
はじめに
情報システム部にいると、「OCRを試してみたい」とか「紙の帳票はやめないが、効率化を図りたい」などといろいろな引き合いが舞い込んできます。そのためOCRを小さなプロジェクトやPoCで試すことも多いのですが、文字認識の精度のせいなのか、ほとんどは立ち消えになってしまっています。
一方で、最近リリースされたgpt-4oは画像認識が可能であり、OCRよりも精度が高いのではないか?と思い始めました。
今回は、OCRとgpt-4o(お金がないので正確にはgpt-4o-mini)の読み取り精度を確認したいと思います。
GPT-4o
今回紹介するプログラムは、指定した画像を生成AIに渡して、その結果を出力するというプログラムです。
base64は標準ライブラリなので、改めてインストールする必要は無いようです。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.prompts.chat import HumanMessagePromptTemplate
import base64
from langchain_core.prompts.image import ImagePromptTemplate
question = """
図の中の文字を答えて
"""
image_path = "C:\\Users\\ogiki\\Desktop\\data\\大阪ばんざい.jpg"
system = (
"あなたは有能なアシスタントです。ユーザーの問いに回答してください"
)
## =================================================================
#画像ファイルをbase64エンコードする
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
base64_image = encode_image(image_path)
image_template = {"image_url": {"url": f"data:image/png;base64,{base64_image}"}}
chat = ChatOpenAI(temperature=0, model_name="gpt-4o-mini")
#chat = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
human_prompt = "{question}"
human_message_template = HumanMessagePromptTemplate.from_template([human_prompt, image_template])
prompt = ChatPromptTemplate.from_messages([("system", system), human_message_template])
chain = prompt | chat
result = chain.invoke({"question": question})
print(result)
プログラム上にgpt-3.5-turboが記述されているコード(コメントアウトしている)がありますが、もちろんこれを実行するとエラーが出ました。gpt-3.5-turebには画像認識の処理はありませんものね。
OCR
次にオープンソースのOCRを利用するためのプログラムを書きます。
今回はTesseractというライブラリを使うことにしました。Windowsでのインストールができるという事で、それをPythonのプログラムで操作することにしました。
インストールは、以下の投稿記事を参考にしました。
@henjiganaiさん、わかりやすい記事を書いていただきありがとうございました。
また、最初にTesseractを理解するために、以下の記事も参考にしました。
@ku_a_i(ku_a_i)さんもありがとうございます。非常にわかりやすかったです。
インストールはうまくいったのですが、その後Pythonのプログラムを実行しようとするとエラーが出ました。
いろいろ確認すると、tesseract.exeのパスがうまく通っていないようです。
上記の投稿記事を基に(kinopi さんありがとうございます)、Pythonライブラリの中のpytesseract.pyの中にあるtesseract_cmdの値を自分のパソコンのパスに置き換えて、pytesseract.pyを実行ファイルと同一ディレクトリに置くことでプログラムをうまく動かすことができました。一旦はこの形で進めていきます。
以下にpytesseract.pyを転記します。もし私と同じ状況に陥った場合、これをそのままコピーして31行目のtesseract_comの部分を皆様のインストールされた場所に変更し、実行ファイルと同一ディレクトリに置いていただけると実行できます。
#!/usr/bin/env python
import re
import shlex
import string
import subprocess
import sys
from contextlib import contextmanager
from csv import QUOTE_NONE
from errno import ENOENT
from functools import wraps
from glob import iglob
from io import BytesIO
from os import environ
from os import extsep
from os import linesep
from os import remove
from os.path import normcase
from os.path import normpath
from os.path import realpath
from pkgutil import find_loader
from tempfile import NamedTemporaryFile
from time import sleep
from packaging.version import InvalidVersion
from packaging.version import parse
from packaging.version import Version
from PIL import Image
#tesseract_cmd = 'tesseract'
tesseract_cmd = 'C:\\Program Files\\Tesseract-OCR\\tesseract.exe'
numpy_installed = find_loader('numpy') is not None
if numpy_installed:
from numpy import ndarray
pandas_installed = find_loader('pandas') is not None
if pandas_installed:
import pandas as pd
DEFAULT_ENCODING = 'utf-8'
LANG_PATTERN = re.compile('^[a-z_]+$')
RGB_MODE = 'RGB'
SUPPORTED_FORMATS = {
'JPEG',
'JPEG2000',
'PNG',
'PBM',
'PGM',
'PPM',
'TIFF',
'BMP',
'GIF',
'WEBP',
}
OSD_KEYS = {
'Page number': ('page_num', int),
'Orientation in degrees': ('orientation', int),
'Rotate': ('rotate', int),
'Orientation confidence': ('orientation_conf', float),
'Script': ('script', str),
'Script confidence': ('script_conf', float),
}
TESSERACT_MIN_VERSION = Version('3.05')
TESSERACT_ALTO_VERSION = Version('4.1.0')
class Output:
BYTES = 'bytes'
DATAFRAME = 'data.frame'
DICT = 'dict'
STRING = 'string'
class PandasNotSupported(EnvironmentError):
def __init__(self):
super().__init__('Missing pandas package')
class TesseractError(RuntimeError):
def __init__(self, status, message):
self.status = status
self.message = message
self.args = (status, message)
class TesseractNotFoundError(EnvironmentError):
def __init__(self):
super().__init__(
f"{tesseract_cmd} is not installed or it's not in your PATH."
f' See README file for more information.',
)
class TSVNotSupported(EnvironmentError):
def __init__(self):
super().__init__(
'TSV output not supported. Tesseract >= 3.05 required',
)
class ALTONotSupported(EnvironmentError):
def __init__(self):
super().__init__(
'ALTO output not supported. Tesseract >= 4.1.0 required',
)
def kill(process, code):
process.terminate()
try:
process.wait(1)
except TypeError: # python2 Popen.wait(1) fallback
sleep(1)
except Exception: # python3 subprocess.TimeoutExpired
pass
finally:
process.kill()
process.returncode = code
@contextmanager
def timeout_manager(proc, seconds=None):
try:
if not seconds:
yield proc.communicate()[1]
return
try:
_, error_string = proc.communicate(timeout=seconds)
yield error_string
except subprocess.TimeoutExpired:
kill(proc, -1)
raise RuntimeError('Tesseract process timeout')
finally:
proc.stdin.close()
proc.stdout.close()
proc.stderr.close()
def run_once(func):
@wraps(func)
def wrapper(*args, **kwargs):
if wrapper._result is wrapper:
wrapper._result = func(*args, **kwargs)
return wrapper._result
wrapper._result = wrapper
return wrapper
def get_errors(error_string):
return ' '.join(
line for line in error_string.decode(DEFAULT_ENCODING).splitlines()
).strip()
def cleanup(temp_name):
"""Tries to remove temp files by filename wildcard path."""
for filename in iglob(f'{temp_name}*' if temp_name else temp_name):
try:
remove(filename)
except OSError as e:
if e.errno != ENOENT:
raise
def prepare(image):
if numpy_installed and isinstance(image, ndarray):
image = Image.fromarray(image)
if not isinstance(image, Image.Image):
raise TypeError('Unsupported image object')
extension = 'PNG' if not image.format else image.format
if extension not in SUPPORTED_FORMATS:
raise TypeError('Unsupported image format/type')
if 'A' in image.getbands():
# discard and replace the alpha channel with white background
background = Image.new(RGB_MODE, image.size, (255, 255, 255))
background.paste(image, (0, 0), image.getchannel('A'))
image = background
image.format = extension
return image, extension
@contextmanager
def save(image):
try:
with NamedTemporaryFile(prefix='tess_', delete=False) as f:
if isinstance(image, str):
yield f.name, realpath(normpath(normcase(image)))
return
image, extension = prepare(image)
input_file_name = f'{f.name}_input{extsep}{extension}'
image.save(input_file_name, format=image.format)
yield f.name, input_file_name
finally:
cleanup(f.name)
def subprocess_args(include_stdout=True):
# See https://github.com/pyinstaller/pyinstaller/wiki/Recipe-subprocess
# for reference and comments.
kwargs = {
'stdin': subprocess.PIPE,
'stderr': subprocess.PIPE,
'startupinfo': None,
'env': environ,
}
if hasattr(subprocess, 'STARTUPINFO'):
kwargs['startupinfo'] = subprocess.STARTUPINFO()
kwargs['startupinfo'].dwFlags |= subprocess.STARTF_USESHOWWINDOW
kwargs['startupinfo'].wShowWindow = subprocess.SW_HIDE
if include_stdout:
kwargs['stdout'] = subprocess.PIPE
else:
kwargs['stdout'] = subprocess.DEVNULL
return kwargs
def run_tesseract(
input_filename,
output_filename_base,
extension,
lang,
config='',
nice=0,
timeout=0,
):
cmd_args = []
if not sys.platform.startswith('win32') and nice != 0:
cmd_args += ('nice', '-n', str(nice))
cmd_args += (tesseract_cmd, input_filename, output_filename_base)
if lang is not None:
cmd_args += ('-l', lang)
if config:
cmd_args += shlex.split(config)
if extension and extension not in {'box', 'osd', 'tsv', 'xml'}:
cmd_args.append(extension)
try:
proc = subprocess.Popen(cmd_args, **subprocess_args())
except OSError as e:
if e.errno != ENOENT:
raise
else:
raise TesseractNotFoundError()
with timeout_manager(proc, timeout) as error_string:
if proc.returncode:
raise TesseractError(proc.returncode, get_errors(error_string))
def run_and_get_output(
image,
extension='',
lang=None,
config='',
nice=0,
timeout=0,
return_bytes=False,
):
with save(image) as (temp_name, input_filename):
kwargs = {
'input_filename': input_filename,
'output_filename_base': temp_name,
'extension': extension,
'lang': lang,
'config': config,
'nice': nice,
'timeout': timeout,
}
run_tesseract(**kwargs)
filename = f"{kwargs['output_filename_base']}{extsep}{extension}"
with open(filename, 'rb') as output_file:
if return_bytes:
return output_file.read()
return output_file.read().decode(DEFAULT_ENCODING)
def file_to_dict(tsv, cell_delimiter, str_col_idx):
result = {}
rows = [row.split(cell_delimiter) for row in tsv.strip().split('\n')]
if len(rows) < 2:
return result
header = rows.pop(0)
length = len(header)
if len(rows[-1]) < length:
# Fixes bug that occurs when last text string in TSV is null, and
# last row is missing a final cell in TSV file
rows[-1].append('')
if str_col_idx < 0:
str_col_idx += length
for i, head in enumerate(header):
result[head] = list()
for row in rows:
if len(row) <= i:
continue
if i != str_col_idx:
try:
val = int(float(row[i]))
except ValueError:
val = row[i]
else:
val = row[i]
result[head].append(val)
return result
def is_valid(val, _type):
if _type is int:
return val.isdigit()
if _type is float:
try:
float(val)
return True
except ValueError:
return False
return True
def osd_to_dict(osd):
return {
OSD_KEYS[kv[0]][0]: OSD_KEYS[kv[0]][1](kv[1])
for kv in (line.split(': ') for line in osd.split('\n'))
if len(kv) == 2 and is_valid(kv[1], OSD_KEYS[kv[0]][1])
}
@run_once
def get_languages(config=''):
cmd_args = [tesseract_cmd, '--list-langs']
if config:
cmd_args += shlex.split(config)
try:
result = subprocess.run(
cmd_args,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
)
except OSError:
raise TesseractNotFoundError()
# tesseract 3.x
if result.returncode not in (0, 1):
raise TesseractNotFoundError()
languages = []
if result.stdout:
for line in result.stdout.decode(DEFAULT_ENCODING).split(linesep):
lang = line.strip()
if LANG_PATTERN.match(lang):
languages.append(lang)
return languages
@run_once
def get_tesseract_version():
"""
Returns Version object of the Tesseract version
"""
try:
output = subprocess.check_output(
[tesseract_cmd, '--version'],
stderr=subprocess.STDOUT,
env=environ,
stdin=subprocess.DEVNULL,
)
except OSError:
raise TesseractNotFoundError()
raw_version = output.decode(DEFAULT_ENCODING)
str_version, *_ = raw_version.lstrip(string.printable[10:]).partition(' ')
str_version, *_ = str_version.partition('-')
try:
version = parse(str_version)
assert version >= TESSERACT_MIN_VERSION
except (AssertionError, InvalidVersion):
raise SystemExit(f'Invalid tesseract version: "{raw_version}"')
return version
def image_to_string(
image,
lang=None,
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
):
"""
Returns the result of a Tesseract OCR run on the provided image to string
"""
args = [image, 'txt', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DICT: lambda: {'text': run_and_get_output(*args)},
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def image_to_pdf_or_hocr(
image,
lang=None,
config='',
nice=0,
extension='pdf',
timeout=0,
):
"""
Returns the result of a Tesseract OCR run on the provided image to pdf/hocr
"""
if extension not in {'pdf', 'hocr'}:
raise ValueError(f'Unsupported extension: {extension}')
args = [image, extension, lang, config, nice, timeout, True]
return run_and_get_output(*args)
def image_to_alto_xml(
image,
lang=None,
config='',
nice=0,
timeout=0,
):
"""
Returns the result of a Tesseract OCR run on the provided image to ALTO XML
"""
if get_tesseract_version() < TESSERACT_ALTO_VERSION:
raise ALTONotSupported()
config = f'-c tessedit_create_alto=1 {config.strip()}'
args = [image, 'xml', lang, config, nice, timeout, True]
return run_and_get_output(*args)
def image_to_boxes(
image,
lang=None,
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
):
"""
Returns string containing recognized characters and their box boundaries
"""
config = f'{config.strip()} batch.nochop makebox'
args = [image, 'box', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DICT: lambda: file_to_dict(
f'char left bottom right top page\n{run_and_get_output(*args)}',
' ',
0,
),
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def get_pandas_output(args, config=None):
if not pandas_installed:
raise PandasNotSupported()
kwargs = {'quoting': QUOTE_NONE, 'sep': '\t'}
try:
kwargs.update(config)
except (TypeError, ValueError):
pass
return pd.read_csv(BytesIO(run_and_get_output(*args)), **kwargs)
def image_to_data(
image,
lang=None,
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
pandas_config=None,
):
"""
Returns string containing box boundaries, confidences,
and other information. Requires Tesseract 3.05+
"""
if get_tesseract_version() < TESSERACT_MIN_VERSION:
raise TSVNotSupported()
config = f'-c tessedit_create_tsv=1 {config.strip()}'
args = [image, 'tsv', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DATAFRAME: lambda: get_pandas_output(
args + [True],
pandas_config,
),
Output.DICT: lambda: file_to_dict(run_and_get_output(*args), '\t', -1),
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def image_to_osd(
image,
lang='osd',
config='',
nice=0,
output_type=Output.STRING,
timeout=0,
):
"""
Returns string containing the orientation and script detection (OSD)
"""
config = f'--psm 0 {config.strip()}'
args = [image, 'osd', lang, config, nice, timeout]
return {
Output.BYTES: lambda: run_and_get_output(*(args + [True])),
Output.DICT: lambda: osd_to_dict(run_and_get_output(*args)),
Output.STRING: lambda: run_and_get_output(*args),
}[output_type]()
def main():
if len(sys.argv) == 2:
filename, lang = sys.argv[1], None
elif len(sys.argv) == 4 and sys.argv[1] == '-l':
filename, lang = sys.argv[3], sys.argv[2]
else:
print('Usage: pytesseract [-l lang] input_file\n', file=sys.stderr)
return 2
try:
with Image.open(filename) as img:
print(image_to_string(img, lang=lang))
except TesseractNotFoundError as e:
print(f'{str(e)}\n', file=sys.stderr)
return 1
except OSError as e:
print(f'{type(e).__name__}: {e}', file=sys.stderr)
return 1
if __name__ == '__main__':
exit(main())
また、実行ファイルは以下となります。
import pytesseract
from PIL import Image
import pandas as pd
def image_to_text(image_path):
# 画像を読み込む
img = Image.open(image_path)
# TesseractでOCRを実行
custom_config = r'--oem 1 --psm 6'
text = pytesseract.image_to_string(img, config=custom_config, lang='jpn')
return text
if __name__ == "__main__":
image_path = 'C:/Users/ogiki/Desktop/data/大阪ばんざい.jpg'
text = image_to_text(image_path)
print(text)
# ファイル保存
csv_path = 'output_ocr.csv'
rows = text.split('\n\n')
table_data = []
for row in rows:
#if row.strip():
table_data.append(row)
df = pd.DataFrame(table_data)
df.to_csv(csv_path, index=False, header=False)
ここにcustom_config = r'--oem 1 --psm 6'とあるのですが、oemとpsmは以下の意味があるようです。
oem (OCRエンジン切替)
| オプション | 説明 |
|---|---|
| 0 | 以前(3.5まで)のTesseractエンジンのみを使用する |
| 1 | ニューラルネットLSTMのみを使用する |
| 2 | TesseractエンジンとLSTM両方使用する |
| 3 | デフォルト。LSTMとTesseractエンジンを状況に応じて使用する |
psm (ページセグメンテーションモード)
| オプション | 説明 |
|---|---|
| 0 | 文字角度の識別と書字系のみの認識(OSD)のみ実施(outputbase.osdが出力され、OCRは行われない) |
| 1 | OSDと自動ページセグメンテーション |
| 2 | OSDなしの自動セグメンテーション(OCRは行われない) |
| 3 | OSDなしの完全自動セグメンテーション(デフォルト) |
| 4 | 可変サイズの1列テキストを想定する |
| 5 | 縦書きの単一のテキストブロックとみなす |
| 6 | 単一のテキストブロックとみなす(5と異なる点は横書きのみ) |
| 7 | 画像を1行のテキストとみなす |
| 8 | 画像を単語とみなす |
| 9 | 円の中に記載された1単語とみなす(例:①、⑥など) |
| 10 | 画像を1文字とみなす |
| 11 | まだらなテキスト。特定の順序でなるべく多くの単語を検出する(角度無し) |
| 12 | 文字角度検出を実施(OSD)しかつ、まだらなテキストとしてなるべく多くの単語を検出する |
| 13 | Tesseract固有の処理を回避して1行のテキストとみなす |
以下の投稿記事を参考にしています。
次章(「比較するサンプル」)で説明しますが、今回はjpeg形式の文字列(英語・数字・日本語の文字)の認識精度を比較するため、psmは「6」、oemは「1」として設定しました。
比較するサンプル
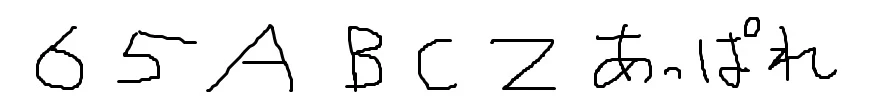
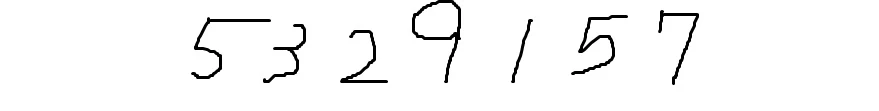
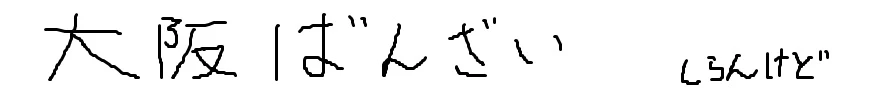
以上3つの画像ファイルをOCRとOpenAIに読み込ませてみることにしました。
最後の画像の「しらんけど」は大阪のおばちゃんが自信満々に話をした後に発する定型文です。あまり気になさらぬよう・・・
比較結果
以下が比較結果となります。
| 文字列 | OCR | gpt-4o-mini |
|---|---|---|
| 65ABCZあっぱれ | 6 ダを作 6てCあ.ばれ | 図の中の文字は「65 ABCZ あっぱれ」です。 |
| 5329157 | 2コ2ブ7/ら7 | 図の中の数値は「5329/57」です。 |
| 大阪ばんざい | 大、阪 1はんざい し5ん1けと" | 図の中の文字は「大阪ばんざい」と「しらんけど」です。 |
どうでしょうか。今回に限っては断然gpt-4o-miniに軍配が上がりました。
ただ、今回のOCRはオープンソースのものを使っているため、有償OCRなどであればもっと精度が高まるかもしれません。
おわりに
今回の比較はあくまでTesseractとgpt-4o-miniということで記憶にとどめていただけると幸いです。
今後、社内で「OCRをやりたいんだけど」という引き合いがあったら、gpt-4oのことも少し頭に入れておいて、選択肢の1つにしていただけると幸いです。
次回の記事では、宝くじ券の番号をOCRで認識させるプログラムを紹介します。私事で恐縮なのですが、先日宝くじを150枚買ったのですが、券を1つ1つ確認すると歳のせいか手がカサカサになり、紙で切れて血が出てしまいました。OCRを使って当選した券を瞬時に見分けられないか・・・ということで、宝くじ番号を大量に読み込んで、当たり券を判定するプログラムの記事を投稿したいと思います。(券売所の機械で確認してもらえばいいのに、プログラムで実装する必要あるか?・・・💦)