はじめに
本記事では「Webブラウザの仕組み」について書いています。
「Webブラウザの仕組み」が少しでも分かるようになってくると、フロントエンドエンジニアとしての渋みが増しますし、また、近年のAngularやReact、Vue.jsといったJavaScriptのフレームワークの興隆により、SPA(Single Page Application)開発も盛り上がってきているので、余計にこのようなフロントエンドの知識は重要となっています。
「ブラウザがリクエストを飛ばしてから画面描画するまで」に関する記事は、他にもいくつかありますが、今回本記事では主に「プロセス」に着目した中で『画面描画の仕組み』について書いておりますので、少し違った切り口となっています。
「Webブラウザの仕組み」はフロントエンドエンジニアであれば絶対に抑えておきたい知識です。ぜひ新人フロントエンドエンジニアの方には、本記事を通して、僕と共に長く深い「ブラウザの仕組み」の世界の入り口に一歩進んでもらえたらなと思います。
※ 1. もちろん十分注意してはおりますが、もし万が一、間違い等ございましたらご指摘いただけたら幸いです。
※ 2. 本記事はGoogleの掲載している記事をベースとしています。元ネタは最後にまとめて掲載しております。
「Webブラウザの仕組み」を知るための予備知識
本記事の主題である「モダンなWebブラウザの仕組み」に入る前に、それを知る上で不可欠な予備知識を少しだけ紹介していきます。
具体的には、「プロセス」「スレッド」「ブラウザアーキテクチャ」の3つの用語なのですが、全て今後の大事なキーワードとなりますので、もしご存知でなければしっかりと読んで理解することをおすすめします。(もちろん既にご存知の方はスキップしていただいて構いません。)
「プロセス」と「スレッド」の違いは?
「プロセス」と「スレッド」、エンジニアであれば恐らくほとんどの方が耳にしたことがある用語かと思いますが、「なんとなくは知ってる〜」くらいの理解な方も少なくないのではないでしょうか。そんな方は、せっかくなので、これを機にサクッと理解してしまいましょう。
「プロセス」と「スレッド」は似て非なる概念なので、ごっちゃにならないよう、丁寧に説明していきます。
「プロセス」とは
まずは「プロセス」についてです。「プロセス」とは、簡単にいうとアプリケーションを実行するプログラムのことです。
例えば、何かのアプリケーションが起動する時、そのアプリケーションを実行するための環境が必要ですよね。その必要な環境を用意するために、OSはPCのメモリに一定の領域を確保します。そして「プロセス」はそのOSによって確保されたメモリ領域を利用してアプリケーションを起動するのです。
つまり、「プロセス」はアプリケーションを実行するプログラムであり、OSによって一定のメモリ領域を確保されているのです。
まだ若干分かりづらいかも知れませんが、ここは一旦、次の「スレッド」に進んでみましょう。
「スレッド」とは
「スレッド」も、先ほど説明した「プロセス」と同じように、プログラムの実行単位ではあるのですが、「プロセス」よりも細かいです。
実際に、1つの「プロセス」の中には1つ以上の複数の「スレッド」が存在します。スレッドもプロセスと同様に、一定のメモリ領域を確保するのですが、スレッドが確保する領域は、あくまでも既にプロセスが確保しているメモリ領域の内部なのです。
イメージとしてはこの図が結構分かりやすいのではないでしょうか。
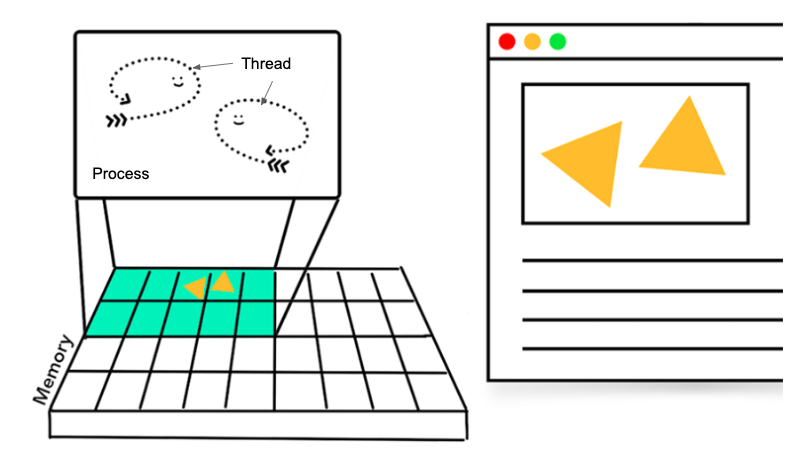
参考:Inside Look At Modern Web Browser
ブラウザアーキテクチャ
みなさんご存知の通り、ブラウザには様々な種類があります。
- Google Chrome
- Firefox
- Microsoft Edge
- Internet Explorer
- Safari
- ...
上記の通り、ブラウザにはたくさんの種類がありますが、大きく分けると二つの**「ブラウザアーキテクチャ」**に分類されます。
それが**「シングルプロセス」なアーキテクチャと「マルチプロセス」**なアーキテクチャです。
それぞれを簡単に説明すると、こんな感じです。
- シングルプロセス:立ち上がるプロセスは一つ、内部で複数ものスレッドが動く
- マルチプロセス:立ち上がるプロセスが複数、各プロセスで数個のスレッドが動く
ちなみに、このブラウザアーキテクチャですが、ブラウザは各ベンダーがそれぞれ独立して開発しているため、いわゆるデファクトスタンダード的なブラウザアーキテクチャは存在していません。
Chromeは「マルチプロセスアーキテクチャ」
そして、本記事の対象である「Google Chrome」はマルチプロセスなアーキテクチャを採用しています。
つまり、皆さんがいつも通り、PCで「Google Chrome」を起動すると、内部では複数のプロセスが立ち上がり、それぞれのプロセス対してメモリ領域が割り当てられているのです。
Google Chromeのプロセスには、以下のようなプロセスがあります。
- ブラウザプロセス:アドレスバーや「進む/戻る」ボタン、ブックマークの制御。ネットワークやファイルアクセス等の見えない部分の制御。
- レンダリングプロセス:各タブ内に表示されているWebページの全ての制御。名前の通り「レンダリング」はこの部分が担当。
- プラグインプロセス:flash等、Webサイトで利用されているプラグインに関する制御。
- GPUプロセス:GPUタスクを制御。
- エクステンションプロセス:拡張機能に関することを制御。
- ...
このように、マルチプロセスアーキテクチャというだけあって、様々なプロセスが存在するのですが、今回重要なプロセスとしては**「ブラウザプロセス」と「レンダリングプロセス」**なので、とりあえずはそこだけ注目していただけたらなと思います。
「マルチプロセスアーキテクチャ」のメリットとデメリット
先ほど、「シングルプロセス」と「マルチプロセス」の二つのブラウザアーキテクチャを紹介しましたが、もちろんそれぞれに良い点と悪い点が存在します。
今回はGoogle Chromeのマルチプロセスアーキテクチャが対象なので、そのメリットとデメリットを簡単に紹介します。
メリット
- 一つのプロセスがクラッシュしてしまっても、そもそも使っているメモリ領域が異なるため、別のプロセスは生き続ける。(=ブラウザが死にづらい)
- プロセスごとに権限管理できるため、セキュリティ面で安全。
デメリット
- 同じアプリケーションでも異なるプロセスなため、アプリ内で共通利用しているインフラを各プロセスで共有できず、メモリの消費量が多くなってしまう。
ちなみにGoogle Chromeでは、この「メモリの消費量が多くなってしまう」というデメリットに対して、次のような策を講じています。
PCのハードウェアが強力な場合は、メモリを贅沢に利用し、各プロセスを疎結合にすることで、アプリケーションとしての安定性を保ちます。
しかし逆に、利用できるリソースが制限されているような、ハードウェアがさほど強力ではないPCの場合は、基本的にはタブごとに別々に起動するプロセスを、ドメインが一緒の別タブの場合はプロセスを共有するなどして、利用するリソースを節約しています。
モダンWebブラウザの画面描画の仕組み
さて、これまで「Webブラウザの仕組みを知るための予備知識」として色々と書いてきましたが、いよいよここからがメインの箇所となります。
これまで紹介してきた予備知識を活用して、「ブラウザの**"どの"プロセスが"どのように"**働くことで、リクエスト〜画面描画までを行っているのか」というポイントに着目しながら解説していきます。
大きく以下の二つのセクションに分けて、順を追って解説していきます。
- 「アドレスバーにURLを入力〜ブラウザがレスポンスを受け取る」
- 「ブラウザがレスポンスを受け取る〜画面描画(レンダリング)」
1. アドレスバーにURLを入力してからブラウザがレスポンスを受け取るまで
まず、一つ目のセクションとしては**「アドレスバーにURLを入力してEnterキーを押下してから、ブラウザがWebサーバからレスポンスを受け取るまで」**についてです。
もう少し具体的なステップとしては、以下の通りです。
- アドレスバーに入力された値が「検索ワード」か「URL」かを判断
- (URLが入力されたテイ)URLの名前解決(DNSサーバに問い合わせ)
- 返却されたIPアドレスに対してリクエストを送信
- レスポンスを受け取り、適切なプロセスにパス
まず最初の起点となるのは「ブラウザプロセス」
一番初めの「URLをアドレスバーに入力してEnterキーを押下」というイベントをキャッチするのは**「ブラウザプロセス」**です。
先ほども簡単に紹介した通り、「ブラウザプロセス」というのは、『アドレスバーや「進む/戻る」ボタン、ブックマークの制御。ネットワークやファイルアクセス等の見えない部分の制御。』を行うプロセスです。
そしてこの「ブラウザプロセス」の中では複数のプロセスが動作しています。
それが、主に以下の3つのスレッドです。
- UIスレッド:アドレスバーやボタンの表示
- ネットワークスレッド:インターネット経由で受け取ったデータの処理
- ストレージスレッド:ファイル等へのアクセスを制御
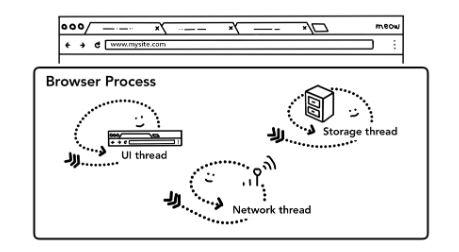
参考:Inside Look At Modern Web Browser
まず一番はじめに、「アドレスバーにURLが入力されてEnterキーを押下」されたタイミングで、UIスレッドが「この入力された値がURLなのか検索ワードなのか」を判断します。
そこで、検索ワードが入力されていた場合は、検索エンジンに値を投げ、URLが入力された場合はそのURLが示す場所にアクセスを試みます。
もちろん本記事では後者の「URL」が入力されたテイで話を進めていきます。
そしてその次にUIスレッドはネットワークスレッドを呼び出し、入力されたURLのIPアドレスを求めてDNSサーバに問い合わせをします。そしてその後、返却されたIPアドレスに対してリクエストを送信します。
レスポンスが帰ってきたら「レンダリングプロセス」へ
そして、Webサーバからレスポンスが返却されたら、まずはレスポンスヘッダーの「Content-type」を読み、返却されたデータがどういったタイプなのかを判断します。
そしてそのレスポンスの中身がHTMLだった場合は、レスポンスを受け取ったブラウザプロセスのネットワークスレッドがUIスレッドに対して、データを受け取った旨を通知し、UIスレッドが「レンダリングプロセス」を探しにいきます。
そして、その後IPC(異なるプロセス間で通信する方法)を利用して、「ブラウザプロセス」から「レンダリングプロセス」へとデータが渡されます。
また、逆にレスポンスの中身がzipファイルなどのHTML以外のファイルだった場合は、そもそもダウンロードのリクエストだったということなので、レスポンスは「ダウンロードマネージャー」に渡されます。
ちなみに、このレスポンスを受け取った段階で、レスポンスやドメインの安全性チェックも行われます。
2. 受け取ったレスポンスを画面描画するまで
それでは、次に「レンダリングプロセス」に渡されたレスポンスが、画面描画までにどのように処理されているのか、という部分です。
「レンダリングプロセス」がになっている役割を簡単にまとめると、「HTML/CSS/JavaScriptファイルをユーザが操作可能なWebページに変換すること」です。
「レンダリングプロセス」では基本的に「メインスレッド」上でソースコードを制御していますが、Web WorkerやService Workerを利用している場合には「ワーカースレッド」が使われたり、後にも登場しますが、「コンポジタースレッド」や「ラスタースレッド」もレンダリングプロセス内で動作しています。
そもそも「レンダリング」ってなんだっけ?
「レンダリング」という言葉は、フロントを触る機会が多いとよく耳にする言葉ですが、なんとなくでしか理解していない方のために、いったんここで簡単に説明しておきます。
**「レンダリング」**とは、HTMLやCSSといった文字データを、皆さんがブラウザでよく見るようなWebページとして描画するまでの過程をまとめて「レンダリング」と呼びます。
つまりは、その名の通り「レンダリングプロセス」が行っていることは、細かく色々とあるけれど、要は「レンダリング(=HTMLファイルをWebページとして画面に描画する)」を行っているのです。
「レンダリングプロセス」が画面描画をするために行っていること
Webサーバからのレスポンスをブラウザプロセスから受け取ったレンダリングプロセスは、次の5つの工程を経て画面にWebページを描画します。
- パース(解析):HTMLの解析。DOMツリーの構築。
- スタイルの計算:CSSの解析。
- レイアウト:レイアウトツリーの構築。
- ペイント:表示順を決定。
- コンポジット:レイヤーごとに別々にラスタライズし、それらを組み合わせ(コンポジット)て画面に表示。
これら各工程のより詳細な処理内容については、末尾の『参考』欄を参照していただきたいところですが、新人フロントエンドエンジニアにとっては少々難しい文章なので、以下で簡単にポイントをまとめました。
パース(解析)
まず一番はじめは**「パース」**という工程です。
この工程ではまず、レンダリングプロセスの「メインスレッド」上で受け取った文字列のHTMLを解析し、DOM(Document Object Model)に変換します。
ちなみにDOMとは、システムが扱いやすいツリー状のオブジェクト(いわゆるDOMツリー)のことです。
この「パース」の段階では、Webサーバがレスポンスとして受け取った情報が次の順番で変換されていきます。
- バイト:マシンが理解できる言葉
- 文字列:UTF-8などの形式でエンコード
- トークン:タグ等のような、個別に固有の意味をもつ文字列
- ノード:プロパティやルールをもったオブジェクト
- オブジェクトモデル(DOMツリー):ツリー状のデータ構造
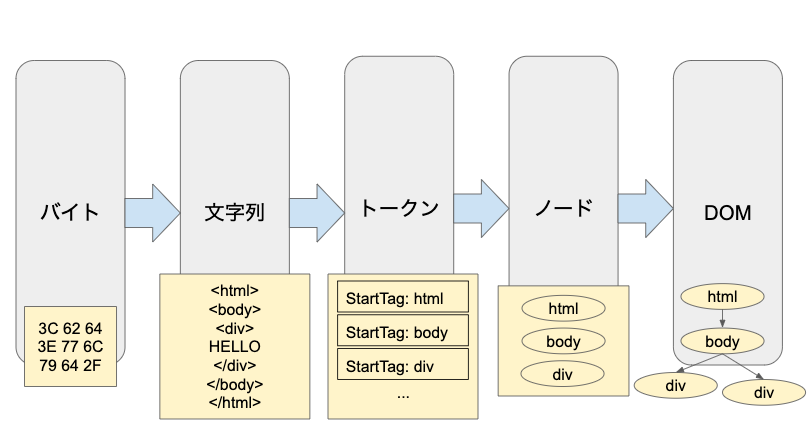
また、HTMLで読み込んでいるCSSやJavaScriptといった別ファイルのリソースについては、HTMLを解析する段階で、該当するタグに遭遇したタイビングでで読み込まれます。
CSSファイルの解析については次で解説します。
スタイルの計算
上の過程でCSSファイルに遭遇したら、この工程で解析されます。
CSSファイルもHTML同様に、解析されると、CSSOM(CSS Object Model)と呼ばれる、DOMツリーと同じようなツリー状のオブジェクトを構築していきます。
ここでCSSが解析される時も、CSSはHTMLの時と同様、『バイト→文字列→トークン→ノード→オブジェクトモデル』の順番でCSSOMを構築していきます。
そして、最終的にはこのCSSツリーとDOMツリーが合わさることによって、各ノードに対してスタイルが割り当てられるのです。
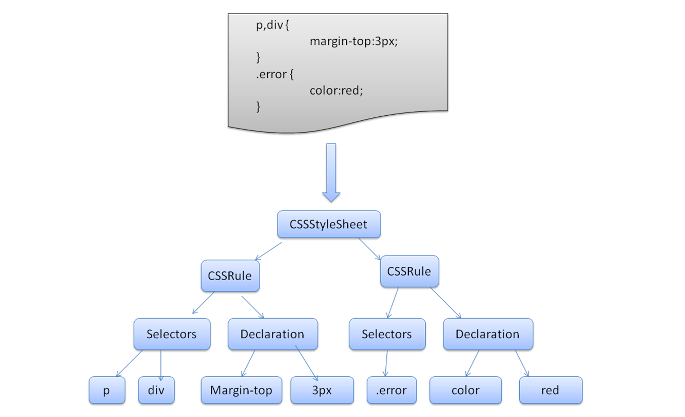
※ちなみに、開発者側でCSSを用意しなかった場合には、ブラウザデフォルトのCSSが適用されます。
レイアウト
さて、現段階では、文章の構造と各要素のスタイルが分かりましたが、画面描画するのに、これらの情報だけではまだ不十分で、各要素のサイズや配置を決定する必要があります。
そしてこの**「レイアウト」でという工程では、先ほどのDOMツリーとCSSOMを組み合わせ、「レンダリングツリー」**という一つのツリー状のオブジェクトを構築し、それを利用して要素の配置やサイズといった情報を計算していきます。
ただし、ここで「レンダリングツリー」に含まれるのは基本的に視覚的に見える要素のみです。
つまり、{display: none}のような視覚的には見えない要素は、ここで構築されるレンダリングツリーには含まれないのです。
大したことではないように思われるかもしれませんが、こういった微妙な違いはパフォーマンスに大きく影響するため、意外と大切な箇所だったりします。
少し余談ですがが、Vue.jsのv-ifとv-showの違いも、このレンダリングツリーに含まれる/含まれないといった違いです。
ペイント
次のペイントの工程では、z-indexといったような手前か奥かの方向での表示順が決定され、レンダリングツリーが画面サイズに応じたピクセルに落とし込まれます。
ここで生成される表示順を**「ペイントレコード」**と呼んだりするようです。
コンポジット
最後の工程である**「コンポジット」**では、最終的な画面への描画処理を行います。
「これまでに作られたレンダリングツリーとかペイントレコードを描画して終わりじゃないの?」と思うかもしれませんが、少し違います。
この最後の工程では「コンポジット(合成)」という一手間が加えられています。
それでは、いったい最後の**「コンポジット」とは何か**というと、『ページをいくつかの層に分け、別々にラスタライズし、コンポジタースレッドでそれらを組み合わせる』という手法です。
ちなみに**「ラスタライズ」**とは、点と線を数値化して作られた「ベクター画像」を点の集まりである「ビットマップ画像」に変換することです。(Webデザイナーの用語としてよく使われています。)
以前の工程で作成されたレンダリングツリーをもとに、ページをいくつかの層に分けた**「レイヤーツリー」**という、レンダリングツリーよりも粒度が大きいツリー状のオブジェクトが生成されます。
そして、レイヤーツリーが生成された段階で、いよいよ作業場がレンダリングプロセスのメインスレッドから、同じくレンダリングプロセス内の**「コンポジタースレッド」**に移動します。
この「コンポジタースレッド」でレイヤーツリーの各レイヤーごとにラスタライズが行われ、描画するために必要なレイヤーを組み合わせたものが、IPCでブラウザプロセスに送信され、最終的にGPUに送られることで画面に描画されます。
最後のコンポジットではメインスレッドを必要としない、ということが大きな利点の一つです。
最後に
最後までご覧いただきありがとうございました。
少しでもお役に立てるような知識が共有できたとしたら幸いです。
最後に、下記参考サイトはどれも良質な記事だったので、ぜひ覗いてみてください。