LinkDataというオープンデータの共有サービスがあるのだけど,その中のデータをCSV形式でダウンロードをする時に,
アカウント単位で全部落とすような方法はないので作った.
アカウントのIDを入れると,そのアカウントのリポジトリをまとめて全部or必要なものを選択してダウンロードできる.
何も選択しなければ愛知県半田市のデータがダウンロードされる.
linkdata-crawler.py
# encoding: utf-8
import urllib.request
import urllib.parse
import json
import os
import sys
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
import time
import re
import inquirer
def main():
print('''
This script get all datasets for a specific user at LinkData.org
you need chromedriver, if you don't have it `brew cask install chromedriver`
Press ^C at any time to quit.
''')
account_id = ""
args = sys.argv
if len(args) < 2:
account_id = input("account id: (kouhou_handacity) ")
if len(account_id) == 0:
account_id = "kouhou_handacity"
options = Options()
options.add_argument('--disable-gpu')
options.add_argument('--headless')
driver = webdriver.Chrome(chrome_options=options)
driver.get("https://user.linkdata.org/user/{0}/work".format(account_id))
while True:
try:
WebDriverWait(driver, 30).until(EC.presence_of_all_elements_located)
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
driver.find_element_by_class_name("btn-more").click()
time.sleep(3)
print("click")
except Exception as e:
print(e)
break
path_list = {}
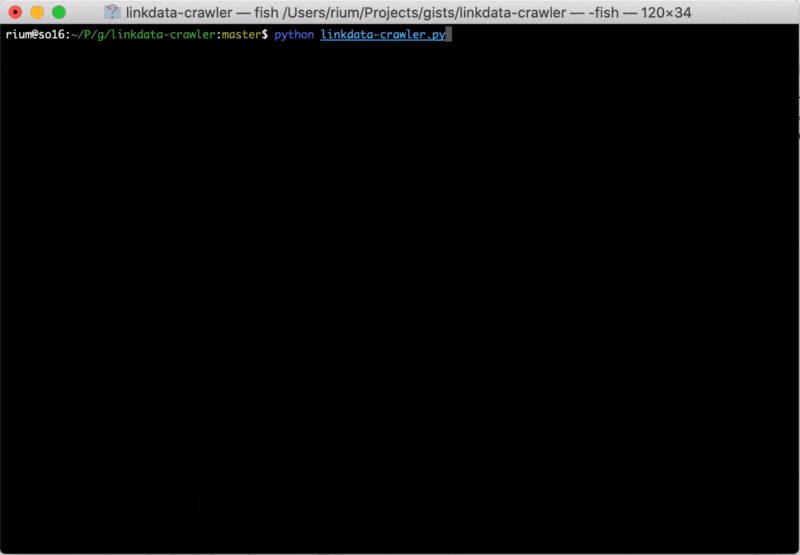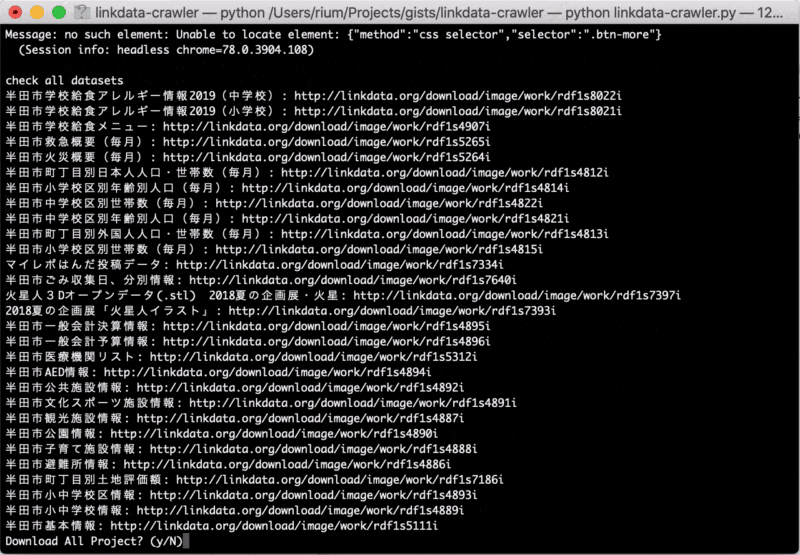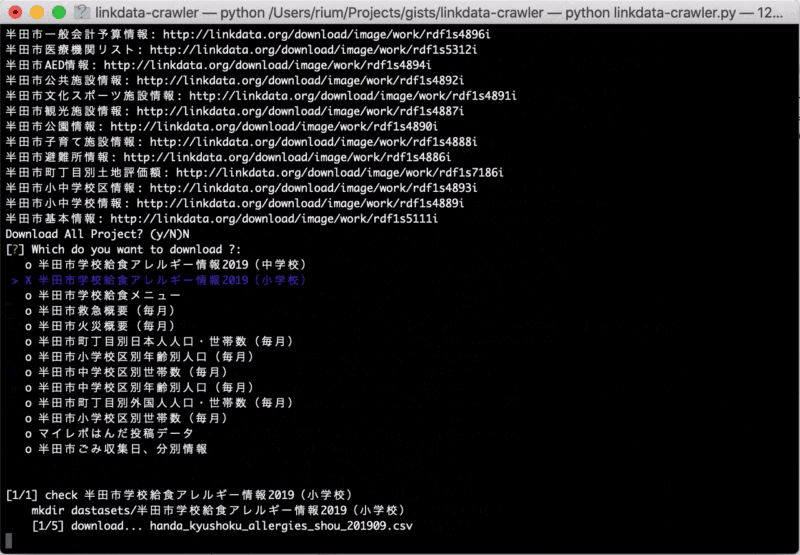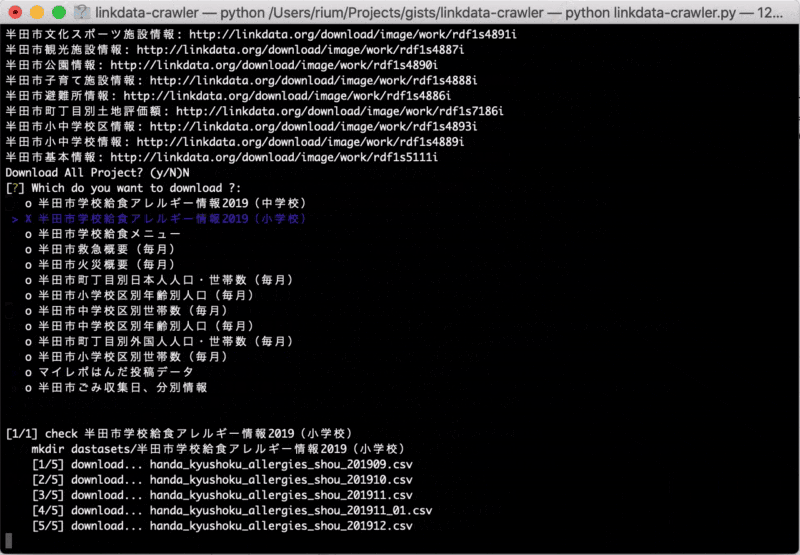
print("check all datasets")
for user_image_path in driver.find_elements_by_class_name('entity'):
dataset_name = user_image_path.find_elements_by_class_name("entity_name")[0].get_attribute("title")
dataset_path = user_image_path.find_elements_by_class_name("user_image")[0].get_attribute("src")
if 'rdf' in dataset_path:
print("{0}: {1}".format(dataset_name, dataset_path))
path_list[str(dataset_name)] = str(dataset_path)
driver.quit()
repos = path_list.keys()
while True:
check = input("Download All Project? (y/N)")
if (check == "y") or (check == ""):
break
elif (check == "N"):
questions = [
inquirer.Checkbox(
'datasets',
message="\nWhich do you want to download ?",
choices=repos
)
]
answers = inquirer.prompt(questions)
repos = answers["datasets"]
break
for i, r in enumerate(repos):
time.sleep(1)
print("\n[{0}/{1}] check {2}".format(i+1, len(repos), r))
if not os.path.exists("datasets/"+r):
print(" mkdir dastasets/{0}".format(r))
os.makedirs("datasets/" + r)
req = urllib.request.Request("http://linkdata.org/api/1/{0}/datapackage.json".format(os.path.basename(path_list[r])))
with urllib.request.urlopen(req) as response:
html = response.read().decode("utf-8")
all_data = json.loads(html)
all_project = all_data["resources"]
for j, proj in enumerate(all_project):
time.sleep(1)
csv_name = os.path.basename(proj["url"])
csv_path = proj["url"]
if not os.path.isfile("datasets/"+r+"/"+csv_name):
print(" [{0}/{1}] download... {2}".format(j+1, len(all_project), csv_name))
urllib.request.urlretrieve(csv_path, "datasets/"+r+"/"+csv_name)
else:
print(" [{0}/{1}] {2} already exists".format(j+1, len(all_project), csv_name))
print("end")
if __name__ == "__main__":
main()
そんな大したものは使ってないけど,依存関係のあるファイルはこれをつかてください.
requirements.txt
blessings==1.7
inquirer==2.6.3
python-editor==1.0.4
readchar==2.0.1
selenium==3.141.0
six==1.12.0
urllib3==1.25.6
誰かの参考になれば.