概要
windowsでTensorFlowやってみた。
生tensorflowで強化学習のデモ作って見た。
環境は、OpenAiGymでフルーツバスケット。
確認用のサンプルコード、載せる。
写真
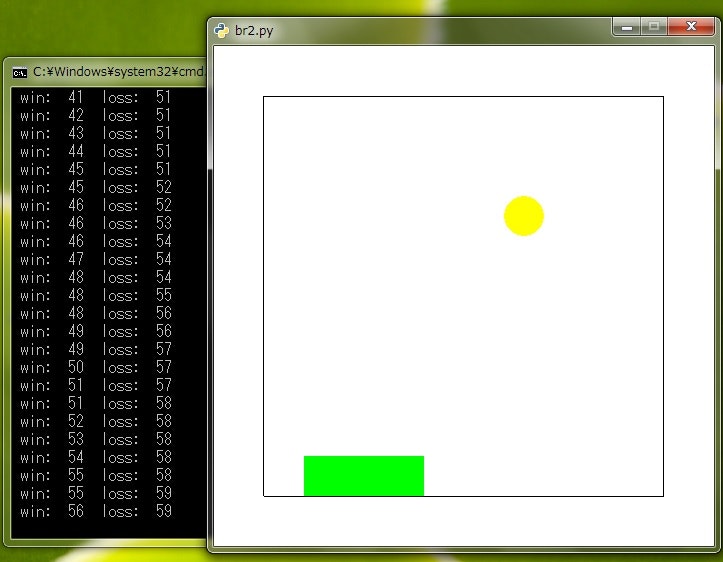
環境
windows 7 sp1 64bit
anaconda3
tensorflow 1.0
OpenAi Gym 0.5
確認用のサンプルコード
from __future__ import print_function
import math
import sys
import gym
import gym.spaces
import numpy as np
from gym import core, spaces
from gym.utils import seeding
from numpy import sin, cos, pi
import time
import random
import tensorflow as tf
import os
from collections import deque
class FBEnvironment(core.Env):
metadata = {
'render.modes': ['human', 'rgb_array'],
'video.frames_per_second' : 30
}
def __init__(self):
self.viewer = None
self.gridSize = 10
self.nbStates = self.gridSize * self.gridSize
self.state = np.empty(3, dtype = np.uint8)
def drawState(self):
canvas = np.zeros((self.gridSize, self.gridSize))
canvas[self.state[0] - 1, self.state[1] - 1] = 1
canvas[self.gridSize - 1, self.state[2] - 1 - 1] = 1
canvas[self.gridSize - 1, self.state[2] - 1] = 1
canvas[self.gridSize - 1, self.state[2] - 1 + 1] = 1
return canvas
def getState(self):
stateInfo = self.state
fruit_row = stateInfo[0]
fruit_col = stateInfo[1]
basket = stateInfo[2]
return fruit_row, fruit_col, basket
def getReward(self):
fruitRow, fruitColumn, basket = self.getState()
if (fruitRow == self.gridSize - 1):
if (abs(fruitColumn - basket) <= 1):
return 1
else:
return -1
else:
return 0
def isGameOver(self):
if (self.state[0] == self.gridSize - 1):
return True
else:
return False
def updateState(self, action):
if (action == 1):
action = -1
elif (action == 2):
action = 0
else:
action = 1
fruitRow, fruitColumn, basket = self.getState()
newBasket = min(max(2, basket + action), self.gridSize - 1)
fruitRow = fruitRow + 1
self.state = np.array([fruitRow, fruitColumn, newBasket])
def observe(self):
canvas = self.drawState()
canvas = np.reshape(canvas, (-1, self.nbStates))
return canvas
def _reset(self):
initialFruitColumn = random.randrange(1, self.gridSize + 1)
initialBucketPosition = random.randrange(2, self.gridSize + 1 - 1)
self.state = np.array([1, initialFruitColumn, initialBucketPosition])
return self.observe()
def _step(self, action):
self.updateState(action)
reward = self.getReward()
gameOver = self.isGameOver()
return self.observe(), reward, gameOver, {}
def _render(self, mode = 'human', close = False):
if close:
if self.viewer is not None:
self.viewer.close()
self.viewer = None
return
from gym.envs.classic_control import rendering
if self.viewer is None:
self.viewer = rendering.Viewer(500, 500)
self.viewer.set_bounds(-2.5, 2.5, -2.5, 2.5)
x = -1.8 + (self.state[1] - 1) * 0.4
y = 2.0 - (self.state[0] - 1) * 0.4
z = -1.8 + (self.state[2] - 1) * 0.4
transform0 = rendering.Transform(translation = (x, y))
transform1 = rendering.Transform(translation = (z, -1.8))
self.viewer.draw_circle(0.2, 20, color = (1, 1, 0)).add_attr(transform0)
self.viewer.draw_line((-2.0, 2.0), (2.0, 2.0), color = (0, 0, 0))
self.viewer.draw_line((-2.0, 2.0), (-2.0, -2.0), color = (0, 0, 0))
self.viewer.draw_line((2.0, 2.0), (2.0, -2.0), color = (0, 0, 0))
self.viewer.draw_line((-2.0, -2.0), (2.0, -2.0), color = (0, 0, 0))
self.viewer.draw_polygon([(-0.6, -0.2), (0.6, -0.2), (0.6, 0.2), (-0.6, 0.2)], color = (0, 1, 0)).add_attr(transform1)
return self.viewer.render(return_rgb_array = mode == 'rgb_array')
class Brain:
INITIAL_EPSILON = 1.0
FINAL_EPSILON = 0.01
EXPLORE = 1000.
OBSERVE = 100.
REPLAY_MEMORY = 50000
BATCH_SIZE = 50
GAMMA = 0.99
def __init__(self, n_action, n_width, n_height, state):
self.n_action = n_action
self.n_width = n_width
self.n_height = n_height
self.time_step = 0
self.epsilon = self.INITIAL_EPSILON
self.state_t = np.stack((state, state, state, state), axis = 1)[0]
self.memory = deque()
self.input_state = tf.placeholder(tf.float32, [None, len(self.state_t), self.n_width * self.n_height])
self.input_action = tf.placeholder(tf.float32, [None, self.n_action])
self.input_Y = tf.placeholder(tf.float32, [None])
self.rewards = tf.placeholder(tf.float32, [None])
self.global_step = tf.Variable(0, trainable = False)
self.Q_value, self.train_op = self.build_model()
self.saver, self.session = self.init_session()
def init_session(self):
saver = tf.train.Saver()
session = tf.InteractiveSession()
saver.restore(session, os.getcwd() + "/br1.ckpt")
return saver, session
def build_model(self):
n_input = len(self.state_t) * self.n_width * self.n_height
state = tf.reshape(self.input_state, [-1, n_input])
w1 = tf.Variable(tf.truncated_normal([n_input, 128], stddev = 0.01))
b1 = tf.Variable(tf.constant(0.01, shape = [128]))
w2 = tf.Variable(tf.truncated_normal([128, 256], stddev = 0.01))
b2 = tf.Variable(tf.constant(0.01, shape = [256]))
w3 = tf.Variable(tf.truncated_normal([256, self.n_action], stddev = 0.01))
b3 = tf.Variable(tf.constant(0.01, shape = [self.n_action]))
l1 = tf.nn.relu(tf.matmul(state, w1) + b1)
l2 = tf.nn.relu(tf.matmul(l1, w2) + b2)
Q_value = tf.matmul(l2, w3) + b3
Q_action = tf.reduce_sum(tf.multiply(Q_value, self.input_action), axis = 1)
cost = tf.reduce_mean(tf.square(self.input_Y - Q_action))
train_op = tf.train.AdamOptimizer(1e-6).minimize(cost, global_step = self.global_step)
return Q_value, train_op
def train(self):
minibatch = random.sample(self.memory, self.BATCH_SIZE)
state = [data[0] for data in minibatch]
action = [data[1] for data in minibatch]
reward = [data[2] for data in minibatch]
next_state = [data[3] for data in minibatch]
Y = []
Q_value = self.Q_value.eval(feed_dict = {
self.input_state: next_state
})
for i in range(0, self.BATCH_SIZE):
if minibatch[i][4]:
Y.append(reward[i])
else:
Y.append(reward[i] + self.GAMMA * np.max(Q_value[i]))
self.train_op.run(feed_dict = {
self.input_Y: Y,
self.input_action: action,
self.input_state: state
})
def step(self, state, action, reward, terminal):
next_state = np.append(self.state_t[1:, :], state, axis = 0)
self.memory.append((self.state_t, action, reward, next_state, terminal))
if len(self.memory) > self.REPLAY_MEMORY:
self.memory.popleft()
if self.time_step > self.OBSERVE:
self.train()
self.state_t = next_state
self.time_step += 1
def get_action(self, train = False):
action = np.zeros(self.n_action)
if train and random.random() <= self.epsilon:
index = random.randrange(self.n_action)
else:
Q_value = self.Q_value.eval(feed_dict = {
self.input_state: [self.state_t]
})[0]
index = np.argmax(Q_value)
action[index] = 1
if self.epsilon > self.FINAL_EPSILON and self.time_step > self.OBSERVE:
self.epsilon -= (self.INITIAL_EPSILON - self.FINAL_EPSILON) / self.EXPLORE
return action, index
def main(_):
env = FBEnvironment()
env.reset()
state = env.observe()
brain = Brain(3, 10, 10, state)
winCount = 0
loseCount = 0
while True:
isGameOver = False
env.reset()
currentState = env.observe()
while (isGameOver != True):
action, index = brain.get_action(True)
#print (index)
state, reward, gameOver, _ = env.step(index)
env.render()
brain.step(state, action, reward, gameOver)
isGameOver = gameOver
if (reward == 1):
winCount = winCount + 1
elif (reward == -1):
loseCount = loseCount + 1
time.sleep(0.1)
print (" win: ", winCount, " loss: ", loseCount)
if __name__ == '__main__':
tf.app.run()