
はじめに
皆さん、突然ですが「このコップ、水が入っているのかな?」と考えたことはありませんか?私はといえば、家にいるときや作業中、ふと目の前のコップを見て「水が入っているか、空なのか」が気になることがあります。そして、あるときQiitaの記事を読んでいて思いつきました。
「これ、機械に判断させることってできないのかな?」と。
今回の挑戦はそんな日常の疑問から始まりました。さらに、以前見たRaspberry Piの自動餌やり機の記事がヒントになりました。家で飼っているハムスターの餌がなくなると自動で補充する仕組みでしたが、これはまさに「ある・ない」を判断するシステムです。これを自分の手で作り上げることで、「水の入ったコップ」と「空のコップ」を機械学習で判別できる仕組みを実現してみたいと思います。
今回挑戦すること
今回の目標はズバリ、画像から水が入っているか、入っていないかを自動判定するシステムを構築することです。
そのために、物体検出アルゴリズムのYOLO: You Only Look Onceを使ってみることにしました。
YOLOとは?
まずはYOLOについて簡単にご説明します。
YOLOは「You Only Look Once」の略で、画像や動画から物体を検出するためのアルゴリズムです。普通の物体検出手法では、画像を細かく分割して何度も検出処理を行うため、時間のかかることが多いです。しかし、YOLOは画像を一度だけ処理して結果を出すので非常に高速です。
特徴として以下のような利点があります:
1.一度の処理で物体を検出するためリアルタイムで動作可能
2.検出するだけでなく、物体の位置やラベルも同時に出力
3.モデルをトレーニングすれば、独自の対象物(今回の場合は「水入り」「空のコップ」)を検出可能
今回、このYOLOを使って「水入りコップ判別システム」を作ることにしました。
ちなみにYOLOで公開している画像を貼り付けます。
こんな感じで、人や動物、物体を認識できるようになります。
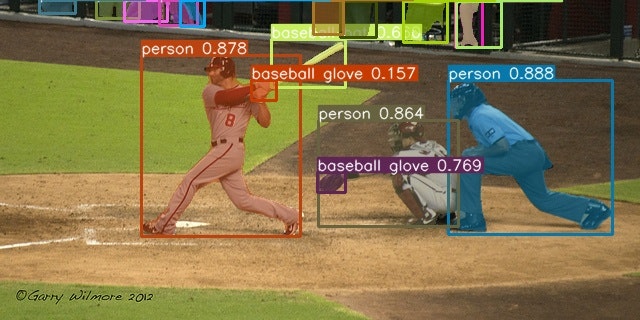
かっこイイ~
機械学習の流れ
機械学習初心者の方でもわかるように、簡単に今回の流れを説明します。作業工程を順番に解説していきますね。
以下、処理をする内容と順序です。
| 項目 | 内容 |
|---|---|
| フォルダ構成構築 | 学習に必要なデータ(画像、アノテーション)、設定ファイル、出力ディレクトリなどを整理します。 |
| yamlファイル設定 | クラス数やデータのパスを記述します。(yaml形式) |
| 画像設置 |
train(学習用)とval(検証用)ディレクトリに画像データを配置します。 |
| アノテーション作成 | 各画像に対応するアノテーションをYOLOフォーマットで作成します。通常、LabelImgやRoboflowというツールを使用して自動生成することが多いです。 |
| 学習と検証 | YOLOモデルを使用して学習を開始します。 |
| 検出 | 学習済みモデルを使用して新しい画像や動画を検出します。 |
YOLOのダウンロードとインストール
今回はyolov7を利用することにします。
以下のサイトを参考にさせて頂きました。
@john-rockyさん、わかりやすい記事の投稿ありがとうございました。おかげで私でもYOLOのセットアップができました!
リポジトリをクローン(複製)
まずはGitHubからソースコードをダウンロードします。
git clone https://github.com/WongKinYiu/yolov7.git
必要なpythonライブラリをインストール
次にダウンロードしたフォルダに移動して、YOLOに必要なライブラリをダウンロードします。
pip install -r requirements.txt
これでエラーが出なければ、インストール完了です。
フォルダ構成構築
フォルダ構成を構築します。YOLOでは、「画像」と「アノテーションファイル」(後ほど説明)を整理したフォルダ構成が必要です。今回は以下のようにフォルダを準備しました。
project/
├── train/ # 学習用(★)
│ ├── images/ # 学習用画像(★)
│ └── labels/ # 学習用アノテーション(★)
└── val/ # 検証用画像(★)
│ ├── images/ # 検証用画像(★)
│ └── labels/ # 検証用アノテーション(★)
├── data # yamlファイルのフォルダ
│ ├── coco.yaml # デフォルトで入っているyaml形式のファイル
│ └── data.yaml # yaml形式の設定ファイル(★)
└── runs/ # 結果保存用
│ ├── detect/ # 検出用結果出力フォルダ
│ ├── test/ # 検証用結果出力フォルダ
│ └── train/ # 学習用結果出力フォルダ
「★」は、今回自分で作成したファイル・フォルダです。
処理を実行すると、基本的に結果はrunsフォルダの下に自動的に保存されます。
例えば、学習(Training)を行うと、runs/trainフォルダ内にexp, exp2, exp3...といったサブフォルダが順次作成されます。同様に、検出(Detect)を実施すると、runs/detectフォルダ内にexp, exp2, exp3...といったサブフォルダが生成されます。
yamlファイルの作成
yamlファイルは、YOLOで学習を行う際の設定情報を記述する重要なファイルです。主に以下の情報を記載します:
| 項目 | 説明 |
|---|---|
| データセットのパス | 学習用のtrainフォルダと検証用のvalフォルダのパスを指定します。 |
クラス数 (nc) |
学習対象のクラス数を設定します。例えば、今回は「水あり」「水なし」の2クラスです。 |
| クラス名 | 各クラスに名前を付けます。例えば、conteins water cup(水あり)とno water cup(水なし)。アノテーションでは0から始まるクラス番号と対応付けられます。例: conteins water cupが0、no water cupが1。 |
以下は設定例です:
train: ./images/train
val: ./images/val
nc: 2
names: ['conteins water cup', 'no water cup']
学習・検証用の画像を収集
これから先の文章を理解していただくために、「学習」と「検証」の違いについて説明しています。
| 項目 | 訓練(Training) | 検証(Validation) |
|---|---|---|
| 目的 | モデルを学習させる | モデルの汎化能力を評価する |
| データの使用 | 訓練データセット(画像+ラベル) | 検証データセット(画像+ラベル) |
| モデルへの影響 | モデルの重みが更新される | モデルの重みは更新されない |
| 評価指標 | ロス関数を最小化することが目標 | 精度やIoU(Intersection over Union)などで評価 |
| 目的の結果 | モデルが訓練データでのパターンを学習すること | モデルの汎化能力を確認し、過学習を防ぐ |
コップに水が入っている状態と空の状態、それぞれの画像をWebサイトから探し集めました。
「学習用」として6枚、「検証用」として4枚を準備しています。
もちろん、画像の枚数が多いほど学習精度は向上するため、できるだけ多く集めることが推奨されています。
しかし、この後に続く「アノテーション作成」の作業量を考慮すると、今回はこれが限界でした…。
学習用画像

左の3つの写真はno water cup、右の3つの写真はconteins water cupとしました。
合計6つの写真で「学習」することにしました。
検証用画像

左の2つの写真はconteins water cup、右の2つの写真はno water cupとしました。
合計4つの写真で「検証」することにしました。
アノテーション作成
YOLOでは、画像内の「物体の位置」を示すアノテーションデータが必要です。
このデータ作成には、LabelImgというツールを使うと効率的に作業できます。
ツールを起動後、矩形(ボックス)を引いてラベルを付けるだけで簡単にアノテーションが作成できます。
LabelImgのダウンロード・インストール
以下のリンクを参考に、LabelImgをインストールしました。
kabecさんの記事を参考に、exeファイルをダウンロードし、指示通りに進めたところ、問題なくインストールが完了しました。
kabecさん、わかりやすい記事の投稿、ありがとうございました。
これでアノテーションファイルを作成できる環境が整いました。
LabelImgの利用方法
LabelImgを起動すると、以下のような画面が表示されます。

| 操作 | 説明 |
|---|---|
| Open Dir | アノテーション対象の画像が保存されているフォルダを指定します。 |
| Change Save Dir | アノテーションファイルを保存するフォルダを指定します。 |
| 形式設定 | デフォルトではPascal/VOC形式になっているため、YOLO形式に変更します。 |
アノテーション作成手順
設定が完了すると、中央に画像が表示されます。この画像上で矩形(ボックス)を引き、クラス名を定義します。以下は、水入りのコップ(contains water cup)をアノテーションする例です。
-
矩形を引く
マウスで対象物を囲むようにボックスを描画します。 -
ラベルを付ける
クラス名を入力して保存します。
これを各画像について繰り返し行い、アノテーションファイルを完成させます。

次にno water cupの例です。
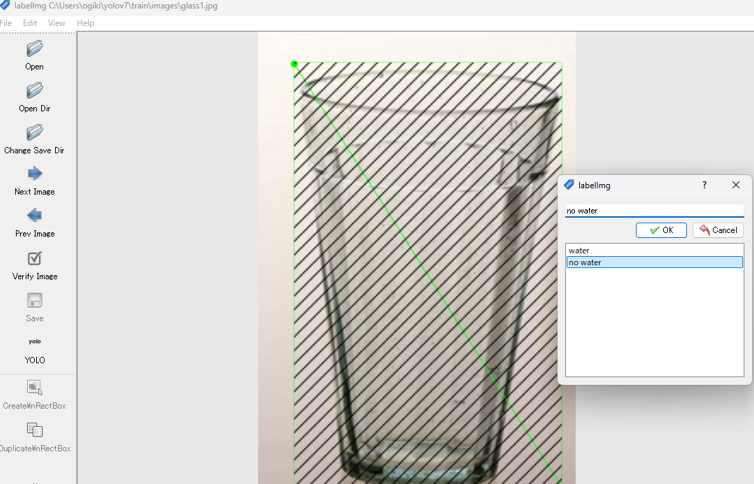
| 項目 | 説明 |
|---|---|
| Create RecBox | 画像に対して矩形(四角)設定ができる状態になります。 |
| 矩形設定 | グラスの部分に矩形ドラッグアンドドロップで設定します。 |
| ラベリング |
waterもしくはno waterのラベルを定義します。 |
完了したら、ファイルを保存して次の画像ファイルに対しても同じことをしていきます。
「学習用」(6枚)と「検証用」(4枚)の合計10枚の画像に対して実施しました。
そうするとアノテーションファイルが作成されます。例えばglass_a.jpgという画像ならばglass_a.txtというアノテーションファイルが生成されます。
LabelImgを起動した場合、personやbottleなど多くのラベル種別が出力されてしまいました。少しやりにくかったのでLabelImgがインストールされたフォルダにdataというフォルダがあり、その中にpredefined_classes.txtというファイルがあるので、それを書き換えるとwatarとno watarとシンプルなラベル選択ができるようになりました。
学習
データがそろったところで、YOLOの学習を開始します。以下のコマンドで学習を進めました。
python train.py --data data.yaml --cfg cfg/training/yolov7-tiny.yaml --weights '' --batch-size 8 --epochs 200
ここでバッチサイズとエポック数のについて説明いたします。
| 項目 | 説明 |
|---|---|
| Batch Size | 学習データをいくつかの小さなグループ(バッチ)に分け、1回の更新でそのグループ全体を使ってモデルを学習させる方法です。例えば、データセットが1000枚の画像から成る場合、batch-size=10だと、データを10枚ずつ分けて学習します。 |
| Epochs(エポック数) | モデルがデータセット全体を1回完全に学習する回数を指します。例えば、データセットが1000枚の画像から成る場合、epochs=10だと、1000枚の画像を10回繰り返して学習します。 |

「コップに水が入っている/入っていない」の学習をしました。
検出
学習が完了したら、次に検出を行います。
学習が終了すると、runs/train/ディレクトリの下にexpフォルダが生成され、その中のweightsフォルダにlast.ptという重みファイルが作成されます。この「重みファイル」を使って検出を実行します。
また、検出に使用する画像も事前に準備しておきます。今回は、検出用の画像を/test/フォルダに配置しました。

例として、以下のように認識されることを期待しています:
-
test_glass1~3.jpg: no water cup -
test_glass4~6.jpg: contains water cup
それでは検出を実行してみます。
python detect.py --source ./test/ --weights runs/train/exp/weights/last.pt
実行が完了すると、runs/detect/ディレクトリの中に結果が保存されます。
検出結果の確認
生成された画像を確認しましたが、以下のように特に変化が見られませんでした。

本来であれば、画像内の対象物に矩形が表示されるはずですが、何も検出されていません。
試しに、カスタム重みファイルlast.ptではなく、「YOLOv7の標準重みファイル」yolov7.ptを使用して検出を行ったところ、うまくいきました。
python detect.py --source ./test/ --weights yolov7.pt
以下はその結果です。

やや見づらいですが、すべての画像がcupとして認識され、グラスを囲む大きな矩形が表示されています。
この結果から、生成した「カスタム重みファイル」(last.pt)に問題があると推測されます。
重みファイルの問題と学習データ数の考察
検出がうまくいかなかった原因を考える中で、「そもそも学習に使用する画像の適切な枚数はどれくらいなのか?」という疑問が浮かびました。
これについて、ChatGPTに質問したところ、次のような回答を得ました。
## **1. 必要な画像の枚数**
物体認識の精度を高めるための画像枚数は、以下の要素に依存します:
### **対象物の種類が少ない場合**
- 例えば、1種類の物体(猫だけ、車だけ)を認識したい場合。
- 最低でも**500~1000枚**の画像が推奨されます。
- ただし、対象物の背景や撮影条件にバリエーションを持たせることが重要です(明るさ、角度、サイズなど)。
### **対象物の種類が多い場合**
- 例えば、5種類の異なる物体(猫、犬、車、人、椅子)を認識したい場合。
- 各クラス(物体の種類)ごとに最低**500~1000枚**は必要です。
- 合計で**2500~5000枚**が目安となります。
### **高い精度を求める場合**
- 1クラスあたり**2000~3000枚**以上が理想的です。
- 大規模データセット(例: COCOデータセットなど)は、10万枚以上の画像を含んでいます。
えっ、そんなに必要なんですか?
LabelImgで2000回もチマチマ設定しろと?…
ムーーリーーー!
(中2の娘がよく使うフレーズを拝借しました)
おわりに
今回はここまでにしました。だって、正直大変なんですもの…。
しかし、人間はこのままでは終わりません!次なる武器として登場するのが、データ拡張という技術です。この方法を使えば、少ない画像から自動的に大量のデータを生成することが可能になるそうです。
次回はこのデータ拡張に挑戦し、「コップに水が入っている/いない」をより精度高く判定できるモデルを作成してみたいと思います。
最後までお付き合いいただき、ありがとうございました!