はじめに
プログラムが素人でPythonの勉強を始めた人で,環境構築に悩んでいる方を想定して書きました。
Spreadsheetをcolaboratoryで扱うために必要な作業についてまとめました。
前提条件
- colaboratoryを開くことができる
本体
Google Driveを立ち上げ、Colaboratoryを開く。
次のコードを入力する
pandas、numpy、matplotlibは頻繁に使うので最初にインポートしておきます(code00.py)。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
スプレッドシートを扱うための認証作業をする
code01.pyを実行すると・・・
# インポート
import gspread
from google.colab import auth
from gspread_dataframe import get_as_dataframe, set_with_dataframe
from oauth2client.client import GoogleCredentials
# 認証する
auth.authenticate_user()
gc = gspread.authorize(GoogleCredentials.get_application_default())
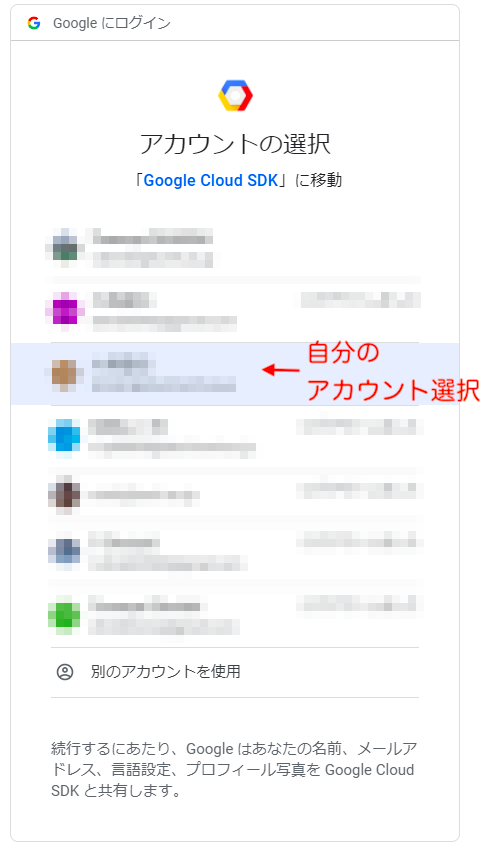
こんな画面になると思います。赤の矢印のURLをクリックします。

自分のアカウント(使用しているアカウント)を選択します。
すると,下の画面が表示されますので,許可をクリックします。

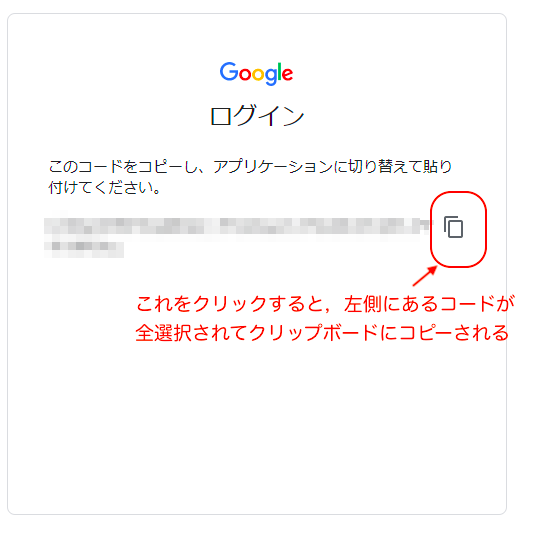
さらに,暗号のようにアルファベットや数字の並んだコードが表示されます。これが認証に用いるコードです。
右にある四角を押すと,認証コードがクリップボードにコピーされます。
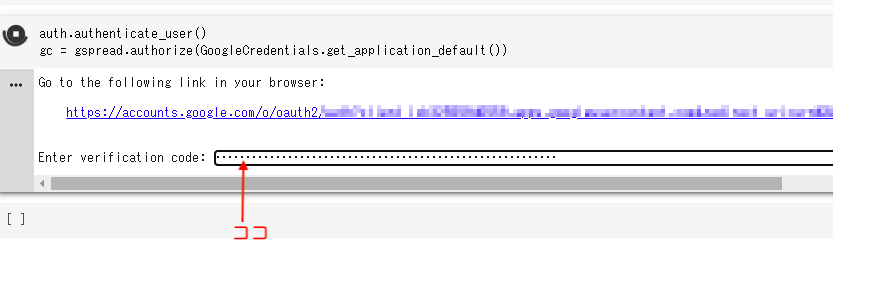
Colaboratoryの画面に戻り,Enter verification codeとある隣のスペースにカーソルをおき,
Ctrl + Vを同時におして貼り付けます。
スプレッドシートを読み込む
シート内のデータを一括してpandasのDataFrame形式に変える方法を例示します。
本題の前に,サンプルのスプレッドシートを作成して作業を進めます。
スプレッドシートを作成する
では,読み込むための例データを作成しましょう。
もしくは,ここにシートをつけておきます。
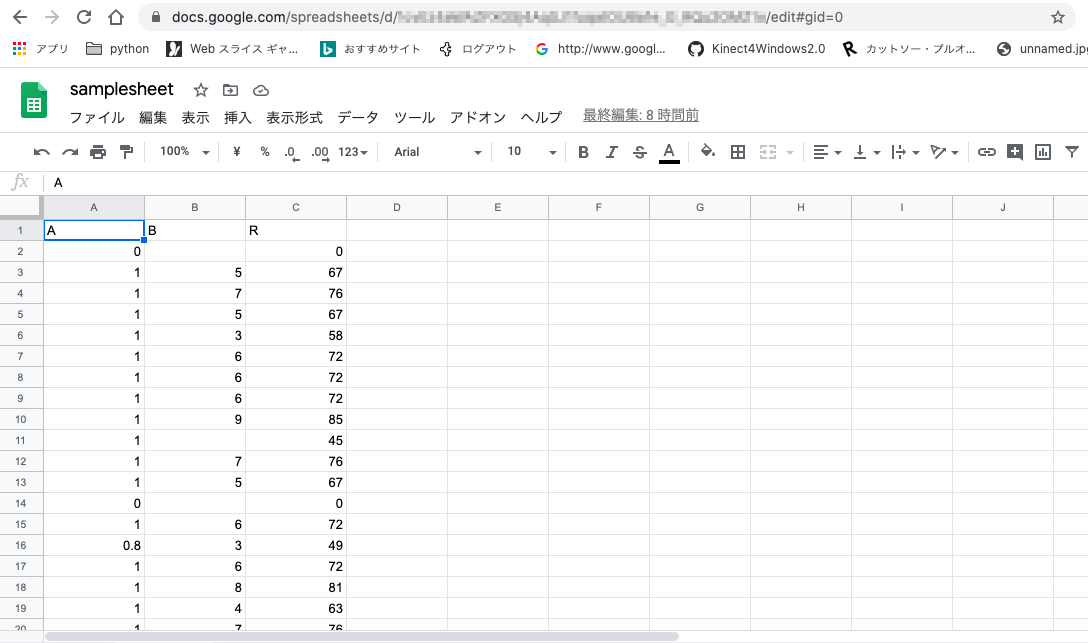
| A | B | R |
|---|---|---|
| 0 | 0 | |
| 1 | 5 | 67 |
| 1 | 7 | 76 |
| 1 | 5 | 67 |
| 1 | 3 | 58 |
| 1 | 6 | 72 |
| 1 | 6 | 72 |
| 1 | 6 | 72 |
| 1 | 9 | 85 |
| 1 | 45 | |
| 1 | 7 | 76 |
| 1 | 5 | 67 |
| 0 | 0 | |
| 1 | 6 | 72 |
| 0.8 | 3 | 49 |
| 1 | 6 | 72 |
| 1 | 8 | 81 |
スプレッドシート内のデータの読み込み
ファイル名を使う場合
ファイル名を使うときは,同じファイル名があると混同されるので,注意します。
スプレッドシートで保存したときのファイル名を文字列型にして ( )内において実行します。
gs = gc.open("samplesheet")
キーを使う場合
はじめに,Spreadsheetのキーを取得します。
キーの取得は,下の図のURLである,
https://docs.google.com/spreadsheets/d/の直後から次のスラッシュまでの間(最後のスラッシュは含まない)が,このスプレッドシートのキーになります。
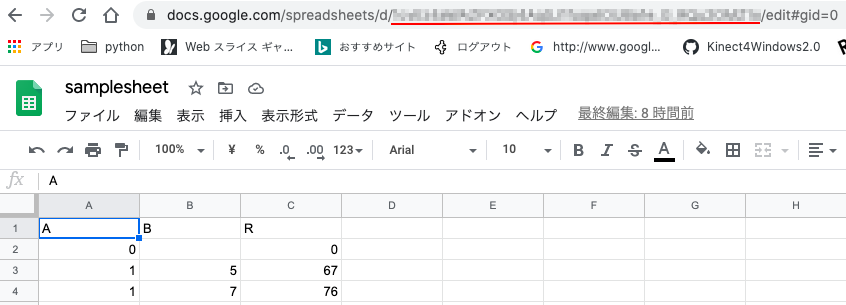
この部分をキー操作でクリップボードにコピー(Ctrl+C)しておきます。
gs = gc.open_by_key("キーをペーストするところ")
データの読み込みとDataFrameへの変換
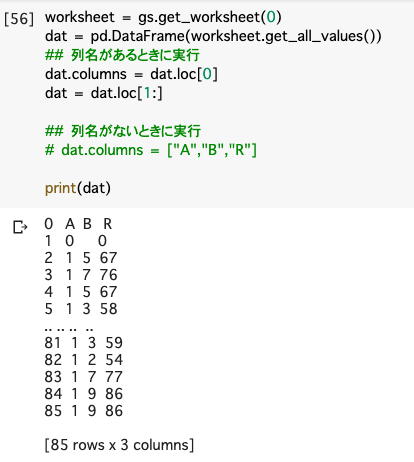
読み込んだデータすべてをDataFrameに変換します。
この前に,スプレッドシートにアクセスしました。それに続けて,その方法について下に例コードを提示します。
worksheet = gs.get_worksheet(0)
dat = pd.DataFrame(worksheet.get_all_values())
## 列名があるとき
dat.columns = dat.loc[0]
dat = dat.loc[1:]
## 列名がないとき
dat.columns = ["A","B","R"]
実行後のcolaboratoryの画面です。
あとは,pandasのDataFrameに対する操作です。
最後に
spreadsheetは無制限で使用できますので,気兼ねなくいろいろなことができます。ネットワーク環境が整っていれば比較的簡単にできると思います。