今回何をするか
自分が興味があり、かつ割とそれなりに知識があるものを実装したいと思います。
僕の専攻は一応自然言語処理で学部論文では深層学習で文書生成やってたんで、
Pytorchで練習がてら自動文書生成していきます。
文書生成器はEmbedding層、LSTM層、線形層を重ねたものとします。
LSTMのレイヤ数など各ハイパーパラメータはコマンドラインから指定できるものを作ります。
訓練に使うデータセットとかいろいろ
訓練に利用するデータセットは長岡技術科学大学自然言語処理研究室の「SNOW T15:やさしい日本語コーパス」を使わせていただきます。
長岡技術科学大学自然言語処理研究室
http://www.jnlp.org/SNOW/T15
5万文の日英対訳+やさしい日本語のパラレルコーパスで超絶便利です。
xlsx形式で提供されているので、あらかじめcsv形式に変換します。
また、自動文章生成ですので、やさしい日本語と英語は用いません。
形態素解析
自然言語処理といえば形態素解析です。形態素解析は与えられた生の文章を形態素に分割します。
形態素解析でしばしば問題となるのが、OOV(Out Of Vocab)です。深層学習の出力次元は出力する可能性となるコーパスに大きさに依存しており、大きくなればなるほどメモリを圧迫します。
そのため、多くの人がコーパス内の低頻度語をUNK(unknown)として登録したり、それ以外にいろいろと工夫したりするんですね。
ここでは、Sentencepieceを用います。
Sentencepieceは教師なし学習により、OOVなしで指定した単語数に収まるように形態素解析を行ってくれる超絶便利なツールです。
詳しい仕様なんかは引用しているURLを参照してください。
これを用いてOOVなしでデータセットを8000単語の範囲で形態素解析します。
モデル定義
まあ普通のLSTMなので語ることが特にないです。
問題点などがあれば指摘してもらえると大喜びします。
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTM(nn.Module):
def __init__(self, source_size, hidden_size, batch_size, embedding_size, num_layers):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.source_size = source_size
self.batch_size = batch_size
self.num_layers = num_layers
self.embed_source = nn.Embedding(source_size, embedding_size, padding_idx=0)
self.embed_source.weight.data.normal_(0, 1 / embedding_size**0.5)
self.lstm_source = nn.LSTM(self.hidden_size, self.hidden_size, num_layers=self.num_layers,
bidirectional=True, batch_first=True)
self.linear = nn.Linear(self.hidden_size*2, self.source_size)
def forward(self, sentence_words, hx, cx):
source_k = self.embed_source(sentence_words)
self.lstm_source.flatten_parameters()
encoder_output, (hx, cx) = self.lstm_source(source_k, (hx, cx))
prob = F.log_softmax(self.linear(encoder_output), dim=1)
_, output = torch.max(prob, dim = -1)
return prob, output, (hx, cx)
def init_hidden(self, bc):
hx = torch.zeros(self.num_layers*2, bc, self.hidden_size)
cx = torch.zeros(self.num_layers*2, bc, self.hidden_size)
return hx, cx
普通ですね。
訓練&ローダー
次に訓練用のコードと、データセットのローダを作ります。
ちなみにindex.modelはsentencepieceで作成した形態素解析用のモデルです。
検証はせずに訓練が終わったらいきなりテストする感じでいきます。
訓練はある日本語文を入力して、それと全く同じ文章を出力することを学習します。
テスト時には、テスト文章の最初の一単語のみを入力し、残りは貪欲法で時系列ごとに出力していきます。
多分これで自動的に文書が生成できるはず・・・
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import argparse
from loader import Dataset
import torch.optim as optim
import sentencepiece as spm
from utils import seq_to_string, to_np, trim_seqs
import matplotlib.pyplot as plt
from torchviz import make_dot
from model.LSTM import LSTM
def make_model(source_size, hidden_size, batch_size, embedding_size=256, num_layers=1):
model = LSTM(source_size, hidden_size, batch_size, embedding_size, num_layers)
criterion = nn.NLLLoss(reduction="sum")
model_opt = optim.Adam(model.parameters(), lr=0.0001)
return model, criterion, model_opt
def data_load(maxlen, source_size, batch_size):
data_set = Dataset(maxlen=maxlen)
data_num = len(data_set)
train_ratio = int(data_num*0.8)
test_ratio = int(data_num*0.2)
res = int(data_num - (train_ratio + test_ratio))
train_ratio += res
ratio=[train_ratio, test_ratio]
train_dataset, test_dataset = torch.utils.data.random_split(data_set, ratio)
dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
del(train_dataset)
del(data_set)
return dataloader, test_dataloader
def run_epoch(data_iter, model, criterion, model_opt, epoch):
model, criterion = model.cuda(), criterion.cuda()
model.train()
total_loss = 0
for i, data in enumerate(data_iter):
model_opt.zero_grad()
src = data[:,:-1]
trg = data[:,1:]
src, trg = src.cuda(), trg.cuda()
hx, cx = model.init_hidden(src.size(0))
hx, cx = hx.cuda(), cx.cuda()
output_log_probs, output_seqs, _ = model(src, hx, cx)
flattened_log_probs = output_log_probs.view(src.size(0) * src.size(1), -1)
loss = criterion(flattened_log_probs, trg.contiguous().view(-1))
loss /= (src.size(0) * src.size(1))
loss.backward()
model_opt.step()
total_loss += loss
if i % 50 == 1:
print("Step: %d Loss: %f " %
(i, loss))
mean_loss = total_loss / len(data_iter)
torch.save({
'model': model.state_dict()
}, "./model_log/model.pt")
dot = make_dot(output_log_probs ,params=dict(model.named_parameters()))
dot.format = 'png'
dot.render('image')
return model, mean_loss
def depict_graph(mean_losses, epochs):
epoch = [i+1 for i in range(epochs)]
plt.xlim(0, epochs)
plt.ylim(1, mean_losses[0])
plt.plot(epoch, mean_losses)
plt.title("loss")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
def test(model, data_loader):
model.eval()
all_output_seqs = []
all_target_seqs = []
with torch.no_grad():
for data in data_loader:
src = Variable(data[:,:-1])
src = src.cuda()
del(data)
input_data = src[:,:2]
hx, cx = model.init_hidden(input_data.size(0))
for i in range(18):
hx, cx = hx.cuda(), cx.cuda()
output_log_probs, output_seqs, hidden = model(input_data, hx, cx)
hx, cx = hidden[0], hidden[1]
input_data = torch.cat((input_data, output_seqs[:,-1:]), 1)
all_output_seqs.extend(trim_seqs(input_data))
out_set = (all_target_seqs, all_output_seqs)
return out_set
if __name__ == "__main__":
sp = spm.SentencePieceProcessor()
sp.load("./index.model")
source_size = sp.GetPieceSize()
parser = argparse.ArgumentParser(description='Parse training parameters')
parser.add_argument('--do_train', type=str, default='False')
parser.add_argument('--batch_size', type=int, default=256)
parser.add_argument('--maxlen', type=int, default=20)
parser.add_argument('--epochs', type=int, default=50)
parser.add_argument('--hidden_size', type=int, default=128)
parser.add_argument('--embedding_size', type=int, default=128)
parser.add_argument('--num_layers', type=int, default=1)
args = parser.parse_args()
model, criterion, model_opt = make_model(source_size, args.hidden_size, args.batch_size, args.embedding_size, args.num_layers)
data_iter, test_data_iter = data_load(args.maxlen, source_size, args.batch_size)
mean_losses = []
if args.do_train == "True":
for epoch in range(args.epochs):
print(epoch+1)
model, mean_loss = run_epoch(data_iter, model, criterion, model_opt, epoch)
mean_losses.append(mean_loss.item())
depict_graph(mean_losses, args.epochs)
else:
model.load_state_dict(torch.load("./model_log/model.pt")["model"])
out_set = test(model, data_iter)
true_txt = out_set[0]
out_txt = out_set[1]
with open("true.txt", "w", encoding="utf-8") as f:
for i in true_txt:
for j in i:
f.write(sp.IdToPiece(int(j)))
f.write("\n")
with open("out.txt", "w", encoding="utf-8") as f:
for i in out_txt:
for j in i:
f.write(sp.IdToPiece(int(j)))
f.write("\n")
import torch
import numpy as np
import csv
import sentencepiece as spm
class Dataset(torch.utils.data.Dataset):
def __init__(self, maxlen):
self.sp = spm.SentencePieceProcessor()
self.sp.load("./index.model")
self.maxlen = maxlen
with open('./data/parallel_data.csv', mode='r', newline='', encoding='utf-8') as f:
csv_file = csv.reader(f)
read_data = [row for row in csv_file]
self.data_num = len(read_data) - 1
jp_data = []
for i in range(1, self.data_num):
jp_data.append(read_data[i][1:2]) #難しい日本語文
self.en_data_idx = np.zeros((len(jp_data), maxlen+1))
for i,sentence in enumerate(jp_data):
self.en_data_idx[i][0] = self.sp.PieceToId("<s>")
for j,idx in enumerate(self.sp.EncodeAsIds(sentence[0])[:]):
self.en_data_idx[i][j+1] = idx
if j+1 == maxlen-1: #末尾なら終了記号
self.en_data_idx[i][j+1] = self.sp.PieceToId("</s>")
break
if j+2 <= maxlen-1:
self.en_data_idx[i][j+2] = self.sp.PieceToId("</s>")
if j+3 < maxlen-1:
self.en_data_idx[i][j+3:] = self.sp.PieceToId("<unk>") #面倒なんでsentencepieceを学習すると発生するunkをpad代わりにしている
else:
self.en_data_idx[i][j+1] = self.sp.PieceToId("</s>")
if j+2 < maxlen-1:
self.en_data_idx[i][j+2:] = self.sp.PieceToId("<unk>")
def __len__(self):
return self.data_num
def __getitem__(self, idx):
en_data = torch.tensor(self.en_data_idx[idx-1][:], dtype=torch.long)
return en_data
結果
とりあえず100エポックくらい回してみる。
レイヤとかハイパーパラメータは過学習を防ぐために小さ目がいいのかわからなすぎたので、
大きすぎない程度に設定してます。
これが学習時のlossです。
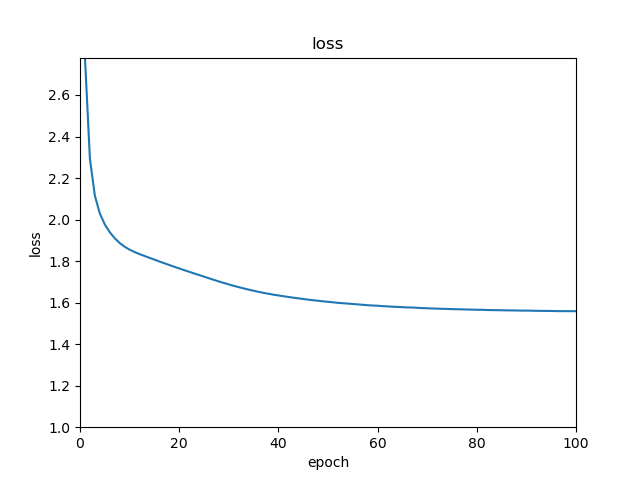
割と順調に下がってはいますが、途中から微妙ですね。
もうちょいハイパーパラメータもなんとかしたほうがいいかも。
で、以下が実際に出力した文章の一例です。
- ▁今のところはいつも家にいたしをしれて試験に曲
- ▁私の姉はは私に満足らずよくその仕事を
- ▁お金のために寝てように偶然わせグので誕生日に警察官
( ^ω^)・・・
ダメダメですやん・・・
結論とかいろいろ
まずモデルの定義がダメなのかもしれない。
Seq2seqのほうが向いているのかな?機会があれば試します。
ともあれいままでLSTMモデルの裸一貫(Embbedingあるけど)で訓練とかしたことなかったので、
なんのタスクするかとか考えるのはまあまあ楽しかったです。
修論では、基本的にTransformerなんかを使うんで今後は実装についてとか論文について紹介などもたまにしていこうかなと思ってます。