はじめに
これはAlibabaCloud Advent Calendar 2019の24日目の記事です。
私の部署では日頃からAlibabaCloudによるソリューションや開発手法、展開に取り組んでおり、日々中国や全世界から最先端の技術取得に励んでいます。
そうした活動をもっと外部へと発信していこうと始めたのがこのAdventCalendarです。社員+α 一人一人が書いた記事を通して、少しでも多くの方にAlibabaCloudの興味を持って頂ければ幸いです。
さて、本記事はAlibabaCloud分析系プロダクトを使って、サンタクロースの働き方革命をする話です。
毎年12月24日クリスマスは、年で唯一サンタクロースさんが大変な日になります。なぜなら、日本全国・いや全世界の子供達にクリスマスプレゼントを贈らなければならない。しかも24日夜中にだ。
そこで、AlibabaCloudを武器に分析・効率化をしていこうと考えています。
ターゲット・要件
毎年12月24日 夜20:00 - 朝 6:00までの10時間だけで 日本国内の子供 1533万人、全世界の子供総計で約19億1580万人にプレゼントを配給しなければならないです。年に一度の大イベントとはいえ、規模が大きいので 効率よくプレゼント配布を進めるために戦略を立てる必要がある、という要件で進めます。今の時代、サンタクロースさんも働き方革命をしたいはず。(現実世界での話ではないので無理やり感がありますが、そこはご容赦を。。)

どうやって分析するか?
プレゼントを配布する子供の数が 日本だけでも 1533万人 = レコード 1533万件です。Pythonとかなら1万件ならまだ大丈夫ですが、1000万件超えなら処理に時間がかかります。 (yieldによるジェネレータ、PyArrow、Cython、Impala+kudu on E-MapReduce、PySpark on E-MapReduce、Spark on MaxComputeを使えばすんなり解決しますが、そこは別の機会にて、、)
今回は AlibabaCloud AnalyticDB for PostgreSQL を使って分析をします。
AnalyticDB for PostgreSQLとは
Greenplum Database をベースとするオンライン超並列処理(MPP) データウェアハウスサービスです。 Greenplum Database は PostgreSQLをベースとしつつ、PBを超える大規模データでも1秒未満のレイテンシで対話ができるよう、OLAP(Online Analytical Processing)として設計されています。
- 数百ノードのデータ拡張ができて、PBレベルデータでもOLAP分析を実現
- Greenplum は「In-Database Analytics」概念に基づきDB内部のみで分析を前提としてるため、高度な分析機能を実装
- 機械学習アルゴリズムとしてApache MADlib をサポート、機械学習アルゴリズムに基づいた分析が可能
AnalyticDB for PostgreSQLはOSSを外部テーブルとして連携利用することが可能です。そのため、OSSにある大量のデータでも高速で処理することができます。
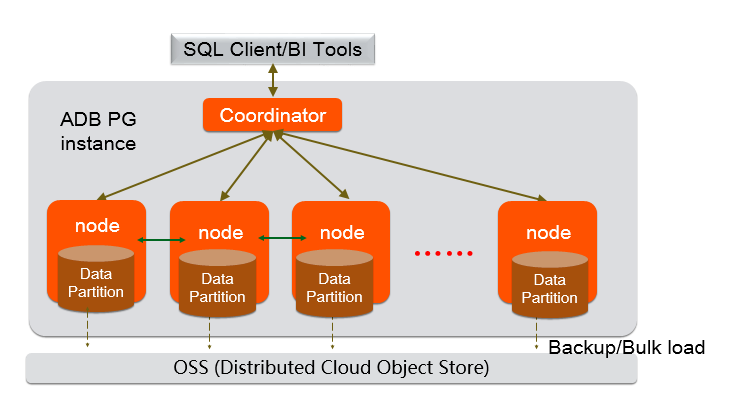
参考:AnalyticDB for PostgreSQLアーキテクチャ
※ MPP(Massively Parallel Processing)は 列指向・複数のCPUを使って複雑な分析クエリをより迅速かつ効率的に処理するシステムです。
それだけでなく、Greenplum Database で特にすごいのが Apache MADlibをサポートしており、300を超える様々な機械学習による分析が実現できます。
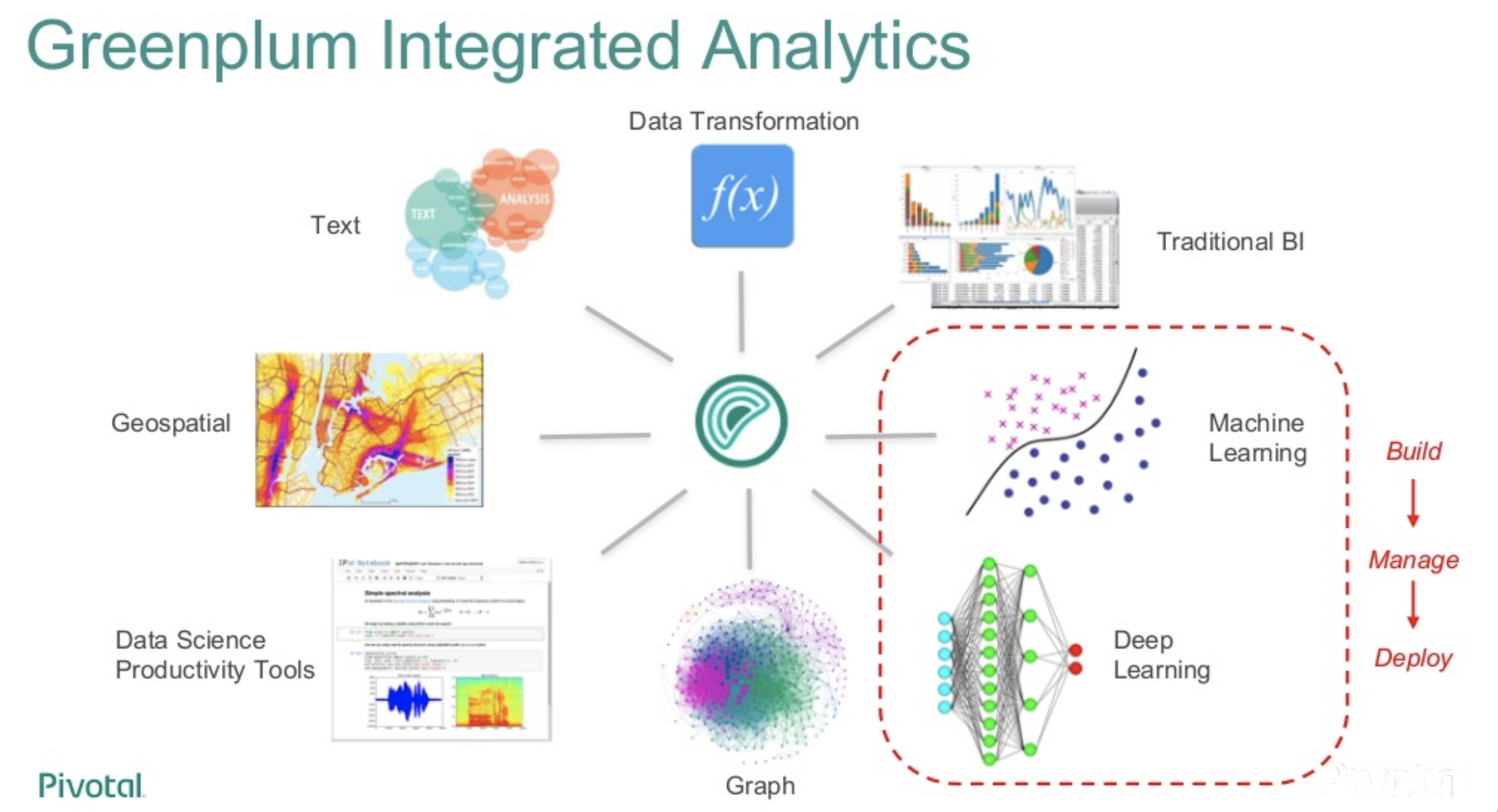
参考:AI on Greenplum Using Apache MADlib and MADlib Flow - Greenplum Summit 2019
In-Database Analytics とは
「なぜ In-Database Analyticsが重要か?」という疑問ですが、IoTやM2M、eXBLなどインタラクションを求めるソリューションではエッジコンピューティングが重要になりつつあり、データのETL、前処理、最適化の都度、一度そのシステム(プロダクトサービス)から別のシステムやプロダクトへ、と外で出すたびにデータ転送やI/O・ストレージ処理・更新に時間がかかる課題が出ます。さらに言えば データをRDB以外に出せば、その分DWHの維持費コストやエンジニア工数課題もあるので 「データが入ってきたら全ての処理を内部で済ます」、という In-Database Analytics スタイルは今後重要になるかなと個人的には思ったりしています。
参考:In-Database Analyticsの必要性と可能性
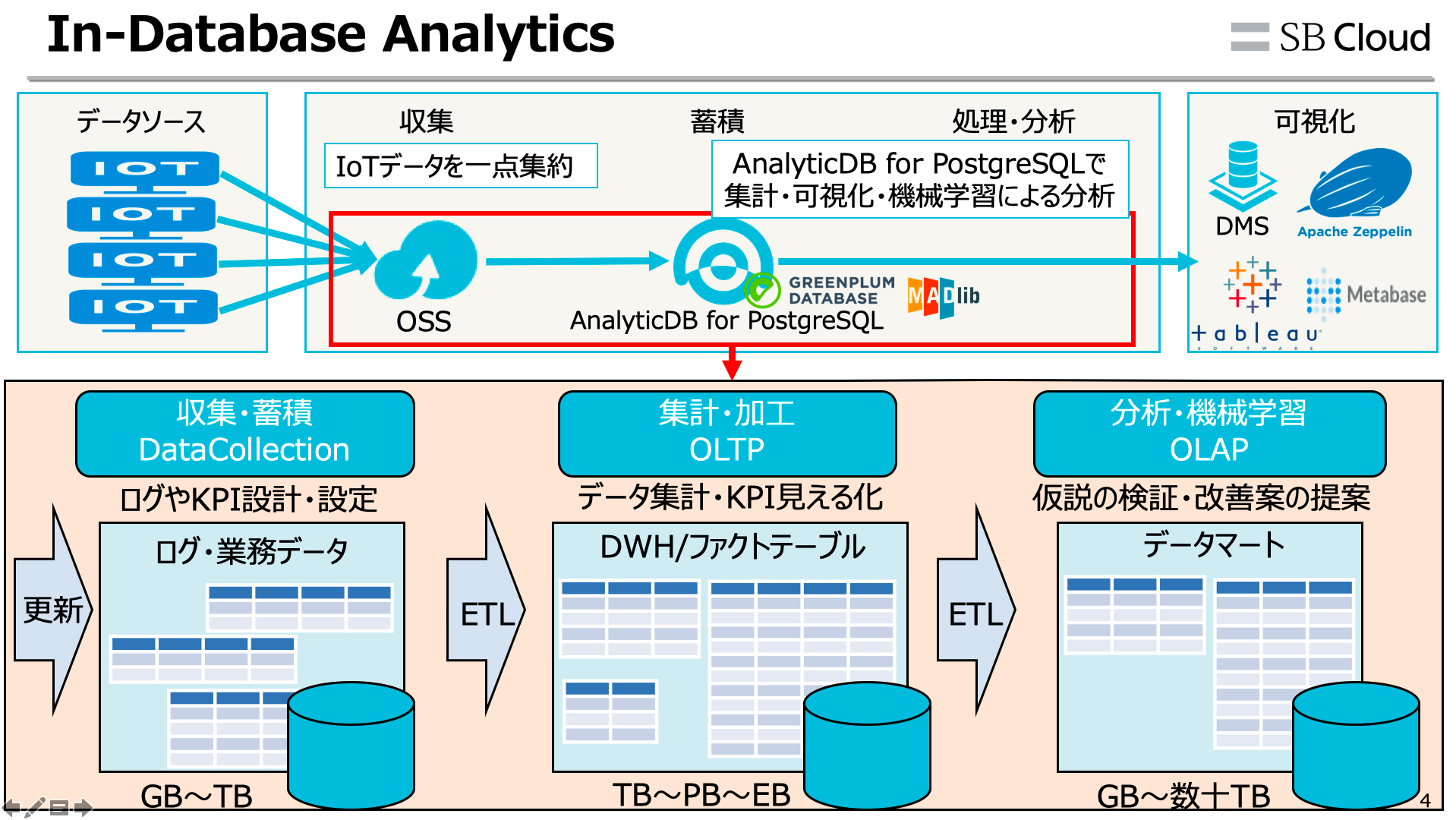
In-Database Analytics ができれば、例えば以下の
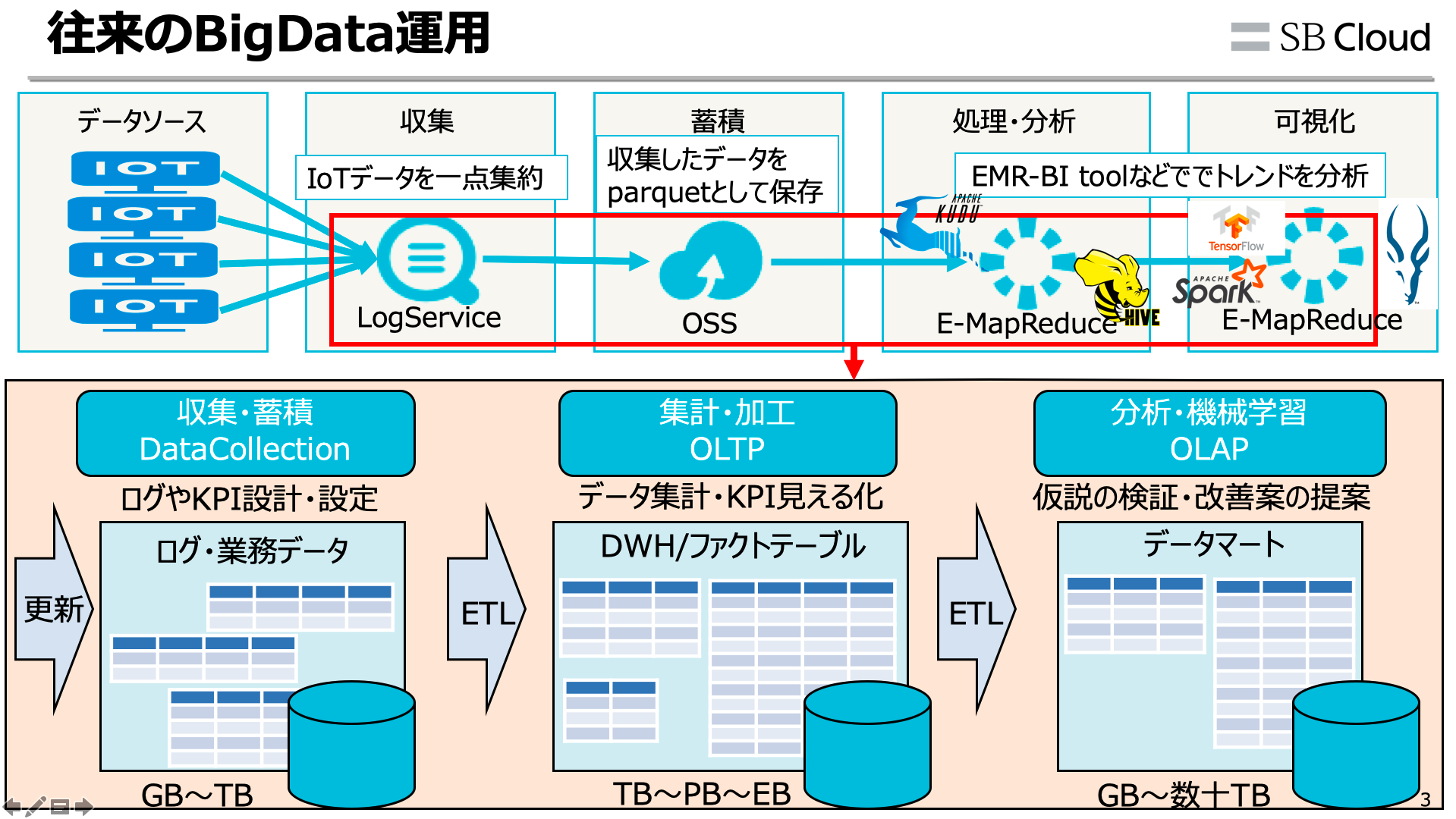
このようなHadoopや大規模DWH・MPPシステムに対し、DB内部で全部完結することができます。データ収集、ETL、機械学習による分析やcbirによる類似画像検索、SVM、などもDB内部で処理が可能です。これであればエンジニア調達問題や工数、データ維持・運用に伴うコスト問題も現実的に解決できます。
データを作る
では本題、欲望に包まれた子供のデータセットを用意します。何事もデータがないと始まらないです。
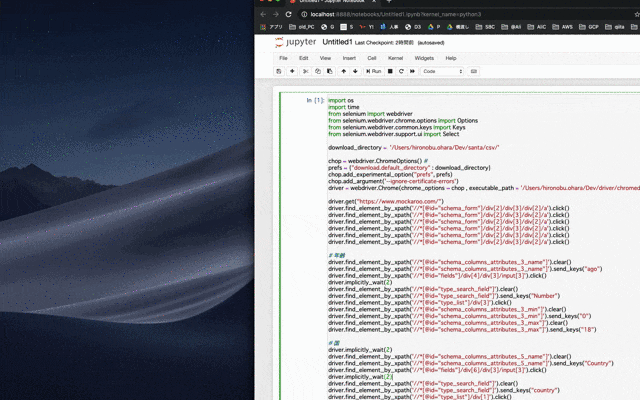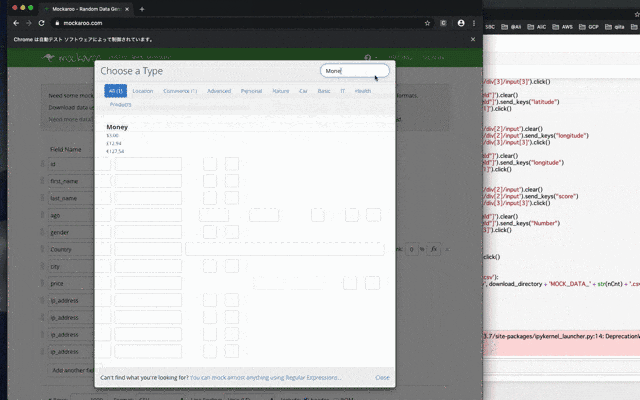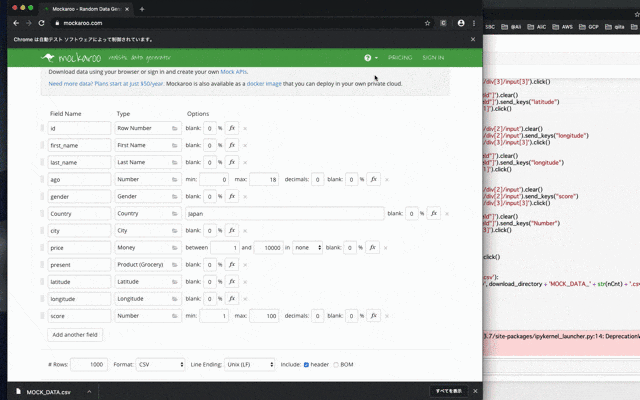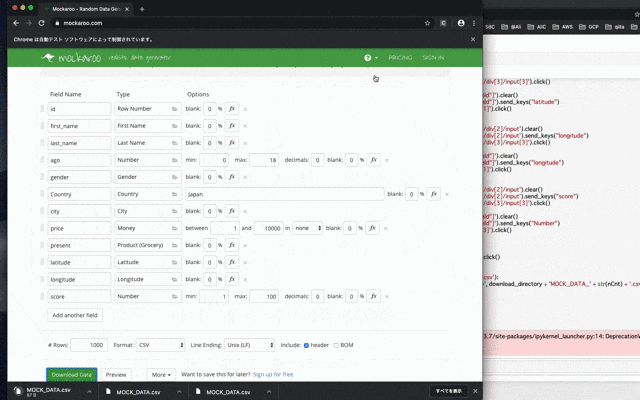
今回はmockarooというダミーデータ作成のサイトを利用して作成します。mockarooはJSON/CSV/SQL/Excelなどのダミーデータを生成してくれるサービスです。
https://www.mockaroo.com/
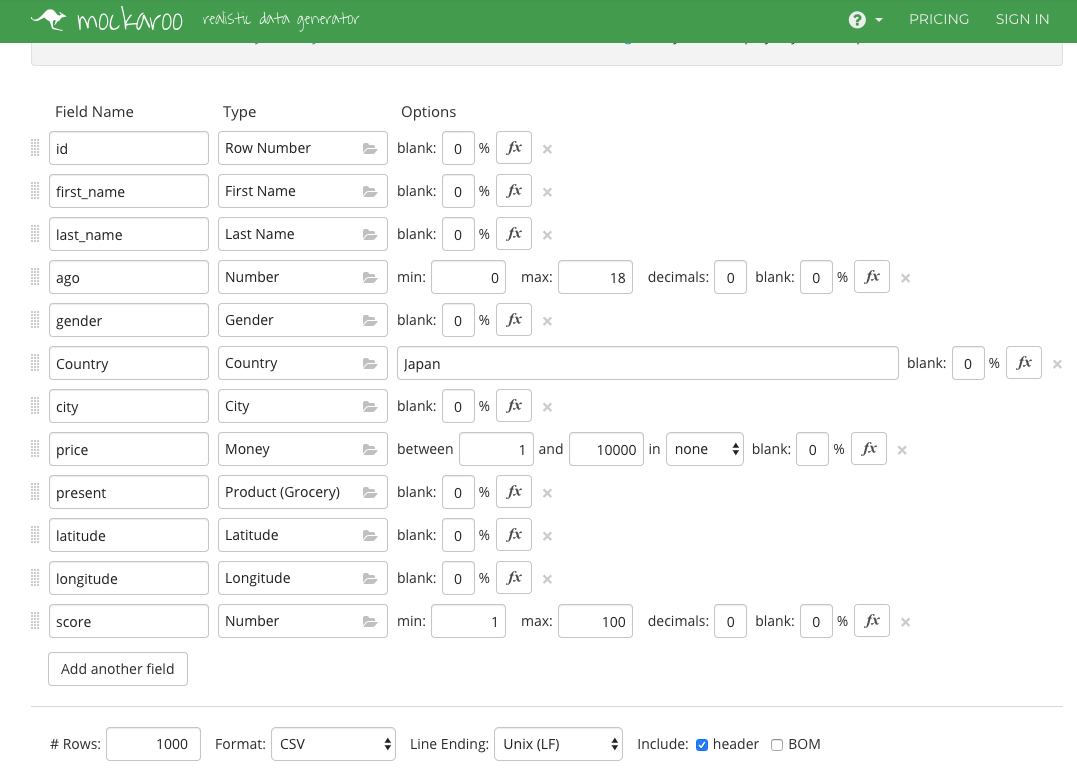
このような構成で日本ユーザ1533万レコード分作成します。
※ mockarooは一度にDLできる上限数が1000件までなので、スクリプトで1533万レコード分(=1533ファイル)DLしました。もちろんサーバやNW負荷に優しい遅延処理構成や、mockarooサンプルデータ作成サイトの利用規約的にOKなことを確認したよす。
そのあとは 日本をのぞく全世界の子供分 19億47万人分のレコードも作成しスクレでDLします。日本含めトータルで全世界の子供約191万5800ファイル(=19億1580万人分)あることを確認。
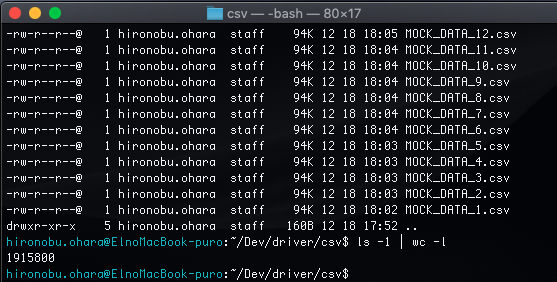
スクレのソースも張ります。mockaroo APIは利用制限あり、k8s分散 + puppeteer で並列Webスクレを考えてたけど、今回の場合ならseleniumのほうが構築含め案外早かった。
import os
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import Select
download_directory = '/Users/hironobu.ohara/Dev/santa/csv/'
chop = webdriver.ChromeOptions()
prefs = {"download.default_directory" : download_directory}
chop.add_experimental_option("prefs", prefs)
chop.add_argument('--ignore-certificate-errors')
driver = webdriver.Chrome(chrome_options = chop , executable_path = '<chromedriverのパス>')
driver.get("https://www.mockaroo.com/")
driver.find_element_by_xpath('//*[@id="schema_form"]/div[2]/div[3]/div[2]/a').click()
driver.find_element_by_xpath('//*[@id="schema_form"]/div[2]/div[3]/div[2]/a').click()
driver.find_element_by_xpath('//*[@id="schema_form"]/div[2]/div[3]/div[2]/a').click()
driver.find_element_by_xpath('//*[@id="schema_form"]/div[2]/div[3]/div[2]/a').click()
driver.find_element_by_xpath('//*[@id="schema_form"]/div[2]/div[3]/div[2]/a').click()
driver.find_element_by_xpath('//*[@id="schema_form"]/div[2]/div[3]/div[2]/a').click()
# 年齢
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_3_name"]').clear()
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_3_name"]').send_keys("ago")
driver.find_element_by_xpath('//*[@id="fields"]/div[4]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("Number")
driver.find_element_by_xpath('//*[@id="type_list"]/div[3]').click()
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_3_min"]').clear()
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_3_min"]').send_keys("0")
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_3_max"]').clear()
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_3_max"]').send_keys("18")
# 国
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_5_name"]').clear()
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_5_name"]').send_keys("Country")
driver.find_element_by_xpath('//*[@id="fields"]/div[6]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("country")
driver.find_element_by_xpath('//*[@id="type_list"]/div[1]').click()
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_5_countries"]').clear()
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_5_countries"]').send_keys("Japan") #日本以外を選ぶ場合はコメントアウト
driver.find_element_by_xpath('//*[@id="schema_columns_attributes_5_countries"]').send_keys(Keys.ENTER) #日本以外を選ぶ場合はコメントアウト
# 都市
driver.find_element_by_xpath('//*[@id="fields"]/div[7]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="fields"]/div[7]/div[2]/input').send_keys("city")
driver.find_element_by_xpath('//*[@id="fields"]/div[7]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("City")
driver.find_element_by_xpath('//*[@id="type_list"]/div[1]').click()
# 価格
driver.find_element_by_xpath('//*[@id="fields"]/div[8]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="fields"]/div[8]/div[2]/input').send_keys("price")
driver.find_element_by_xpath('//*[@id="fields"]/div[8]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("Money")
driver.find_element_by_xpath('//*[@id="type_list"]/div[1]').click()
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div[3]/div[2]/div[1]/div[8]/div[4]/div[18]/input[1]').clear()
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div[3]/div[2]/div[1]/div[8]/div[4]/div[18]/input[1]').send_keys("1")
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div[3]/div[2]/div[1]/div[8]/div[4]/div[18]/input[2]').clear()
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div[3]/div[2]/div[1]/div[8]/div[4]/div[18]/input[2]').send_keys("10000")
element = driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div[3]/div[2]/div[1]/div[8]/div[4]/div[18]/select')
select_element = Select(element)
select_element.select_by_value('none')
# プレゼント
driver.find_element_by_xpath('//*[@id="fields"]/div[9]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="fields"]/div[9]/div[2]/input').send_keys("present")
driver.find_element_by_xpath('//*[@id="fields"]/div[9]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("product")
driver.find_element_by_xpath('//*[@id="type_list"]/div[1]').click()
# Lat
driver.find_element_by_xpath('//*[@id="fields"]/div[10]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="fields"]/div[10]/div[2]/input').send_keys("latitude")
driver.find_element_by_xpath('//*[@id="fields"]/div[10]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("latitude")
driver.find_element_by_xpath('//*[@id="type_list"]/div[1]').click()
# Lon
driver.find_element_by_xpath('//*[@id="fields"]/div[11]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="fields"]/div[11]/div[2]/input').send_keys("longitude")
driver.find_element_by_xpath('//*[@id="fields"]/div[11]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("longitude")
driver.find_element_by_xpath('//*[@id="type_list"]/div[1]').click()
# 良い子かスコア
driver.find_element_by_xpath('//*[@id="fields"]/div[12]/div[2]/input').clear()
driver.find_element_by_xpath('//*[@id="fields"]/div[12]/div[2]/input').send_keys("score")
driver.find_element_by_xpath('//*[@id="fields"]/div[12]/div[3]/input[3]').click()
driver.implicitly_wait(2)
driver.find_element_by_xpath('//*[@id="type_search_field"]').clear()
driver.find_element_by_xpath('//*[@id="type_search_field"]').send_keys("Number")
driver.find_element_by_xpath('//*[@id="type_list"]/div[3]').click()
for nCnt in range(1), <DLしたい件数>):
# Download
driver.find_element_by_xpath('//*[@id="download"]').click()
while True:
if os.path.exists(download_directory + 'MOCK_DATA.csv'):
os.rename(download_directory + 'MOCK_DATA.csv', download_directory + 'MOCK_DATA_' + str(nCnt) + '.csv')
break
time.sleep(3)
driver.quit()
OSSへ格納
これをOSSに格納します。量が多いので ossimportで一気にUploadします。実はE-MapReduceを使ってでIDC/オンプレ - OSSへ並列インポートしたほうが早いです。
参考:ossimport
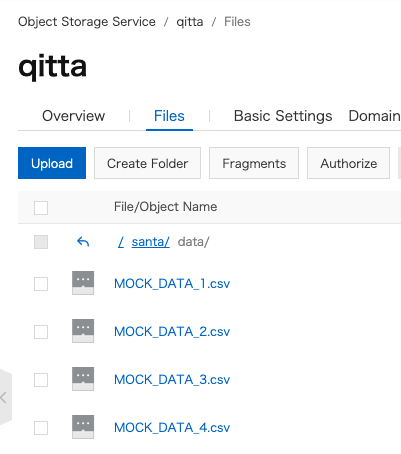
OSSへUploadしました。全部で約190GBあります。
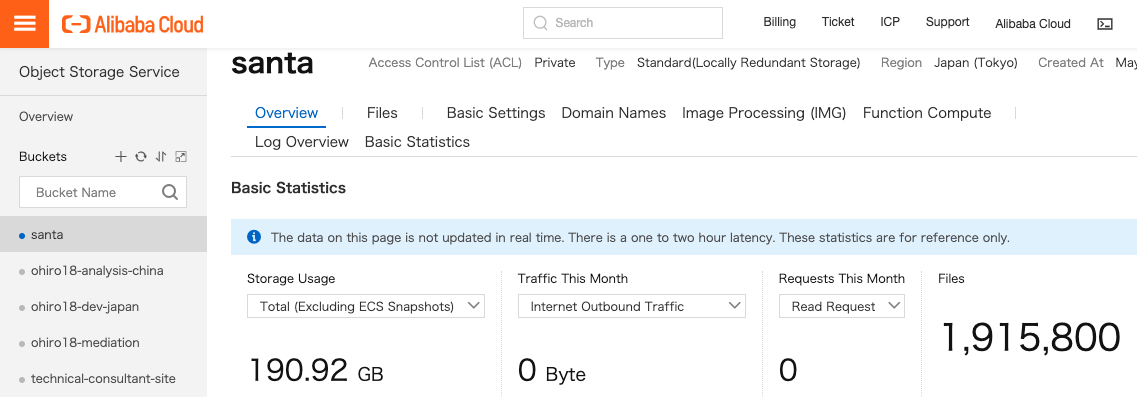
これをAnalyticDB for PostgreSQLにて読み込ませます。(本当はcsvでなくtar.gzなどファイル圧縮してからOSS-Importした方がOSSストレージコスト節約もなるもの、今回は解説用として、、参考まで)
読み込ませるとき、以下の流れで進めます。
- oss_extで外部テーブルを宣言
- OSS外部テーブル(santa_list_table_for_oss_file)を作成し、OSSデータをリロード
- AnalyticDB for PostgreSQL内部にてテーブル(santa_list_table_for_gpdb)を作成
- OSS外部テーブル(santa_list_table_for_oss_file)をAnalyticDB for PostgreSQL内部にてテーブル(santa_list_table_for_gpdb)へINSERT格納
そのため、AnalyticDB for PostgreSQLのCPU/メモリ/ストレージ容量は 処理したい容量(OSS外部テーブルの容量も含めて)に合わせる必要があります。
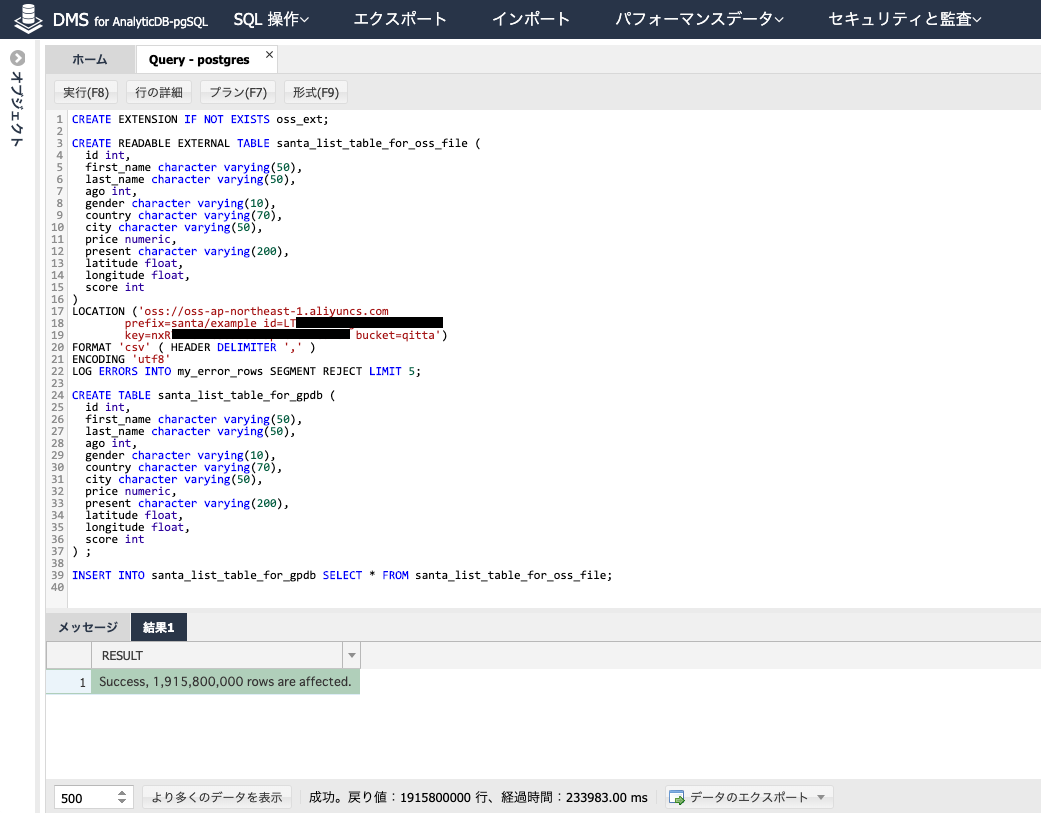
SQLコマンドでcsvファイル約191万ファイルを1つのテーブルとして格納します。
CREATE EXTENSION IF NOT EXISTS oss_ext;
CREATE READABLE EXTERNAL TABLE santa_list_table_for_oss_file (
id int,
first_name character varying(50),
last_name character varying(50),
ago int,
gender character varying(10),
country character varying(70),
city character varying(50),
price numeric,
present character varying(200),
latitude float,
longitude float,
score int
)
LOCATION ('oss://oss-ap-northeast-1.aliyuncs.com
prefix=santa/example id=<OSSに紐づいてるAccessKey ID>
key=<OSSに紐づいてるAccess Key Secret> bucket=qitta')
FORMAT 'csv' ( HEADER DELIMITER ',' )
ENCODING 'utf8'
LOG ERRORS INTO my_error_rows SEGMENT REJECT LIMIT 5;
CREATE TABLE santa_list_table_for_gpdb (
id int,
first_name character varying(50),
last_name character varying(50),
ago int,
gender character varying(10),
country character varying(70),
city character varying(50),
price numeric,
present character varying(200),
latitude float,
longitude float,
score int
) ;
INSERT INTO santa_list_table_for_gpdb SELECT * FROM santa_list_table_for_oss_file;
これで全世界19億人分の子供の情報データを格納することができました。大体5分ぐらいです。このデータ量であればpg_bulkloadより早い。。。
ちなみにテーブル一覧はこのコマンドで確認できます。
SELECT * FROM pg_tables;
Metabaseと接続する
AnalyticsDB for PostgreSQLはGreenplum Database、 PostgreSQLをベースとしてるので、
BI ToolでもPostgreSQLとして接続することができます。PostgreSQLに対応するものならなんでも接続できますw
※ 事前に外部インターネット接続設定、port解放が必要です
https://www.alibabacloud.com/help/zh/doc-detail/92523.htm
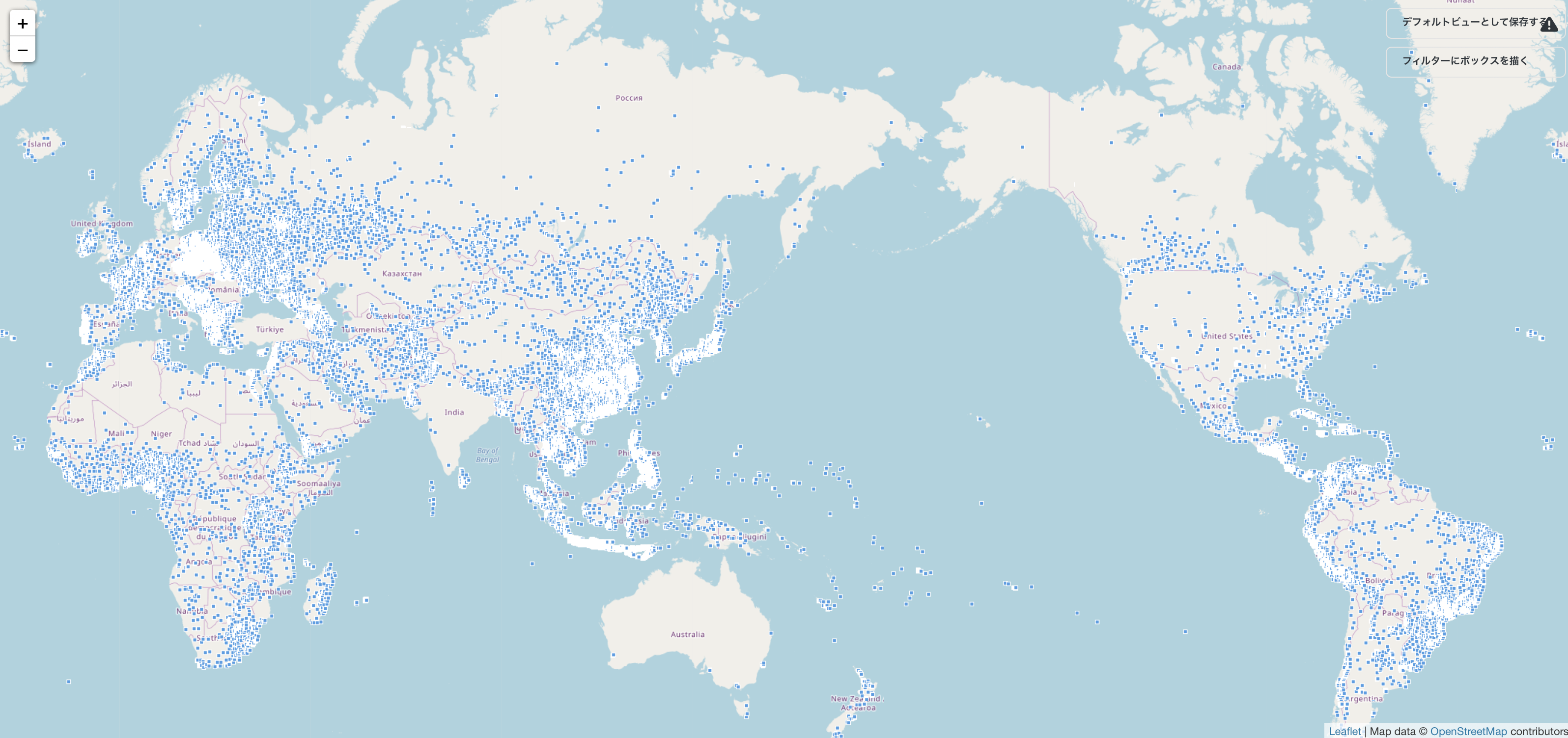
全体像をみる
Metabaseで全体像を見ちゃいましょう。
とは言え、Metabaseは100GBのテーブルそのままでは描画ら処理しきれないので(1GB規模データでも描画演算処理的に無理です)、 ここは全体テーブルの0.000001%(=1915レコード)に絞って地図上にて可視化します。
SELECT * INTO view_list FROM santa_list_table_for_gpdb limit 1915;
きゃあ、全世界の0.00001%、1,915人の子どもだけでもこんなにいる。。
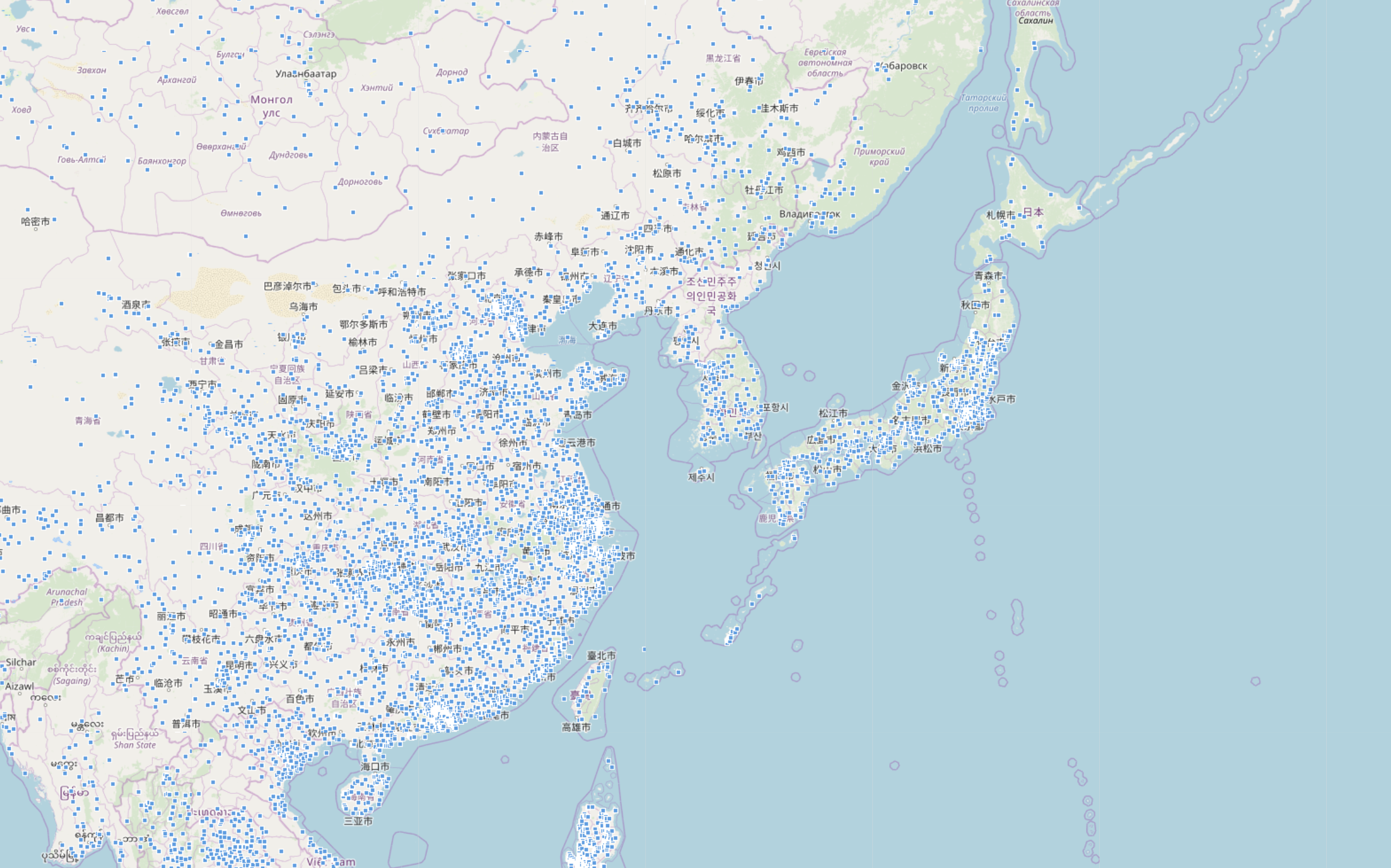
日本・中国だけでも結構いますね。
プレゼント割合はどうでしょうか?見てみます。
select PRESENT, count(*)
from santa_list_table_for_gpdb
group by PRESENT
order by count(*) desc;
ほー お肉が欲しい子供結構いるんですね。
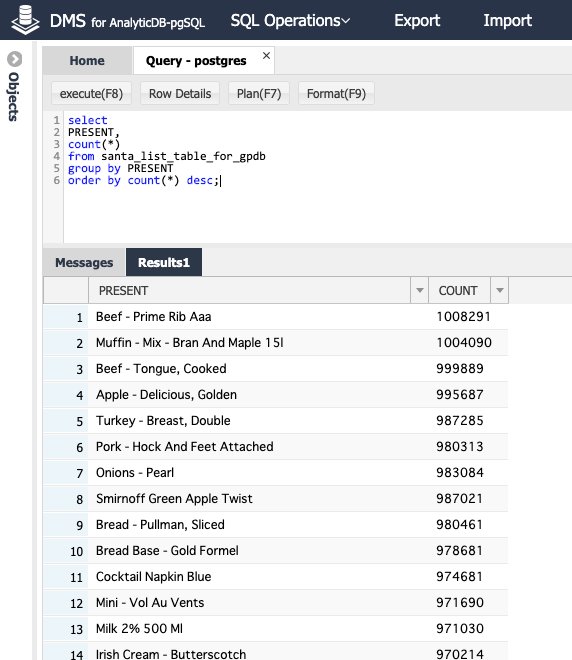
しかし、よく見たら まあ 未成年のくせにビールやワイン、タバコ、斧、薬、、、お仕置きにこの子たちはプレゼント無しにしょう。(公平性がない適当なデータ前処理です。恨むならデータを作ってくれたmockarooサイトさんに言いましょう。)
DELETE FROM santa_list_table_for_gpdb
WHERE PRESENT LIKE 'Wine%'
or PRESENT LIKE 'Beer%'
or PRESENT LIKE 'Axe%'
or PRESENT LIKE 'Knife%'
or PRESENT LIKE 'Drug%';
年齢 × 国ごとのプレゼント分布をみてみます。このようなSQLクエリで書けば大容量データによるPivot集計も可能です。
select PRESENT, count(*),
sum(case when AGO = 1 then 1 end) as "1 ago",
sum(case when AGO = 2 then 1 end) as "2 ago",
sum(case when AGO = 3 then 1 end) as "3 ago",
sum(case when AGO = 4 then 1 end) as "4 ago",
sum(case when AGO = 5 then 1 end) as "5 ago",
sum(case when AGO = 6 then 1 end) as "6 ago",
sum(case when AGO = 7 then 1 end) as "7 ago",
sum(case when AGO = 8 then 1 end) as "8 ago",
sum(case when AGO = 9 then 1 end) as "9 ago",
sum(case when AGO = 10 then 1 end) as "10 ago",
sum(case when AGO = 11 then 1 end) as "11 ago",
sum(case when AGO = 12 then 1 end) as "12 ago",
sum(case when AGO = 13 then 1 end) as "13 ago",
sum(case when AGO = 14 then 1 end) as "14 ago",
sum(case when AGO = 15 then 1 end) as "15 ago",
sum(case when AGO = 16 then 1 end) as "16 ago",
sum(case when AGO = 17 then 1 end) as "17 ago",
sum(case when AGO = 18 then 1 end) as "18 ago"
from santa_list_table_for_gpdb
group by PRESENT
order by count(*) desc;
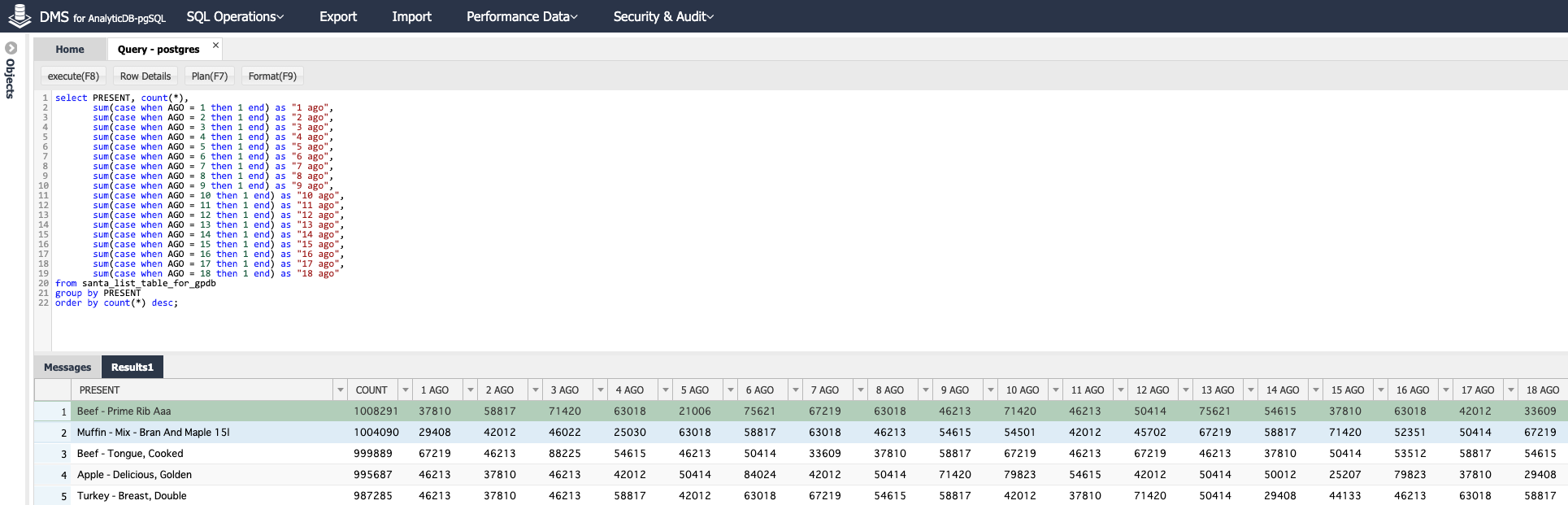
年齢 × 国ごとのプレゼント予算をみてみます。
select country,
sum(price) as total_price,
sum(case when AGO = 1 then price end) as "1 ago",
sum(case when AGO = 2 then price end) as "2 ago",
sum(case when AGO = 3 then price end) as "3 ago",
sum(case when AGO = 4 then price end) as "4 ago",
sum(case when AGO = 5 then price end) as "5 ago",
sum(case when AGO = 6 then price end) as "6 ago",
sum(case when AGO = 7 then price end) as "7 ago",
sum(case when AGO = 8 then price end) as "8 ago",
sum(case when AGO = 9 then price end) as "9 ago",
sum(case when AGO = 10 then price end) as "10 ago",
sum(case when AGO = 11 then price end) as "11 ago",
sum(case when AGO = 12 then price end) as "12 ago",
sum(case when AGO = 13 then price end) as "13 ago",
sum(case when AGO = 14 then price end) as "14 ago",
sum(case when AGO = 15 then price end) as "15 ago",
sum(case when AGO = 16 then price end) as "16 ago",
sum(case when AGO = 17 then price end) as "17 ago",
sum(case when AGO = 18 then price end) as "18 ago"
from santa_list_table_for_gpdb
group by country
order by sum(price) desc;
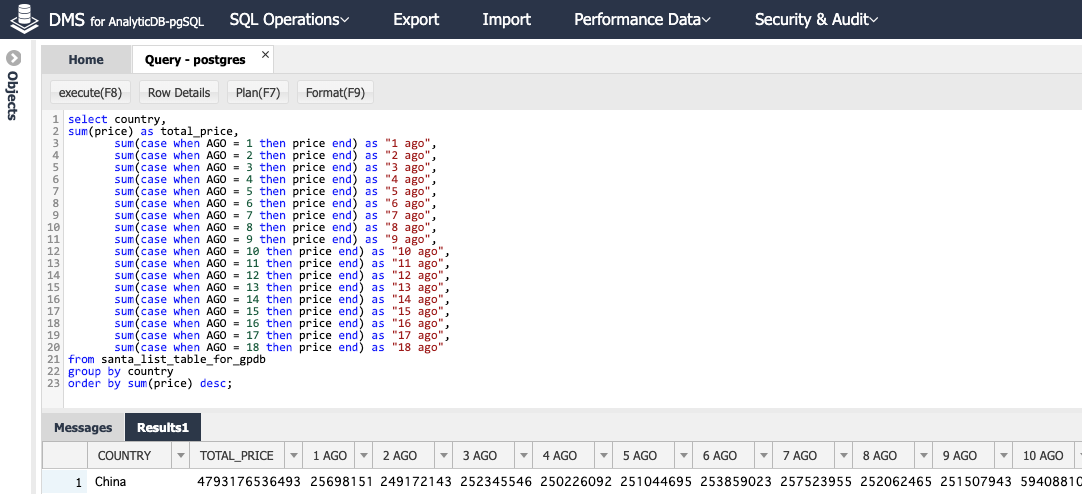
中国だけでも、1歳だけのプレゼント総計で256,981,510,374円、約2500億円といきなり国家予算レベルを追求していますね。年齢 × 国 の集計で 平均費用は以下のように書きます。
select country,
sum(price) as total_price,
sum(case when AGO = 1 then price end)/sum(1) as "1 ago",
sum(case when AGO = 2 then price end)/sum(1) as "2 ago",
sum(case when AGO = 3 then price end)/sum(1) as "3 ago",
sum(case when AGO = 4 then price end)/sum(1) as "4 ago",
sum(case when AGO = 5 then price end)/sum(1) as "5 ago",
sum(case when AGO = 6 then price end)/sum(1) as "6 ago",
sum(case when AGO = 7 then price end)/sum(1) as "7 ago",
sum(case when AGO = 8 then price end)/sum(1) as "8 ago",
sum(case when AGO = 9 then price end)/sum(1) as "9 ago",
sum(case when AGO = 10 then price end)/sum(1) as "10 ago",
sum(case when AGO = 11 then price end)/sum(1) as "11 ago",
sum(case when AGO = 12 then price end)/sum(1) as "12 ago",
sum(case when AGO = 13 then price end)/sum(1) as "13 ago",
sum(case when AGO = 14 then price end)/sum(1) as "14 ago",
sum(case when AGO = 15 then price end)/sum(1) as "15 ago",
sum(case when AGO = 16 then price end)/sum(1) as "16 ago",
sum(case when AGO = 17 then price end)/sum(1) as "17 ago",
sum(case when AGO = 18 then price end)/sum(1) as "18 ago"
from santa_list_table_for_gpdb
group by country
order by sum(price) desc;
このような感じで、SQLだけで全体傾向を把握できればいいかなと思います。今回の19億人の子供情報を統計的に見てみると一人平均512円、中央値2365円、最大値10000円、最小値0円でした。人が人だけに規模が大きいので、泣く子も黙る断捨離をします。
思いっきり断捨離
断捨離の方法、基準は色々ありますが、今回は「(今年1年間良い子にしてたか)スコア」 「年齢」 「価格」 のフィールドを生かして切り捨てる基準ラインを見つけて断捨離します。非常に良い子であり、なおかつプレゼントが安いものは優先度大、でいきます。
Pythonで処理できるレベルの容量であれば、お馴染みの ScatterPlotによる散布図(seabornなど) を利用します。(実は先ほどのMedabaseでもscatterPlotら相関図描画ができます)
しかし、データがデータだけに多いので、MADlibのSVMで区別します。
SVM(Support Vector Machines) は教師あり学習、データ前処理もせずパラメータ調整も不要のまま、高次元空間ながらデータの分類が可能です。(詳しいことはここでは割愛)
SVMは様々な種類がありますが、今回は既存データのクラスに沿って3変数分析(「スコア」 「年齢」 「価格」 の関係図) を 三次元的な観点で 区切り線を出す方法です。そこから予測や特徴把握、テキスト分類、異常検知などにも応用できます。
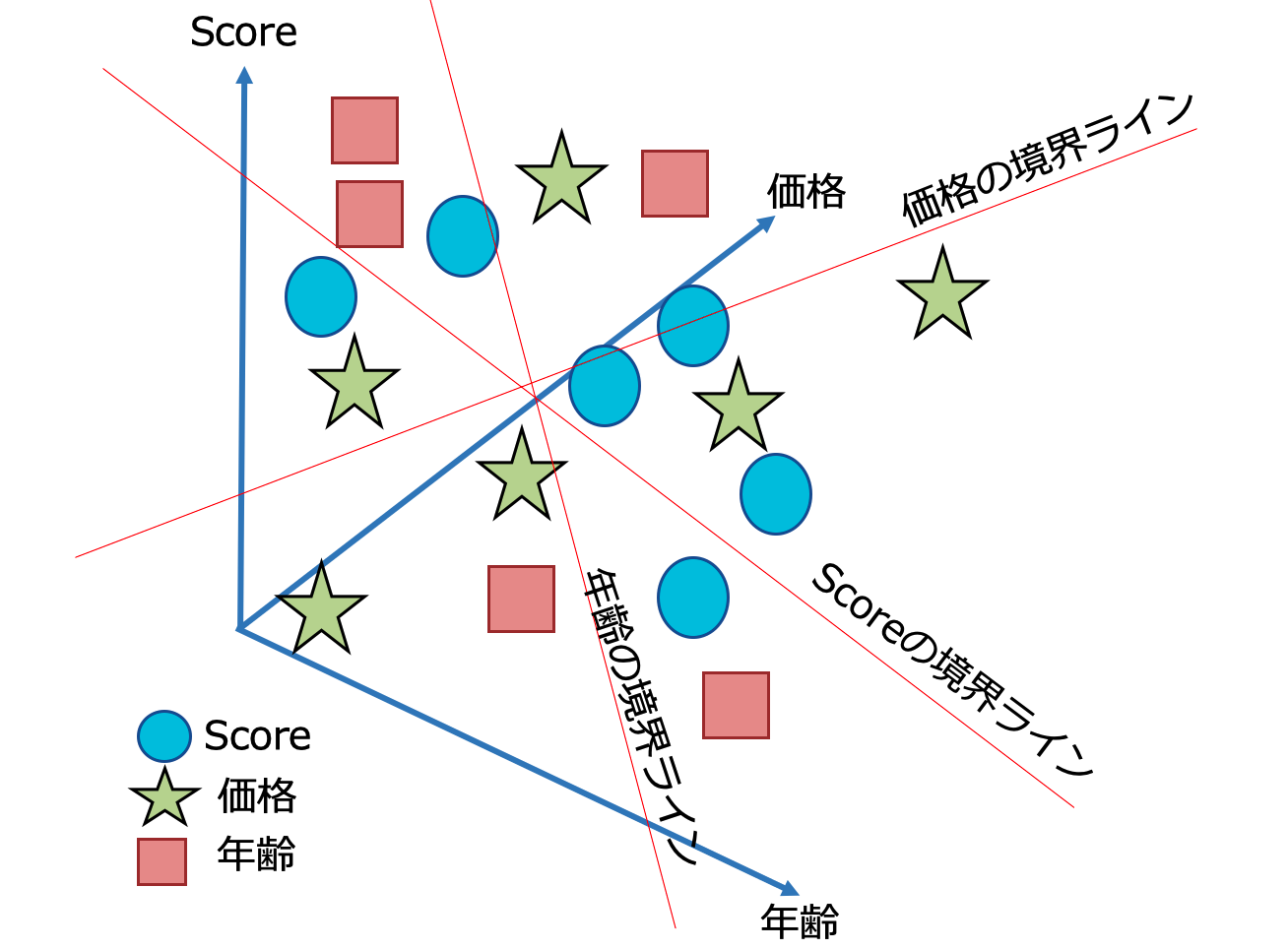
(イメージ図が下手くそですが、、要は 多次元フィールドから分類、区切りに最適な閾値(※今回の例であれば中央値に近似した区切りライン)を割り出すことです。)
jupyner(Python)で実行します。流れとしては
- CREATE EXTENSION plpythonu で PythonによるPostgreSQL分析を有効にします。
- CREATE EXTENSION madlib で madlibを有効にします。
- svm_classification で SVMトレーニングを実行(今回は最適なスコア>年齢>価格 のプライオリティに区別したため、より深い分類がしたい場合はパラメータ変数を追加するといいです。)
- svm_classification によるSVMトレーニング結果(分類モデル) を確認
- svm_predict によるモデル予測
- 分類する閾値を特定 (以降、パラメータ調整メインで3-5の繰り返し。ここは割愛)
CREATE EXTENSION plpythonu;
CREATE EXTENSION madlib;
drop table if exists svm_table, svm_table_summary;
SELECT madlib.svm_classification('santa_list_table_for_gpdb',
'svm_table',
'class', // (scoreや価格など条件を指定したかったらここにて score > 10 と、 任意のパラメータを入れることも可能です)
'ARRAY[1, ago, price, score]'
);
drop table if exists svm_table_score_pred;
select madlib.svm_predict('svm_table',
'santa_list_table_for_gpdb',
'score',
'svm_table_score_pred');
select
t1.id,
t1.score,
t1.ago,
t2.prediction,
t2.decision_function
from santa_list_table_for_gpdb a
join svm_table_score_pred b
order by id;
id | score | ago | prediction | decision_function
----+-------+-----+------------+--------------------
1 | 40 | 4 | 1 | 6.578378896356342
2 | 10 | 17 | 0 | -0.329874750309708
3 | 33 | 3 | 0 | -0.690380500692336
4 | 69 | 13 | 1 | 8.689389350927463
5 | 72 | 10 | 1 | 11.024795001840554
6 | 15 | 9 | 0 | -0.112450805466771
(略)
19億人近くの子供からSVMによる容赦のない分類結果、以下のような条件で区切りすることにしました。
ago | score | price
----+-------+-------
1 | 37 | 1912
2 | 29 | 948
3 | 67 | 2203
4 | 49 | 905
5 | 38 | 1214
6 | 28 | 691
7 | 49 | 1164
8 | 26 | 2060
9 | 59 | 2094
10 | 53 | 992
11 | 20 | 2188
12 | 67 | 868
13 | 66 | 1201
14 | 41 | 865
15 | 20 | 1869
16 | 37 | 866
17 | 52 | 1727
18 | 62 | 1353
例えば、1才の子供なら、 score 37以上、プレゼント価格1921円まで。という区切りです。これによって、19億レコードが4億レコードへしぼり出せました。
プレゼントが貰えない子供さん、知らんがな(´・ω・`)
ちなみに(繰り返しになり恐縮ですが)MADlibには 上記SVMのほか、線形回帰、ロジスティック回帰、K-meanなどの300以上の機械学習による分析・予測が可能です。このような数百GB級のテーブルでも瞬殺で分析です。

リアルタイム在庫管理しょう
プレゼントを配布するとき、不法侵入・時間管理で精一杯・プレゼント在庫リソースを考えないのがサンタさんの悩みなので、リアルタイム在庫管理を考えてみました。
そこで嬉しいことに、Greenplum はIn-Memory Gridの Pivotal GemFire に対応しており、これを使うとリアルタイム処理が可能です。(他にもSpark-connectorやAlibabaCloud RealtimeComputeからの連携技もあります)
Pivotal GemFire は一言で言えば分散データ管理プラットフォームです。Pivotal GemFire は高可用性、信頼性、管理性を持ちながらレプリケーション、パーティション分割、データベース対応ルーティングなど多様多種な環境を持ったデータとの管理コネクタ(パイプライン)として利用ができます。例えば、データソースで秒間数百MBのデータが入ってきたときでも、GemFireを経由することで、データ処理遅延もなく、すぐにOLTP/OLAP分析、機械学習処理が可能になります。
参考:Big Data Meets Fast Data To Fight Fraud (And More)
参考:Pivotal GemFire-Greenplum Connector

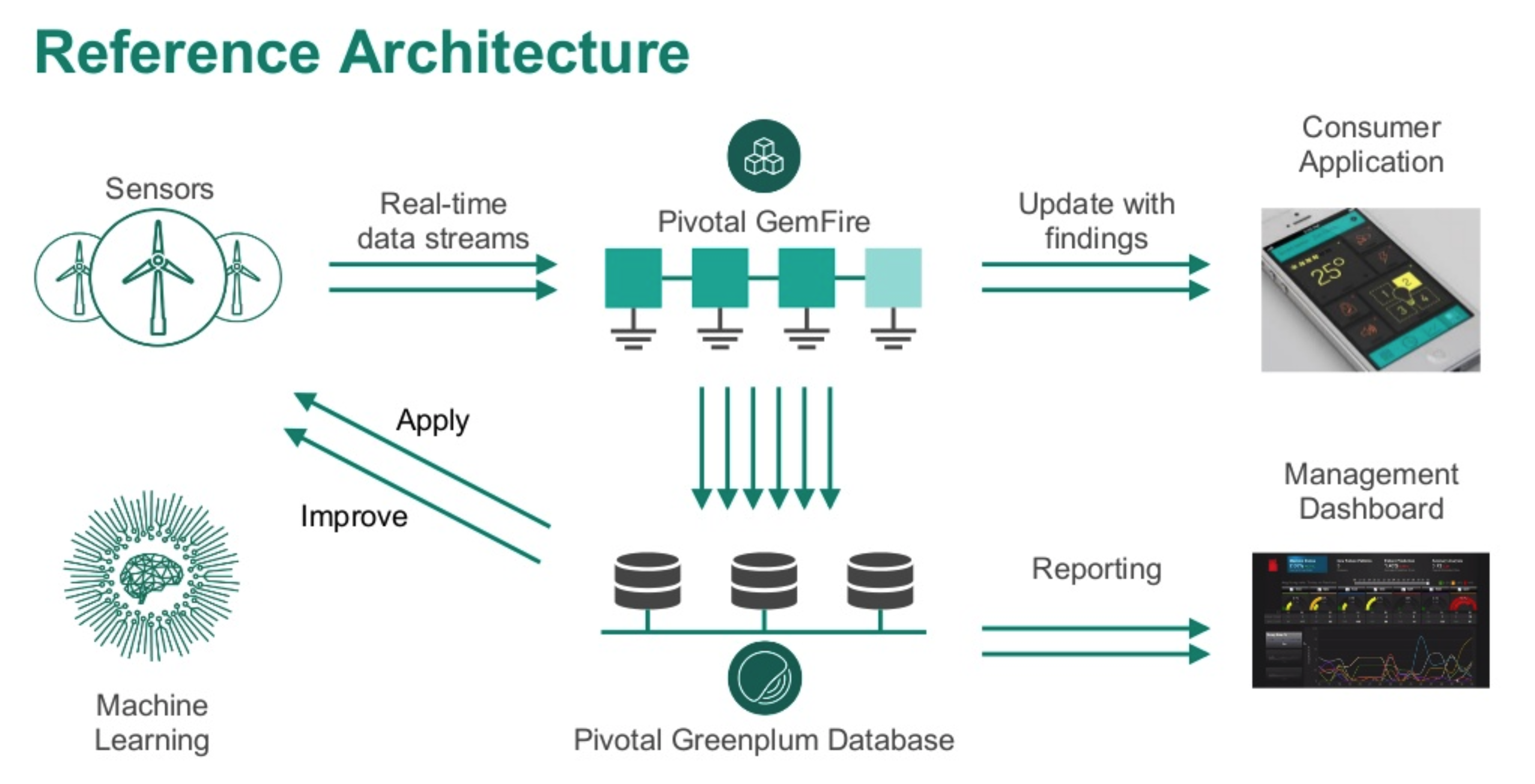
Real Time Business Platform by Ivan Novick from Pivotal
(今回これを再現したかったが、Qiita Advent Calendar締切と準備時間不足によりその環境を用意できなかったので割愛、、、いつかリベンジします)
トナカイから降りて配るエリアを決める
SVMで対象の子供をかなり絞ったとはいえ、配布するエリアがやはり大きいです。
そこでトナカイに乗って移動し、家着いたら降りてプレゼントを配給し、またトナカイに乗って次の家へ移動し、、というのも非効率なので、以下の図のように半径500km以内に対象の子供がいる家が密集してるエリアへ絞って、そこの中心地を拠点としつつトナカイの降りる場所を決めて一斉配給します。
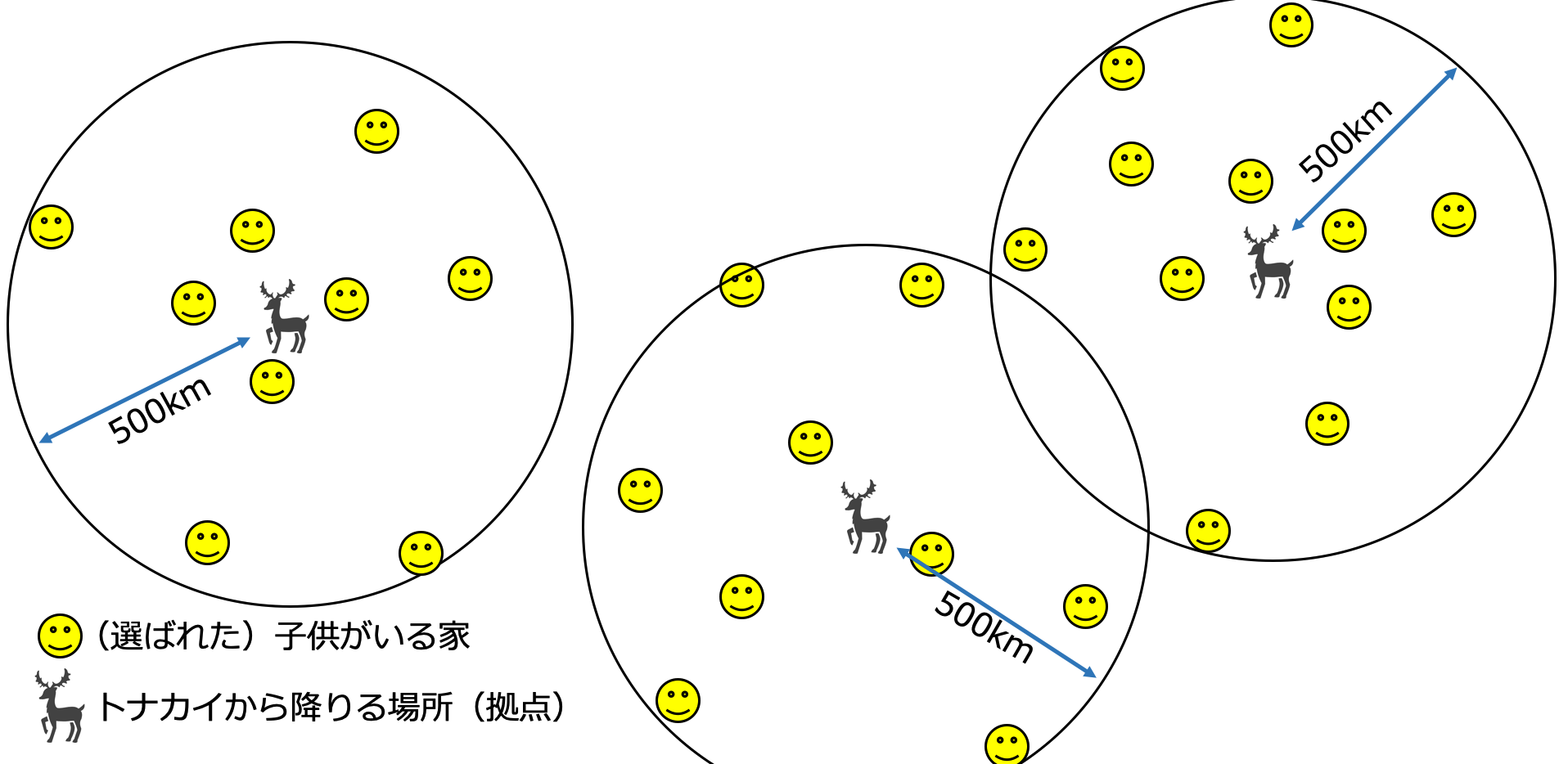
Spatial indexという空間データ処理機能を使うため、postgis機能を使って実行します。
参考:Spatial index
流れとしては
- CREATE EXTENSION postgis で postgisによる地理分析を有効にします。
- Spatial indexを削除し、Spatial indexを作成します。
- santa_list_table_for_gpdbテーブルのLat/LonからGEOMETRY型というSpatialデータ値に変換し、santa_geom_locationといテーブルを作成します。
※ 緯度経度を地理空間データに変換します。 #Spatial indexを扱う場合は緯度経度をSpatialデータ値に変換する必要があります。
緯度経度のSpatialデータ変換について - 既存の子供へ配る位置情報(Lat,Lon)から、半径500kmの円型ポリゴンを全て作成し、Yes/No型で割り当てます。
- 円型ポリゴンの中心(=トナカイから降りる場所)を絞ります。
※現状のAnalyticDB for PostgreSQLは 8.x系とバージョンが古いため、PostGIS 1.x系から使える機能のみ利用と、注意が必要です。
http://postgres.cn/docs/postgis-2.3/ST_Within.html
CREATE EXTENSION postgis;
DROP INDEX santa_geom_location;
CREATE INDEX santa_geom_location ON santa_list_table_for_gpdb USING GIST
(ST_SetSRID(ST_MakePoint(longitude, latitude), 4326));
//Convertら処理に時間がかかるので 以下SQL+Scriptで一気Insertもありです
DROP santa_geom_location test;
CREATE TABLE santa_geom_location ( id VARCHAR(16) NOT NULL, geom GEOMETRY NOT NULL );
CREATE INDEX geom ON santa_geom_location USING GIST(geom);
INSERT INTO santa_geom_location (id, geom) VALUES
(1, ST_GeomFromText('POINT(longitude latitude)', 4326)),
(2, ST_GeomFromText('POINT(longitude latitude)', 4326)),
(3, ST_GeomFromText('POINT(longitude latitude)', 4326)),
(4, ST_GeomFromText('POINT(longitude latitude)', 4326));
〜略〜
// --- Spatial indexデータ作成はここまで
// 以下は半径500km以内のエリアで密集がないか抽出
Select longitude, latitude From santa_list_table_for_gpdb
left join santa_geom_location.geom
on ST_DWithin(st_setsrid(st_make_point(longitude, latitude),4326), santa_geom_location.geom,0)
WHERE ST_Distance_Sphere(geom, st_make_point(longitude, latitude),4326) ) < 500000;
longitude | latitude
----------+----------
166.53333 | -20.6532
166.95813 | -0.52131
173.04259 | 1.353171
167.73919 | 8.774796
163.00781 | 5.324798
158.16109 | 6.924773
152.24551 | 8.609431
146.30531 | 7.491931
144.71654 | 13.47215
(略)
ちなみにAlibabaCloud Blog でも AnalyticDB for PostgreSQL PostGISを使った、商用エリアやマーケ分析に利用した実例がありますので、こちらも参考にいただければ幸いです。 (HybridDB for PostgreSQL は 昔の AnalyticDB for PostgreSQLの名称です )
AlibabaCloud GIS-based Grid Operations of New Retail Merchants
以下、jupyterでleafletによる地図上の可視化をしてみました。あまり重複することなくクラスタ区別していますね。
参考:ipyleaflet (leaflet on jupyter)
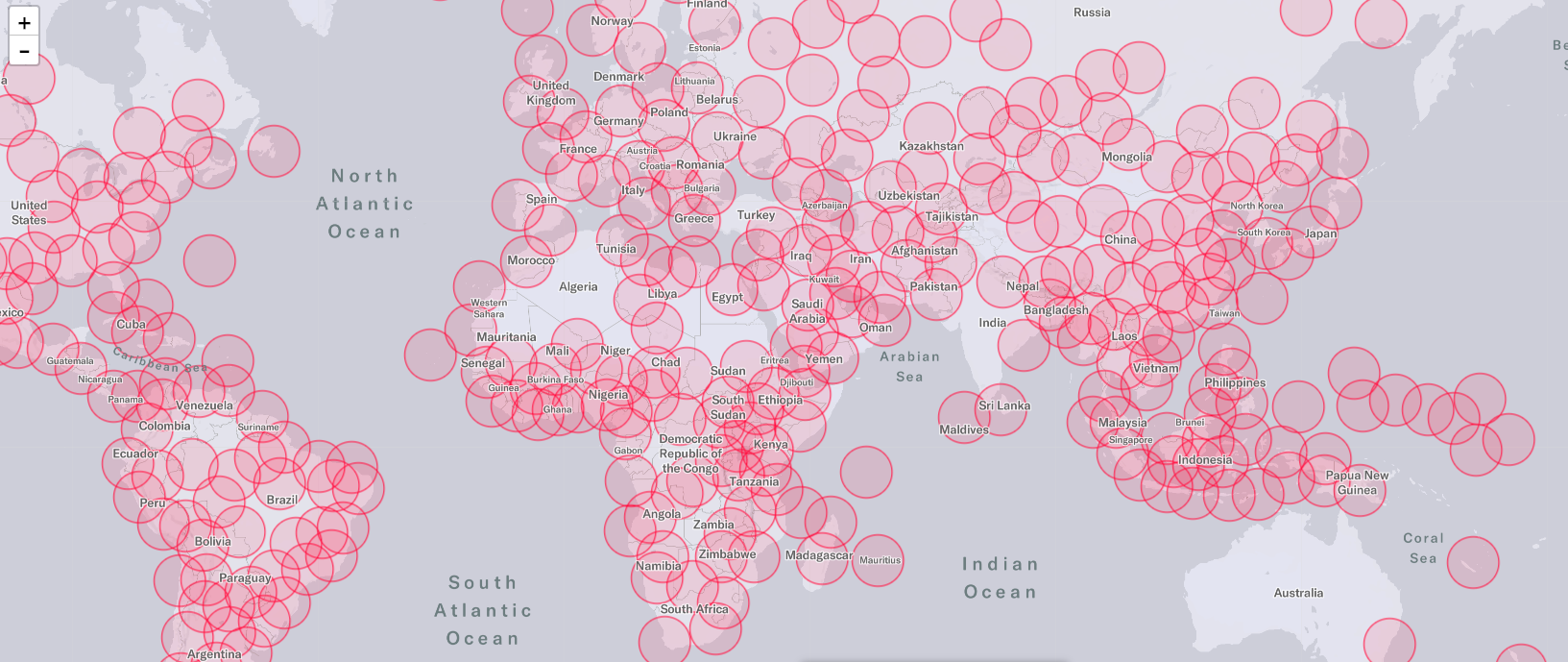
最短配達ルートを決める
上記の地図通り、トナカイから降りる場所が多すぎるので、最短配達ルートを決めます。GoogleMapのカーナビにあるよう最短ルートみたいなものです。
GreemplumことPostgreSQLにはpgroutingに対応しています。pgrouting機能にはpgr_aStar、pgr_connectedComponents、pgr_analyzeGraphなどロケーションにおける様々な計算処理ら関数があります。
参考:pgRouting
今回はpgr_tsp関数を使います。tspはtravelling salesman problem、セールスマン巡回問題から発案されたアルゴリズムです。
参考:Traveling Sales Person
参考:巡回セールスマン問題における最短経路をpgRoutingで探索する
参考として、AnalyticDB for PostgreSQLがなくても、Pythonのmlroseを使えば実現も可能です(量が数千万レコードと多い場合はPySparkで分散・遅延処理すればOK)
参考:Solving Travelling Salesperson Problems with Python
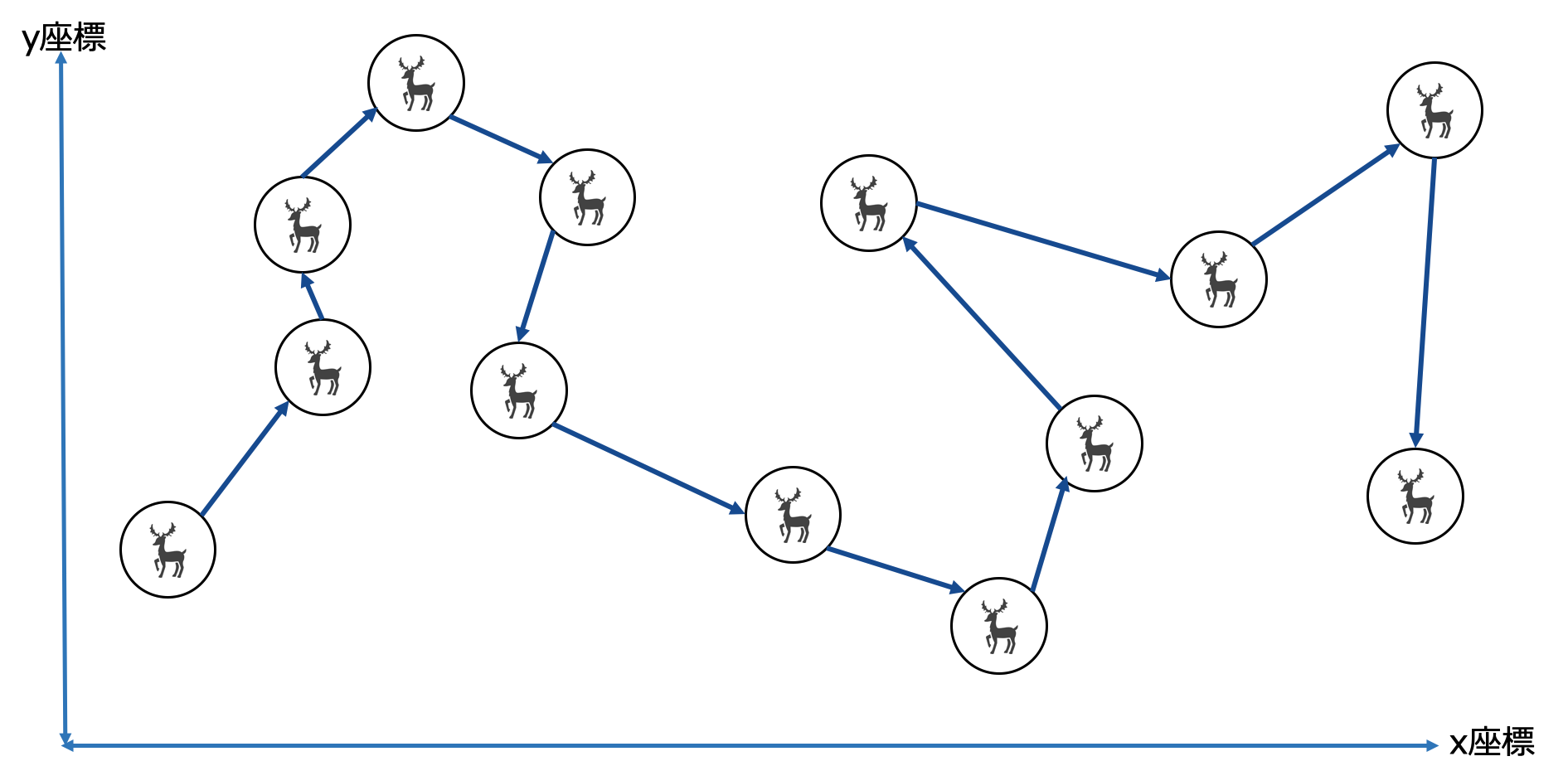
流れとしては以下の通りです。
- CREATE EXTENSION postgis でpostgisを有効にします。
- 先ほどのリストをdelivery_list_table という名前で別テーブルとして作成
- lat/lonをxy座標にしつつ、pgr_tspで最短ルート算出
- xy座標をjoinでlat/lon座標一覧として表示
CREATE EXTENSION postgis;
CREATE TABLE delivery_list_table (
sid serial primary key,
latitude float,
longitude float
);
INSERT INTO delivery_list_table
select longitude, latitude From santa_list_table_for_gpdb
left join santa_geom_location.geom
on ST_DWithin(st_setsrid(st_make_point(longitude, latitude),4326), santa_geom_location.geom,0)
WHERE ST_Distance_Sphere(geom, st_make_point(longitude, latitude),4326) ) < 500000;
SELECT sid id, latitude x, longitude y FROM delivery_list_table ORDER BY sid
SELECT * FROM pgr_tsp('SELECT sid id, latitude x, longitude y FROM delivery_list_table ORDER BY sid', 1);
SELECT s.longitude, s.latitude FROM
pgr_tsp('SELECT sid id, latitude x, longitude y FROM delivery_list_table ORDER BY sid', 1) t
LEFT OUTER JOIN delivery_list_table s ON t.id2 = s.sid;
longitude | latitude
-----------+----------
-146.27611 | 64.85611
-149.88047 | 61.18729
-134.47425 | 58.32716
-126.67008 | 54.39976
-117.28599 | 56.25014
-113.73513 | 52.46681
-111.12338 | 45.72463
(略)
さあプレゼント配布開始!
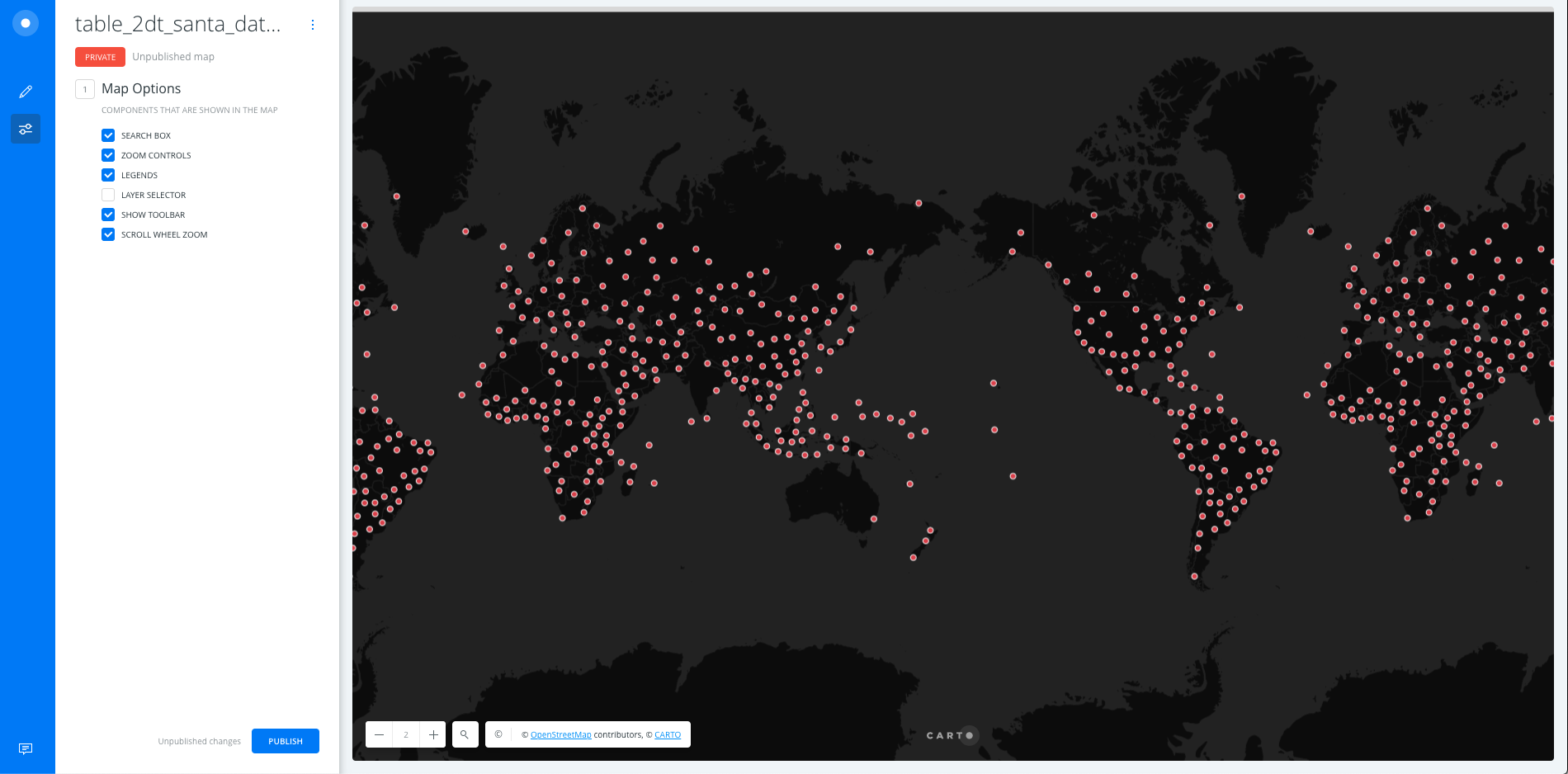
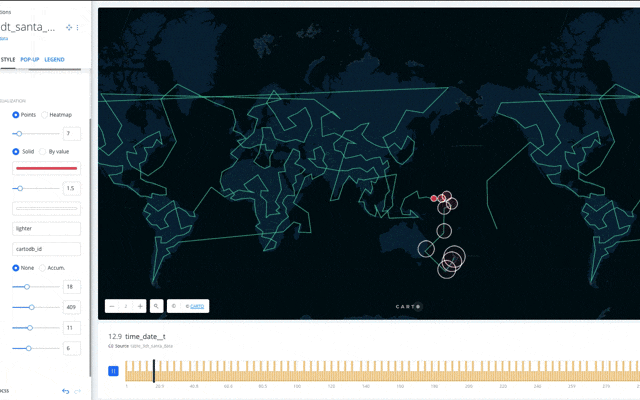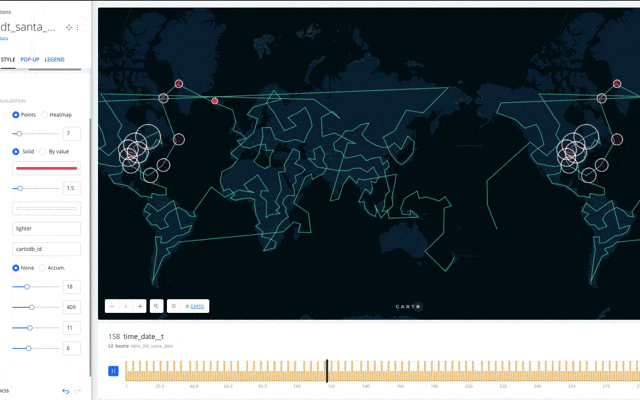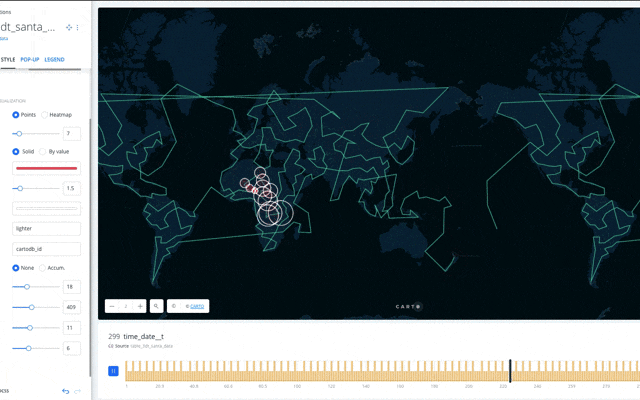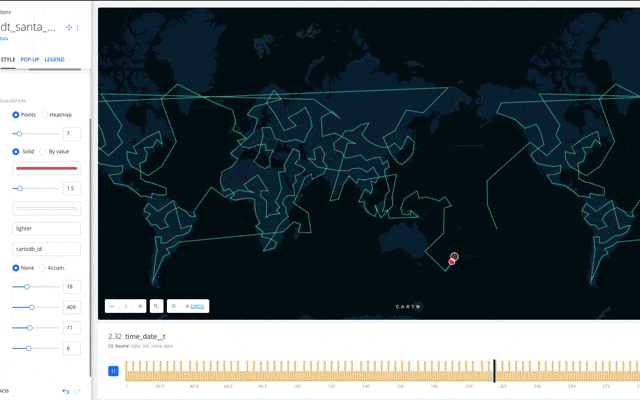
CARTOを使って リアルタイム状況確認してみます。
CARTOは地図上にデータをplotするだけでなく、空間データとして分析、データマイニングが可能です。とりあえずplotしてみました。
また分析機能として、ルートのLine作成などがありますので、これも利用してみます。
以上で、サンタさんのプレゼント配布ルート、行動の可視化ができました。赤色の円がサンタさんの配布ポイントです。
(配達最短ルート順でUploadしたのになぜかCARTO側でルート順が飛んでる。。。CARTOの設定下手くそですいませんorz)
最後に
めでたしめでたし。
AnalyticDB for PostgreSQLといい、Greenplumが便利すぎた記事でした。何よりもOSSとシームレスな連携ができる点が大きいです。
加えて、AnalyticDB for PostgreSQLはPAYG、使った分だけ課金があるので、経済的にもお得です。

おまけ
来年にはAnalyticDB for PostgreSQL が Greenplum6.0系 最新版へUpgradeする。。(かも?)
https://cn.aliyun.com/product/news/detail?id=14561
現在 中国サイトで トライアル提供中のようです。国際サイトでUpgradeできたら、In-Database Analyticsとして分析の幅が今以上に広まることやOLTP、多重ユーザ利用などを考えると楽しみですね。
https://yq.aliyun.com/articles/720538