
ローカルLLMをWindowsで動かしてみた話
はじめに
最近「ローカルLLM」という言葉に惹かれ、調べてみたところ、なんとChatGPTのような言語モデルをローカルPC上で構築できるということを知りました。@ksonodaさんの投稿記事を参考にさせて頂きました。ありがとうございます。
これまで、過去の投稿記事でRAG(Retrieval Augmented Generation)をローカルPC上で動かすことに成功していたので(下記の過去の投稿記事)、もしかしたら生成AIに関するすべての処理を自前で完結させることができるかもしれない、という期待が膨らんできました。
そこで今回は、ローカルでのLLM構築に挑戦してみた体験談を共有したいと思います。
Ollamaのインストールとサーバ起動
ローカルで動かせるLLMのオープンソースプロジェクトはいくつかあるようなのですが、Windows上で利用できるものを探してみたところ、Ollamaというものが見つかりました。まずはこれを試すことにしました。
当初、VSCodeを使いたかったのでWindows Subsystem for Linux(WSL)を使おうとしましたが、curlが使えなかったり、インストールでエラーが出たりといった問題が発生。最終的に、Windowsに直接インストールする方法を採用することにしました。インストールには以下の投稿記事を参考にしました。@kitさんありがとうございます。以上に分かりやすい内容となっていました。
早速command-r-plusモデルをインストールして実行してみました。
ollama run command-r-plus
しかしながら、失敗です。
Error: model requires more system memory (57.1 GiB) than is available (8.0 GiB)
どうやらメモリ不足のようです。手元のPCはメモリが8GBしかなく、参考にした投稿記事では、かなりリソースに余裕のある環境で動作させていました。
「AWSでスペックの高いサーバを借りようか?」とも考えましたが、それに匹敵するAWSのEC2にちて、m5.2xlargeは月額276ドル、m5.4xlargeならば月額552ドルということで、即座に断念。そんな贅沢な遊びはできません…
仮想メモリの活用
「いや待てよ、仮想メモリを使えば何とかなるんじゃないか?」と思い立ち、仮想メモリの設定を行いました。最小1901MB、最大19GBに設定して再度試行。
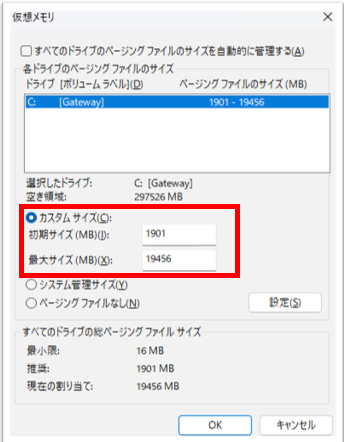
やっぱりメモリ不足で稼働しませんでした。
モデル変更
次に、軽量なモデルがないか探してみたところ、gemma2というモデルが見つかりました。これを導入し、再び実行。
ollama run gemma2
しかし、またもやメモリ不足のエラー。
そこで、「仮想メモリの最小サイズを最大と同じにしてみたらどうだろう?」と考え、再度設定を変更。
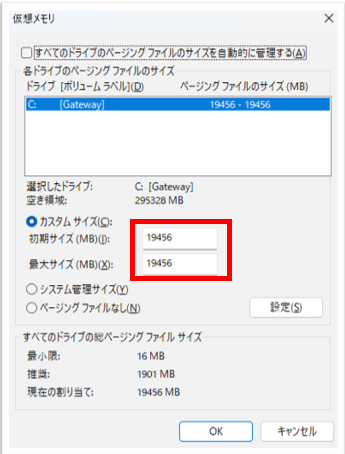
再起動後、何とか動作させることに成功しました。ただし、メモリは限界まで使用されている状態でした。
生成AIに質問してみた
次にPythonでプログラムをしてみました。
import datetime
from langchain_community.chat_models.ollama import ChatOllama
# ===============================================
print(f"[start] {datetime.datetime.now()}")
llm = ChatOllama(model="gemma2")
response_message = llm.invoke("大阪万博はあと何日?")
print(f"[process] {datetime.datetime.now()} {response_message.content}")
試しに「大阪万博はあと何日?」と質問してみました。モデルは動いているようですが、回答が返ってくるまでかなり時間がかかっている様子。9分後に、ようやく返答が表示されていました。
[start] 2024-09-14 15:34:15.569601
[process] 2024-09-14 15:43:31.424225 大阪万博は**2025年4月13日から10月13日まで**開催されます。
つまり、現在(2023年10月27日)から **もう約1年と8か月**後です。
楽しみですね!
とっても感動はしたものの、1つの質問に9分はさすがに長すぎました。これでは商用には耐えられません。
因みにこの処理の実行は、2024年9月14日に実施しているのですが、Ollamaの時が止まっているようで、現在が2023年10月27日になっていました。
おわりに
今回、ローカルでのLLM構築自体はそれほど難しくなく、インストールからデプロイまでなんとか進めることができました。しかし、PCのリソースが不足していたため、実用的な速度での応答は難しいという結果に。
今後はもっと軽量なローカルLLMがないか探してみようと思います。最終的には、LLMやRAGをすべて自作で賄うのが目標です。ただ、よく考えると、もし自分でLLMをうまく作れるようになったら、RAGは必要ないのかもしれませんね。
これが私のローカルLLM体験談です。興味のある方はぜひ試してみてください。