
はじめに
先日、「OCRとOpenAIの比較」や「宝くじの番号をOCRで一括確認する方法」に関する記事を投稿しました。主に画像内の文字や数字の認識精度を比較した内容です。詳しくは以下の記事をご覧ください。
今回は、表形式の画像に焦点を当てて、OCRとOpenAIの認識精度を比較してみようと思います。
私自身は現在、別の業務の傍ら「特許情報検索システム」の開発を進めています。特許情報には文章だけでなく、図や数式、表なども含まれるため、それらの内容を正確に読み取る技術が必要です。特に、表の認識精度向上は非常に重要な課題です。この調査結果は今後のシステム開発の貴重な知見となると考えています。
使用したサンプルについて
今回は、特許庁のサイトからダウンロードした表形式の画像をサンプルとして使用し、OCRとOpenAIで認識精度を確認していきます。

この画像はかなり細かく、文字や線がかすれているため、精度の高い読み取りは難しそうです。それでも、OCRとOpenAIを使用してどこまで正確に認識できるかを試してみます。
プログラム
以下に、gpt-4oとOCRを使用したプログラムを示します。
gpt-4oのプログラム
まずは、ChatGPTに表形式の画像を読み込ませ、テキストとして出力する方法です。その後、そのテキストを表に変換してCSV形式で保存します。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import base64
import pandas as pd
question = """
図の中の表を表形式にして出力して
"""
image_path = "C:\\Users\\ogiki\\Desktop\\spreadsheet.jpg"
system = "あなたは有能なアシスタントです。ユーザーの問いに回答してください"
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
base64_image = encode_image(image_path)
image_template = {"image_url": {"url": f"data:image/png;base64,{base64_image}"}}
chat = ChatOpenAI(temperature=0, model_name="gpt-4o-mini")
human_prompt = "{question}"
human_message_template = HumanMessagePromptTemplate.from_template([human_prompt, image_template])
prompt = ChatPromptTemplate.from_messages([("system", system), human_message_template])
chain = prompt | chat
result = chain.invoke({"question": question})
rows = result.content.split('\n')
table_data = [row.split() for row in rows if row.strip()]
df = pd.DataFrame(table_data)
csv_path = 'output_gpt-4o.csv'
df.to_csv(csv_path, index=False, header=False)
print(f"CSVファイルが {csv_path} に保存されました。")
OCR(Tesseract)のプログラム
続いて、Tesseract OCRを使用したプログラムです。基本的な流れは同様で、OCRで取得したテキストを表形式に変換し、CSVファイルに保存します。
import cv2
import pytesseract
import pandas as pd
image_path = 'C:/Users/ogiki/Desktop/spreadsheet.jpg'
image = cv2.imread(image_path)
custom_config = r'--oem 1 --psm 6'
text = pytesseract.image_to_string(image, config=custom_config, lang='jpn')
rows = text.split('\n')
table_data = [row.split() for row in rows if row.strip()]
df = pd.DataFrame(table_data)
csv_path = 'output_ocr_cv2.csv'
df.to_csv(csv_path, index=False, header=False)
print(f"CSVファイルが {csv_path} に保存されました。")
OCRについての詳しい設定や事前準備については、以前の記事を参考にしてください。
処理実行結果
それでは、実際にプログラムを実行してみた結果を確認します。
gpt-4oの結果
最初に試した際、次のようなエラーメッセージが表示されました。
申し訳ありませんが、画像の内容を直接読み取ることはできません。
gpt-4o-miniでは対応できないようです。次にgpt-4oで実行したところ、出力が得られました。
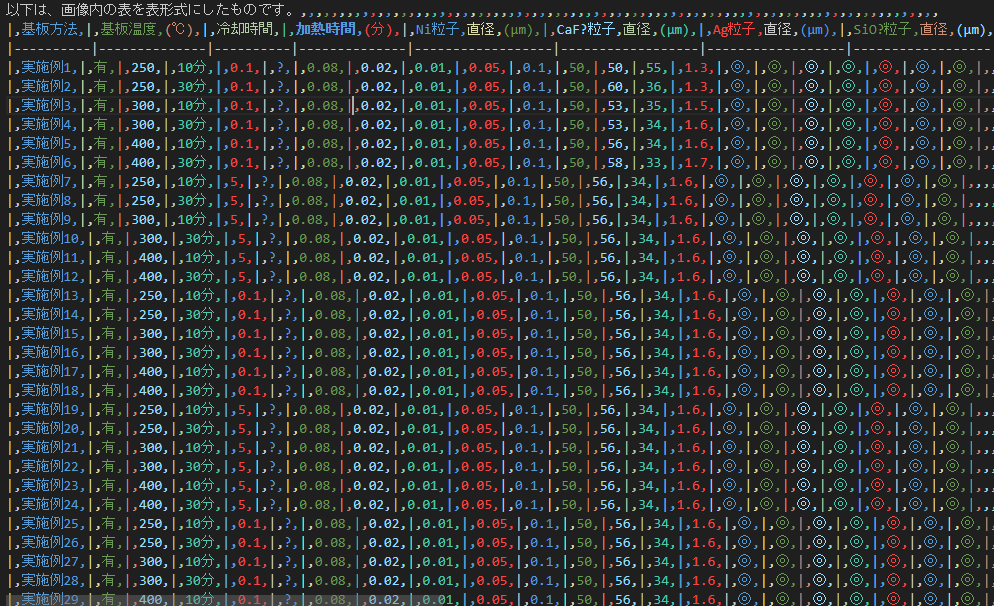
一見うまくいっているように見えますが、タイトル部分が大きく異なっていたり、セルが正確に認識されていない箇所があります。
OCR(Tesseract)の結果
続いて、Tesseractを使用した結果です。
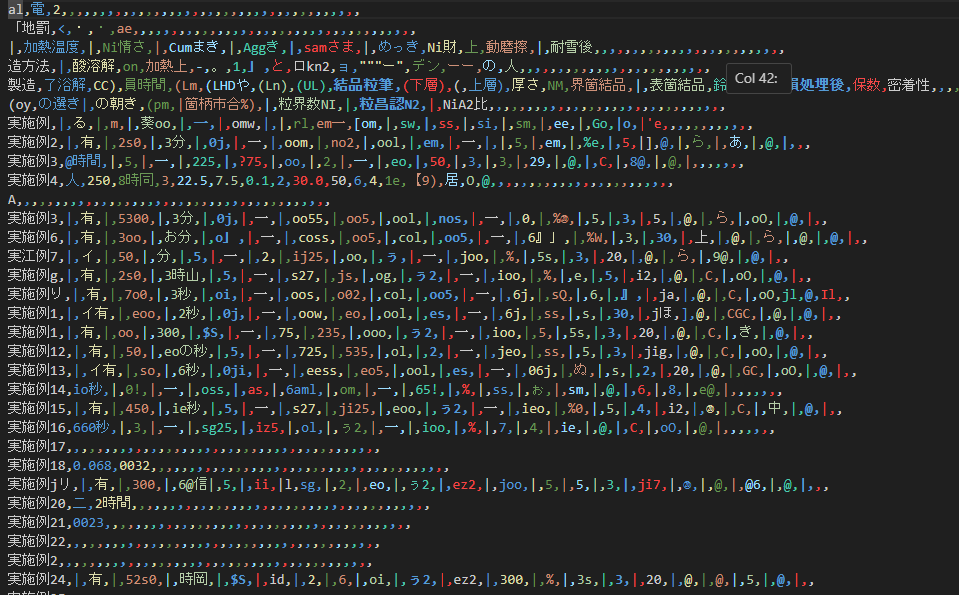
こちらも表が正しく認識されておらず、実用には程遠い結果となりました。
おわりに
今回は、表形式の画像認識について、OCR(Tesseract)とOpenAI(gpt-4o)を比較してみました。どちらも現段階では課題が残っており、完璧な認識は難しいと感じました。しかし、この経験は今後のシステム開発に役立つ知識となるでしょう。