概要
windowsでTensorFlowやってみた。
生tensorflowで強化学習のデモ作って見た。
環境は、フルーツバスケット。
確認用のサンプルコード、載せる。
写真
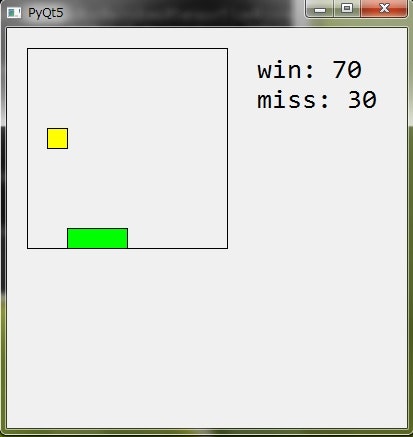
環境
windows 7 sp1 64bit
anaconda3
tensorflow 1.0
pyqt5
確認用のサンプルコード
import sys
from PyQt5.QtCore import *
from PyQt5.QtGui import *
from PyQt5.QtWidgets import *
import tensorflow as tf
import numpy as np
import random
import os
from collections import deque
class CatchEnvironment():
def __init__(self, gridSize):
self.gridSize = gridSize
self.nbStates = self.gridSize * self.gridSize
self.state = np.empty(3, dtype = np.uint8)
def getState(self):
stateInfo = self.state
fruit_row = stateInfo[0]
fruit_col = stateInfo[1]
basket = stateInfo[2]
return fruit_row, fruit_col, basket
def reset(self):
initialFruitColumn = random.randrange(1, self.gridSize + 1)
initialBucketPosition = random.randrange(2, self.gridSize + 1 - 1)
self.state = np.array([1, initialFruitColumn, initialBucketPosition])
return self.getState()
def isGameOver(self):
if (self.state[0] == self.gridSize - 1):
return True
else:
return False
def drawState(self):
canvas = np.zeros((self.gridSize, self.gridSize))
canvas[self.state[0] - 1, self.state[1] - 1] = 1
canvas[self.gridSize - 1, self.state[2] - 1 - 1] = 1
canvas[self.gridSize - 1, self.state[2] - 1] = 1
canvas[self.gridSize - 1, self.state[2] - 1 + 1] = 1
return canvas
def getReward(self):
fruitRow, fruitColumn, basket = self.getState()
if (fruitRow == self.gridSize - 1):
if (abs(fruitColumn - basket) <= 1):
return 1
else:
return -1
else:
return 0
def updateState(self, action):
if (action == 1):
acton = -1
elif (action == 2):
acton = 0
else:
acton = 1
fruitRow, fruitColumn, basket = self.getState()
newBasket = min(max(2, basket + acton), self.gridSize - 1)
fruitRow = fruitRow + 1
self.state = np.array([fruitRow, fruitColumn, newBasket])
def observe(self):
canvas = self.drawState()
canvas = np.reshape(canvas, (-1, self.nbStates))
return canvas
def act(self, action):
self.updateState(action)
reward = self.getReward()
gameOver = self.isGameOver()
return self.observe(), reward, gameOver, self.getState()
class Brain:
INITIAL_EPSILON = 1.0
FINAL_EPSILON = 0.01
EXPLORE = 1000.
OBSERVE = 100.
REPLAY_MEMORY = 50000
BATCH_SIZE = 50
GAMMA = 0.99
def __init__(self, n_action, n_width, n_height, state):
self.n_action = n_action
self.n_width = n_width
self.n_height = n_height
self.time_step = 0
self.epsilon = self.INITIAL_EPSILON
self.state_t = np.stack((state, state, state, state), axis = 1)[0]
self.memory = deque()
self.input_state = tf.placeholder(tf.float32, [None, len(self.state_t), self.n_width * self.n_height])
self.input_action = tf.placeholder(tf.float32, [None, self.n_action])
self.input_Y = tf.placeholder(tf.float32, [None])
self.rewards = tf.placeholder(tf.float32, [None])
self.global_step = tf.Variable(0, trainable = False)
self.Q_value, self.train_op = self.build_model()
self.saver, self.session = self.init_session()
def init_session(self):
saver = tf.train.Saver()
session = tf.InteractiveSession()
saver.restore(session, os.getcwd() + "/br1.ckpt")
return saver, session
def build_model(self):
n_input = len(self.state_t) * self.n_width * self.n_height
state = tf.reshape(self.input_state, [-1, n_input])
w1 = tf.Variable(tf.truncated_normal([n_input, 128], stddev = 0.01))
b1 = tf.Variable(tf.constant(0.01, shape = [128]))
w2 = tf.Variable(tf.truncated_normal([128, 256], stddev = 0.01))
b2 = tf.Variable(tf.constant(0.01, shape = [256]))
w3 = tf.Variable(tf.truncated_normal([256, self.n_action], stddev = 0.01))
b3 = tf.Variable(tf.constant(0.01, shape = [self.n_action]))
l1 = tf.nn.relu(tf.matmul(state, w1) + b1)
l2 = tf.nn.relu(tf.matmul(l1, w2) + b2)
Q_value = tf.matmul(l2, w3) + b3
Q_action = tf.reduce_sum(tf.multiply(Q_value, self.input_action), axis = 1)
cost = tf.reduce_mean(tf.square(self.input_Y - Q_action))
train_op = tf.train.AdamOptimizer(1e-6).minimize(cost, global_step = self.global_step)
return Q_value, train_op
def train(self):
minibatch = random.sample(self.memory, self.BATCH_SIZE)
state = [data[0] for data in minibatch]
action = [data[1] for data in minibatch]
reward = [data[2] for data in minibatch]
next_state = [data[3] for data in minibatch]
Y = []
Q_value = self.Q_value.eval(feed_dict = {
self.input_state: next_state
})
for i in range(0, self.BATCH_SIZE):
if minibatch[i][4]:
Y.append(reward[i])
else:
Y.append(reward[i] + self.GAMMA * np.max(Q_value[i]))
self.train_op.run(feed_dict = {
self.input_Y: Y,
self.input_action: action,
self.input_state: state
})
def step(self, state, action, reward, terminal):
next_state = np.append(self.state_t[1:, :], state, axis = 0)
self.memory.append((self.state_t, action, reward, next_state, terminal))
if len(self.memory) > self.REPLAY_MEMORY:
self.memory.popleft()
if self.time_step > self.OBSERVE:
self.train()
self.state_t = next_state
self.time_step += 1
def get_action(self, train = False):
action = np.zeros(self.n_action)
if train and random.random() <= self.epsilon:
index = random.randrange(self.n_action)
#print ("rnd", index)
else:
Q_value = self.Q_value.eval(feed_dict = {
self.input_state: [self.state_t]
})[0]
index = np.argmax(Q_value)
#print ("brain", index)
action[index] = 1
if self.epsilon > self.FINAL_EPSILON and self.time_step > self.OBSERVE:
self.epsilon -= (self.INITIAL_EPSILON - self.FINAL_EPSILON) / self.EXPLORE
return action, index
class Test(QWidget):
def __init__(self):
app = QApplication(sys.argv)
super().__init__()
self.init_ui()
self.show()
self.timer = QTimer(self)
self.timer.timeout.connect(self.update)
self.timer.start(200)
self.winCount = 0
self.loseCount = 0
state = env.observe()
self.brain = Brain(3, 10, 10, state)
app.exec_()
def init_ui(self):
self.setWindowTitle("PyQt5")
self.resize(400, 400)
self.angle = 0
def paintEvent(self, QPaintEvent):
action, index = self.brain.get_action(False)
state, reward, gameOver, stateInfo = env.act(index)
self.brain.step(state, action, reward, gameOver)
fruitRow = stateInfo[0]
fruitColumn = stateInfo[1]
basket = stateInfo[2]
if (reward == 1):
self.winCount = self.winCount + 1
elif (reward == -1):
self.loseCount = self.loseCount + 1
painter = QPainter(self)
painter.setPen(Qt.black)
painter.drawLine(QPoint(20, 20), QPoint(20, 220))
painter.drawLine(QPoint(20, 20), QPoint(220, 20))
painter.drawLine(QPoint(220, 20), QPoint(220, 220))
painter.drawLine(QPoint(20, 220), QPoint(220, 220))
painter.setFont(QFont('Consolas', 20))
painter.drawText(QPoint(250, 50), "win: " + str(self.winCount));
painter.drawText(QPoint(250, 80), "miss: " + str(self.loseCount));
painter.setBrush(Qt.yellow)
painter.drawRect(fruitColumn * 20, fruitRow * 20, 20, 20)
painter.setBrush(Qt.green)
painter.drawRect(basket * 20 - 20, 10 * 20, 60, 20)
if (gameOver):
fruitRow, fruitColumn, basket = env.reset()
env = CatchEnvironment(10)
fruitRow, fruitColumn, basket = env.reset()
if __name__ == '__main__':
Test()