
はじめに
前回は、各XMLファイルの中にある「タイトル情報」を基に「自動タグ付け」して、それをVectorDB (Chroma)の属性として登録することをしてみました。これで、VectorDBに対する準備ができました。
ただ、この記事を書いた後に大量ファイルをロードしようとしたのですが、処理時間を非常に要することがわかりました。
今までは1ファイルの処理に0.01~0.1秒かかる程度だったのですが、「自動タグ付け」処理を追加すると、1ファイルにつき30~40秒かるようになりました。
XMLファイルが10,000程度あるので、単純に計算したらVectorDBへ登録する処理時間は3日半かかることになります・・・💦
これはまずいという事で、もう一度プログラムを見直すことにしました。
ソースコード
最終的なソースコードは以下となります。
XMLの「コンテンツ」が無いことによるエラーへの対処と、性能への対処の大きく2点が改良点です。
それぞれについて、説明をしていきます。
import glob
import os
import xml.etree.ElementTree as ET
from dotenv import load_dotenv
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from pydantic import BaseModel, Field
from langchain.chat_models import ChatOpenAI
from langchain.chains import create_tagging_chain_pydantic
load_dotenv()
docs = []
# 取り出したい名前空間-タグ名
name_spaces_tag_names = [
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PublicationNumber",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PublicationDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}RegistrationDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}ApplicationNumberText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PartyIdentifier",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}EntityName",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PostalAddressText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}PersonFullName",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}P",
"{http://www.wipo.int/standards/XMLSchema/ST96/Common}FigureReference",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}PlainLanguageDesignationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}FilingDate",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}MainClassification",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}FurtherClassification",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}PatentClassificationText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}SearchFieldText",
"{http://www.wipo.int/standards/XMLSchema/ST96/Patent}ClaimText",
]
llm = ChatOpenAI(model="gpt-3.5-turbo")
class TagAttribute(BaseModel):
tags: list[str] = Field(description="文章の中でキーワードを取得")
def set_element(level, trees, el):
trees.append({"tag" : el.tag, "attrib" : el.attrib, "content_page" :el.text})
def set_child(level, trees, el):
set_element(level, trees, el)
for child in el:
set_child(level+1, trees, child)
def parse_and_get_element(input_file):
tmp_elements = []
new_elements = []
tree = ET.parse(input_file)
root = tree.getroot()
set_child(1, tmp_elements, root)
for name_space_tag_name in name_spaces_tag_names:
for tmp_element in tmp_elements:
if tmp_element["tag"] == name_space_tag_name:
new_elements.append(tmp_element)
return new_elements
title = ""
entryName = ""
patentCitationText = ""
files = glob.glob(os.path.join("C:\\Users\\ogiki\\JPB_2023185", "**/*.*"), recursive=True)
for file in files:
base, ext = os.path.splitext(file)
if ext == '.xml':
# --- topic名称 ---
topic_name = os.path.splitext(os.path.basename(file))[0]
# --- file名称 ---
print(file)
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
new_elements = parse_and_get_element(file)
for new_element in new_elements:
text = new_element["content_page"]
if text is not None:
tag = new_element["tag"]
title = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle" else ""
entryName = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Common}EntityName" else ""
patentCitationText = text if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Common}PatentCitationText" else ""
# --- キー情報取得 ---
keys_str = ""
if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle":
chain = create_tagging_chain_pydantic(TagAttribute, llm)
keys = chain.run(text)
i = 0
for key in keys:
i += 1
if i == 1:
keys_str = str(key[1][0])
else:
keys_str = keys_str + ", " + str(key[1][0])
documents = text_splitter.create_documents(texts=[text], metadatas=[{
"name": topic_name,
"source": file,
"tag": tag,
"keys": keys_str,
"title": title,
"entry_name": entryName,
"patent_citation_text" : patentCitationText}]
)
docs.extend(documents)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
db = Chroma(persist_directory="C:\\Users\\ogiki\\vectorDB\\local_chroma", embedding_function=embeddings)
# トークン数制限のため、500 documentずつ処理をする
intv = 500
ln = len(docs)
max_loop = int(ln / intv) + 1
for i in range(max_loop):
splitted_documents = text_splitter.split_documents(docs[intv * i : intv * (i+1)])
db.add_documents(splitted_documents)
特筆する部分を説明していきます。
「コンテンツ」が無い(None)
大量のファイルをロードしようとすると、たまに「content_page」のNoneとなるエラーが発生しました。これは「開始タグ」と「終了タグ」の間に「コンテンツ」が無い場合であるためでした。try catchで対応しようかとも思ったのですが、今後もいろいろな未知のエラーを想定して、以下の様に「コンテンツ」が無い場合は処理をしないことにしました。
if text is not None:
性能問題
前回のプログラムと比較して、性能が大幅に劣化しました。どこに性能問題があるかですが、それは明らかで、XMLファイルのelementを取得するたびにcreate_tagging_chain_pydanticの関数を呼び出す部分です。この関数はタグ付けをするため、いちいち生成AI(ChatGPT)のAPIをコールします。そのためこの関数の処理時間は長くなってしまいます。この関数の呼び出す頻度を減らすことが肝要だと考えました。
いろいろ考えた挙句、今回は「タイトル」だけを「自動タグ付け」の対象としてVectorDBに登録することとしました。修正したプログラムが以下となります。
if tag == "{http://www.wipo.int/standards/XMLSchema/ST96/Patent}InventionTitle":
こうすることで、タグ名称が<pat:InventionTitle>の場合のみcreate_tagging_chain_pydanticを呼び出すこととなり、処理性能の劣化を食い止められます。
では、プログラムを実行します。
python chroma_streamlit_tagging.py
VectorDB確認
いつものように「DB Browser(SQLite)」で確認をしてみます。

一応「keys」というレコードはあるようです。
では、「keys」だけに絞り込んでみます。
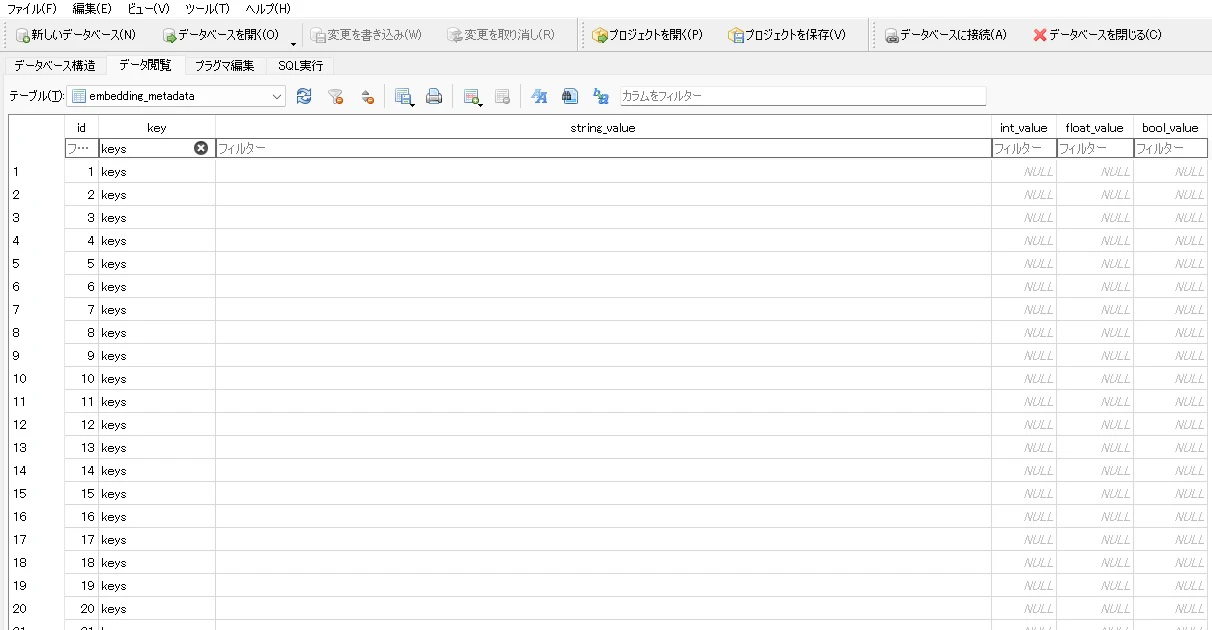
ある程度予測をしていましたが、ほぼブランクです。少し不安でしたので、ちゃんと値が入っているもののみを抽出することにしました。
SELECT * FROM embedding_metadata WHERE key = 'keys' AND string_value <> ''
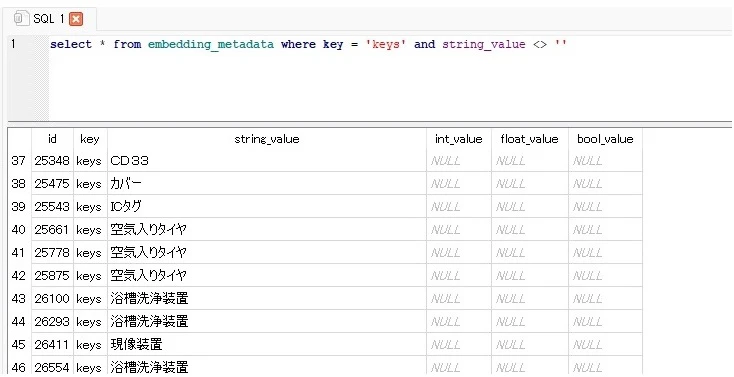
ちゃんと入っているようです。💦
これで、各XMLファイルから「タイトル情報」に「自動タグ付け」ができました。
念のため、SQLiteのファイル容量を確認してみます。
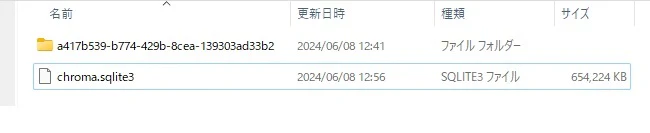
今回はtext-embedding-3-smallを採用したためでしょうか。text-embedding-ada-002の場合より容量が増えるのではないかと思っていたのですが、逆に小さくなっていました。ただ、654MBのファイルという事でデータベースは正しく生成されているのだろうと判断しました。
おわりに
今回の記事では、streamlitで生成AIに対して質問をするプログラムを記載する予定だったのですが、大きな問題にぶち当たり、急遽VectorDBへの登録ソースコードの修正について載せることにしました。
これでやっと生成AIとQAのやり取りができることになります。