PMDとは、ソースコードを解析することによってバグや危険な実装を見つけるツールです。PMDを用いることで、簡単にJavaの抽象構文木(AST)を作成することができます。
Eclipse Java Development Tool (JDT) を用いたソースコード解析の説明をesploさんがしてくださっています。
JDTでJavaのソースコード解析を行う
JDTはIDEのプラグインであり、さらにコンパイラなので、解析能力は非常に高いです。しかし、その複雑さと多機能さのため、理解が難しい面もあります。また、AST作成のためだけに重いライブラリを使うのがためらわれることもあります。PMDは(JDTよりは)軽量で手軽に使えるライブラリです。
PMDは高々バグ検出ツールの1つであり、JDTほど一般的ではありません。そのため、バグを含んでいる可能性があります。また、作成されるASTの仕様がJDTと異なる可能性があります。その場合、PMDは一般的なライブラリではないため、妥当性への脅威となり得ます。つまり、ファイルサイズなどを気にしない、研究などでの利用の場合は、JDTを用いるべきということです。
PMDの準備
PMDのライブラリはMaven Central Repository から取得できます。この記事を書いている時点での最新版は5.4.1でした。
net.sourceforge.pmd : pmd-java : 5.4.1
ASTの作成
Java18Parserクラスのコンストラクタに、ParserOptionsのインスタンスを渡して初期化します。Java18Parser.parseメソッドに、ファイル名とファイル読み込みインスタンスを渡すとパース結果が返ってきます。
Path path = Paths.get("src/main/java/MyPmdJava.java");
try (BufferedReader br = Files.newBufferedReader(path)) {
ParserOptions options = new ParserOptions();
Java18Parser java18Parser = new Java18Parser(options);
ASTCompilationUnit unit = (ASTCompilationUnit) java18Parser.parse(path.getFileName().toString(), br);
}
ビジターでASTノードをめぐる
それでは、作成したASTを解析してみましょう。今回は、ソースファイル中に各AST要素がどの程度含まれているのかを数えてみます。
JavaParserVisitorインターフェースを実装したクラスのvisitメソッドに、めぐりたいASTのノードを渡します。すると、ビジターが各ノードをめぐる旅に出ます。JavaParserVisitorを1から実装するのは大変なので、インターフェースを実装したJavaParserVisitorAdapterクラスの一部をオーバーライドし、追加したい処理を実装します。
import net.sourceforge.pmd.lang.java.ast.JavaNode;
import net.sourceforge.pmd.lang.java.ast.JavaParserVisitorAdapter;
import java.util.HashMap;
import java.util.Map;
public class AstElementsCounter extends JavaParserVisitorAdapter {
public final Map<Class<? extends JavaNode>, Integer> elements = new HashMap<>();
@Override
public Object visit(JavaNode node, Object data) {
elements.merge(node.getClass(), 1, (a, b) -> a + b);
return super.visit(node, data);
}
}
ビジターを上のように実装しました。さて、このビジターでノードをめぐってみます。
import net.sourceforge.pmd.lang.ParserOptions;
import net.sourceforge.pmd.lang.java.Java18Parser;
import net.sourceforge.pmd.lang.java.ast.ASTCompilationUnit;
import java.io.BufferedReader;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
public class MyPmdJava {
public static void main(String[] args) throws IOException {
Path path = Paths.get("src/main/java/MyPmdJava.java");
try (BufferedReader br = Files.newBufferedReader(path)) {
ParserOptions options = new ParserOptions();
Java18Parser java18Parser = new Java18Parser(options);
ASTCompilationUnit unit = (ASTCompilationUnit) java18Parser.parse(path.getFileName().toString(), br);
AstElementsCounter visitor = new AstElementsCounter();
visitor.visit(unit, null);
visitor.elements.forEach((a,b) -> System.out.format("%s : %d%n", a.getSimpleName(), b));
}
}
}
この出力結果は、以下のようになります。
ASTStatementExpression : 2
ASTResourceSpecification : 1
ASTClassOrInterfaceBodyDeclaration : 1
......以下略
ツリー構造の出力
ASTをツリー構造で出力してみます。
import net.sourceforge.pmd.lang.java.ast.JavaNode;
import net.sourceforge.pmd.lang.java.ast.JavaParserVisitorAdapter;
public class AstElementsCounter extends JavaParserVisitorAdapter {
int depth = 0;
@Override
public Object visit(JavaNode node, Object data) {
for (int i=0; i<depth; i++) {
System.out.print(" ");
}
System.out.printf("%s <%d:%d>%n", node, node.getBeginLine(), node.getBeginColumn());
depth++;
Object returnValue = super.visit(node, data);
depth--;
return returnValue;
}
}
この出力は以下のようになります。
CompilationUnit <1:1>
ImportDeclaration <1:1>
Name <1:8>
ImportDeclaration <2:1>
Name <2:8>
ASTノード名と行番号・カラム番号が1行毎に出力されます。
さて、コメントはAST上には存在しません。とういうのは、コメントは構文解析の前段階である字句解析の段階で取り除かれるからです。コメントを取得するには、パースした結果のASTCompilationUnitのgetComments()で取得できます。
ParserOptions options = new ParserOptions();
Java18Parser java18Parser = new Java18Parser(options);
ASTCompilationUnit unit = (ASTCompilationUnit) java18Parser.parse(path.getFileName().toString(), br);
System.out.println(unit.getComments().get(0));
ASTを超えて
PMDではこのビジターを実装することによって、バグっぽいソースコードのパターンを分析します。そのパターンのことを、PMDではルールといいます。
例えば、データフローグラフを検出するルールを使うには、以下のようにします。
public class MyPmdJava {
public static void main(String[] args) throws IOException, PMDException {
Path path = Paths.get("src/main/java/MyPmdJava.java");
try (BufferedReader br = Files.newBufferedReader(path)) {
PMDConfiguration config = new PMDConfiguration();
RuleSet rs = new RuleSet();
JavaDFAGraphRule javaDFAGraphRule = new JavaDFAGraphRule();
rs.addRule(javaDFAGraphRule);
RuleContext rc = new RuleContext();
rc.setSourceCodeFilename("[no filename].java");
new SourceCodeProcessor(config).processSourceCode(br, new RuleSets(rs), rc);
// javaDFAGraphRuleをここでいじいじする
}
}
}
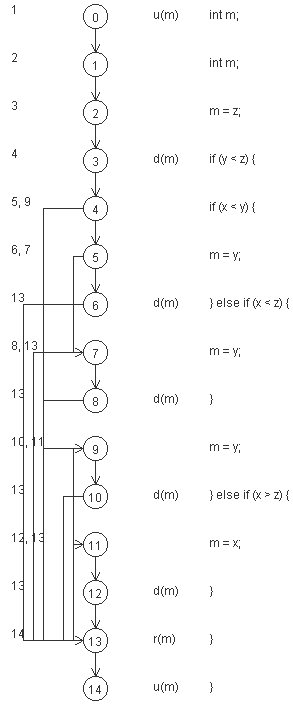
例えば、中央値を求めるプログラムMidのデータフローグラフを出力してみると、以下のようになります。(図はPMD Rule Editorを用いて作成)
public class Mid {
public static int mid(int x, int y, int z) {
int m;
m = z;
if (y < z) {
if (x < y) {
m = y;
} else if (x < z) {
m = y;
}
} else {
if (x > y) {
m = y;
} else if (x > z) {
m = x;
}
}
return m;
}
}
Fin.