この記事は この記事誰得? 私しか得しないニッチな技術で記事投稿! - Qiita の参加記事です。
はじめに
先日とある謎解き で、文字化けした鬆ュ謨ーの文字列を戻す必要があることがありました(?)
ちょうど、[改訂新版]プログラマのための文字コード技術入門:書籍案内|技術評論社 を読んだので、練習として「鬆ュ謨ー」がなぜ「頭数」になるのか解説を書きます。
(記事内に誤りがあればコメント等いただけると助かります)
前提
コンピュータでの文字の処理や描画には、文字コードが関係しています。
コンピュータの内部では文字のそれぞれに番号が振られており、その番号を処理しています。
その文字と番号の組み合わせを定めたものが文字コードであり、様々な種類があります。そして、文字コードの種類ごとに文字と番号の組み合わせが異なったりします。
例えばASCIIの場合、Hello World!という文字列は、以下のバイト列になります。
"Hello world!".encode(Encoding::ASCII).bytes.map { |c| sprintf("%#x", c) }
# => ["0x48", "0x65", "0x6c", "0x6c", "0x6f", "0x20", "0x77", "0x6f", "0x72", "0x6c", "0x64", "0x21"]
これをUTF-16で表すと ASCII とは異なるバイト列になります。(BOM は省略している)
"Hello world!".encode(Encoding::UTF_16BE).bytes.map { |c| sprintf("%#x", c) }
# => ["0", "0x48", "0", "0x65", "0", "0x6c", "0", "0x6c", "0", "0x6f", "0", "0x20", "0", "0x77", "0", "0x6f", "0", "0x72", "0", "0x6c", "0", "0x64", "0", "0x21"]
文字化けはなぜ起こるのか
[改訂新版]プログラマのための文字コード技術入門:書籍案内|技術評論社 では、文字化けのよくあるパターンとして以下 2 つが挙げられています。
文字コード A でエンコードされたものを文字コード B で解釈してしまうとき
例) UTF-8で保存したファイルをShift_JISとして表示させた
例) UTF-8のデータの HTTP レスポンスヘッダに異なる charset が指定されていた
機種依存文字が含まれるとき
例) ベンダー A ではとある文字コードの空き領域に ![]() の文字を実装しているが、ベンダー B では同じ空き領域に
の文字を実装しているが、ベンダー B では同じ空き領域に ![]() を実装している場合、
を実装している場合、
「Qiitan かわいいよね ![]() 」と送ったつもりが、相手側では
」と送ったつもりが、相手側では
「Qiitan かわいいよね ![]() 」と表示されてしまう
」と表示されてしまう
「鬆ュ謨ー」はなぜ「頭数」になるのか
文字コード A でエンコードされたものを文字コード B で解釈してしまうとき
から、同じバイト列を異なる文字コードで解釈をすると「鬆ュ謨ー」が「頭数」になるのではないかと考えました。
実際に実験をしてみましょう。
実験
今回は、頭数をUTF-8(現在一般的に使われている)で保存したファイルを、Shift_JIS(こちらも日本で広く使われている)として表示させてみます。
とりあえず、「頭数」をUTF-8でエンコードしたバイト列をみてみます。
"頭数".encode(Encoding::UTF_8).bytes.map { |c| sprintf("%#x", c) }
# => ["0xe9", "0xa0", "0xad", "0xe6", "0x95", "0xb0"]
これをファイルに保存し、Shift_JISとして解釈するようにファイルを開いてみます。
$ od -tx1 atamakazu-utf8.txt
0000000 e9 a0 ad e6 95 b0
0000006
$ nvim atamakazu-utf8.txt
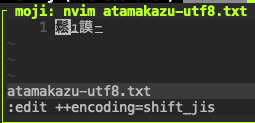
頭数が鬆ュ謨ーになりました。
解説
もう一度、頭数をUTF-8でエンコードしたバイト列をみてみます。
"頭数".encode(Encoding::UTF_8).bytes.map { |c| sprintf("%#x", c) }
# => ["0xe9", "0xa0", "0xad", "0xe6", "0x95", "0xb0"]
頭数の文字はそれぞれ、
-
頭->0xe9 0xa0 0xad -
数->0xe6 0x95 0xb0
のバイト列で表されています。
そして、鬆ュ謨ーをShift_JISでエンコードしたバイト列もみてみます。
'鬆ュ謨ー'.encode(Encoding::Shift_JIS).bytes.map { |c| sprintf("%#x", c) }
# => ["0xe9", "0xa0", "0xad", "0xe6", "0x95", "0xb0"]
頭数をUTF-8でエンコードしたバイト列と同じになっていることがわかります。
鬆ュ謨ーの文字はそれぞれ、
-
鬆->0xe9 0xa0 -
ュ->0xad -
謨->0xe6 0x95 -
ー->0xb0
のバイト列で表されています。
つまり、頭数をUTF-8でエンコードしたバイト列がShift_JISで文字を表現できているため、このように文字化けになっています。
今回は謎解きなので考える必要はないので蛇足ですが、なぜこのような文字化けが発生してしまったかを真面目に考えるとすれば、
-
頭数をUTF-8で保存したファイルを、誤ってShift_JISとして表示させた
のではないかということが推測できます。
さいごに
文字化けした「鬆ュ謨ー」はなぜ「頭数」になるのかについて書きました。
文字コードについて学んだ知識を活かす良いタイミングになったのでよかったです。
また謎解き楽しみにしてます。