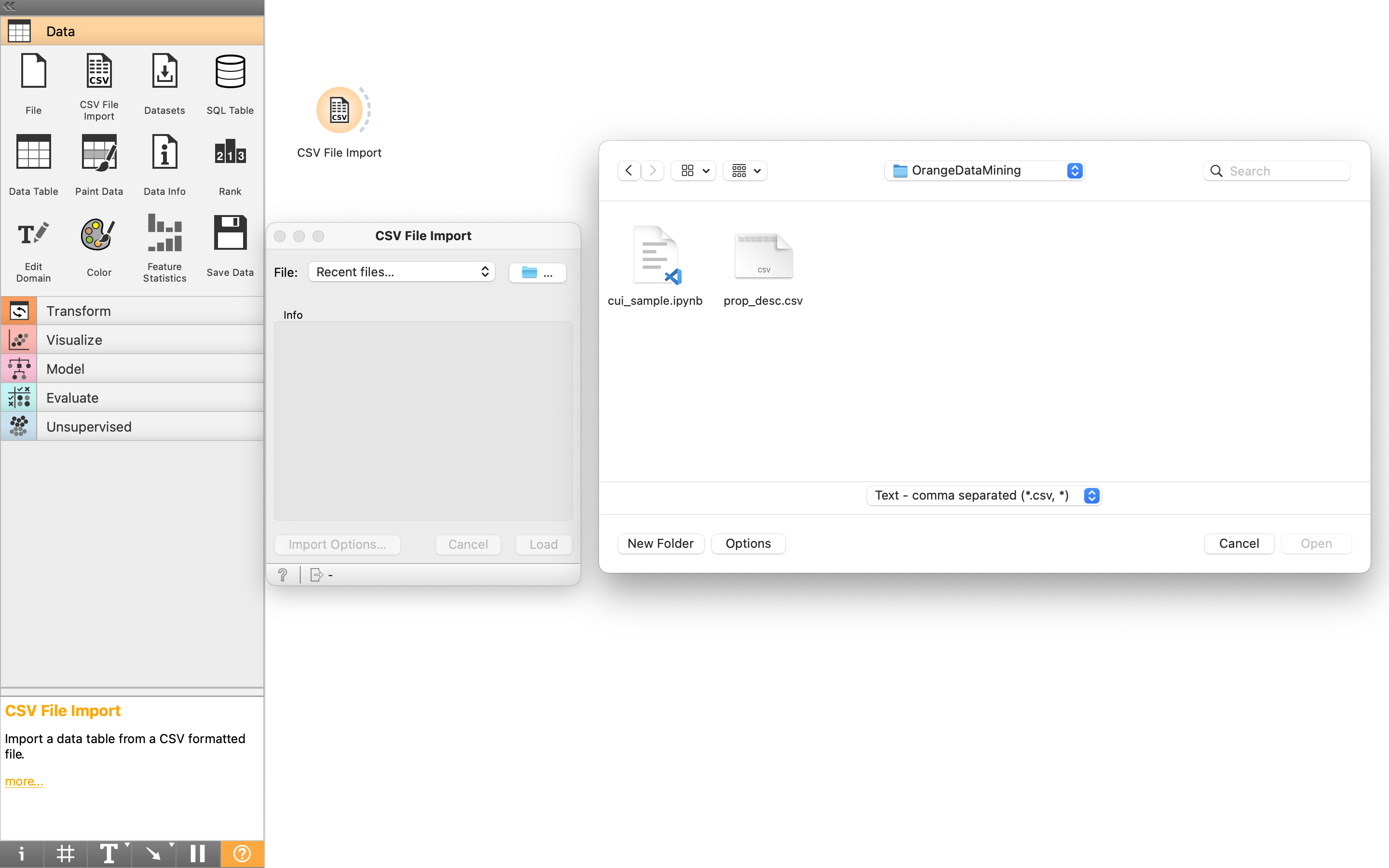
次に出てくる画面は、閉じてしまって問題ない。
ここで注意点だが、このOrange3の特徴として、「操作を実行する」に相当する作業がない。つまり、アイコンを配置し、条件を設定した時点で、そのフローは実行されている。「OK」や「実行」に相当するボタンがないので最初は面食らうが、慣れると楽(かもしれない)。
この操作は、以下のコードに相当する。
import pandas as pd
#ここではprop_desc.csvというファイル名のファイルを読み込む
df0 = pd.read_csv('prop_desc.csv')
続いて、読み込んだデータを、目的変数(解析対象の物理量)と、説明変数(目的変数を計算するための物理量、特性値)に分けたい。そこで、「Transform」のカテゴリから、「Select Columns」をドラッグ&ドロップで配置する。続いて、最初の「CSV File Import」と、この「Select Columns」をつなぐ操作を行う。これは以下の動画の通り。言葉で説明するとややこしいが、個別の操作のアウトプットを得たい場合は、アイコンの右側の円弧、別の操作からインプットを得たい場合は左側の円弧から線を引っ張ってくる(ドラッグ&ドロップしている)。

続いて、Select Columnsのアイコンをダブルクリックし、データの選択画面に移行する。続いて、下記の動画の要領で、目的変数を「Target」の欄に移動する。どうやら、デフォルトでは全ての列(columns)が、説明変数(Features)に入っているらしいので、一回そこから取り出す操作が必要になっている。

この操作は、次のコードに該当する。
#ここでは、'log_ed'という列に目的変数(解析対象の物理量)が入っている。
obj = df0['log_ed']
desc = df0.drop('log_ed', axis=1)
次の操作では、データを訓練用データとテストデータに分割する。ここでは、「Transform」カテゴリ内の「Data Sampler」を使う。「Data Sampler」を設置し、「Select Columns」と接続したら、「Data Sampler」をダブルクリックして、データの分割条件を決める。ここでは、70%を訓練データに回すことにした。
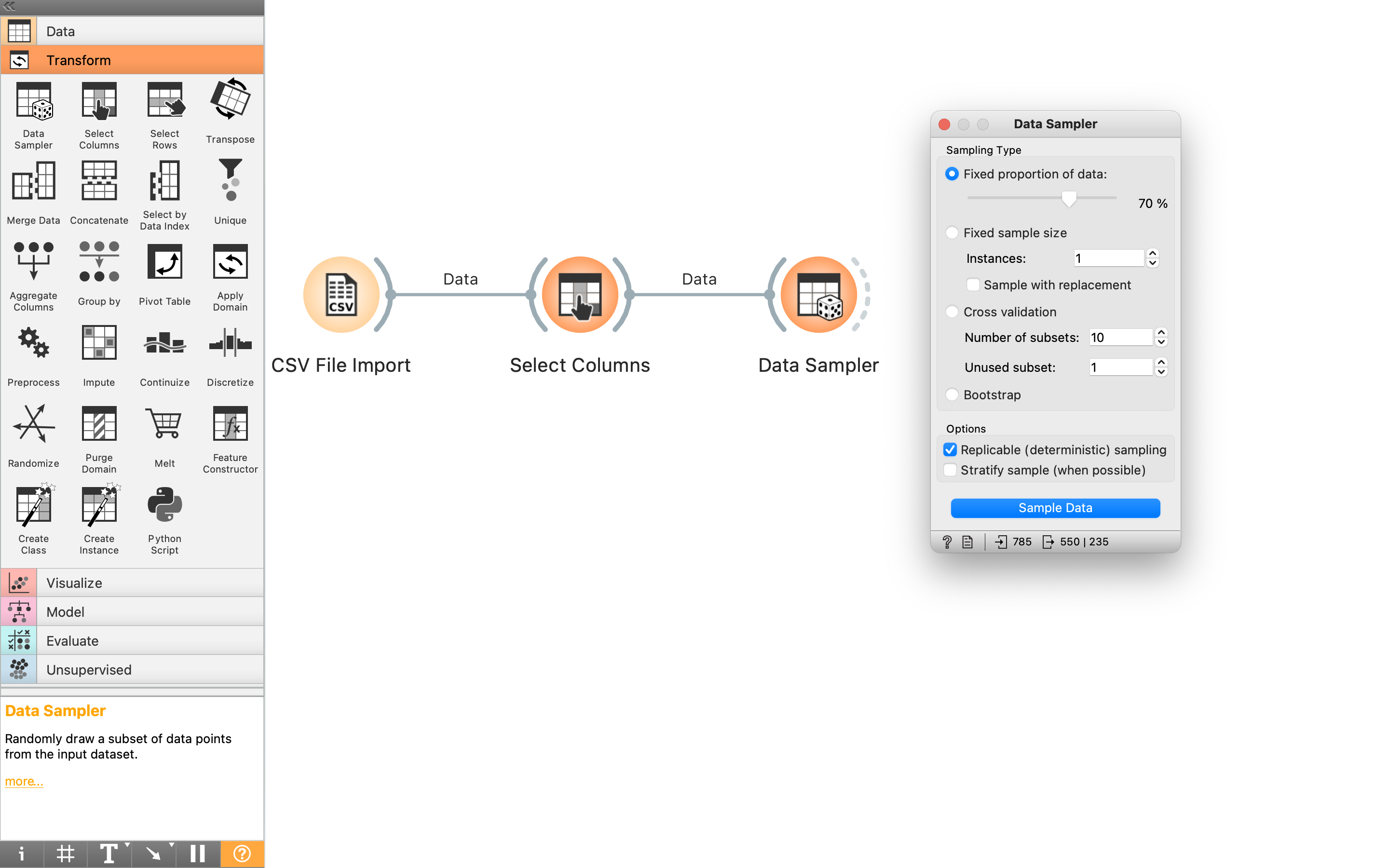
該当コードは以下の通り。
from sklearn.model_selection import train_test_split
desc_train, desc_test, obj_train, obj_test = train_test_split(desc, obj, test_size=0.3)
次は機械学習モデルを作成する。「Model」カテゴリ内の「Linear Regression」を配置し、「Data Sampler」と繋いだら、「Linear Transform」をダブルクリックして、条件を設定する。ここでは、Ridge回帰を用いることにした。
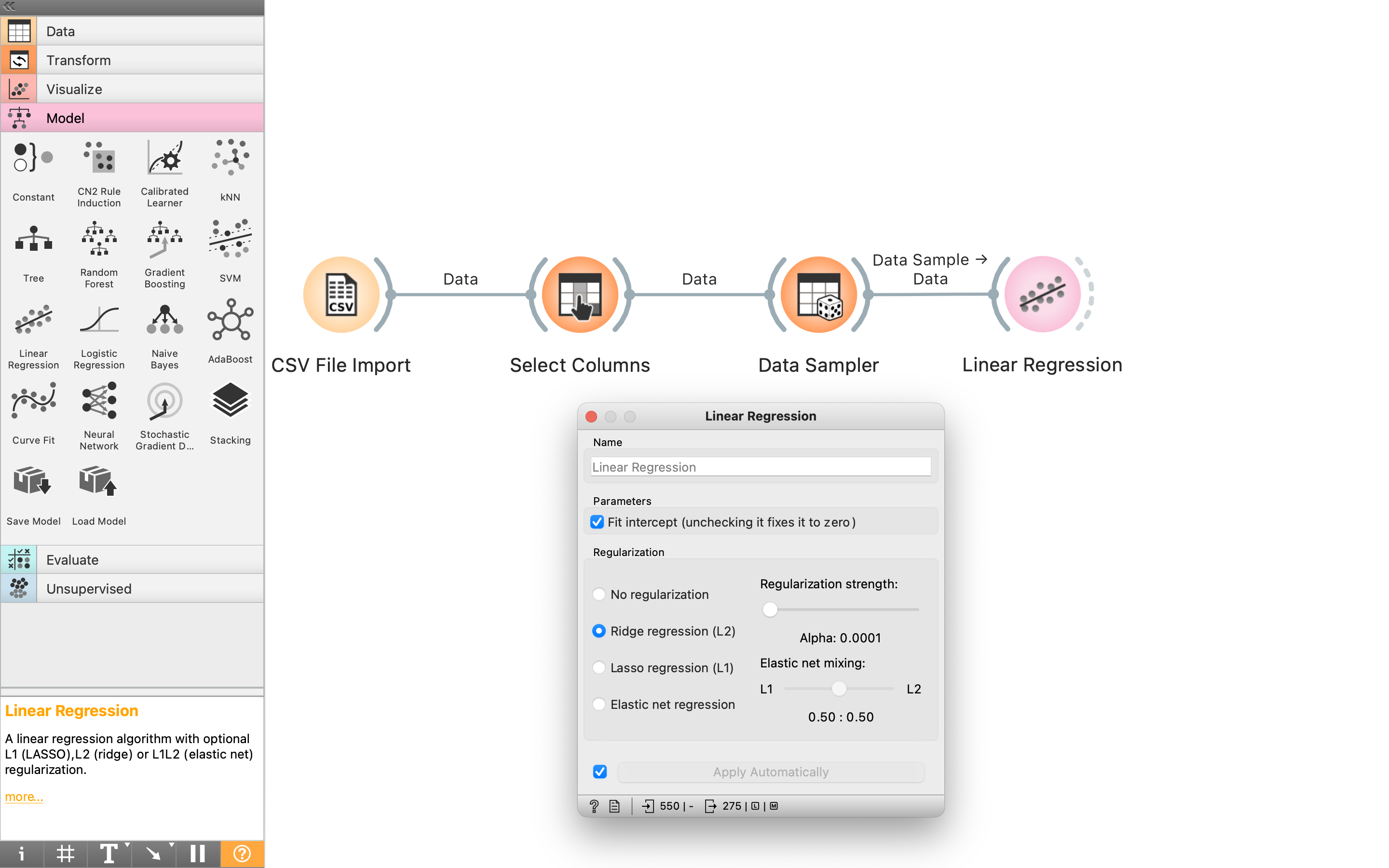
このコードは以下の通り。
from sklearn.linear_model import Ridge
rdg = Ridge()
rdg.fit(desc_train, obj_train)
そしたら、「Evaluate」カテゴリの「Predictions」を配置し、「Data Sampler」および「Linear regression」と接続する。

ここで微妙に気をつけたいのが、「Data Sampler」とつなぐと、デフォルトでは訓練用データが入力されるようになっているらしい。そこで、以下の操作により、テストデータを入力するようにする。繋がっている線をダブルクリックしてデータ選択画面を開き、その後、出力データを選んでいる。データの出力を選ぶのが最終的に「Remaining Data」を「Predictions」につなげられればいいのだが、微妙にわかりにくいポイントとして、・すでに繋がっている線はクリックで消える ・新しく繋げたい時は、ドラッグ&ドロップする がある。

ここは、コードで書けば一行。
pred = rdg.predict(desc_test)
最後に、解析したデータを可視化しよう。「Visualize」カテゴリから「Scatter Plot」を選択し、例によって「Predictions」と接続する。
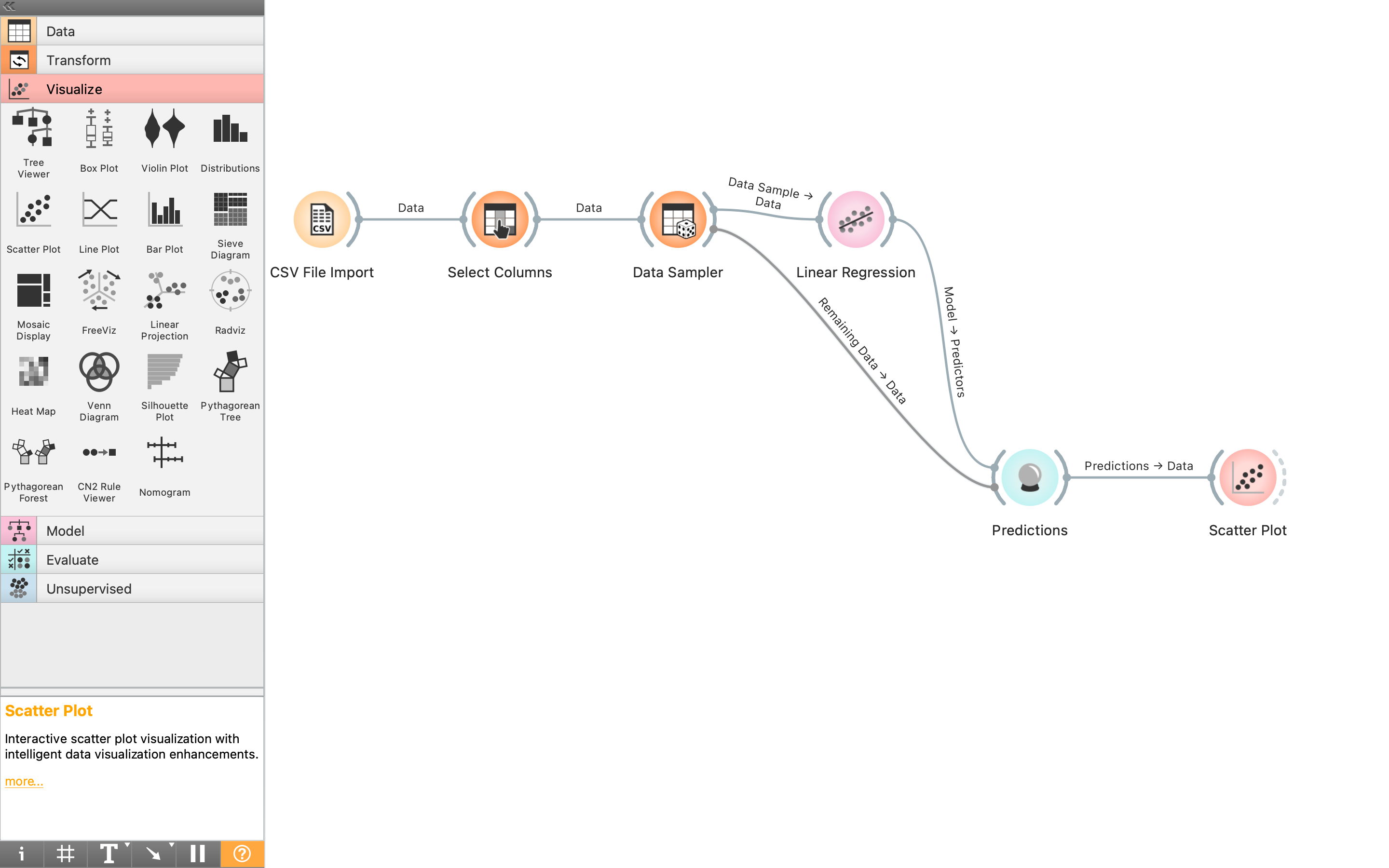
この後、「Scatter Plot」をダブルクリックしても何も表示されないが、以下の二枚の画像の要領でデータを選択することにより、散布図が得られる。つまり、「Axis x」では実測データ(元の列名になっており、ここでは「log_ed」)、「Axis y」では予想データ(Linear Regression)を選ぶ。

これもコードを載せておく。
import matplotlib.pyplot as plt
plt.scatter(obj_test, pred)
以上で、簡単な回帰のプロセスをGUIで実行することができた。フローが可視化されおり、直感的に「何をしているのか」がわかるのは、初心者には大きなメリットだろう。デザインも良いので、コーディングに慣れていても、作業プロセスを人に説明する時には便利だ。
本記事はここまで。