1. はじめに
TwitterのモバイルWeb (Twitter Lite) は、今年の2月頃のリニューアルによってReactアプリ化されたのですが、今回ツールを使い、この現在のTwitter公式サイトのRedux Store設計を調べてみることにしました。少し昔のこちらのmediumの記事にインスパイアされました。。
2. 準備
react-devtoolsでReduxのStoreを覗き見ることができます。今回Chromeのextensionを使っています。
https://github.com/facebook/react-devtools
こちらとても便利で、actionのdispatchまでブラウザからできてしまいます。
インストールしたら、ChromeのDeveloper Toolsを開き、consoleに
$r.store.getState();
と入力してみましょう。storeツリーが返ってきます。
余談ですが、mastodonはReact+Reduxかつopen sourceなので、mastodonの適当なインスタンスのページをwebで開き、このツールでstoreを眺めてみたり、勝手にactionをdispatchしてみたりするだけでも、なかなか楽しいです。
3. みてみる
適当に見て回って、naming conventionやデータ構造をあれこれ調べてみるだけでもいろいろ参考になります。
データの実体は正規化して1箇所に
例えば、アプリの根幹であるtweetデータの実体はすべてentities.tweetsという場所に入っています。
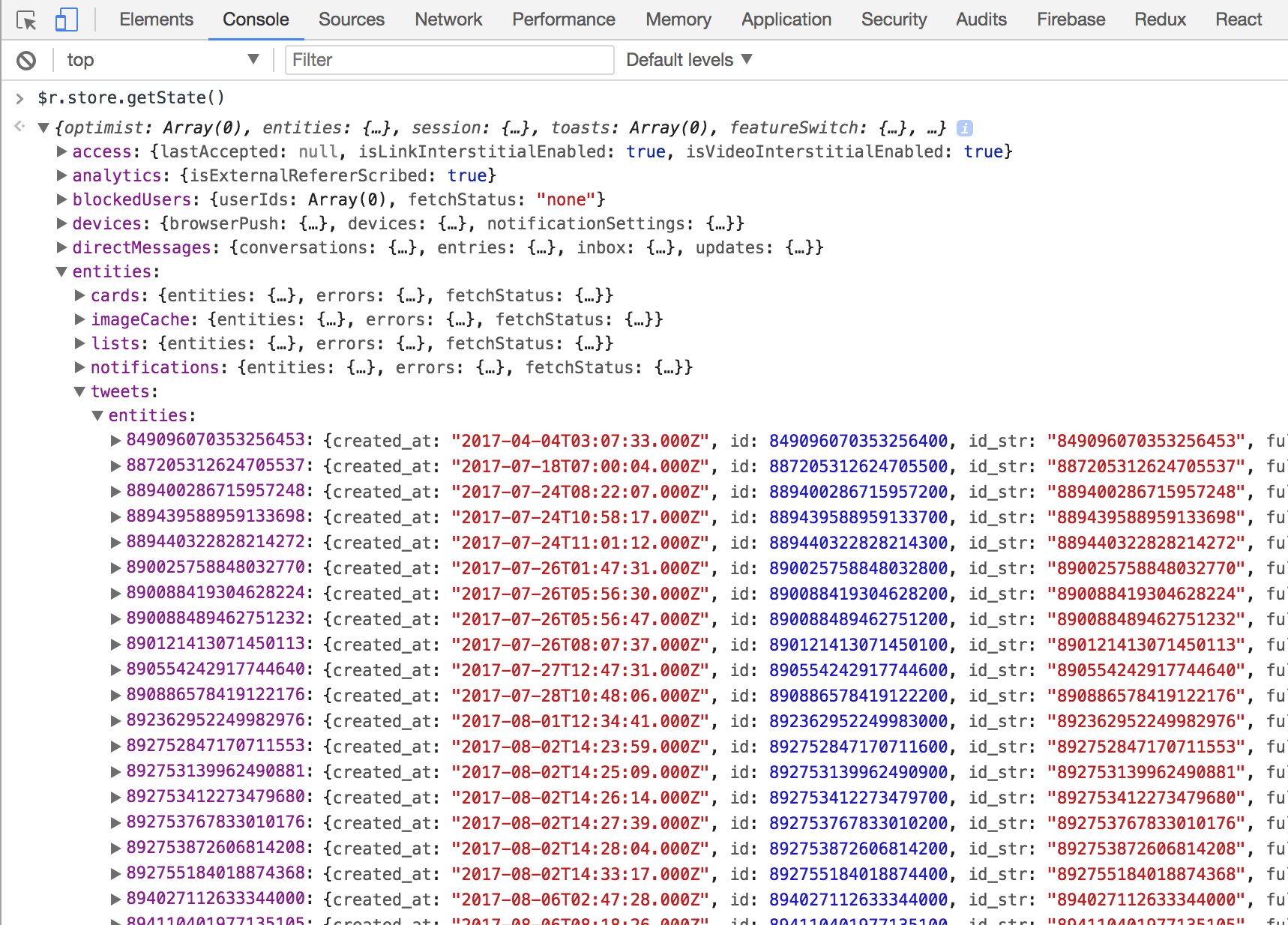
公式ブログによると、
API response data is first processed by Normalizr – which allows us to de-duplicate items and transform data into more efficient forms – before being sent to various Redux modules used for fetching, storing, and retrieving remote and local data.
とのことなので、クライアント側でTwitter APIを叩いて受け取ったresponseをnormalizrというライブラリを使ってnormalizeした後、こちらのentities以下に保存しているようです。なので、twitter API response由来の部分はsnake_caseになっていて、その他のcamelCaseになっているkey名との間に一貫性が無いように思えますが、気にしていない(または敢えて区別するためにそのままにしている)のがちょっと独特に思えました。
また、タイムライン(ホーム画面)は、urt.homeという場所を参照しています。entitiesにはtweetの実データは入っておらず、entryId(tweetのid)の配列が入っており、これをキーにしてentities.tweetsからデータを取得する設計になっています。
例えば自分のtweetが誰かにfavoriteされた場合、タイムラインタブと通知タブの両方に同じtweetを表示することになりますが、同じデータ(似たようなデータ)を複数の箇所に重複して持たせるのではなく、IDのみを教えて常に同じデータを参照させるようになっています。これはreduxの原則である「Single source of truth」に通じており、理にかなった考え方です。
cursorをtimelineのentityと同一視して扱っている
次に、そのurt.home以下を見てみましょう。
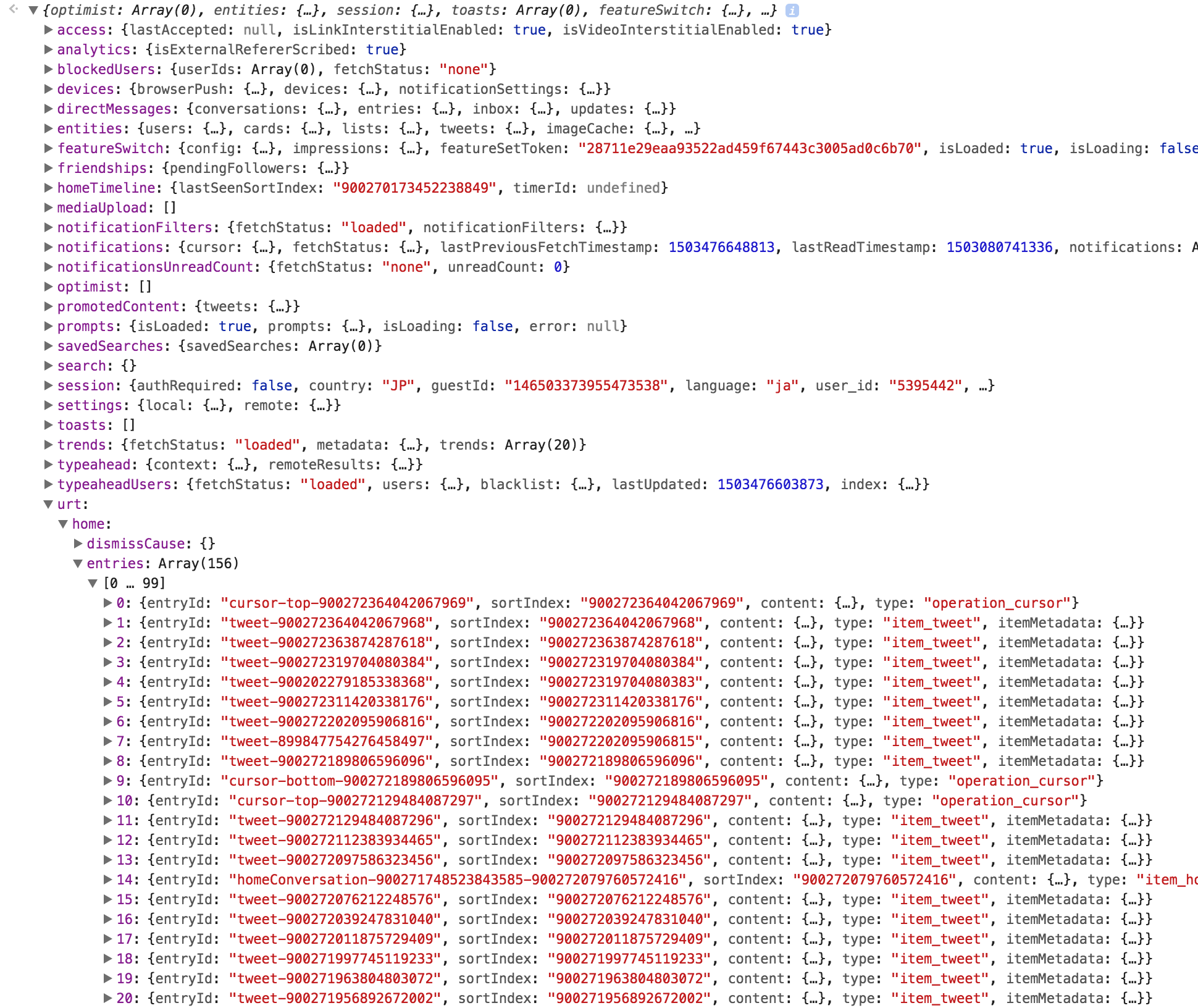
cursor-top-で始まるIDとcursor-bottom-で始まるIDがこのhome.entitiesの中に入っている(しかも直前・直後のtweetと1つ違いのIDが振られている)のが興味深いです。Twitter APIでのcursorを示していると思われ、実際のタイムライン上に表示される情報ではないですが、このようにメタ情報を同じ配列に入れて扱うことで、ループ処理の途中での処理を扱いやすくすることを狙っているのでしょうか。
面白いことに、リリース当初はtimelineのデータ構造は現在とかなり異なっており、昔はhometimelinesというkeyの下にcursorとtimelinesがぶらさがっていました。リリースから約1年半ですが、データの持ち方の根幹に関わるような部分の大手術をどこかで少なくとも1回行っていると思われます。Twitterのようなビジネスインパクトの非常に大きなサービスといえども(だからこそ?)、守りに入らず攻めの改善を日々行っているのだということが垣間見え、我々も見習わなければと思わされる今日このごろです。
ここにあるhomeConversation-で始めるIDは、replyの集まりを1つの会話として扱っているブロックです。このIDをもとにしてさらに子のtweetを引いてきて、画面を構成しています。同様に、promotedTweet-などのプロモーション広告もこの階層に同じデータ構造を持って並びます。
データの取得状態をentity単位で持っている
最後に、引用したブログでも触れられていますが、entities配下のデータは共通のデータ構造を持っていて、その中にfetchStatusというキーがあります。これを開いてみると、各entityのIDをkeyにして、valueでfetch状態を示しています。ブログでは、このようなentity単位での状態管理をしている理由として、
- 同じentityを要求するリクエストをサーバへ二重に送信しないようにするため(
loadingなどの状態が他にあると推測されるが、表示済みのentityはすべてloadedとなっている) - entityに含まれる詳細な情報を取得する前にentityのrenderを開始可能にするため
が考えられるとしています。このデータはAPIから返ってきたデータとは性質が異なるため、entities本体のデータと切り離し、かつ同じデータ構造で管理するのは妥当であると言えます。また、cursorを使ってデータを一定個数ずつ取得するAPIの性質上からも、あえて細かく状態管理して可視化したほうがデバッグもしやすくなりそうですし、色々と都合が良いのでしょう。

4. おわり
以上です。
浅い部分にしか触れられていませんが、まだまだ色々知見が詰まっていると思いますし、他のサービスと比較してみても面白いかもしれません。