皆さん、こんにちは大畑と申します。
小売企業でデータサイエンティスト兼データエンジニアとして働いています。データサイエンスの観点からデータの活用方法について、ユニークな洞察を提供したいと思います。
本日のテーマ:Microsoft Fabric 導入時の躓きポイントと対応策
Microsoftのデータ基盤である Microsoft Fabric を私が検証した際に躓いた部分とその対応策をまとめましたので、ぜひ皆さんに共有したいと思います。この内容は、Power BI 勉強会のライトニングトーク会 第7回(2024年12月開催)でお話しした内容を再構成したものです。
データ基盤の重要性
データ活用を成功させるには、しっかりとしたデータ基盤が必要です。データ基盤とは、データの収集、保存、管理、分析を行うサービスやシステムのことです。これには、多様なソースから効率的にデータを集め、安全かつ効率的に保存し、品質を維持しながら適切に管理し、データから有益なインサイトを引き出すことが含まれます。データ基盤が整っていると、データの収集から分析までがスムーズに進み、正確なデータに基づいた意思決定が可能になり、データ管理や分析のコストを削減できます。データ基盤の構築はビジネスの成功に不可欠です。
Microsoft Fabric とは?
Microsoft Fabricは、データの収集、処理、分析、共有を一つのプラットフォームで実現する統合データ分析プラットフォームです。SaaS型で提供され、Azure Data Factory や Power BI、Azure Synapse Analytics などのツールを統合し、データの管理とガバナンスを一元化します。これにより、企業はデータの効率的な活用と迅速な意思決定を支援し、ビジネスのデータ活用力を強化するものです。
躓きポイントと対応策
躓きポイントは全部で三つあります。
- 無料試用版の最大容量に達した
- データストアの種類が多い
- レイクハウスのSQL分析エンドポイントが読み取り専用
1. 無料試用版の最大容量に達した|躓きレベル1
無料試用版の問題
皆さん、Fabricを導入または検証する際、まず無料試用版から始めることが多いと思います。
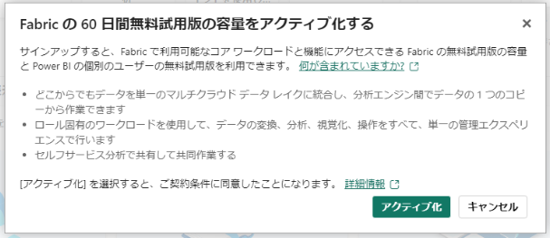
私も無料試用版を申し込んだのですが、「最大容量に達した」というメッセージが表示され、Fabric の無料試用版をアクティブになりませんでした。これには焦りましたが、どう対処すれば良いのかをお伝えします。
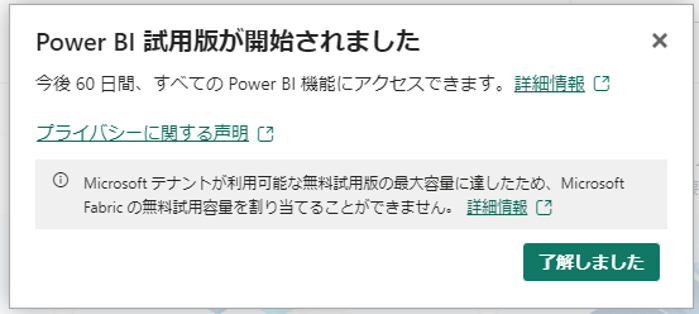
対応策
以下の手順で対応できます:
- 管理画面にアクセス:FabricやPowerBIの管理権限を持つユーザーが管理画面にアクセスします
- 容量の確認:管理画面で、どのユーザーがどれくらいの容量を使用しているかを確認します
- 不要な容量のキャンセル:不要な試用版の容量を使用しているユーザーを見つけ、その容量をキャンセルします
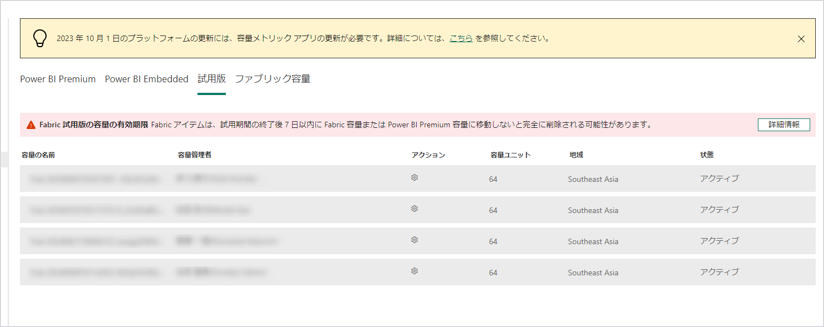

試用版の容量は最大で4つまでしかアクティブにできないようなので、不要な容量をキャンセルすることで、自分の試用版の容量をアクティブにすることができます。これにより、すぐにFabricを利用できるようになりました。
2. データストアの種類が多い|躓きレベル2
データストアの多様性
次に取り上げるのは、データストアの種類が多すぎるという問題です。Fabricを試してみたいと思う方は、同じことを感じたことかあるのではないでしょうか。以下に一覧を示しますが、レイクハウス、ウェアハウス、Fabric SQL Database、Power BI データマート、イベントハウスなど、多くの種類があります。
- レイクハウス
- ウェアハウス
- Fabric SQL Database
- Power BI データマート
- イベントハウス
これらのデータストアの中で、どれを使ってデータを保存すれば良いのか迷うことが多いと思います。これが、躓きポイントの一つです。
対応策
この問題に対する私の対応策は、公式情報を参考にして自社に適したものを選択することです。近道はありませんが、Microsoftから公開されている「Microsoft Fabric決定ガイド」などの公式情報を活用するのが最適です。
これらのガイドを読んで、それぞれのデータストアのメリット・デメリットを比較検討し、自社にとって適切なものを選んでください。
個人的には、レイクハウスの方がFabricの良さを引き出せると思います。なぜなら、ウェアハウスを選んでも、MERGEなどのコマンドが使えないため、工夫が必要な部分はレイクハウスと同じだからです。それならば、レイクハウスを選んだ方が、メリットが大きいと感じています。
参考(抜粋):現時点では、ウェアハウスで以下のコマンドはサポートされていません:
Microsoft Fabric の T-SQL のセキュリティ、外部からのアクセス
- MERGE
- 再帰クエリ
- OPENROWSET
- BULK LOAD
これらの情報を参考にして、自社に適したデータストアを選んでいただければと思います。
3.レイクハウスのSQL分析エンドポイントが読み取り専用|躓きレベル3
読み取り専用の問題
次に紹介するのは、躓きレベル3の問題です。レイクハウスのSQL分析エンドポイントが読み取り専用であるという問題です。
このエンドポイントは、レイクハウスやウェアハウスをデプロイすると生成され、SQLクエリを投げることができます。しかし、読み取り専用モードでしかクエリを実行できないため、データの追加や更新ができません。
エンドポイントでCRUD操作を試す
実際にエンドポイントでCRUD操作(作成、読み出し、更新、削除)を試してみました。
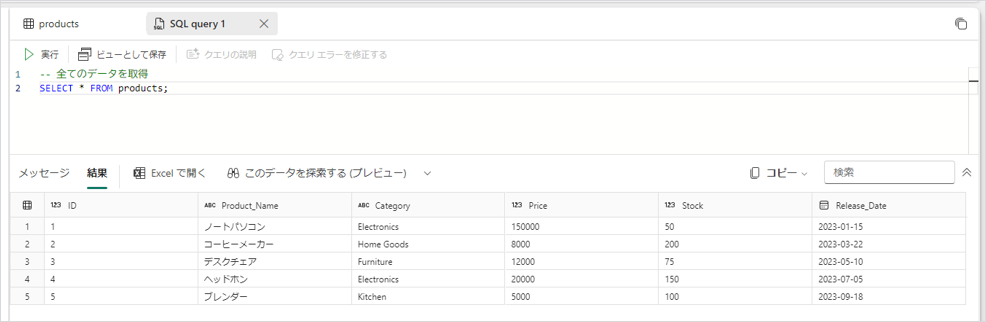
1.読み出し(Read):SELECT文は問題なく実行できました
SELECT * FROM products;
2.作成(Create):CREATE文を実行しようとすると、エラーが発生し、DML(データ操作言語)のクエリはサポートされていないというメッセージが表示されました
INSERT INTO products (ID, Product_Name, Category, Price, Stock, Release_Date) VALUES
(6, 'スマートフォン', 'Electronics', 70000, 80, '2023-11-25');
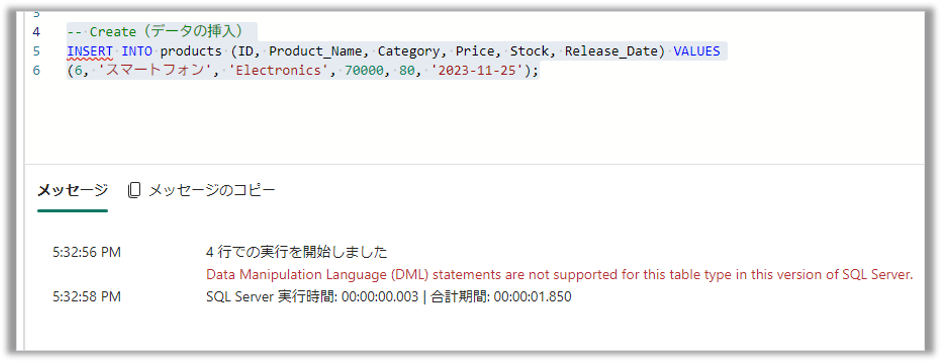
3.更新(Update):UPDATE文も同様にエラーが発生しました
-- 特定の商品(例:IDが1のノートパソコン)の価格を更新
UPDATE products SET Price = 160000 WHERE ID = 1;
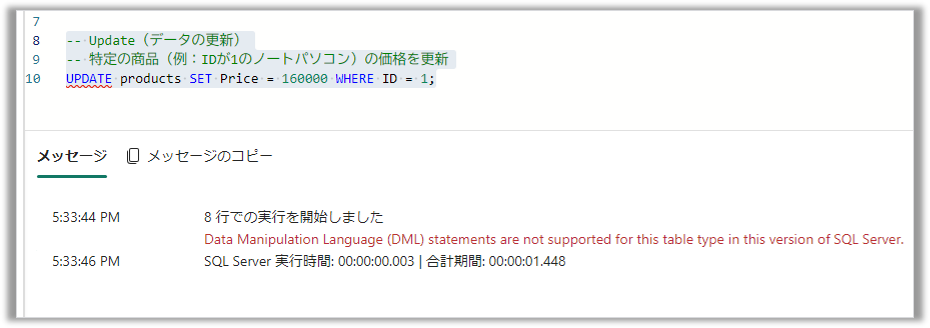
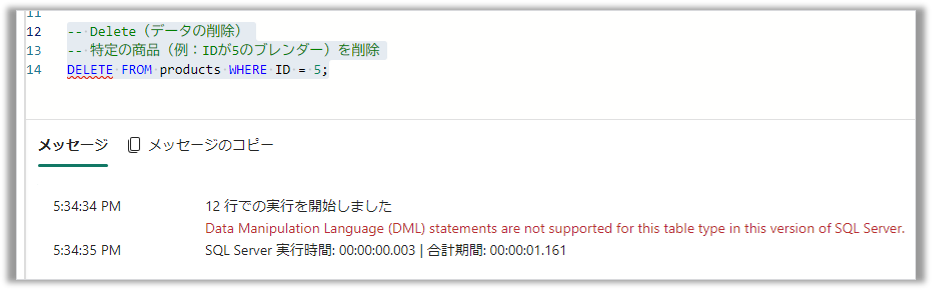
4.削除(Delete):DELETE文もエラーとなり、DML系のコマンドはサポートされていないことが確認できました
-- 特定の商品(例:IDが5のブレンダー)を削除
DELETE FROM products WHERE ID = 5;
対応策:ノートブックでクエリを実行する
この問題に対する対応策として、ノートブックを使用する方法があります。ノートブックは、PythonやSpark SQLなどのプログラミング言語を実行できる環境です。
ノートブックを使用することで、データ操作を行うことができます。特に、Spark SQLモードで実行すると、SQLクエリをそのまま実行することが可能です。



ノートブック (Spark SQL) で、MERGE コマンドを使ったアップサート
ここでは、実際にノートブックを使って成功した例を紹介します。スクリーンショットには、CREATE、UPDATE、DELETEの各操作がデータテーブルに反映された結果が示されています。
ノートブックを使うと、MERGEコマンドも利用できるため非常に便利です。MERGEコマンドを使うことで、新規データはINSERT、既存データはUPDATEするというアップサート操作が一度に実行できます。
-- IDが一致する場合は既存のレコードを更新し、一致しない場合は新しいレコードを挿入します。
MERGE INTO products AS p
USING temp_prod AS tp
ON p.ID = tp.ID
WHEN MATCHED THEN
UPDATE SET
p.Product_Name = tp.Product_Name,
p.Category = tp.Category,
p.Price = tp.Price,
p.Stock = tp.Stock,
p.Release_Date = tp.Release_Date
WHEN NOT MATCHED THEN
INSERT (ID, Product_Name, Category, Price, Stock, Release_Date)
VALUES (tp.ID, tp.Product_Name, tp.Category, tp.Price, tp.Stock, tp.Release_Date);
ノートブック (PySpark) は、4行でアップサート出来るから楽
さらに、ノートブックをPySparkモードに切り替えると、Pythonのコードで簡単にアップサート操作が行えます。実際、PySparkを使えば、たった4行のコードでアップサートが実行できるため非常に便利です。Pythonはプログラミング言語としても使いやすく、少ないコードで効率的に操作が可能です。
# pyspark でマージ処理
from pyspark.sql.functions import coalesce, col
# データフレームの読み込み
products_df = spark.read.format('delta').table('trial_b_lh.products')
temp_prod_df = spark.read.format('delta').table('trial_b_lh.temp_prod')
# マージ処理
columns = ['Product_Name', 'Category', 'Price', 'Stock', 'Release_Date']
select_expr = [col('ID')] + [coalesce(col(f'tp.{col_name}'), col(f'p.{col_name}')).alias(col_name) for col_name in columns]
merged_df = products_df.alias('p').join(temp_prod_df.alias('tp'), 'ID', 'outer').select(*select_expr)
# 結果の表示
display(merged_df)
# 結果の保存(アップサート処理)
merged_df.write.format('delta').mode('overwrite').option('overwriteSchema', 'true').saveAsTable('trial_b_lh.products')
アップサート関連の参考情報
アップサートやデータ更新に関する設計についての参考情報もいくつかあります。例えば、Dataflow Gen2でデータを段階的に蓄積するパターンや、緩やかに変化するディメンションタイプ1などです。これらの情報は、データの実装や処理方法についての公開情報として非常に役立ちます。
特に英語の情報は「SCD(Slowly Changing Dimensions)」のキーワードで検索すると多く見つかります。Microsoftに限らず、他のデータベース関連の情報も出てくるため、データ業界全体で一般的な知識として活用できます。
まとめ
次に、まとめに入ります。
躓きポイントと対応策
- 無料試用版の最大容量に達した場合
- 対応策:不要な試用版の容量をキャンセルする
- データストアの種類が多い
- 対応策:レイクハウスを選ぶことでFabricの良さを引き出せるが、工夫が必要な部分もあることを留意する
- レイクハウスのSQL分析エンドポイントが読み取り専用
- 対策:ノートブックでSpark SQLやPythonコードを書いてデータを操作する。これにより、CREATE、UPDATE、DELETEの各操作が実行可能
最後に
以上が、Fabricを数日間触っただけのナレッジです。もし「ここは違うんじゃないか」とか「こういう選択肢もあるよ」といったご意見があれば、ぜひコメントを送ってください。
Fabricを使い始めてまだ1週間ほどですが、これからも躓きながらどんどん使っていきたいと思います。また新しい躓きポイントや対応策があれば、皆さんにシェアしていきたいと思いますので、今後ともどうぞよろしくお願いいたします。